






 本文综述了群智能算法在特征选择中的应用,探讨了其在大数据背景下解决维度诅咒的方法,重点介绍了PSO、ABC和AOC等主流算法,以及特征选择中的表示和搜索机制。
本文综述了群智能算法在特征选择中的应用,探讨了其在大数据背景下解决维度诅咒的方法,重点介绍了PSO、ABC和AOC等主流算法,以及特征选择中的表示和搜索机制。
群智能算法特征选择方法综述
参考文献: A survey on swarm intelligence approaches to feature selection in data mining Bach Hoai Nguyen ∗, Bing Xue, Mengjie Zhang(kbs顶刊 sci一区 2020年发表)

本文概要:以讲解论文的形式,快速并深入了解群智能算法特征选择的方法和目前的问题。
阅读本文你能得到: 0.阅读论文的一般流程
1.什是特征选择,特征选择的基本方法
2.目前传统特征选择的和群智能算法特征选择研究
3.特征选择两个主要问题:表示方法和搜索机制
4.群智能算法特征选择的三大主流算法(粒子群,人工蜂群,蚁群算法)
第一部分:分析论文结构
- 论文共:13页
- 摘要0.5页,
- 介绍1页,
- 背景,1.5页,
- 用于特征想选择的群智能算法9页,
- 问题与挑战0.5页,结论0.5页
论文大部分篇幅就是对目前群智能算法特征选择的研究主要包含是三大算法(PSO,ABC ,AOC)
第二部分:阅读
注:阅读论文的一般方法,1.先看摘要,2.再看介绍的最后一两段(这部分内容:是这篇论文贡献点,会简要阐述论文采用的主要方法)3.看研究的基础 4.细看提出的算法 5.看实验 6.看结论
2.1 摘要
大数据的主要问题之一是大量的特征或维度,这导致在应用机器学习,特别是分类算法时出现“维度诅咒”的问题。特征选择是一种重要的技术,它选择小而信息量大的特征子集来提高学习性能。由于搜索空间大而复杂,特征选择不是一件容易的事情。近年来,群体智能技术以其简单性和潜在的全局搜索能力受到了特征选择界的广泛关注。分类特征选择是特征选择领域中研究最为广泛的领域,而群体智能在分类特征选择方面的研究尚未得到全面的研究。仅对该领域进行了一些简短的调查,仍然缺乏对最新方法的深入讨论,以及现有方法的优势和局限性,特别是在表示和搜索机制方面,这是适应群体智能来解决特征选择问题的两个关键组成部分。本文综述了应用群体智能实现分类特征选择的最新研究成果,重点介绍了群体智能的表示和搜索机制。本文的目的是概述不同类型的最先进的方法及其优缺点,鼓励研究人员研究更先进的方法,为从业者提供在现实世界中选择合适方法的指导,并讨论未来研究的潜在局限性和问题。
摘要总结 这里主要提出了三个点:
1.特征选择通过选择小而信息量大的特征子集,避免“维度灾难”,提高模型的学习能力
2.群智能算法收到特征选择研究的关注
3.分类特征选择是特征选择的主要问题,本文讲述了群智能算法特征的最新研究成果,重点介绍了表示方法和搜索机制
2.2 介绍
先看最后一段:
这一段主要介绍了这篇综述的研究内容:回顾了至今为止的先进的群智能特征选择方法,主要从表示机制和搜索策略上进行了研究
然后回顾一下前面介绍部分一些有用信息:
按特征的相关性 ,特征集中的特征包括:(相关特征,不相关特征,冗余特征)不相关特征和冗余特征会降低机器学习分类的性能,增加复杂度,还会导致过度拟合
特征选择已经被用于改进许多机器学习任务。如:分类,聚类,回归等。大多数研究用于分类问题,本文的研究重点也在于分类特征选择。目前分类机器学习模型(kNN,DT决策树,SVM支持向量机,朴素贝叶斯)这些机器学习算法我将会出一篇文章单独讲解。这里不进行分析。
2.3研究背景
特征选择目标:从原始的特征集中选择一个较小而且信息量更大的特征子集。
一般的步骤如下:
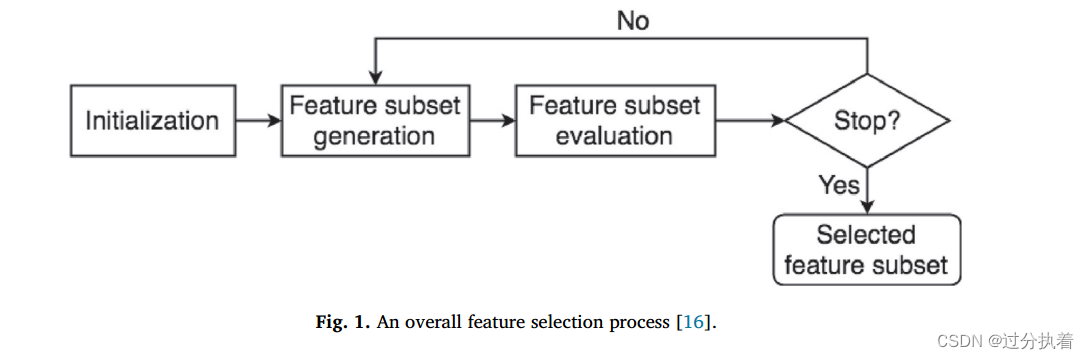
在这四个步骤中,“子集生成”和“子集评价”是最重要的两个步骤。“子集生成”使用搜索方法生成候选特征子集。候选子集的优度是通过“子集评价”中的评价函数(即SI方法中的适应度函数)来衡量的。基于“子集评估”的反馈,“子集生成”有望生成更多有前途的特征子集。
评价标准:主要分为三类过滤,包装,和嵌入。
过滤法,通过一定的评估准则,通过一个阀值对特征子集进行一个过滤,保留大于阀值的特征元素。

包装法:用生成的初始特征集合采用机器学习算法进行分类,然后通过分类的准确率和其他标准作为评估特征集合好坏的标准,来指导生成更好的特征集合

嵌入法:生成特征集合的过程和机器学习模型的训练同时进行
在这三种方法中,过滤方法通常是最有效的,因为它不涉及任何学习过程。然而,包装器和嵌入式方法通常可以获得更好的分类性能,因为它们考虑了所选特征和分类算法之间的相互作用。嵌入式方法的计算量通常低于包装方法,但它们仅适用于某些特定的分类算法
特征选择的评估标准
1.在包装器特征选择算法中,通过分类性能来评估特征子集。大多数分类算法都可以用于特征选择,如KNN[19,20]、朴素贝叶斯(NB)[21,22]、支持向量机[23-26]、人工神经网络(ANN)[27-29]。
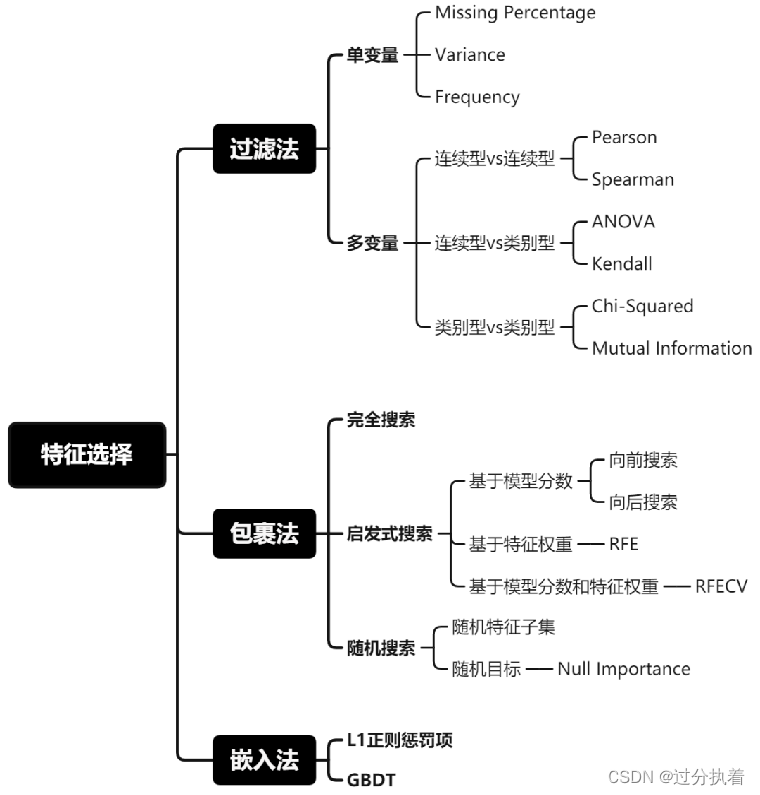
2.过滤法特征选择评价标准
过滤法:主要分为单变量和多变量评估,(这个变量主要是指过滤度量的标准)
在过滤法特征选择中,最常见的四种过滤度量是距离度量、相关性度量、一致性度量和信息度量。
距离度量的目的是选择一个特征子集,该子集可以尽可能地将实例从不同的类中分离出来。一个著名的基于距离的方法代表是Relief[30]。
一致性度量[31]显示了与使用所有原始特征相比,所选特征在分离不同类方面的一致性。如果两个实例具有相同的特征值,但它们属于不同的类,则它们是不一致的,目的是是找到一个最小的特征子集,达到可接受的不一致率。
相关性度量[32]评估两个随机变量的依赖程度,因此它们可以用来选择与类标签高度相关(最大化相关性)并包含不相关特征(最小化冗余)的特征子集。
与相关度量类似,信息度量[33]可用于度量特征子集的冗余和相关性。在这四种度量中,信息度量由于能够检测随机变量之间的非线性关系而受到更多的关注。
嵌入式特征选择:
嵌入式特征选择算法中,选择过程发生在分类算法的训练过程中。DT是嵌入式特征选择算法的一个例子,其中最终树中出现的特征是被选择的特征。支持向量机也可以被认为是一种嵌入式方法,其模型权重可以反映相应特征的重要程度。最近,一种基于稀疏学习机制的嵌入式特征选择方法因其良好的性能而受到越来越多的关注。
其思想是在目标函数中包含一个稀疏正则化项,这样当分类误差最小化时,许多特征系数被强制为非常小,或者恰好为零。特征选择是通过选择系数足够大的特征来实现的。
特征选择搜索方法: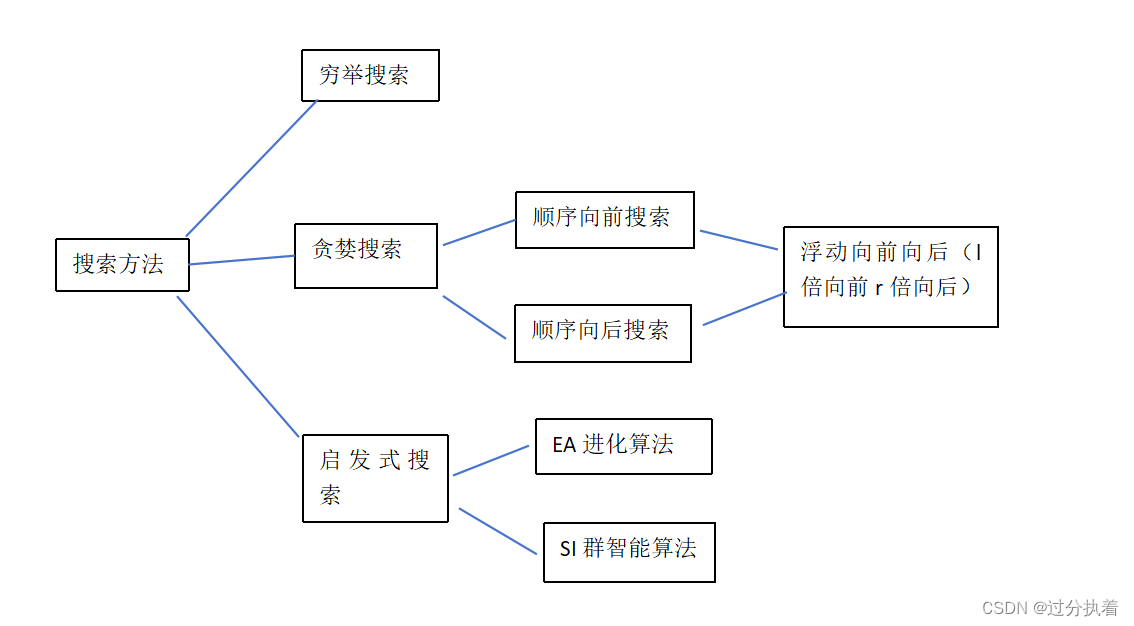
在处理特征选择问题上,假设初始特征集合有n个特征那么可能的特征子集的数量就为2的n次方个。这样呈指增长的搜索空间使用,穷举搜索显然是不太可能的。
随后提出了贪婪搜索方法,顺序向前和顺序向后,(意思是从一个空(满)的子集开始,逐渐加或者逐渐减,每次进行评估,直到无法改进算法性能然后停止)但是这种方法,不能考虑到特征之间的相互关系(例如:两个弱相关特征,放在一起可能就是强相关特征)随后提出的动态浮动搜索策略(l倍向前,r倍向后)
由于特征维度巨大顺序搜索还是没办法满足需求,就有了启发式的方法进行特征选择
在ea中,遗传算法(GAs)可能是最常用的特征选择技术。SI算法的灵感来自群居昆虫/动物的行为。在这些算法中,由一组个体组成的群体探索并与其他成员分享他们关于搜索空间的知识。共享机制帮助整个群体在搜索空间中向更好的位置移动,最终收敛到最优[50]。一些著名的SI算法代表是PSO [51], ACO[52]和ABC[53]。与GAs相比,当计算预算较低时,SI算法通常收敛更快,性能也相对更好[54,55],这可能是使用SI算法进行特征选择的论文数量显著增加的原因,尤其是PSO[9]。
第三部分:用于特征选择的群智能算法
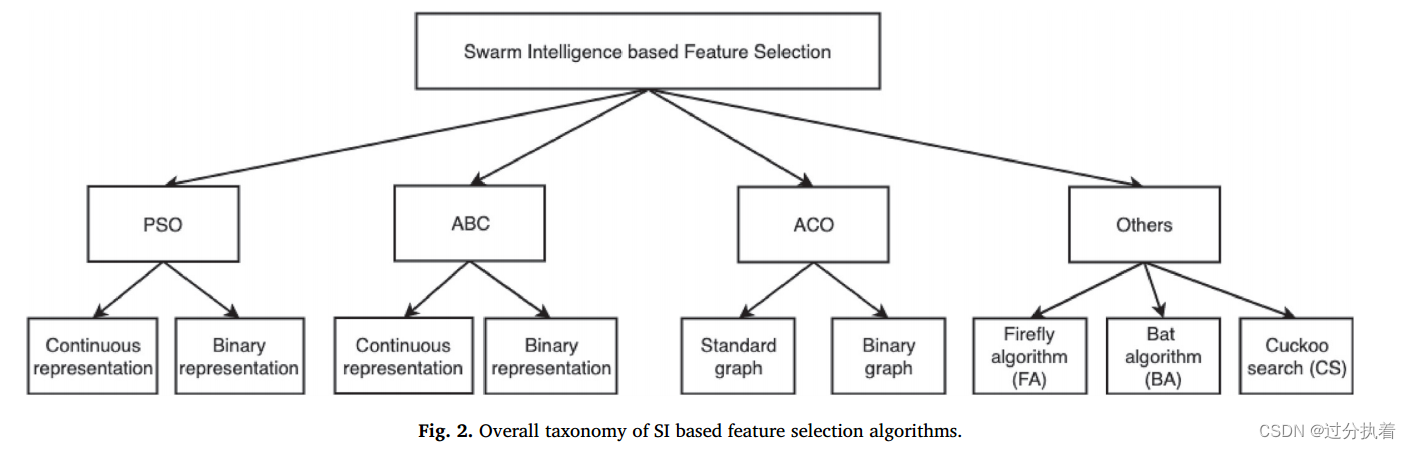
3.1用于特征选择的pso算法
pso特征选择在表示方法上主要有两种,一种是连续向量表示
一种是二进制表示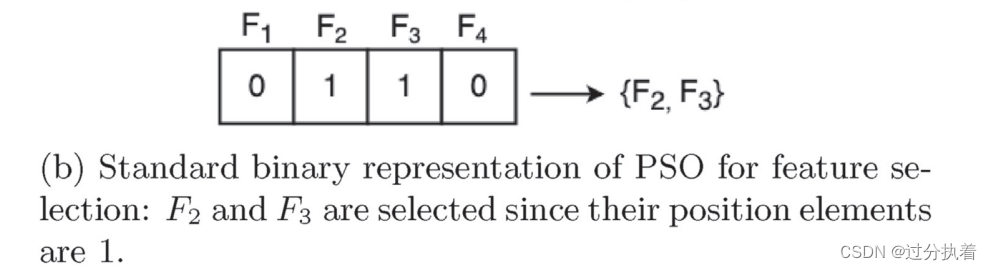

















 1597
1597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









