






今天这个案例,适合小白,通俗易懂,代码不复杂
关于爬虫的原理网上都有,这里就不再废话了,我们直接开始案例。
本案例,我就以汽车二手之家这个网站做教程,原网址下方链接
https://www.che168.com/china/benchi/#pvareaid=100943
首先打开网站
可以看到各种汽车的数据
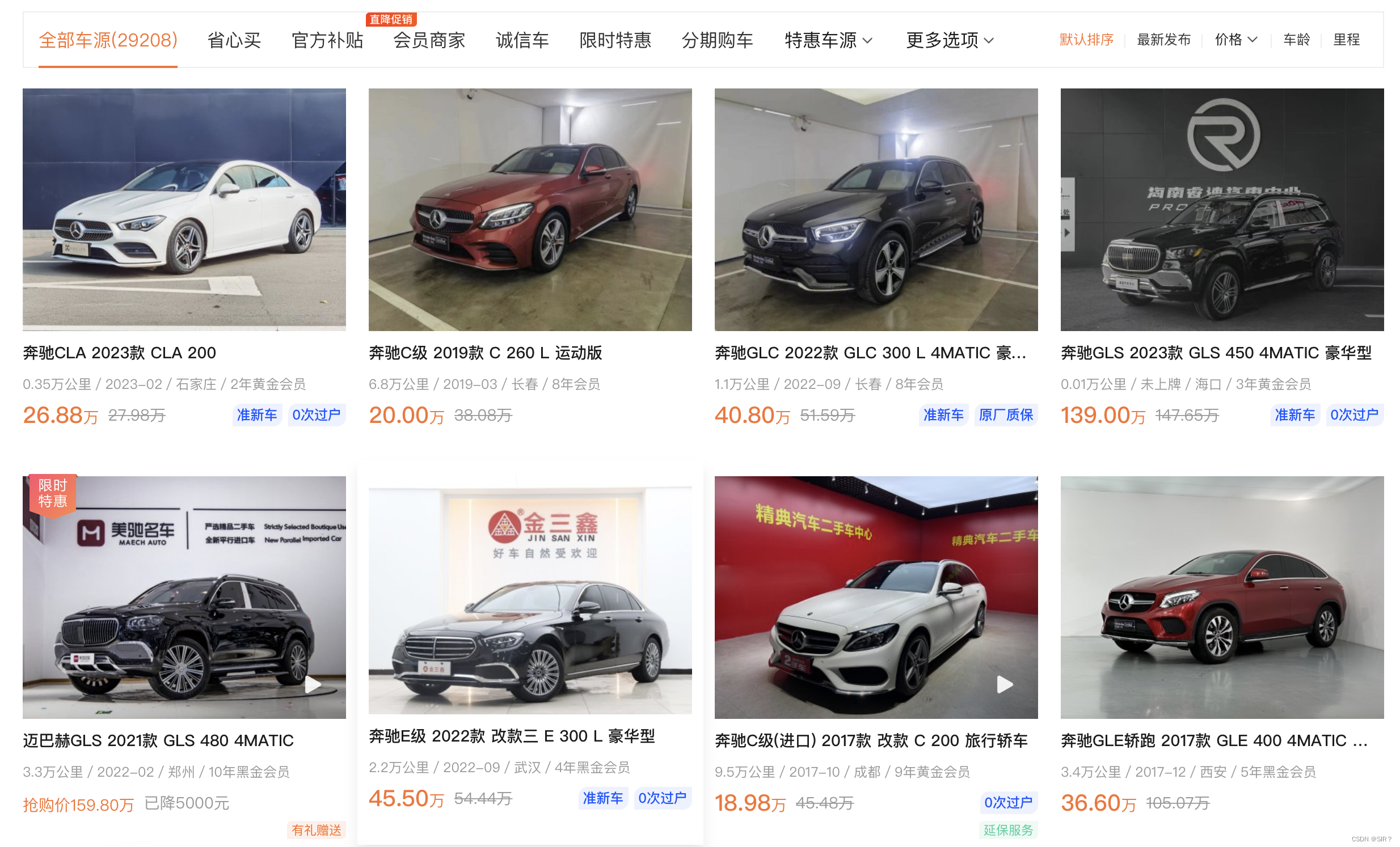
我们右键点击检查元素来到控制台
点击左上角的定位,然后随便点在一张图片上



此时,我们将鼠标放在图片上,就可以看到相关的数据信息,这就是我们所需的数据来源
导入相关的库(requests)
import requestsrequests库可以让我们对指定的网页发起请求的意思
相关参数(headers)
在爬取数据的过程中,我们需要两个参数url和headers,参数的详解如下:
| 参数 | 详解 |
| Request URL | 发送请求的网站地址,也就是汽车数据所在的网址 |
| user-agent | 用来模拟浏览器对网站进行访问,避免被网站监测出非法访问 |
参数代码准备
headler={
'User-Agent': 'Mozilla / 5.0(Macintosh;IntelMacOSX10_15_7) AppleWebKit / 605.1.15(KHTML, likeGecko) Version / 15.6Safari / 605.1.15'
}
#获取网页的地址
url = 'https://www.che168.com/china/benchi/#pvareaid=100943'向网站发送请求
#获取网页请求
reponse=requests.get(url=url,headers=headers)
#判断是否请求成功,成功的话相应码为200
if reponse.status_code==200:
print(reponse.text)
else:
break请求成功了之后,我们会看到一下的内容

此时,我们需要将数据从html源码中解析出来
解析源码数据
先导入相关的库
from lxml import etree通过etree这个库,可以将源码数据进行解析
selector=etree.HTML(reponse.text)
car1_list=selector.xpath('//*[@id="goodStartSolrQuotePriceCore0"]/ul/li')此时,将所有数据所在的列表解析出来,然后对其遍历
for car in car1_list:
try:
string=car.xpath('a/div[@class="cards-bottom"]/h4/text()')[0]
str_split=string.split(' ')
title=str_split[0]
string1=car.xpath('a/div[@class="cards-bottom"]/p/text()')[0]
str_split1=string1.split('/')
car_size=str_split1[0]
car_month=str_split1[1]
car_city=str_split1[2]
car_money=car.xpath('a/div[@class="cards-bottom"]/div/span[@class="pirce"]/em/text()')[0]
yield {
'系列':title,
'年份':car_month,
'行驶公里数':car_size,
'购买地':car_city,
'价格':car_money
}
except Exception:
continue将爬取的数据进行存储
需要导入相关的库,对爬取的数据进行存储
import csv现在可以对数据进行存储
#使用一个函数进行封装
def save_data():
with open('自己的路径名称/car.csv', 'a+', newline='', encoding='utf-8-sig') as fp:
writer = csv.writer(fp)
writer.writerow(['系列', '年份', '行驶公里数', '购买地', '价格'])
for car in car_list:
reponse=requests.get(url=car,headers=headler)
for item in parse_html(reponse.text):
writer.writerow(list(item.values()))
print('数据爬取成功了!!!!')此时,我们的数据已经爬取完毕,并且在我们的csv文件中,可以看到相应的数据
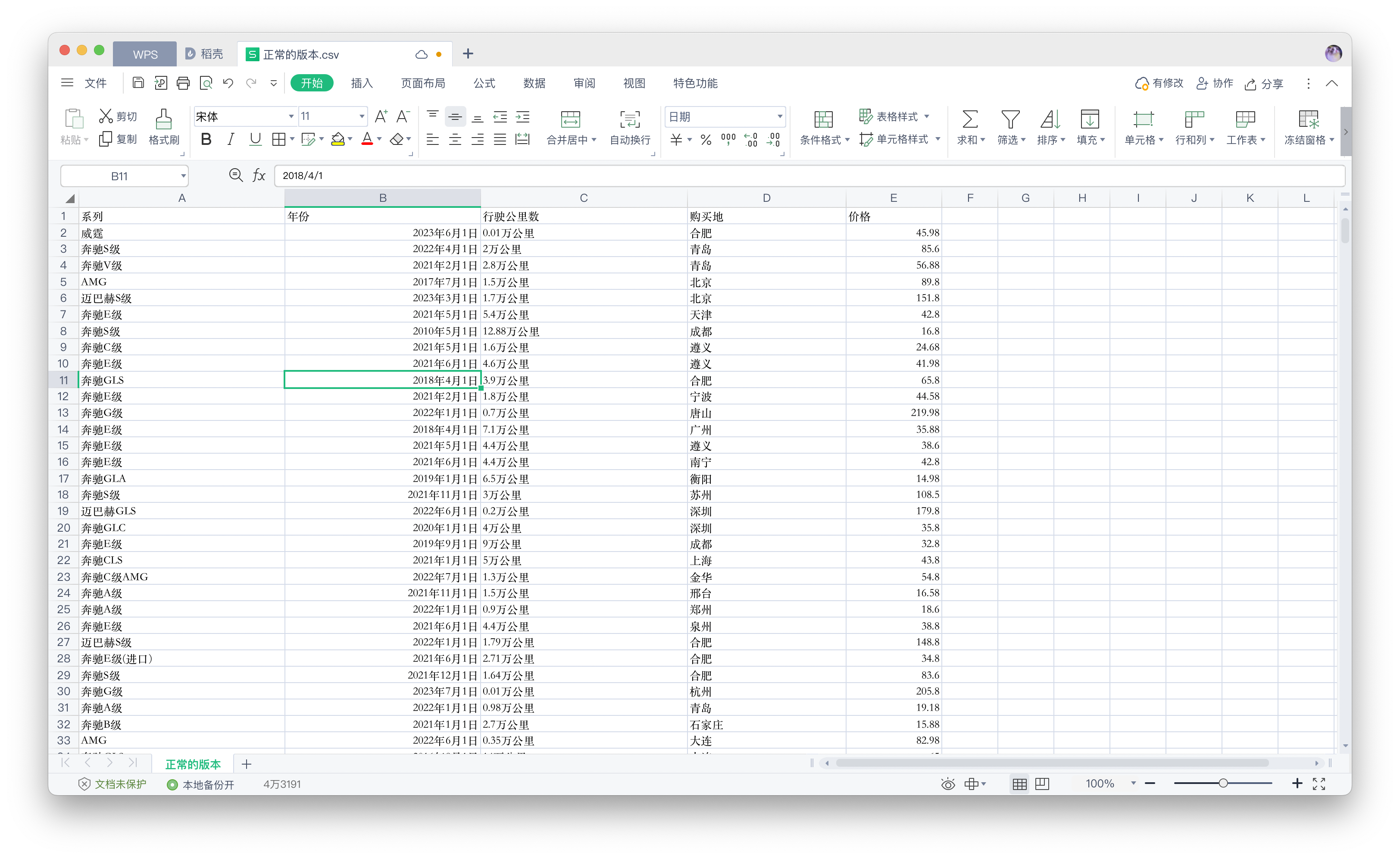
以上就是爬取一页的数据
爬取多页的数据
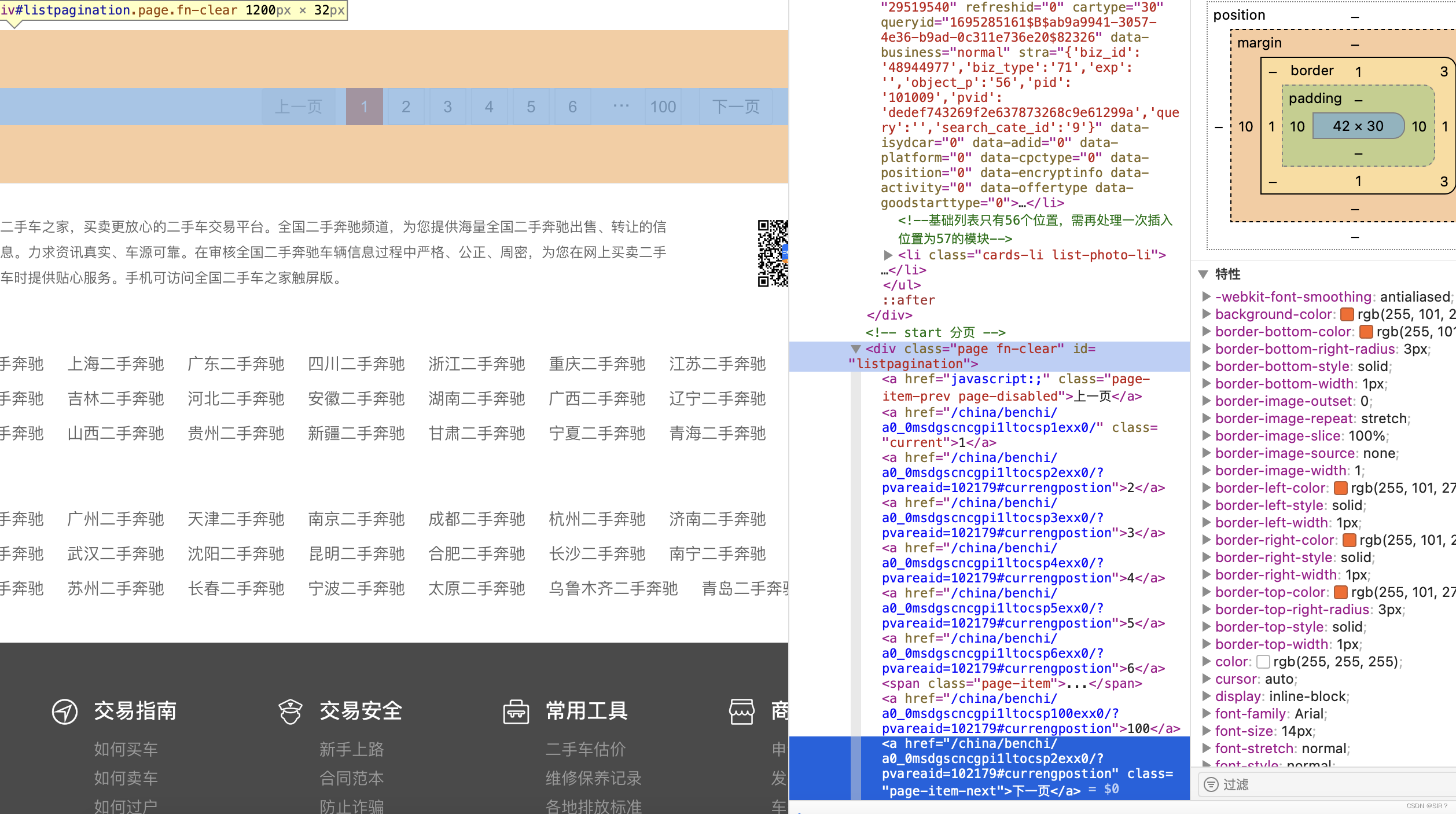
通过上述图片,可以知道,下一页网址在下一页按钮中,我们可以自定义一个函数,来获取下一页的网页地址
def main():
count=0;
url = 'https://www.che168.com/china/benchi/#pvareaid=100943'
while True:
reponse=requests.get(url,headers=headler)
if reponse.status_code!=200:
break
selector=etree.HTML(reponse.text)
try:
next_ur = re.findall('href="(.*?)" class="page-item-next">下一页', reponse.text)[0]
url = "https://www.che168.com" + next_ur
car_list.append(url)
except IndexError:
continue
count+=1
if count>=10:
break通过上述代码,可以获取10个网页地址,此时需要使用到正则表达式来获取下一页的网址,爬取的网页地址如下:

完整代码
import re
import requests
import csv
from lxml import etree
#获取网页的地址
headler={
'User-Agent': 'Mozilla / 5.0(Macintosh;IntelMacOSX10_15_7) AppleWebKit / 605.1.15(KHTML, likeGecko) Version / 15.6Safari / 605.1.15'
}
#获取网页的地址
url = 'https://www.che168.com/china/benchi/#pvareaid=100943'
car_list=[]
car_list.append(url)
#解析页面数据
def parse_html(html):
selector=etree.HTML(html)
car1_list=selector.xpath('//*[@id="goodStartSolrQuotePriceCore0"]/ul/li')
for car in car1_list:
try:
string=car.xpath('a/div[@class="cards-bottom"]/h4/text()')[0]
str_split=string.split(' ')
title=str_split[0]
string1=car.xpath('a/div[@class="cards-bottom"]/p/text()')[0]
str_split1=string1.split('/')
car_size=str_split1[0]
car_month=str_split1[1]
car_city=str_split1[2]
car_money=car.xpath('a/div[@class="cards-bottom"]/div/span[@class="pirce"]/em/text()')[0]
yield {
'系列':title,
'年份':car_month,
'行驶公里数':car_size,
'购买地':car_city,
'价格':car_money
}
except Exception:
continue
def save_data():
with open('./car.csv', 'a+', newline='', encoding='utf-8-sig') as fp:
writer = csv.writer(fp)
writer.writerow(['系列', '年份', '行驶公里数', '购买地', '价格'])
for car in car_list:
reponse=requests.get(url=car,headers=headler)
for item in parse_html(reponse.text):
writer.writerow(list(item.values()))
print('数据爬取成功了!!!!')
#爬取全部的网页地址
def main():
count=0;
url = 'https://www.che168.com/china/benchi/#pvareaid=100943'
while True:
reponse=requests.get(url,headers=headler)
if reponse.status_code!=200:
break
selector=etree.HTML(reponse.text)
try:
next_ur = re.findall('href="(.*?)" class="page-item-next">下一页', reponse.text)[0]
url = "https://www.che168.com" + next_ur
car_list.append(url)
except IndexError:
continue
count+=1
if count>=10:
break
if __name__ == '__main__':
main()
save_data()
本次教程到此就结束了,一个简单的爬虫程序















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









