







 本文详细介绍了数据挖掘的概念、用途及常用方法论,包括分类、聚类、回归和关联问题。强调了数据挖掘在业务理解、数据理解、数据准备、建模、评估和部署等步骤中的重要性。还提到了Python数据结构、数据处理工具和数据学习资源。文章探讨了如何处理干净数据、选择合适算法及评估模型效果,并提醒关注模型在实际业务中的应用。
本文详细介绍了数据挖掘的概念、用途及常用方法论,包括分类、聚类、回归和关联问题。强调了数据挖掘在业务理解、数据理解、数据准备、建模、评估和部署等步骤中的重要性。还提到了Python数据结构、数据处理工具和数据学习资源。文章探讨了如何处理干净数据、选择合适算法及评估模型效果,并提醒关注模型在实际业务中的应用。
数据挖掘
前言
笔记来源于系统学习以下课程:
B站最完整系统的Python数据分析-数据挖掘教程,72小时带你快速入门,轻松转行(月入10W+数据分析师强烈推荐!)
数据挖掘01——什么是数据挖掘,能解决什么问题
-
什么是数据挖掘?
数据挖掘——寻找数据中隐含的知识,并用于产生商业价值 -
为什么要做数据挖掘?
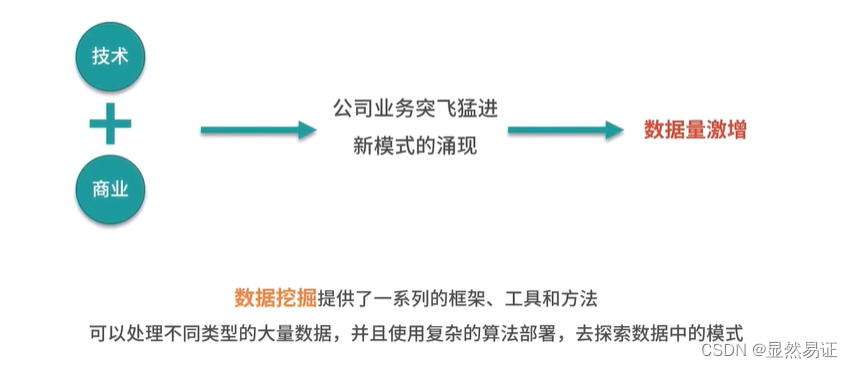
-
数据挖掘的产生动因?

-
数据挖掘有什么用处?
(1)分类问题——对已知类别的数据进行学习,为新的内容标注一个类别(如:新闻分类等)
(2)聚类问题——类别预先不清楚,比较适合一些不确定的类别场景(如:树叶类别聚类)
(3)回归问题——最大特点:生成的结果是连续的(如:回归预测房价)
(4)关联问题——最常见的一个场景:推荐(如:购物推荐图)
- 数据学习也是有方法论的!
数据挖掘经过了数十年的发展和无数专家学者的研究,有很多人提出了完整的流程框架
应用最多的方法论:
CRISP-DM(Cross-industry Standard Process for Data Mining,跨行业数据挖掘标准流程)
- 数据挖掘怎么做?
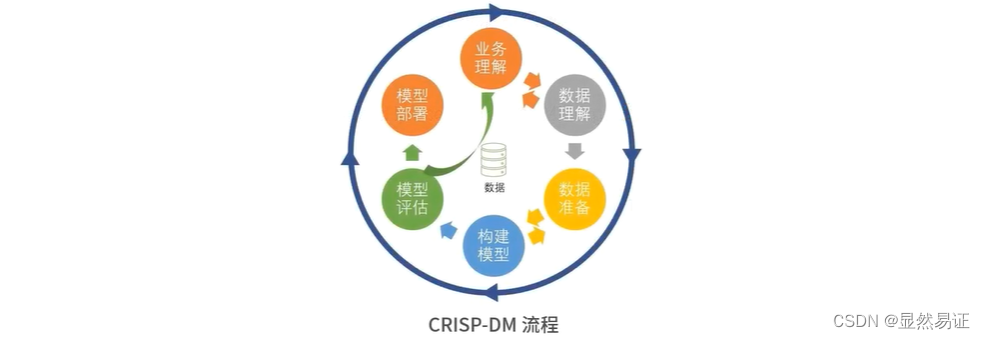
-
业务理解(Business Understanding)—— 理解你的数据挖掘要解决什么业务问题

必须从商业或者从业务的角度去了解项目的要求和最终目的
去分析整个问题涉及的资源、局限、设想,甚至是风险、意外等情况
从业务出发,到业务中去 -
数据理解(Data Understanding)

数据理解阶段的重点:
在业务理解的基础上,对掌握的数据要有一个清晰、明确的认识
注意:数据理解和业务理解是相辅相成的 -
数据准备(Data Preparation)

数据准备是基于原始数据,去构建数据挖掘模型所需的数据集的所有工作,包括数据收集、数据清洗、数据补全、数据整合、数据转换、特征提取等一系列动作。 -
构建模型(Modeling)
也叫做训练模型,重点解决技术方面的问题
选用各种各样的算法模型来处理数据,让模型学习数据的规律,并产出模型
如果有多重技术要适用,在这一任务中,对于每一个要适用的技术要分别对待
比如:SVM算法只能输入数值型的数据 -
模型评估(Evaluation)
模型的效果如何,能否满足业务需求
需要适用各种评估手段、评估指标甚至是让业务人员一起参与进来,彻底地评估模型
在评估之后会有两种情况:
(1) 评估通过,进入到上线部署阶段
(2) 评估不通过,要反过来再进行迭代更新 -
模型部署(Deployment)
解决一些实际的问题,如:
长期运行的模型是否有足够的机器来支撑,数据量以及并发程度会不会造成部署的服务出现问题
-
数据挖掘02——Python的数据结构和基本用法
这部分直接跳过啦~
数据挖掘03——工欲善其事必先利其器 扩展包与Python环境
这里关于安装Anaconda的安装和配置就跳跳跳过啦~
dir() # 查看模块中所包含的工具
help() # 展示模块中所有方法的说明
标准库:

第三方库——基础模块:


深度学习平台:

数据挖掘04——数据学习网站
数据挖掘05——数据挖掘的具体步骤
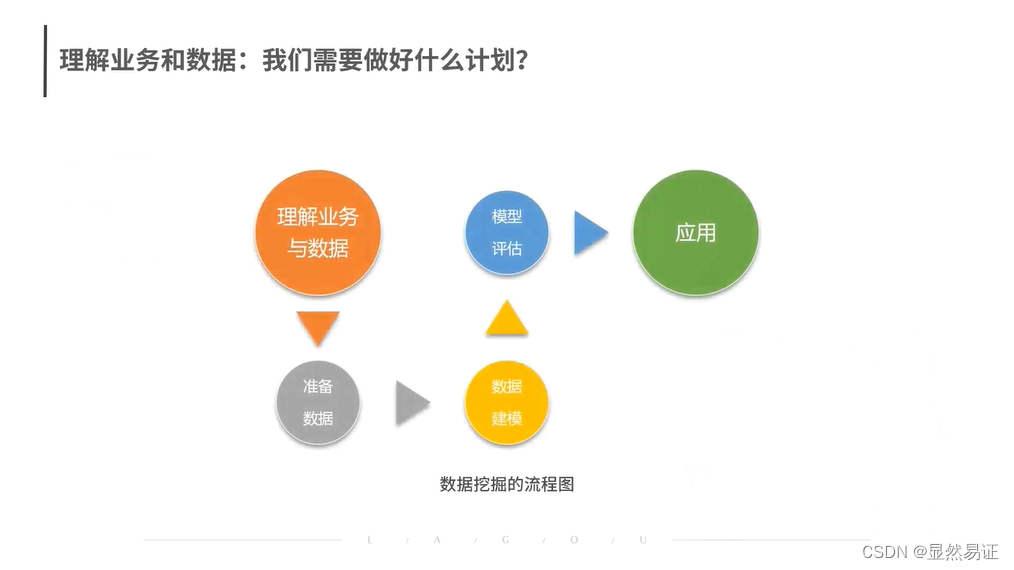

数据挖掘06——如何处理出完整干净的数据?
-
找到数据
需要掌握一些数据库的适用技巧
关系型数据库MySQL、大数据使用的Hbase、HIVE、搜索引擎数据库ES、内存数据库Redis
图数据库,如NEO4J或者JanusGraph等
还要与各部分协商以获取数据 -
数据探索
要对数据进行分析、预处理以及转换等基础工作
以构建出更加贴合你所要预测结果的特征
大牛把这个环节叫做数据变多或者数据升维 -
数据清洗
处理扩展后的数据、解决所发现的问题,同时又要顾及处理后的数据是否适合应用于下一个步骤-
缺失值的处理
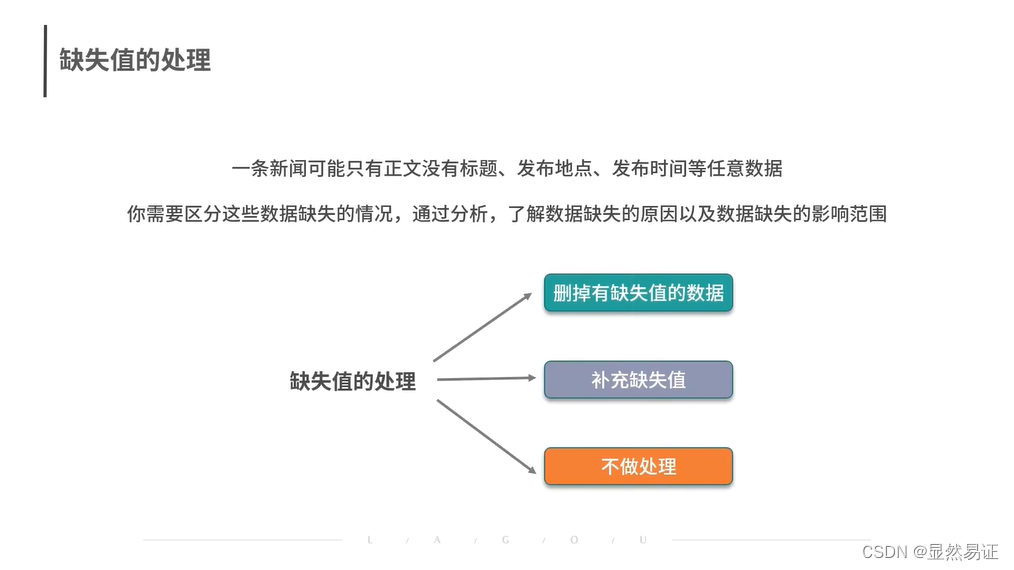
-
异常值的处理


-
数据偏差的处理


-
数据标准化

-
特征选择


-
构建训练集和测试集(有些需要验证集)


-
-
思想准备

数据挖掘07——数据建模:该如何选择一个适合我需求的算法?
建议观看视频 数据建模:该如何选择一个适合我需求的算法?
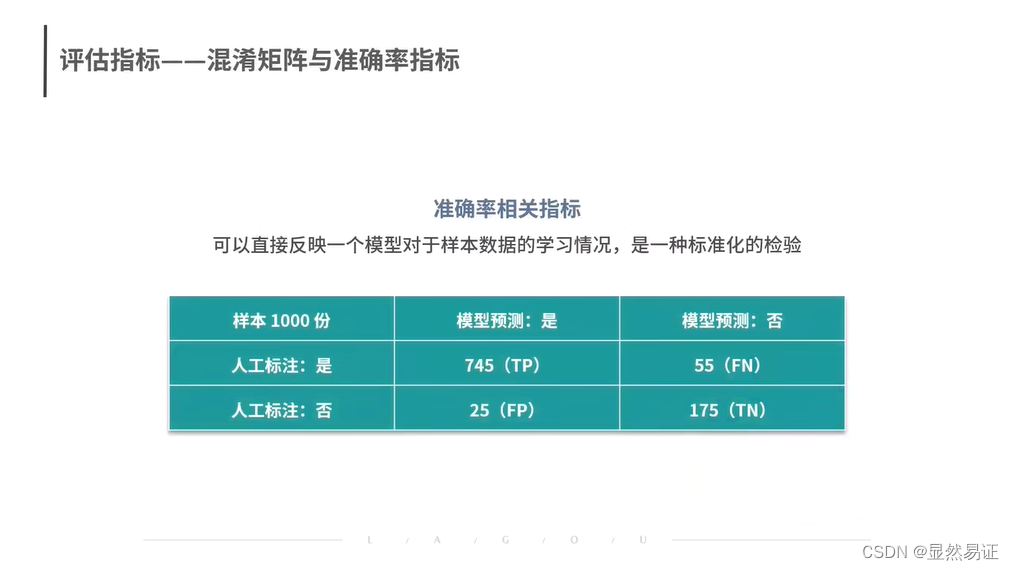
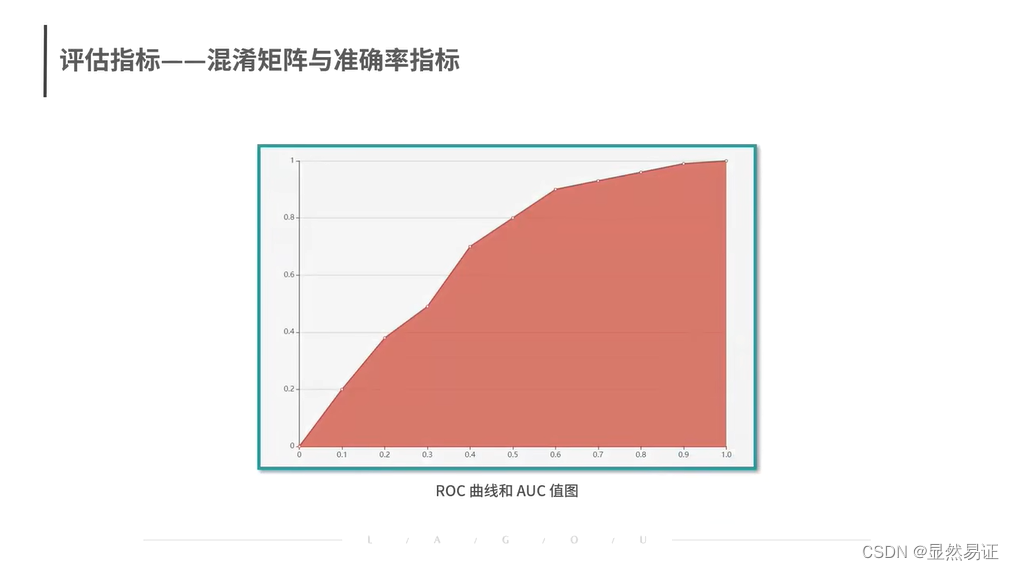
数据挖掘08——数据评估:如何确认我们的模型已经达标?
建议观看视频 数据评估:如何确认我们的模型已经达标?












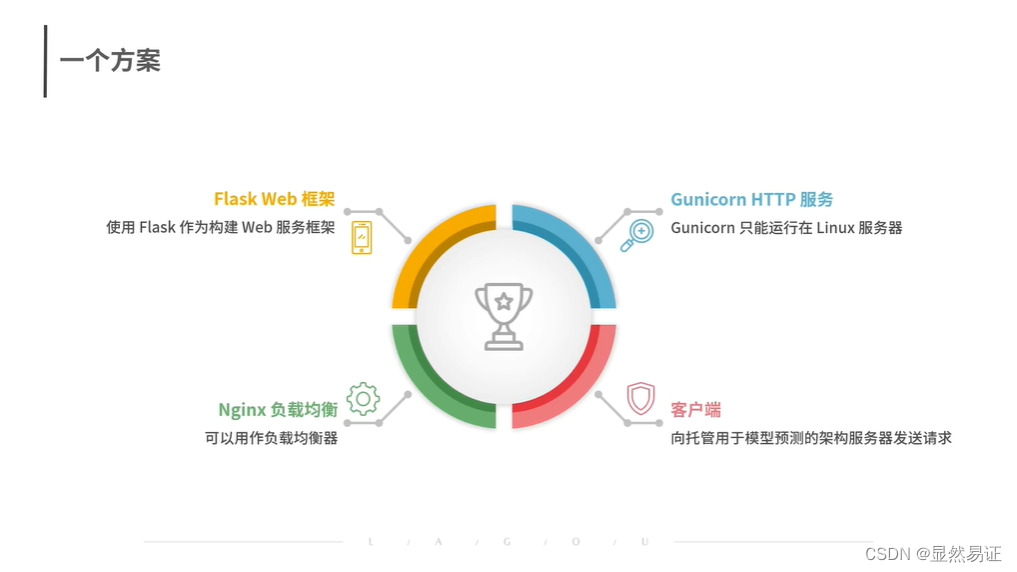
数据挖掘09——数据应用:我们的模型是否可以解决业务需求?
建议观看视频 数据应用:我们的模型是否可以解决业务需求?

















 8829
8829

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









