







组合预测法
前言
这篇博客建立在已经对回归分析、微分方程、灰色预测、时间序列、马尔科夫链、神经网络已经有了一定了解的基础上,来考虑如何在建模过程中增加Innovation,让自己的模型变得更高级、更有说服力。因为去年国赛尝到了组合评价模型的甜头,所以今年来浅浅总结一下组合预测模型,正所谓 “海纳百川、博采众长”。最后还是希望数模大佬在评论区或私信批评指正!不胜感激!
组合预测法就是采用适当的方法组合多个单项预测模型,对各种单项预测模型的预测效果进行综合处理,生成一个含有多个预测模型信息的总预测模型。
一、组合预测法技术
优势:
传统的预测方法在其各自的适用领域都表现出了良好的预测性能,但是,现实世界中事物的发展规律本身十分复杂,会受到很多随机因素的影响,且在发展过程中会有各种突发的变化,导致数据发展趋势产生很大的波动性。大多数传统预测模型的预测性能会下降很快,得不到令人满意的预测效果。组合预测模型可以灵活利用不同方法的优点,避免单一模型的缺点,有效提高预测性能。
组合预测方法可以对同一个问题,采用两种以上不同预测方法进行预测。它既可以是几
种定量方法的组合,也可以是几种定性方法的组合,但实践中更多的是利用定性方法与定量方
法的组合。组合的主要目的是综合利用各种方法所提供的信息,发挥各种预测方法的优点,尽可能地提高预测精度。
分类:
总结国内外的文献,组合预测技术包括两类:①模型组合法,即利用建模机制中的优势互补,将两种或多种不同的预测模型或方法结合起来产生一个新的模型或改进模型;组合后的模型具有新的结构,再输人原始数据得到预测结果。②结果组合法,即对几种不同的预测方法得到的预测结果,选取适当的权重进行加权平均,计算出它们的组合结果,以此作为最终的预测结果。这两种组合方法的区别在于一个是对模型内部的组合,一个是对结果的组合,而一般文献中提到的组合预测问题大多是对结果的组合,而模型的组合可以有具体的命名。
组合模型不仅研究相同或不同单独模型之间的组合,还可以将数据的前期处理、模型的结构优化及每个模型的参数选择、预测数据的后期处理技术构建到组合预测模型当中。
适用范围:
每种组合模型都有其适用的范围,比如基于权重的组合方法,对于数据有较强的适应性并具有稳定的预测性能,但是对权重的分配不能保证模型获得最佳的性能,需要额外的运算来优化权重。再比如基于数据预处理的组合方法,通过数据预处理过程可以帮助模型获得更高的预测精度,然而,对新的数据进行分解时,需要完善数学理论作为基础并且会耗费更多的时间;相对于权重组合模型,基于模型结构与参数优化的组食合方法应用比较广泛,通常该类方法的性能可以获得显著提高。但模型结构和参数的优化方法对其最终的预测性能会产生很大影响,且训练模型阶段的时间性能比较低;相应地,基于误差修正技术的组合方法可以降低模型的整体误差,然而,由于该类方法要耗费大量时间进行误差修正,所以相对于其他预测方法,该方法的时间效率没有优势。没有统一的组合方法在所有应用领域的预测度量中都表现出最好的预测性能,为了对特定领域内的数据进行更好地分析,应在避免选择不确定性的组合模型,而是根据特定的应用领域研究并建立性能更好的组合模型。
上述总结:YYSY,就题论题!
二、预测性能评价方法
2.1 精度指标
为了比较不同预测方法的精度,需要制定一套可行的评价指标体系来对预测效果进行全方位的综合性评价。
记
Y
1
,
Y
2
,
.
.
.
,
Y
n
Y_1,Y_2,...,Y_n
Y1,Y2,...,Yn为实际预测值,
Y
^
1
,
Y
^
2
,
.
.
.
,
Y
^
n
\hat{Y}_1,\hat{Y}_2,...,\hat{Y}_n
Y^1,Y^2,...,Y^n为预测值,单个预测误差为
e
t
=
Y
t
−
Y
^
t
e_t=Y_t-\hat{Y}_t
et=Yt−Y^t,衡量整体预测效果的指标有如下几种形式。
- 平均误差(ME)
M E = 1 n ∑ t = 1 n ( Y t − Y ^ t ) ME=\frac1n\sum_{t=1}^n(Y_t-\hat{Y}_t) ME=n1t=1∑n(Yt−Y^t) - 平均绝对误差(MAE)
M A E = 1 n ∑ t = 1 n ∣ Y t − Y ^ t ∣ MAE=\frac1n\sum_{t=1}^n|Y_t-\hat{Y}_t| MAE=n1t=1∑n∣Yt−Y^t∣ - 误差平方和(SSE)
S S E = ∑ t = 1 n ( Y t − Y ^ t ) 2 SSE=\sum_{t=1}^n(Y_t-\hat{Y}_t)^2 SSE=t=1∑n(Yt−Y^t)2 - 均方误差(MSE)
M S E = 1 n ∑ t = 1 n ( Y t − Y ^ t ) 2 MSE=\frac1n\sum_{t=1}^n(Y_t-\hat{Y}_t)^2 MSE=n1t=1∑n(Yt−Y^t)2 - 误差的标准差(SDE)
S D E = 1 n − 1 ∑ t = 1 n ( Y t − Y ^ t ) 2 SDE=\sqrt{\frac1{n-1}\sum_{t=1}^n(Y_t-\hat{Y}_t)^2} SDE=n−11t=1∑n(Yt−Y^t)2 - 平均绝对百分比误差(MAPE)
M A P E = 1 n ∑ t = 1 n ∣ Y t − Y ^ t Y t ∣ MAPE=\frac1n\sum_{t=1}^n|\frac{Y_t-\hat{Y}_t}{Y_t}| MAPE=n1t=1∑n∣YtYt−Y^t∣ - 均方百分比误差(MSPE)
M S P E = 1 n ∑ t = 1 n ( Y t − Y ^ t Y t ) 2 MSPE=\frac1n\sqrt{\sum_{t=1}^n(\frac{Y_t-\hat{Y}_t}{Y_t})^2} MSPE=n1t=1∑n(YtYt−Y^t)2
选择不同的指标可能会对不同的预测结果有不同的评价,较为常用的是MSE、MAE和MAPE.
2.2 样本外检验和样本内检验
建模过程中的参数估计一般都是根据某些样本得到的。当对预测模型精度进行检验时,不使用建模时估计参数用的样本,而采用其他样本进行检验的方法,称为样本外检验。而样本内检验则是使用原来估计模型参数的样本进行检验。显然,对于一个预测问题。衡量精度的指标要针对未来的预测值,对过去预测值的检验是没有意义的,而且进行样本内检验时往往会低估预测的误差值。这是因为模型的参数是由原先样本完全确确定的,对原先的样本一般都会有很高的拟合精度,但是对其他样本可能并不适用,而且还容易易发生过拟合现象。一种解决方法是将过去到现在的观测值作为样本来确定模型,而使用实时更新的观测数据进行样本外的检验。这种方法常被应用于预测理论的研究中。而对一般的预测模型精度的检验,则是预先保留一部分的预测数据作为样本外检验的数据,用其他数据进行模型的估计。
2.3 动态时间弯曲距离评价方法
(改进距离度量)
动态时间弯曲距离(Dynamic Time Warping,DTW)是一种更有效的检测方法,可以对时间序列进行更有效的距离度量。采用欧氏距离的传统方法或其他一些变化的方法度量时间序时,只考虑到相应点的距离,并没有考虑序列之间的相似性影响,得到的度量结果不能准确映序列之间的变化。DTW方法将形状匹配思想加人到距离度量当中,可以有效度量在时间轴上异相的序列。这种灵活的特性,使得DTW泛地应用于气象、医学和金融领域,能够有效地解决时间序列匹配、生物信息对比和语音识别问题。
DTW是一种典型的通过优化问题来评价模型性能的方法,其使用时间规整函数来描述个时间序列之间的对应关系,将求解得到的规整函数最小的匹配累计距离作为两时间序的距离度量。算法具体定义如下。
假设有两个样本序列,分别标记为
X
X
X和
Y
Y
Y,且
X
=
[
x
1
,
x
2
,
…
,
x
n
]
,
Y
=
[
y
1
,
y
2
,
…
.
y
n
]
X=[x1,x_2,…,x_n],Y=[y_1,y_2,….y_n]
X=[x1,x2,…,xn],Y=[y1,y2,….yn],为了使找到的子序列部分在所在度量方法中距离最小,序列时间点之间的对应关系可以表示
f
(
k
)
=
(
f
x
(
k
)
,
f
y
(
k
)
)
f(k)=(f_x(k),f_y(k))
f(k)=(fx(k),fy(k)),其中
f
x
=
(
1
,
2
,
3
,
…
,
m
)
,
f
y
=
(
1
,
2
,
3
,
…
,
n
)
,
k
=
1
,
2.3
,
…
.
f_x=(1,2,3,…,m),f_y=(1,2,3,…,n),k=1,2.3,….
fx=(1,2,3,…,m),fy=(1,2,3,…,n),k=1,2.3,….。两个序列的累计距离可以表示为
d
f
(
x
,
y
)
=
∑
k
=
1
T
d
(
f
x
(
k
)
,
f
y
(
k
)
)
d_f(x,y)=\sum_{k=1}^Td(f_x(k),f_y(k))
df(x,y)=k=1∑Td(fx(k),fy(k))DTW的核心工作就是要计算出序列X中的点与序列Y中的点之间的对应关系,并找出对应关系中最相似的部分。由累计距离计算公式可以计算出距离矩阵,同时考虑时间规整和距离度量两方面的因素,采用动态规划技术依次比较两个不同的子序列,求出序列中最小的累计距离即为DTW。表达式为
D
T
W
(
X
,
Y
)
=
arg min
f
d
f
(
X
,
Y
)
DTW(X,Y) =\argmin_f d_f(X,Y)
DTW(X,Y)=fargmindf(X,Y)计算时距离除采用欧氏距离外,还可以采用对称的Kullback-Leibler测度方法。通过DTW计算公式可以生成累计距离矩阵,而生成的过程就是一个典型的动态规划的过程,最后两个对比的序列距离就是累计距离矩阵的右下角的值。
2.4 二阶预测有效度评价方法
现有问题:
传统的组会模型的建立和评估主要采用最小平均绝对误差、MSE和MAPE等指标,但这些指标知识在时间序列上对应的点之间比较预测的准确性,并不能很好地评估组合模型的有效性。针对不同序列中量纲不一致的问题,直接对比会损失很多有用的评估信息。
优势:
二阶预测有效性(Two-Order Forecasting Validity,TOFV)评价方法有效地解决了此问题,它同时考虑了模型预测精度分布的偏差和峰度,是一种更合理的性能评估方法。
方法论:
假设有真实的事件序列
y
t
(
t
=
1
,
2
,
3
,
.
.
.
,
N
)
y_t(t=1,2,3,...,N)
yt(t=1,2,3,...,N),组合模型中有M个子模型参与预测,且
y
^
i
t
\hat{y}_{it}
y^it,代表第
i
(
i
=
1
,
2
,
3
,
.
.
.
,
m
)
i(i=1,2,3,...,m)
i(i=1,2,3,...,m)个子模型在
t
t
t时刻的预测值,
e
i
t
e_{it}
eit代表第
i
i
i个模型在第
t
t
t时刻的预测误差,误差函数定义如下:
e
i
t
=
{
−
1
(
y
t
−
y
^
i
t
/
y
t
)
<
1
(
y
t
−
y
^
i
t
/
y
t
)
−
1
≤
(
y
t
−
y
^
i
t
/
y
t
)
≤
1
1
(
y
t
−
y
^
i
t
/
y
t
)
>
1
e_{it}=\begin{cases} -1 & (y_t-\hat{y}_{it}/y_t)\lt 1\\(y_t-\hat{y}_{it}/y_t) & -1\le (y_t-\hat{y}_{it}/y_t)\le 1\\ 1 & (y_t-\hat{y}_{it}/y_t)\gt 1 \end{cases}
eit=⎩
⎨
⎧−1(yt−y^it/yt)1(yt−y^it/yt)<1−1≤(yt−y^it/yt)≤1(yt−y^it/yt)>1假设
A
i
t
A_{it}
Ait定义为第i个模型在t时刻的精度且满足
A
i
t
=
1
−
∣
e
i
t
∣
A_{it}=1-|e_{it}|
Ait=1−∣eit∣,则TOFV定义为
M
=
E
(
A
)
(
1
−
σ
(
A
)
)
=
∑
t
=
1
N
Q
t
(
1
−
∣
∑
i
=
1
m
l
i
e
i
t
∣
)
{
1
−
∑
t
=
1
N
Q
t
(
1
−
∣
∑
i
=
1
m
l
i
e
i
e
∣
)
−
[
∑
t
=
1
N
Q
t
(
1
−
∣
∑
i
=
1
m
l
i
e
i
e
∣
)
]
2
}
1
2
M=E(A)(1-\sigma(A)) \\ =\sum_{t=1}^NQ_t(1-|\sum_{i=1}^ml_ie_{it}|)\{1-\sum_{t=1}^NQ_t(1-|\sum_{i=1}^ml_ie_{ie}|)-[\sum_{t=1}^NQ_t(1-|\sum_{i=1}^ml_ie_{ie}|)]^2\}^{\frac12}
M=E(A)(1−σ(A))=t=1∑NQt(1−∣i=1∑mlieit∣){1−t=1∑NQt(1−∣i=1∑mlieie∣)−[t=1∑NQt(1−∣i=1∑mlieie∣)]2}21式中:
Q
t
Q_t
Qt为
m
m
m种方法在
t
t
t时刻的离散概率分布;
E
(
A
)
E(A)
E(A)表示组合模型预测精度的数学期望;
σ
(
A
)
\sigma(A)
σ(A)表示组合模型预测精度的标准差;
l
i
l_i
li为第
i
i
i种单项预测方法的权重;
M
M
M为模型的二阶预测有效度,其值越接近1,组合模型的预测效果越好。
2.5 预测模型的准确性
预测模型的准确率不仅和误差度量方法有关,而且和给定的数据划分方法也有密切的关系。评估预测模型准确率常用的方法有保持法、随机子抽样法、自助法和交叉确认法等。
1. 保持法
保持法是评估模型准确率常用的方法。将给定的数据按照数据的特征随机划分为训练集和检验集两部分。一般随机分配 2/3 作为训练集,其余 1/3 作为检验集。以训练集对所需的模型进行训练,模型的准确率以检验集进行估计。这种估计是悲观的,因为训练集只是占整体数据的一部分,不能代表所有样本的特性。
2. 随机子抽样法
随机子抽样法是一种变异的保持方法,使用 k k k次保持的方法分别对模型进行估计,并取预测模型精度的平均值作为模型的最终准确率。这种方法会消耗更多的计算资源,但可以有效评价模型的准确率。
3. 交叉确认法
交叉确认法通常分为两种方法,分别为k折交叉确认法和留一法。 k k k折交叉确认法:数据被划分为大致相等、互不相交的 k k k个子集 { D 1 , D 2 , … , D t } \{D_1,D_2,…,D_t\} {D1,D2,…,Dt},依次使用 D i D_i Di作为检验集,剩下的其他子集作为训练集用于训练并导出模型,以 D i D_i Di进行验证。也就是说,第一次训练集为 { D 1 , D 2 , … , D t } \{D_1,D_2,…,D_t\} {D1,D2,…,Dt},得到第一个模型,检验集为 D 1 D_1 D1;第二次迭代训练集为 { D 1 , D 2 , … , D t } \{D_1,D_2,…,D_t\} {D1,D2,…,Dt},检验集为 D 2 D_2 D2,如此迭代下去直到每一个子集都用于检验一次。将k次迭代平均精度作为模型的准确率。
留一法:是 k k k折交叉确认法的一种特殊情况。 k k k值的大小与原始样本的个数相同,每次第 i i i个样本作为检验集,因为是一个样本,所以称为留一。通过 k k k次迭代,最终取k次精确度的平均值作为准确率。
4. 自助法
从给定的数据中进行有放回均匀抽样,使每个样本均有等可能的概率被下一次抽中加到训练集当中。通常采用一种称为0.632的自助法,假设数据集中的样本个数为d,每次数据集中样本被选中的概率为
1
/
d
1/d
1/d,被选中的率为
1
−
1
/
d
1-1/d
1−1/d次选择中,一样本没有被选中的概率为
(
1
−
1
/
d
)
d
(1-1/d)^d
(1−1/d)d,如果
d
d
d趋向于无穷大,那么未被选中的概率近似为0.368,而被选中的概率为0.632。所以模型的总体准确率可用如下公式进行计算:
A
c
c
(
M
)
=
∑
i
=
1
d
[
0.632
…
A
c
c
(
M
i
)
t
r
a
i
n
s
e
t
+
0.368
…
A
c
c
(
M
i
)
t
e
s
t
s
e
t
]
Acc(M) = \sum_{i=1}^d[0.632…Acc(M_i)_{train_set}+0.368…Acc(M_i)_{test_set}]
Acc(M)=i=1∑d[0.632…Acc(Mi)trainset+0.368…Acc(Mi)testset]式中:train_set 代表训练集;test_set代表检验集;
A
c
c
(
M
i
)
Acc(M_i)
Acc(Mi)代表模型的整体准确率。自助法耗费大量的计算资源,但对于规模小的数据集,可以获得很好的估计效果。
三、模型组合法
组合预测的本质就是将各种单项预测模型看作代表不同信息的片段,通过信息的集成,散单个预测特有的不确定性和减少总体的不确定性,从而提高预测精度。但在实际应用中,测问题往往是一个动态随机的非线性过程,单纯利用一种特定的预测方法进行预测具有片性。要提高预测的效果和精度,应将定性和定量预测、线性和非线性预测、静态和动态预测方法相结合。下面介绍几种模型组合预测法。
3.1 灰色马尔可夫链
(改进趋势平稳性和波动性的处理方法)
适用场景与优劣分析:
马尔可夫预测法作为一种概率预测的方法,可以有效地处理含有一定随机因素的问题使用马尔可夫预测法的前提是待处理的数据要较为平稳。这在实际中预测对象都具有一定的增长或趋势,并不能满足这一前提。灰色马尔可夫预测模型则可以克服这些问题。它将灰色系统理论与马氏链理论相结合,利用灰色预测曲线来揭示事物发展的总体趋势和规律,利用马氏链预测来体现事物的随机波动性,确定其中的微观波动规律,实现两个预测模型的优势互补。
思想:
建立灰色马尔可夫预测模型的基本思想是:先建立灰色预测模型,以获得预测对象的变化挡势;然后去除预测对象的变化趋势,便可得到只含有随机因素的数据;再对这些数据建立马氏链预测模型,得到这些随机因素的状态变化规律;最后再加上去掉的趋势变化,还原出真正的预测结果。
方法论:
先建立灰色预测模型,求出预测曲线
x
^
(
k
)
\hat{x}(k)
x^(k),再以平滑的预测曲线
x
^
(
k
)
\hat{x}(k)
x^(k)为基准,划分出若干动态的状态区间。根据落入各状态区间的数据点,计算出马尔可夫转移概率矩阵,按照马氏链的预测方法来预测未来的状态,知道未来的状态即可得出预测的区间值(若需要进行点预测,则可取区间中点),最终就得到更符合实际情况的预测结果。
在应用灰色马尔可夫预测模型时,状态的划分与预测正确与否有很大关系。应根据数据序列的特点,采用不同的划分方法。一般划分越多,结果越精确,但若数据样本较少,则只能划份出较少的状态以保证预测的准确性。
3.2 灰色线性回归预测模型
(改进异常值的处理方法)
适用场景与优劣分析:
灰色预测主要适用于单一的指数增长的模型,对序列数据出现异常的情况很难加以考虑,而时序线性回归分析法根据事物发展的连续性相等原理未来看是的继续,在各种条件相对稳定的情况下,对今后发展情况进行预测,短期预测可以取得较好结果,但长期预测往往效果不佳。因此可以考虑运用灰色灾变预测方法来预测灾变点及其市变值,而在非灾变点处采用线性回归方法预测,这样就由灰色预测和回归预测组合而成了新的方法,能够较好地克服GM(1.1)模型和线性回归的缺陷,提高预测精度。
思想:
灰色线性回归预测模型主要是针对含有灾变点的预测对象。其思路是先通过灰色灾变模型预测出灾变点的位置(即灾变发生的日期),再对这些灾变点上的值建立灰色预测模型,计算出未来灾变点的灾变值;而对非灾变点,可以建立回归模型进行预测。总的来说,灰色线性回归预测模型就是通过灰色预测来处理异常值,用线性回归模型处理非异常值通过这样的组合方式可以获得更高的预测精度。但应注意,对于非异常值,需要谨慎地选择出合适的回归模型。当非异常值的分布较为平稳时,可以建立统一的整体回归模型;而当非异常值也随相邻的异常值呈线性规律变化时,则可以建立以异常值为分段点的线性回归模型。
方法论:
先从数据中找出灾变点,一般可以通过绘制数据的折线图,找出数据中跳跃度较高的数值作为灾变值序列,并记录下灾变的日期点。**根据所记录的灾变点和灾变值分别建立GM(1.1)模型,预测出下一个或几个时刻的灾变点和灾变值。然后再由灾变值之外的点的具体分布情况,建立合适的线性回归模型。**在预测时,如果预测日期点是根据改进灰色模型预测出的灾变日期点,则它的值是通过灾变预测函数计算出的灾变值;如果预测日期点不是根据改进灰色模型预测出的灾变日期点,则它的值是通过线性回归曲线计算出的函数值
3.3 ARIMA神经网络混合预测模型
(改进数据非线性结构的处理方法)
适用场景与优劣分析:
ARIMA模型与神经网络模型的结合,充分发挥了两种模型各自的独特性和优势,通过对线性部分和非线性部分分别建立ARIMA模型和神经网络模型,再将两种模型组合,提高了预测的精度,并且得到的预测结果也更加符合实际。
思想:
ARIMA 是线性时间序列预测建模中最为经典的方法,对于大多数预测问题都能给出很好的结果。但是当需要处理的问题不是完全的线性关系时,将会出现一定的偏差,这就需要建立非线性的时间序列模型,而ANNs恰好可以弥补这些缺陷;因此可以将 ARIMA 预测方法和神经网络预测方法组合,以发挥各自的优势,提高非线性时间序列的预测精度。
方法论:
对于一个时间序列
{
y
t
}
\{y_t\}
{yt},一般可以认为它是由一个线性自相关部分L,和一个非线性部分
N
N
N,组成,即
y
=
L
+
N
y=L+N
y=L+N,式中
L
L
L和
N
N
N,根据时间序列数据进行估计。
①对数据进行预处理。经过预处理后的数据,能够缩短模型预测的时间,提高预测精度。用于ARIMA预测模型的数据需先经过平稳性处理,即将非平稳序列变成平稳性序列,再对平稳序列建模;而对于神经网络模型,需要先对数据进行归一化处理,这样可避免训练过程计算的溢出,并且能够加快训练过程的收敛速度。
② 利用 ARIMA 对线性部分建模,线性模型的残差只包含原序列中的非线性关系。令为
t
t
t时刻线性模型的残差,则
e
=
y
t
−
L
^
t
e=y_t-\hat{L}_t
e=yt−L^t,式中
L
^
t
\hat{L}_t
L^t为根据 ARIMA建模的
t
t
t时刻的预测值。
③对残差序列
{
e
t
}
\{e_t\}
{et}建立人工神经网络模型,可以处理其中的非线性关系。对于
n
n
n个输节点的人工神经网络模型,残差计算为
e
t
=
f
(
e
t
−
1
,
e
t
−
2
,
…
,
e
t
−
n
)
+
ϵ
t
e_t=f(e_{t-1},e_{t-2},…,e_{t-n})+\epsilon_t
et=f(et−1,et−2,…,et−n)+ϵt式中为随机误差,非线性函数
f
f
f通过神经网络来逼近,得到的t时刻的残差预测结果为
N
^
t
\hat{N}_t
N^t,。
④ 将两种模型组合,即
y
^
t
=
L
^
t
+
N
^
t
\hat{y}_t=\hat{L}_t+\hat{N}_t
y^t=L^t+N^t。
综上所述,针对混合系统所提出的方法包括两个步骤:首先,建立 ARIMA 模型来分析问题的线性部分;其次,对ARIMA模型的残差建立神经网络模型。由于ARIMA模型不能描述数据的非线性结构,因此线性模型的残差将会为非线性,而神经网络模型正好可以用于 ARIMA模型误差项的预测。将 ARIMA与神经网络模型组合,充分发挥了两种模型各自的优势,通过对线性部分和非线性部分分别建立模型,再将预测结果组合,可以改进模型的预测精度。
四、结果组合法
4.1 非最优组合模型预测方法
- 算术平均法
- 误差平方和和倒数法
4.2 最优组合模型预测方法
- 以误差平方和为目标函数的线性组合预测模型
- 可变权重的组合预测模型
- 以绝对(相对)误差和为目标函数的线性组合预测模型
- 以误差绝对值的最大值为目标函数的线性组合预测模型
- 加权调和和平均组合预测模型
- 加权几何平均组合预测模型
五、基于数据预处理的组合预测模型
数据中包含噪声、随机波动等不确定因素,这类组合模型的思想是由不同的模型来处理数据预处理部分和数据预测部分。组合模型中的预测模块主要负责数据拟合预测工作,而预理模块主要进行辅助工作,如数据分解或数据过滤等。在数据的预处理部分,将非线性时间序列数据分解成相对更加稳定和规则的子序列来实现预测模型的初步处理过程,使得模型可以过滤与预测结果相关性很小或不相关的特征,减少数据的冗余特征。预处理可以提高原始数据的质量,提升预测模型的性能。同时,预处理可以降低时间复杂度、减轻模型的计算负担。基于数据预处理技术的组合模型框架如图12.2所示。
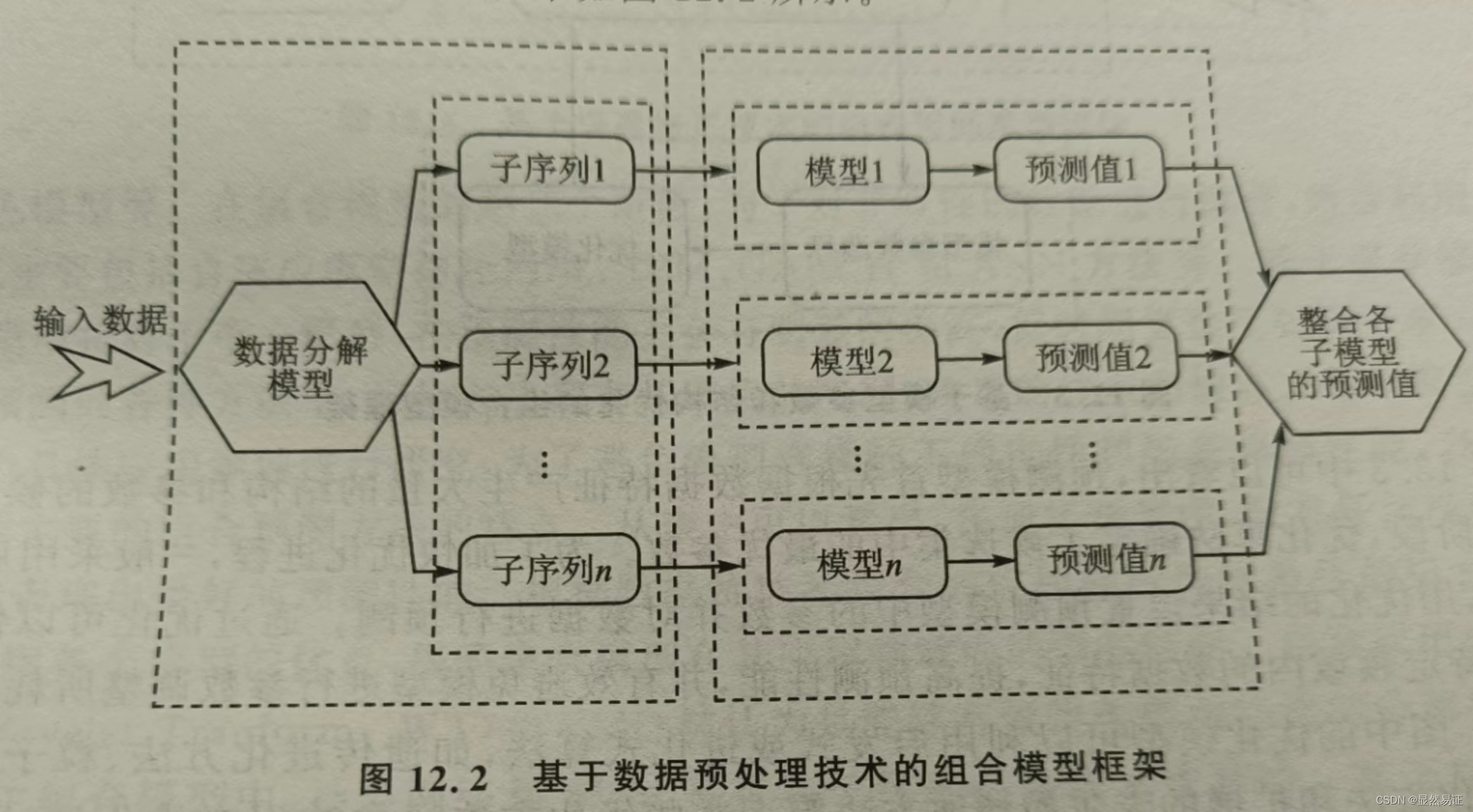
图12.2中,数据通过分解模型被拆分为更容易分析的子序列,各子序列分别对应不同的模型,将各子模型的预测值进行整合得到最终预测值。通过数据分解模型得到更稳定的子字列,其所包含更多相似特征的信息量可以提高数据的质量,并避免过多的计算负担,以提高则性能。在组合模型的数据预处理部分,可采用基于小波分解的处理模型,其利用小波对连据的分解能力将数据按频率分解为几个级别,把高频率的子序列与低频率的子序列分开,并结合统计学习、机器学习模型进行组合,来提高预测性能。也可用基于经验模态分解(Empirical Mode Decompostion,EMD)的方法,将复杂的数据分解为有限个本征模函数(In trinsic Mode Functions,IMF),使分解出来的IMF分量包含不同的局部特征信号。此外,基于过滤技术的数据预测处理方法还有马氏链方法(MarkovChain,MC)、主成分分析方法(Principal Component Analysis,PCA)和卡尔曼滤波方法等,通过对影响预测精度的信息进行过滤以提高预测性能。
六、基于模型参数和结构优化的组合预测模型
模型的结构和模型中的参数在进行预测时都是是不确定的,不同参数和结构对预测的结果会产生很大的影响。基于模型参数和结构优化的经组合预测模型在大量候选参数和不同结构组合方案中测试模型的预测性能,通过训练数据对所优化或选择的参数和结构进行验证,将最优的参数和结构用于预测,以提高模型的预测性能。 根据以上过程,说明优化的结果对预测性能做出了相当大的贡献。此外,在优化阶段通常采用启发式的方法对模型参数和结构的候选集进行选优,并将候选结果作为最终模型的设定标准。 基于模型参数和结构优化的组合模型框架如图12.3所示。
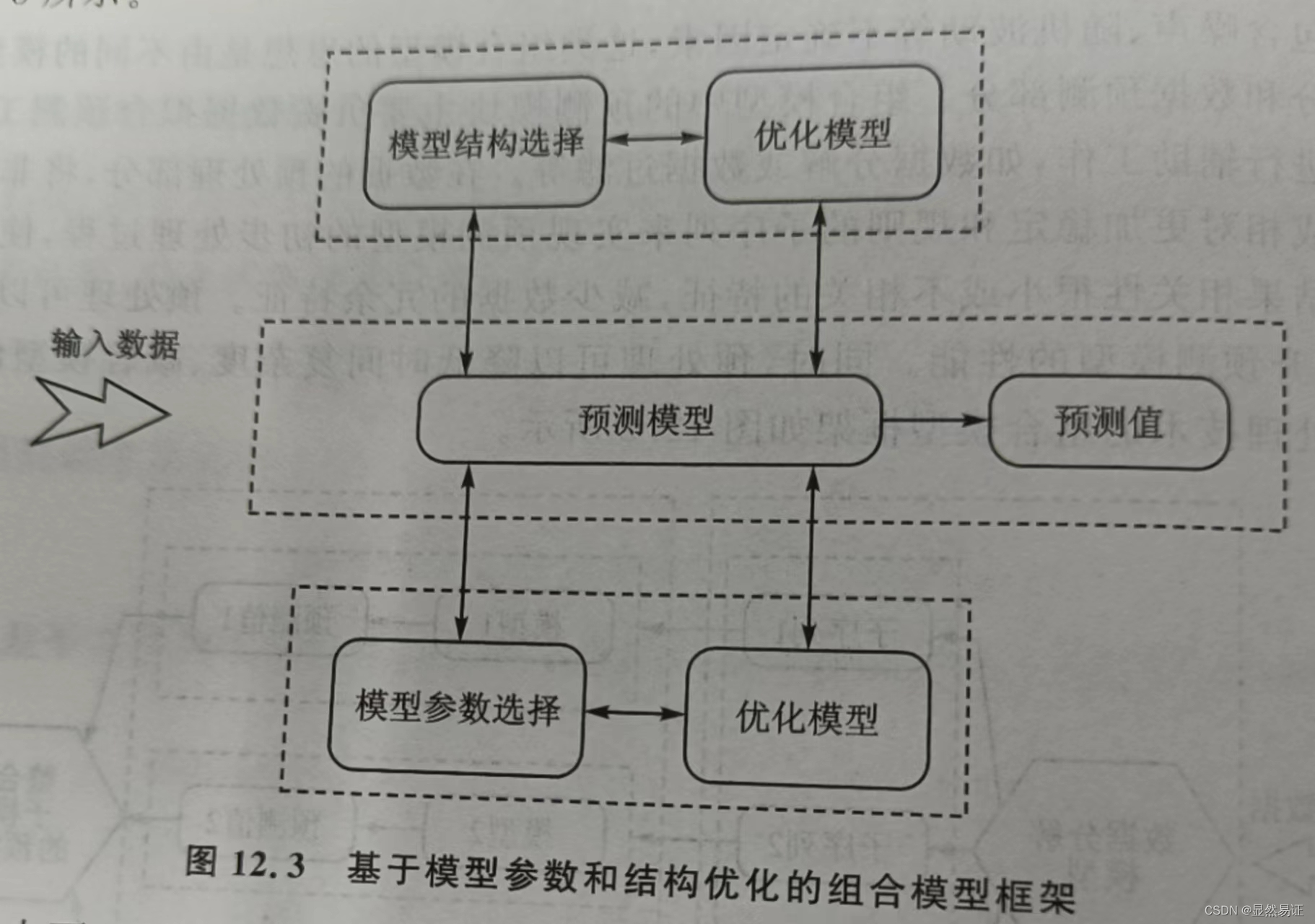
从图12.3中可以看出,预测模型首先根据数据特征产生大量的结构和参数的候选集,在
模型训练阶段,优化算法确定了候选集中的最优参数。 为了加快优化进程,一般采用启发式搜
索的方法,用优化的结果设置预测模型中的参数并对数数据进行预测。通过优化可以使模型更好地拟合特定领域内的数据特征,提高预测性能,并有效避免模型进行参数调整所耗费的大量计算时间。图中的优化模型可以利用启发式或进化式式算法,如遗传进化方法、粒子群优化方法、差分进化方法和扩展的卡尔曼滤波方法等。这些优优化方法通常被用来优化如神经网络的结构和权重、SVM模型的参数、ARIMA模型的参数、脊神经网络(Ridgelet Neural Network, RNN)的结构与参数等。将数据预处理方法和模型参数优化方法结合建立新的组合预测模型,可以更好地适应参数选择,从而提高预测精度。
七、基于误差修正技术的组合预测模型
一模型的预测结果通常是对数据整体发展趋势的估计,在大多数时间内预测值会过高或过低,有可能在某种程度上对预测结果产生负面影响。为了解决上述问题,可以采用基于误修正技术的组合预测模型。首先,该方法通过对数据特征的分析,选择能够合理表达数据发趋势的模型对数据进行预测;然后用观测值减去预测值来计算当前模型的预测残差,将预残差作为分析的对象;之后,通过对残差进行分解、转换等操作得到更容易分析的子序列,并选择相应的模型进行拟合;最后,将修正的预测残差与上一步的预测值进行合并,产生最终的预测值。基于误差修正技术的组合预测模型的目的是,通过残差分析来提高预测的准确性,其框架如图12.4所示。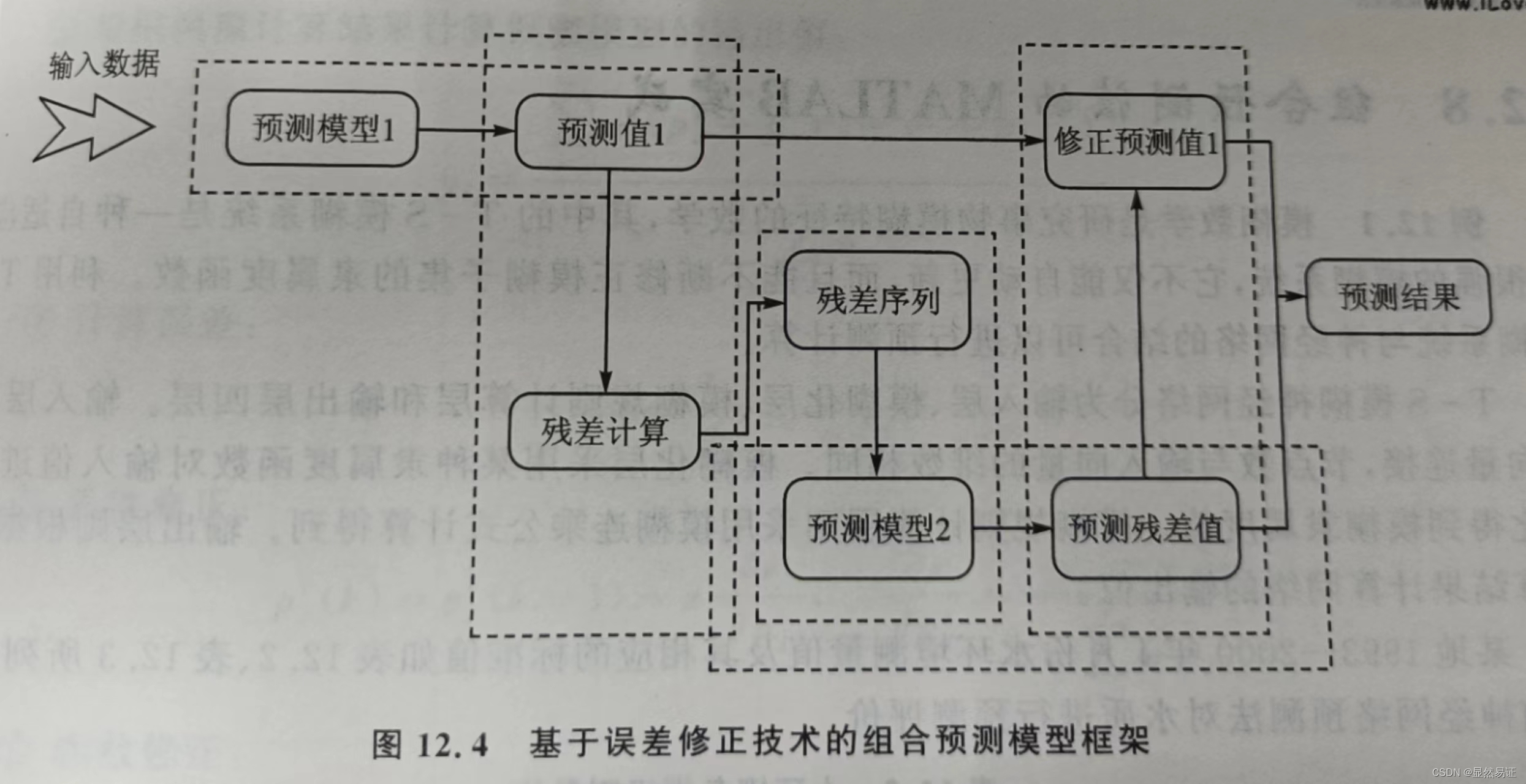
在图12.4中,首先输入的数据通过预测模型1获得预测值1和残差,将残差序列进行分析转换后作为预测模型2的输入数据对残差进行预测;然后通过预测残差值来修正每一个时间点的预测值1,根据修正值和残差预测值获得最终的预测结果。组合模型的第一阶段,通常利用对线性数据拟合良好的模型和卡尔曼滤波技术,如ARIMA模型、ANN模型、逻辑回归模型和灰色模型等。在组合模型的第二个阶段,为了对非线性的数据进行拟合,通常利用机器学习方法,主要包括自适应模糊神经网络、SVM、GARCH和ANN方法等。基于误差修正技术此书的组合模型相对于单一模型,在预测性能上会有明显的提高,但时间复杂度要高于单一模型。
**在预测的各种方法中,每种方法都有其适用的范围、各自的优点和缺点。**每个模型通常都是对某个具体应用领域进行研究,为了避免模型选择的不确定性和提高预测性能,表12.1列出了几种主要的组合预测方法的特点。从表中可以看出,在现实预测中,没有任何模型在所有方面都能表现出最好的预测性能。根据数据特性和拟合的应用领域选择最佳的组合模型,能有效地利用各个模型的优点,提高组合模型在其应用领域内的预测性能。在数据预处理中,小波变换(Wavelet Tranform,WT)和EMD被认为是能够有效改善模型性能的分解处理方法。在误差修正组合模型中,神经网络和SVM是有利于促进提高预测质量的。基于权重的组合方法一般在预测周期比较长的预测任务中可以获得合理的结果。此外,基于模型结构和参数优化的组合方法可以获得更高的预测精度。然而与单一预测方法相比,组合方法通常计算时间效率比较低,需要消耗更多的计算资源。

参考
[1] 《预测理论与方法及其MATLAB实现》许国根,贾瑛,黄智勇,沈可可
[2] 《数学建模算法与应用(第三版)》司守奎,孙玺菁
[3] 数学建模-预测模型总结 博主:延锋L

















 1109
1109

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









