







第八章 深度学习
1.加深网络
集成学习、学习率衰减、Data Augmentation(数据扩充)等都有助于提高识别精度。
- Data Augmentation基于算法“人为地”扩充输入图像(训练图像)。还可以通过其他各种方法扩充图像,比如裁剪图像的“crop处理”、将图像左右翻转的“flip处理”等。
- 加深层可以减少网络的参数数量,使学习更加高效,还可以分层次的传递信息。
- 叠加小型滤波器来加深网络的好处是可以减少参数的数量,扩大感受野(receptive field,给神经元施加变化的某个局部空间区域)。并且,通过叠加层,将 ReLU等激活函数夹在卷积层的中间,进一步提高了网络的表现力。这是因为向网络添加了基于激活函数的“非线性”表现力,通过非线性函数的叠加,可以表现更加复杂的东西。
2.常用网络
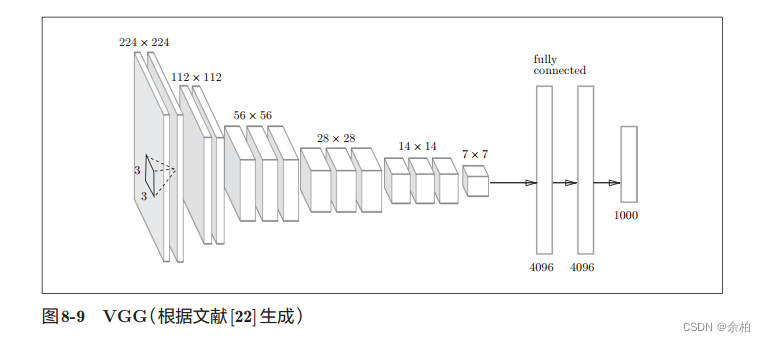
- VGG
VGG是由卷积层和池化层构成的基础的CNN。它的特点在于将有权重的层(卷积层或者全连接层)叠加至16层(或者19层),具备了深度(根据层的深度,有时也称为“VGG16”或“VGG19”)。VGG中需要注意的地方是,基于3×3的小型滤波器的卷积层的运算是连续进行的。
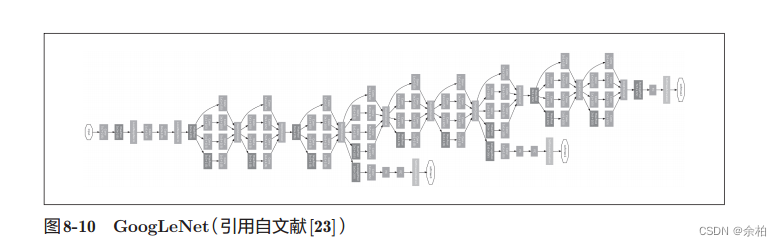
- GoogLeNet
GoogLeNet在横向上有“宽度”,这称为“Inception结构”,Inception结构使用了多个大小不同的滤波器(和池化),最后再合并它们的结果。
 1 × 1的卷积运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理
1 × 1的卷积运算通过在通道方向上减小大小,有助于减少参数和实现高速化处理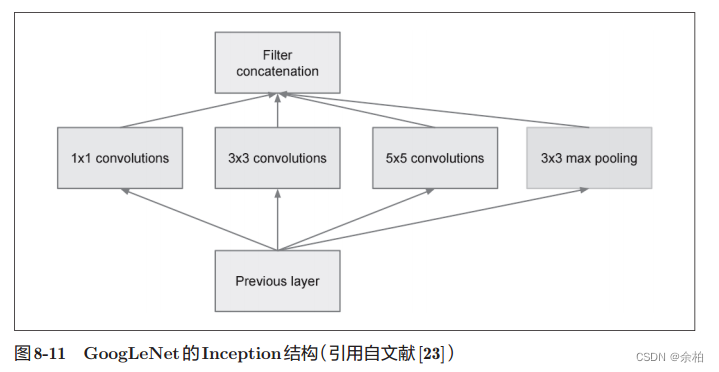
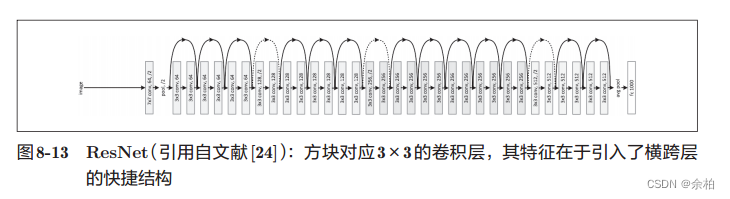
- ResNet
导入快捷结构横跨(跳过)了输入数据的卷积层,将输入x合计到输出。不用担心梯度会变小(或变大),能够向前一层传递“有意义的梯度"。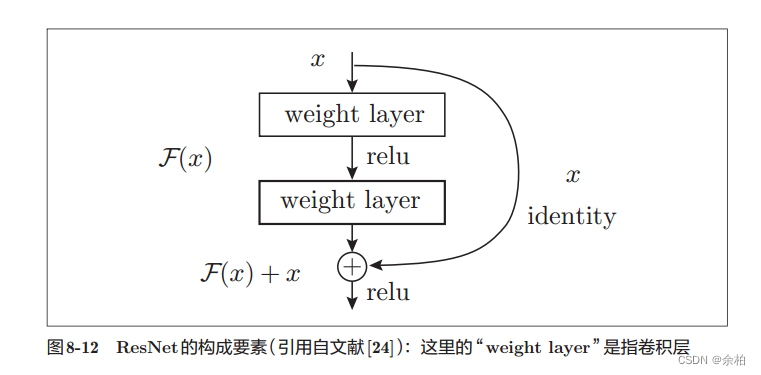 ResNet通过以2个卷积层为间隔跳跃式地连接来加深层。
ResNet通过以2个卷积层为间隔跳跃式地连接来加深层。
3.应用案例
- 物体检测:物体检测是从图像中确定物体的位置,并进行分类的问题。
- 图像分割:图像分割是指在像素水平上对图像进行分类。
- 生成图像标题
- 图像风格变化
- 图像生成
- 自动驾驶


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









