






TiDB ——TiKV
TiKV持久化
- TiKV架构和作用
- TiKV数据持久化和读取
- TiKV如何提供MVCC和分布式事务支持
- TiKV基于Raft算法的分布式一致性
- TiKV的coprocessor
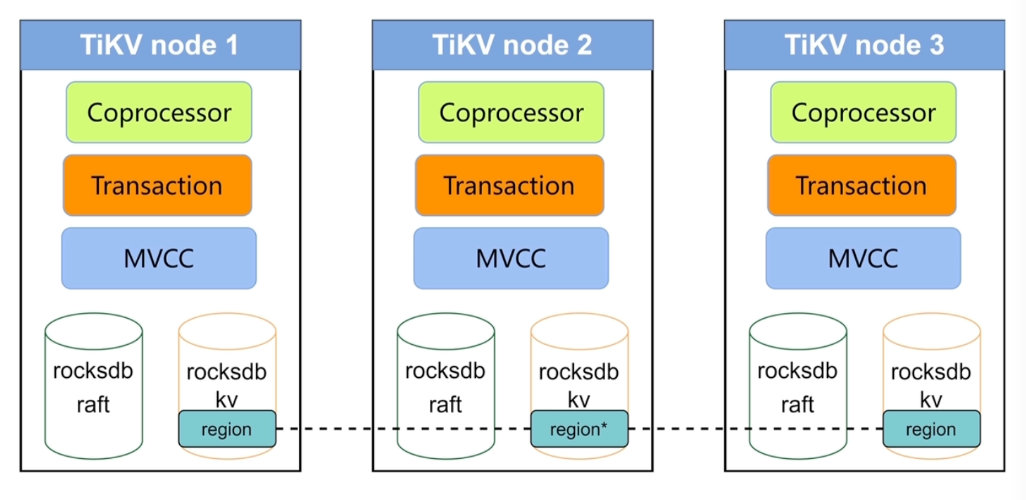
TiKV架构和作用
- 数据持久化
- 分布式一致性
- MVCC
- 分步式事务
- Coprocessor
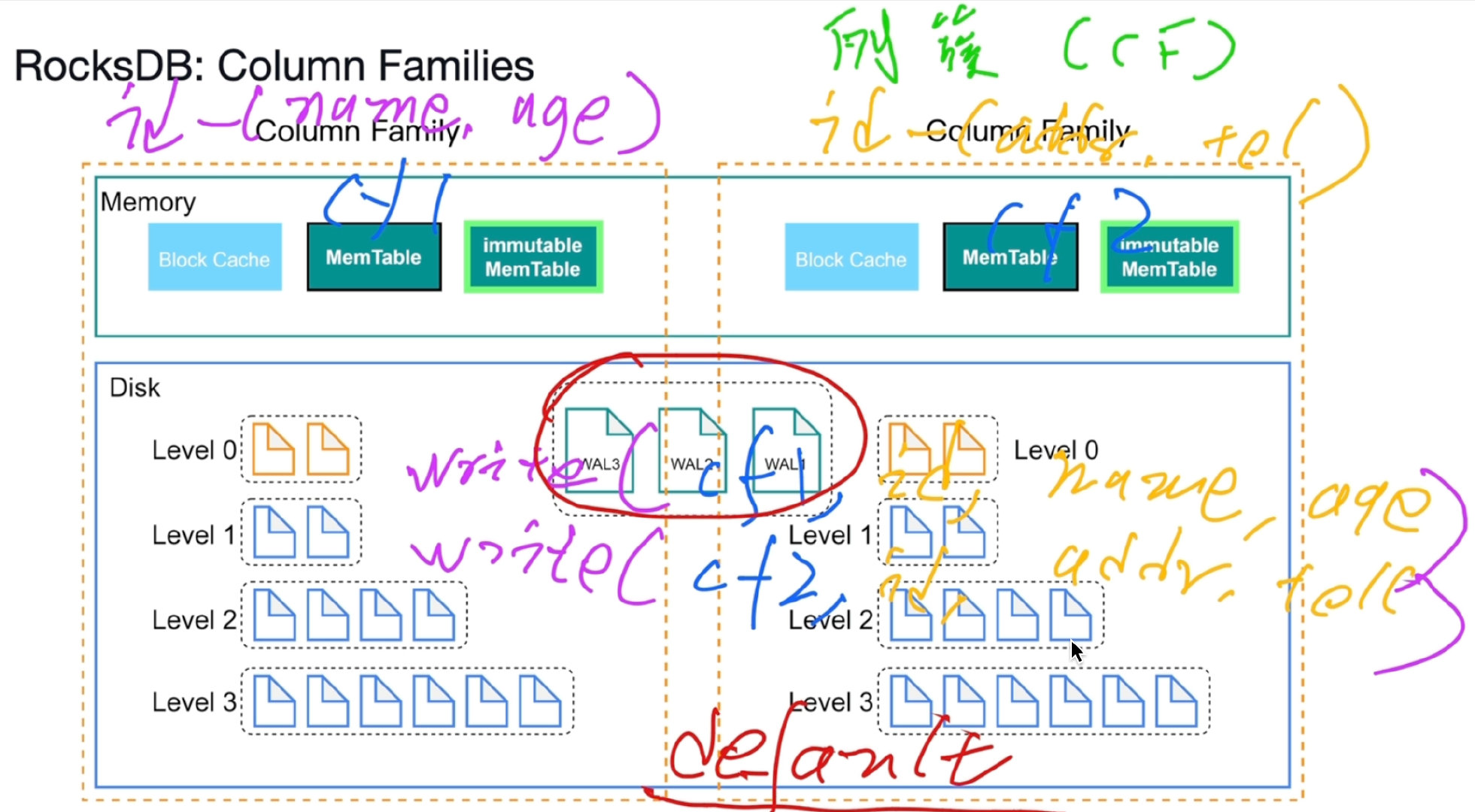
RocksDB
单机持久化引擎,单机key-value的哈希表

写入先会保存在MemTable当中,批量写入磁盘,合并。
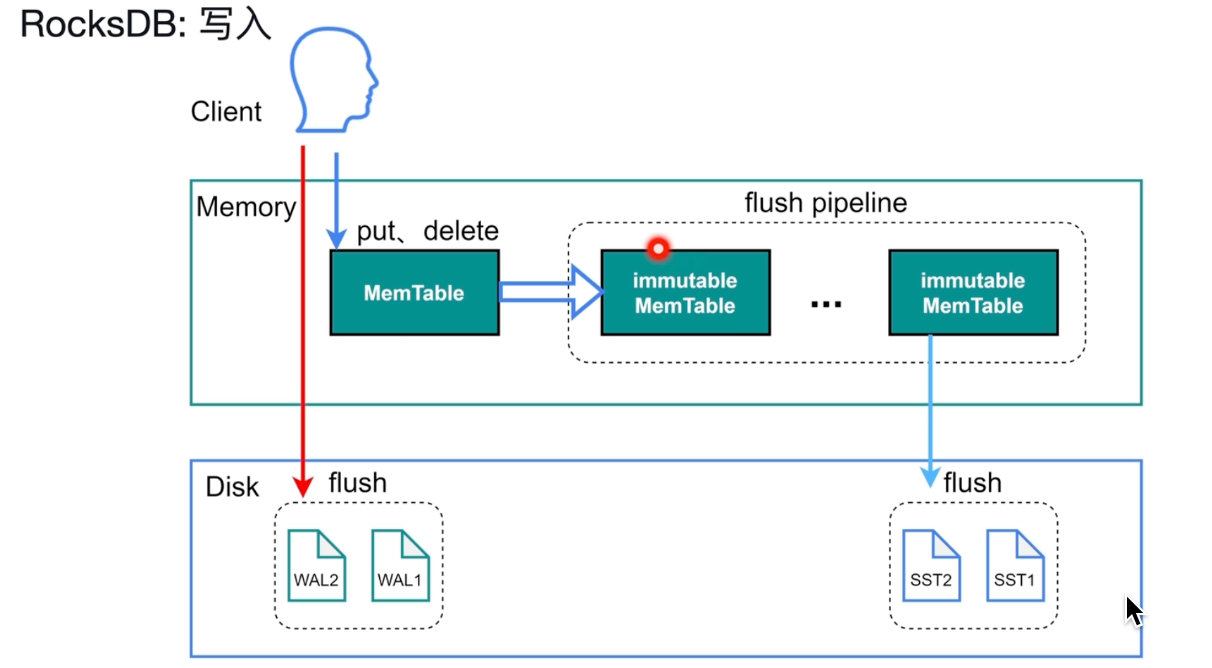
WAL:用来保证事务的原子性和持久性。
会先写到磁盘中,在写到内存中。可以实现故障恢复。
Sync_log=true
MemTable:调表和搜索保证有序性。
流控write stall=5
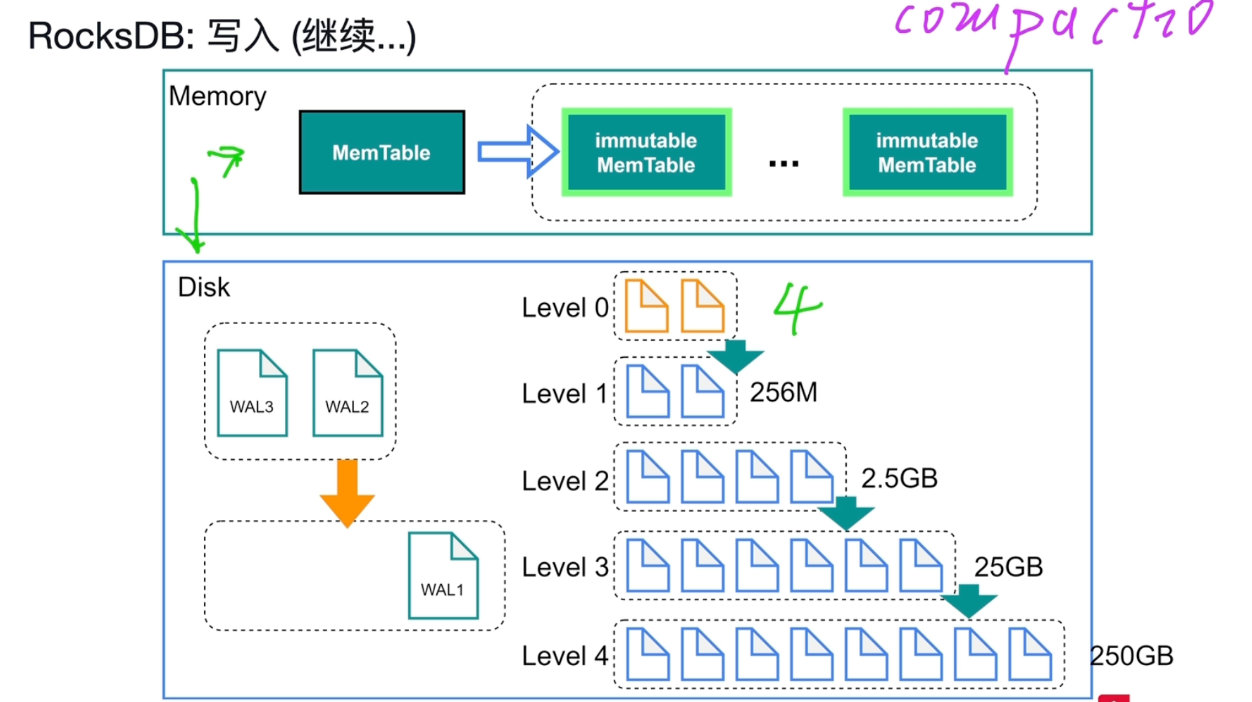
compaction查找:有序,使用二分查找。
删除:操作memTable,写入一个delete
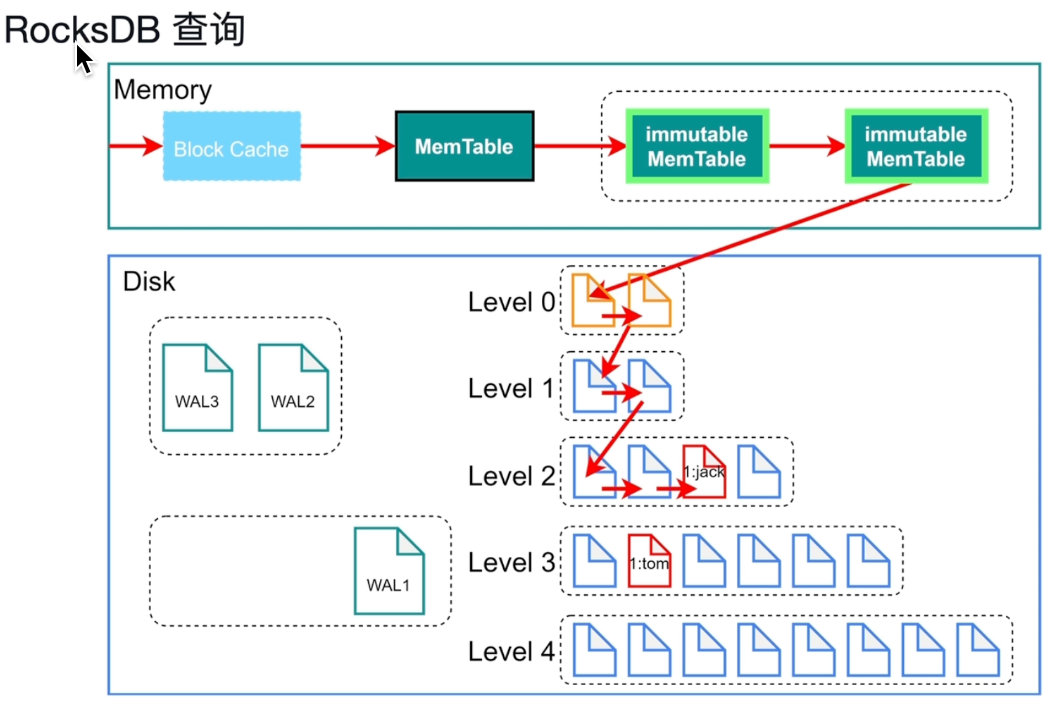
Block Cache:存最近最常读取的,找不到就去找下一个。
最新的数据永远在老数据上面,
bloom Filter:判断集合中的元素,它说元素不在就是不在,在可能不在。
分布式事务
乐观锁。
分布式事务
在内存中修改事务
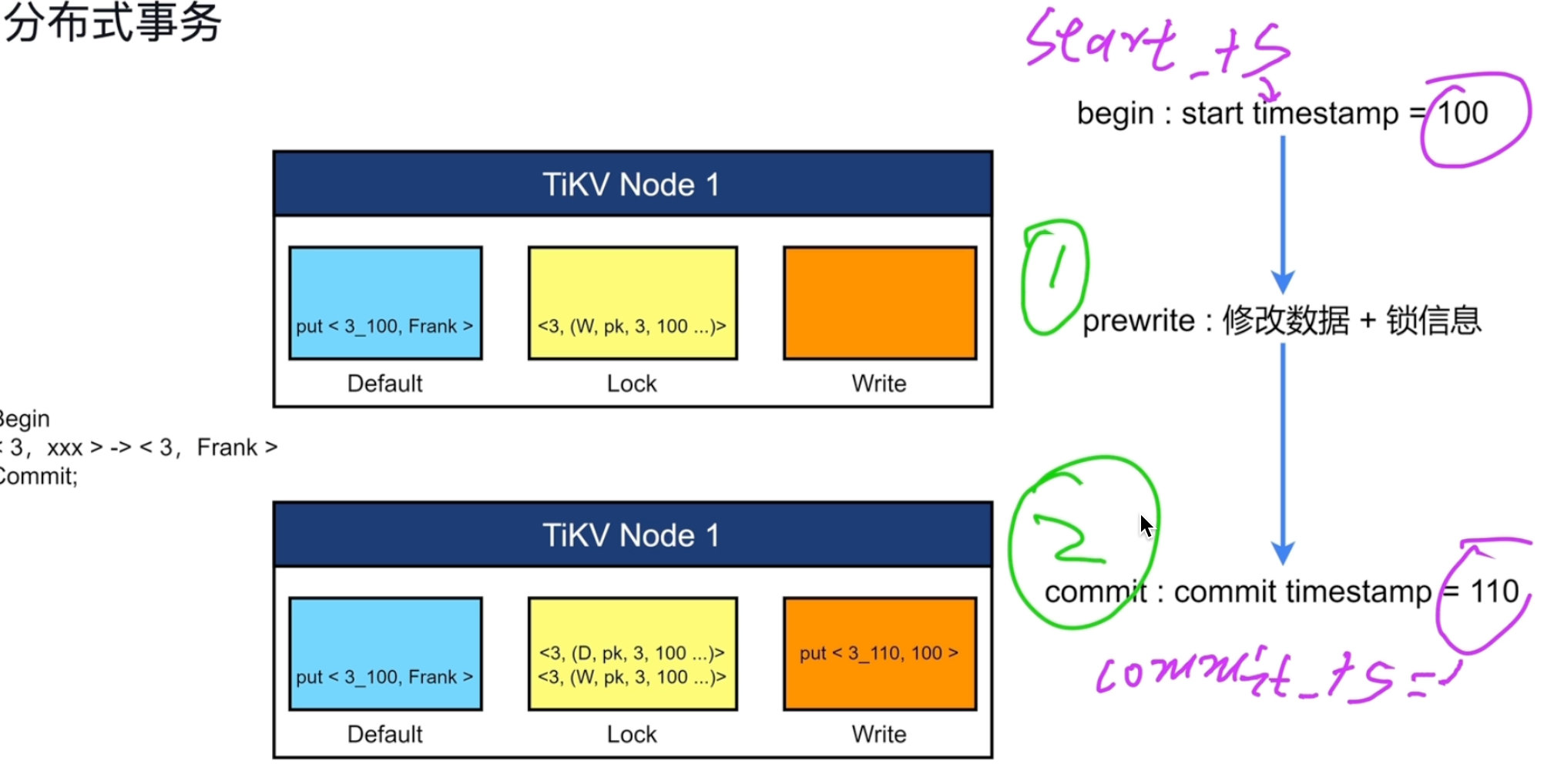
只给事务的第一行加一把主锁。
修改是检查lock里面有没有锁,如果有则先不修改,起到了阻塞的作用。事务会从PD获取事务开始的时间。
锁信息的清理:不是删除,是加入一条新的锁信息。
事务有三个阶段:
开始获取一个时间戳,一旦做了提交以后,进入两个阶段。
- 第一阶段将修改的数据和锁信息,写入
default列簇当中,锁信息写入lock列簇当中 - 第二阶段
commit,获取事务结束时间,在write当中写入提交时间,清除lock信息。从write当中去default当中去找信息。
注意事项:
write不单单是写提交信息,当用户写入了一行小于255字节,那么会存储在write列中,否则会被存入default列中。
default:存储的都是大于255字节的数据。
主锁:别的锁会存一个对主锁的指向。只给第一行数据加一把主锁,其他只加一个指向。
如果发生宕机,就看主锁有没有信息,进行一个恢复。
MVCC 多并发版本控制
实现:生成一个副本,读副本,用时间戳,取最新的。
悲观事务/悲观锁:要能感知到锁的存在。其他的事务是可以感知到的。写不阻塞读。

- 如果当前读id=1,TSO=120,可以发现最近的一条信息结束TSO是110,开始TSO是100,找到id=1,发现可以读出Jack,但是在lock当中有一条锁信息,所以不能进行写,
- 如果当前读id=2,TSO=120,可以发现,和1同理可以读出Candy,但是lock没有锁,所以也可以进行写。
- 如果当前读id=4,TSO=120,可以发现,可以读出Tony,但是lock存在锁信息,指向1的主锁,所以也不能进行写入。
TiKV-Raft
Raft与Multi Raft
读写只走leader。
region超过96MB就会另起一个单元,插入是连续的。每一个副本的ky-value都是一样的。区间是左闭右开。
一个region多副本组成一个raft group。
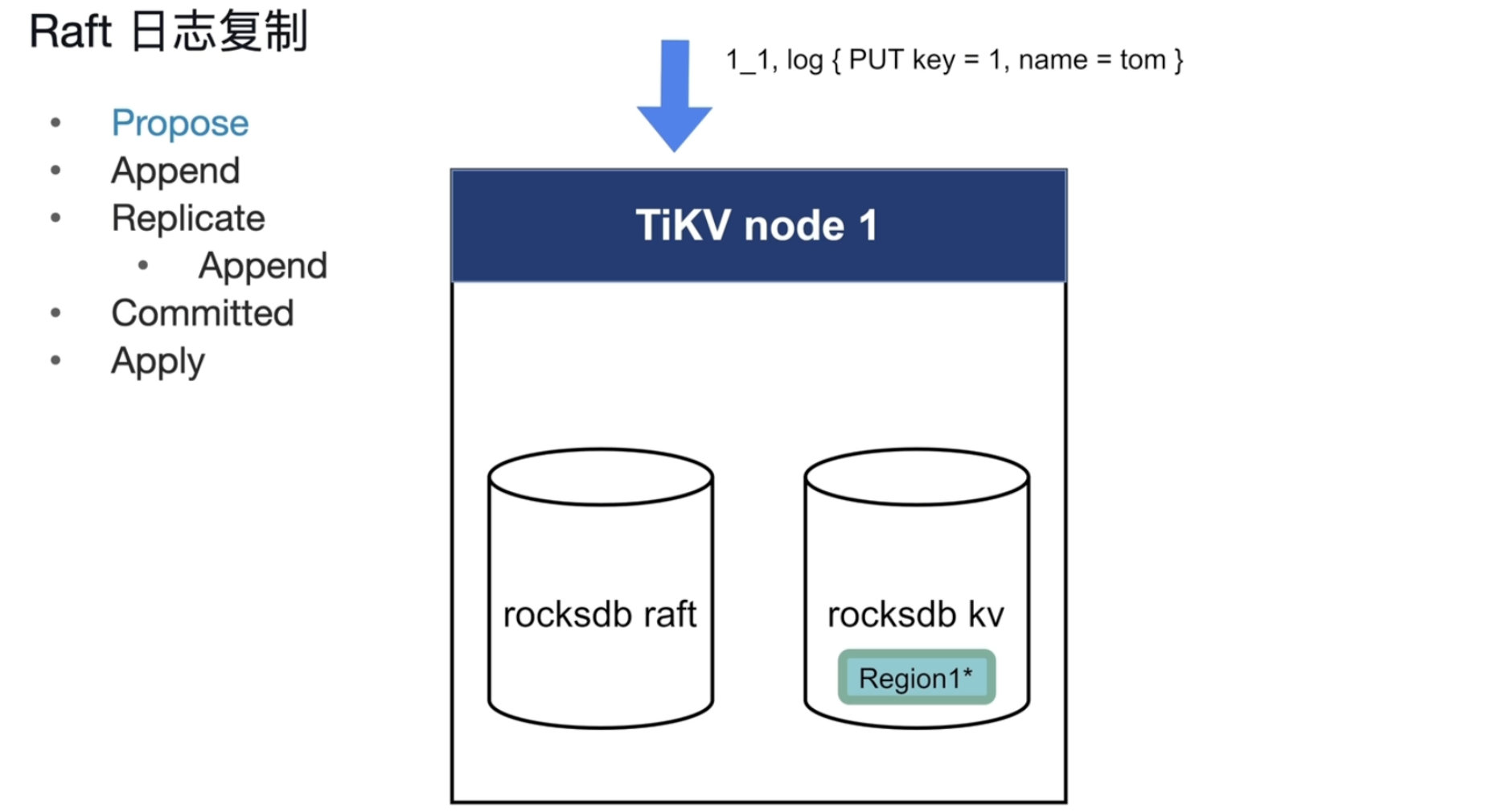
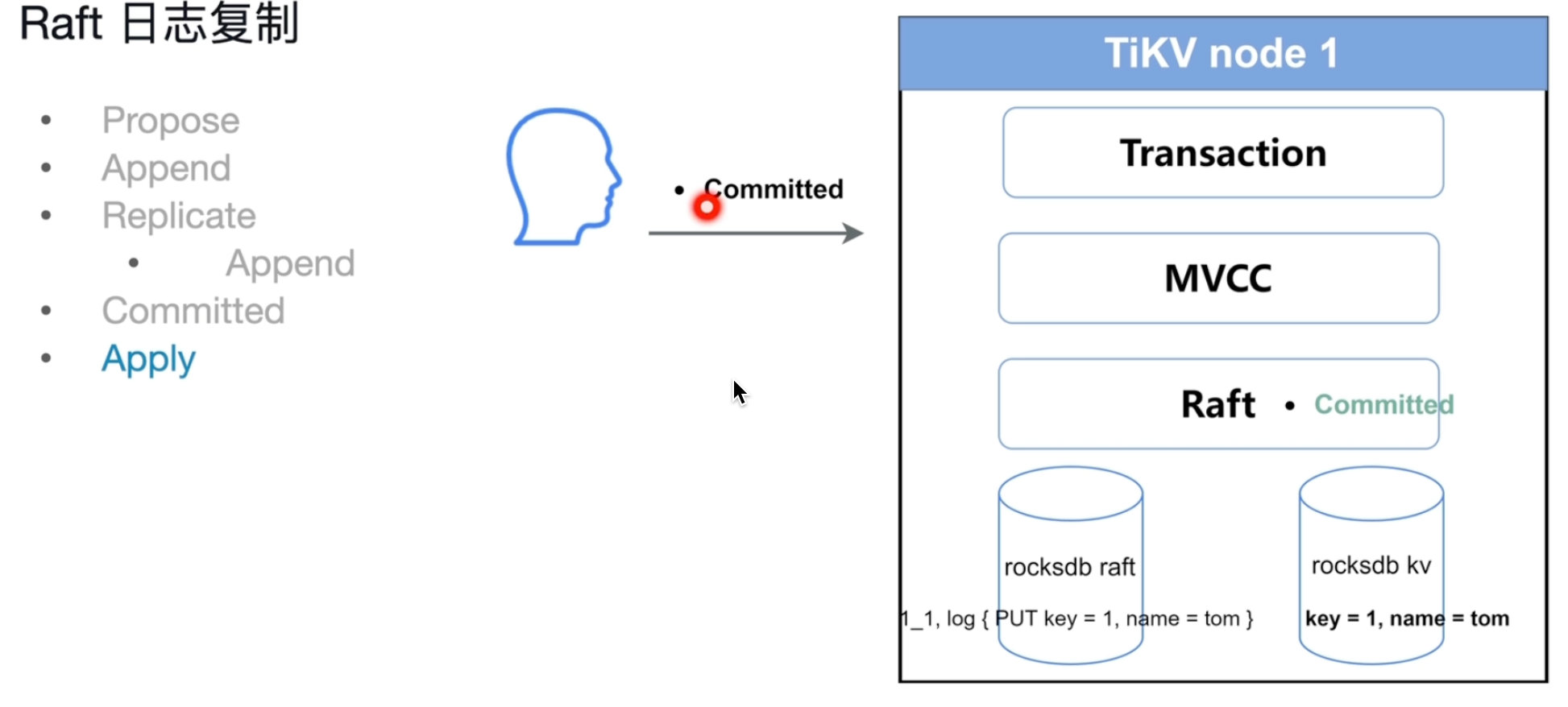
Raft日志复制
- propose,会将请求变成一个写入日志。
- append,将Raft日志存储到本地的专门存raft日志的rocks DB中。
- Replicate,复制 ,分发其他副本的所在的节点当中,持久化
- Commited,副本返回一个响应值收到并存起来了,多数节点丢不了
- Apply 将Raft日志应用,存到rocksdb KV当中
Raft Leader 选举
term:在稳定的关系的一段时期
election timeout:150ms~300ms没有心跳,没有leader。变成下一段关系。
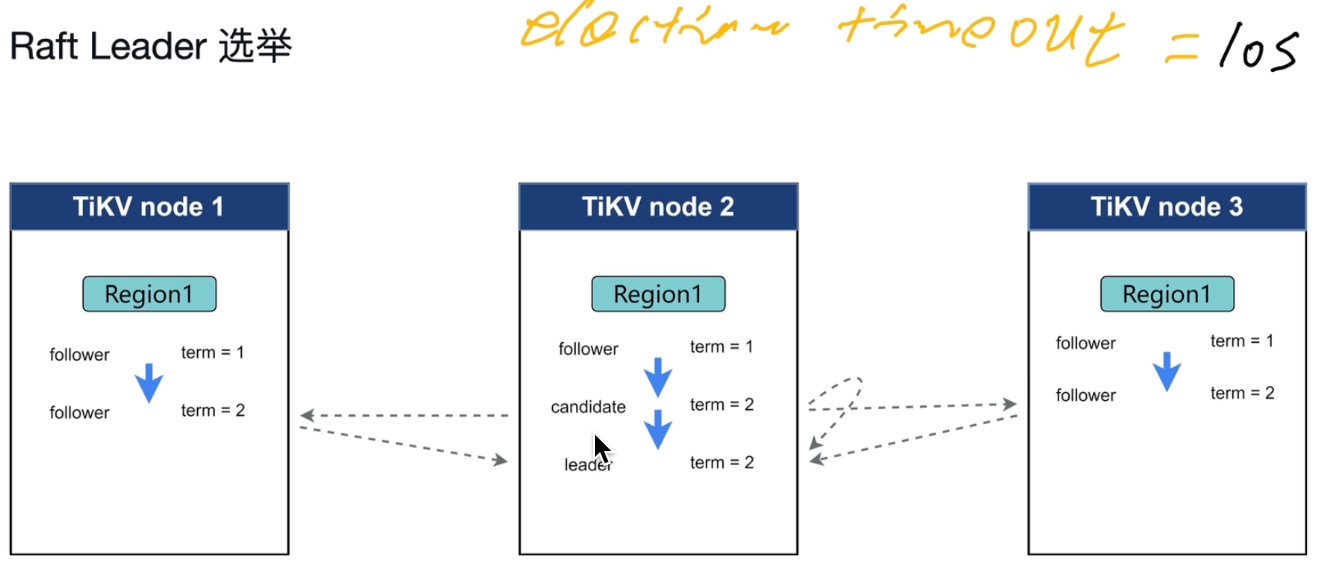
发起投票,term+1,谁的term大,谁就会变成leader
Heartbeat time interval:每隔一段时间给follower发心跳信息,没有收到心跳信息就会发起选举。如果多次时间相同,可能发起多次选举。会让一个区间的follwer都进入选举。

raft-election-timeout-ticks不能小于raft-heartbeat-ticks
TiKV 读写
数据的写入
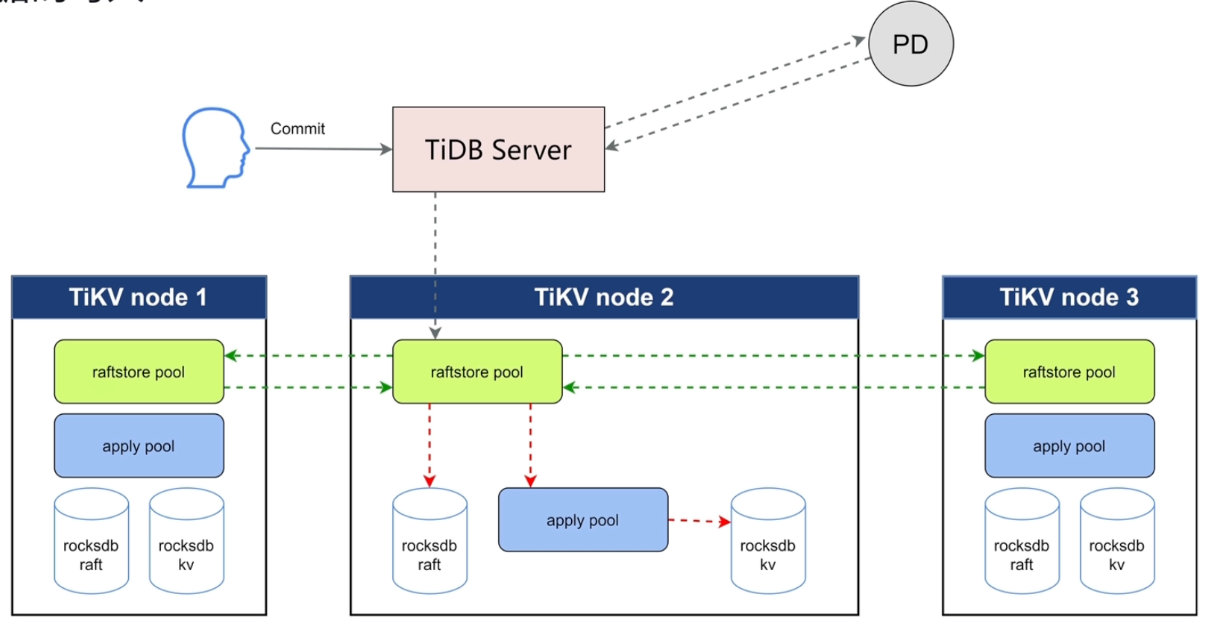
两个线程池
- propose:raftstore pool将写请求转化成raft log
- Append,raftstore pool将日志存储、持久化到rocksdb raft中
- Replicate,复制,复制给其他副本节点。保证持久化,大多数返回成功,就进入下一个状态
- commited,指日志被大多数副本接受并持久化,接受到信息,不是指用户的commited
apply pool 应用到rocksdb kv才算成功。commited才返回。
读到数据,数据一定应用到rocksdb kv中。
数据的读取
TiDB Server收到读取请求,会先去PD查,这个key在哪一个node的哪一个region当中。
readIndex:读一定在写之后,读取保证在修改之后,在读之写都应该commited掉,apply。保证读一定可以到修改之后的值。
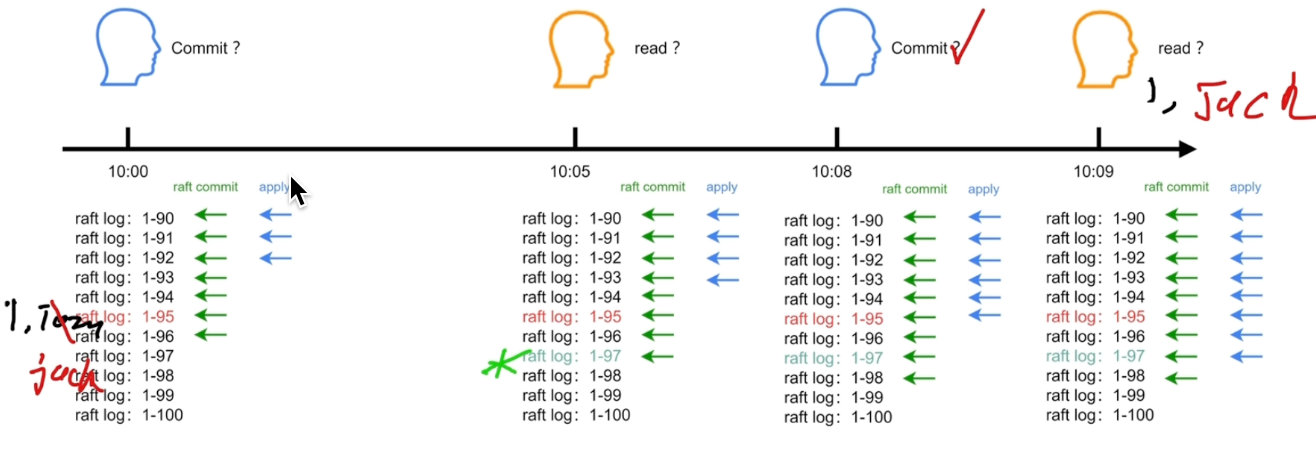
Lease Read:在election timeout 之内leader都不会改变
Follower Read:比leader读的更快由于apply的速度。
Coprocessor 协同处理器
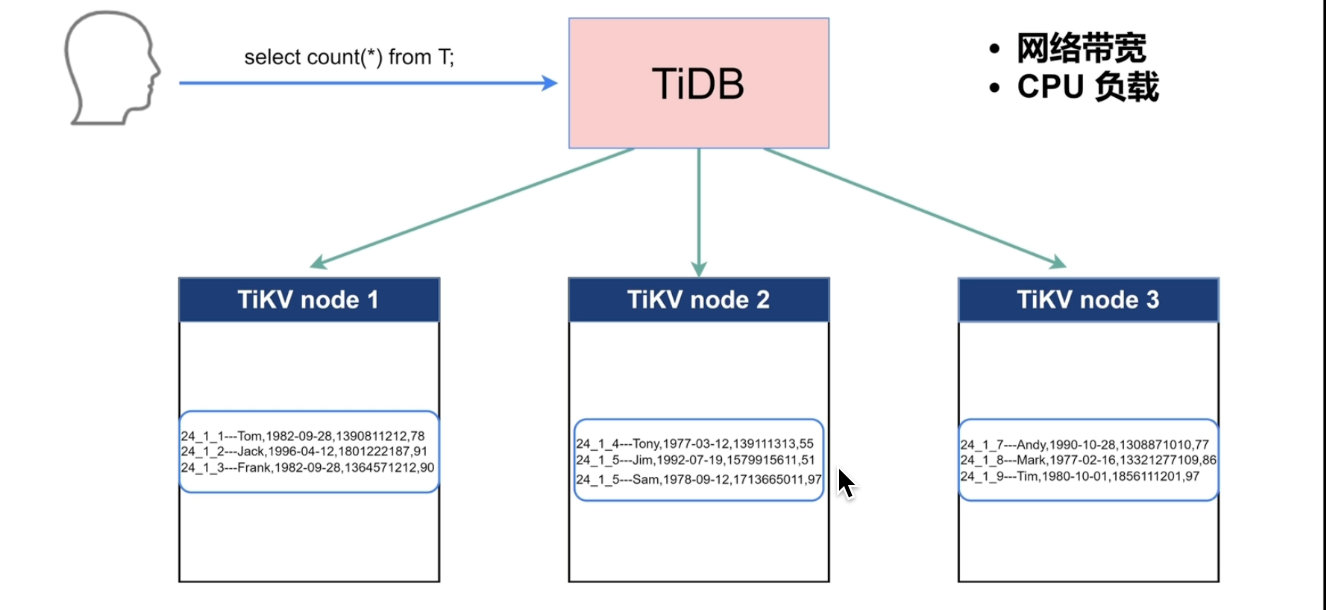
TiDB将就计算分发给TiKV的Coprocessor计算,降低TiDB Server的压力。
- 物理算子,sql的中间结果
- 分析数据,统计信息,对表进行校验

















 1528
1528











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











