







为什么 Redis 比 MySQL 缓存快?
在一次课堂项目演示的过程中,老师提出了一个问题:“为什么要选择 Redis 作为缓存,而不是选择MySQL 缓存呢?Redis 的优势在哪?”
对于这个问题我一时间回答不出来,只是说了些 “Redis 是基于内存操作的,存储查询速率很快“ 之类的话,老师回应说 ”那 MySQL 缓存也是在内存操作的,为什么比不上 Redis 呢 “,这时我陷入了沉默。
课后我查找了一些资料,写出这篇文章,该篇文件从 MySQL 缓存 和 Redis 两个方面进行阐述,论证了 Redis 为什么 比 MySQL 缓存快这个问题。
由于查找资料较少,论证观点可能存在错误,望修改指正。
MySQL 缓存
MySQL 采用的缓存方式是 MYSQL Query Cache(MySQL 查询缓存)。
实现手段是:
对 查询语句 进行 hash 计算,然后把得到的 hash 值 与 hash 链表(初始状态为空)进行一次匹配。
如果匹配不成功,则将该 hash 值 作为新节点插入到 hash 链表中,并把 Query 结果集存放到 Cache 中,再将结果集的内存地址存放到对应的 hash 链表节点中;
如果匹配成功,则返回该 hash 值对应 Query 结果集所在的内存地址。
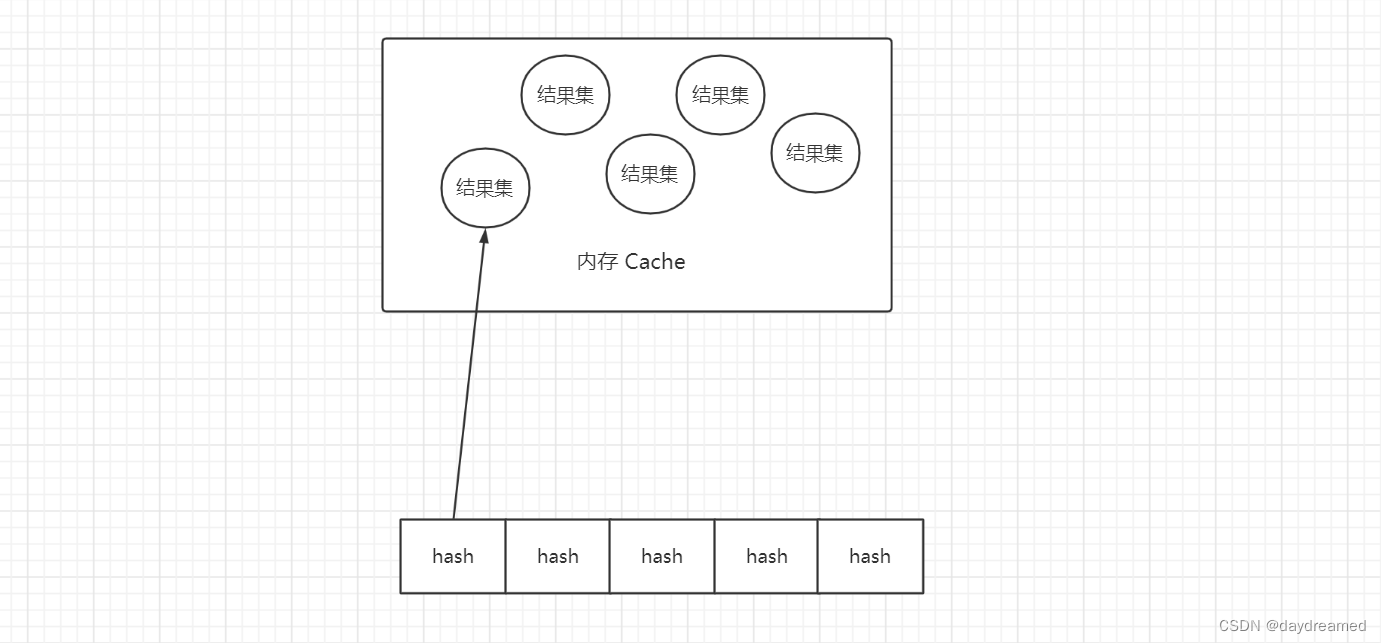
Query Cache 的缺点:
- Query Cache 是基于 select 语句的 Query 结果集进行缓存,这就造成了一个问题:缓存结构单一,我们没法去构建一个更高效的缓存结构。
- Query Cache 只能缓存 select 语句,不能修改缓存内容,这也导致了一个问题:如果数据库表的内容发生改动了,该缓存就作废了。
- Query Cache 是多线程的,因而在查询缓存前会加一个全局锁(global lock),这就产生了锁资源的开销,并且线程间的切换和上下文的切换也会造成额外资源的浪费。
Redis
Redis 的缓存方式:将目标数据以 K-V 键值对的形式存储在内存中。
Redis 的优点:
- Redis 基于 K-V 键值对的存储模式,查找的时间复杂度为 O(1) 。
- Redis 是单线程的,不用考虑加锁问题,减少了锁资源的消耗,并且也避免了线程间切换和上下文切换所造成的额外资源消耗问题。
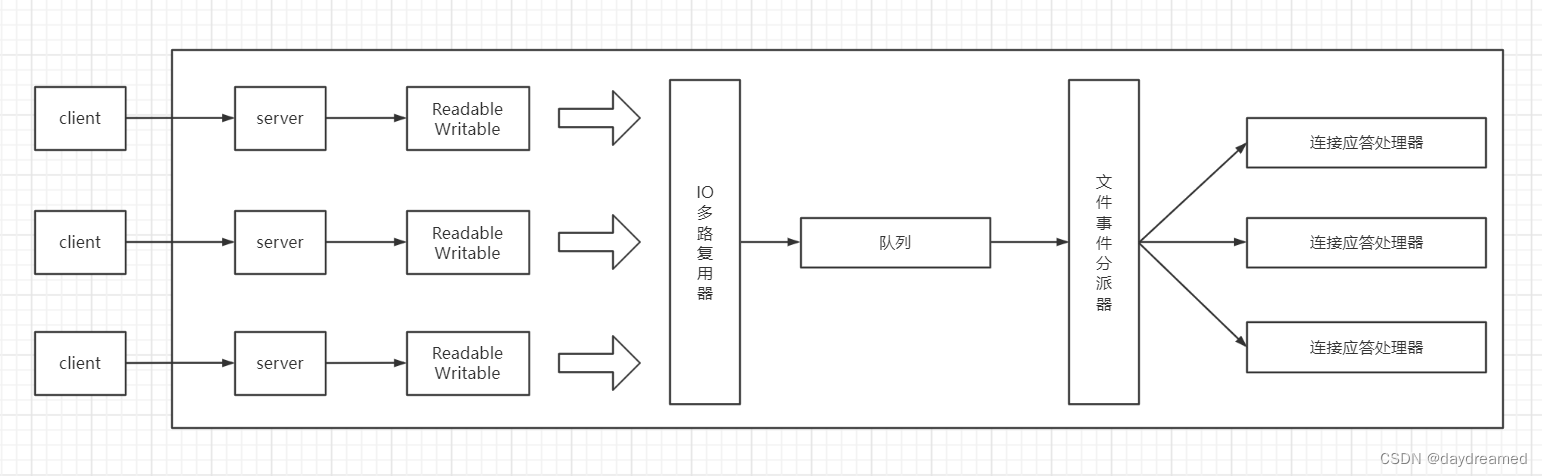
- Redis 采用了多路 IO 复用模型,使得单个线程可以高效的处理多个请求。















 641
641











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









