







论文随记 | Identity-Preserving Talking Face Generation with Landmark and Appearance Priors基于特征和外观先验的保持身份的说话人脸生成
论文发表于CVPR2023
原文链接:https://arxiv.org/pdf/2305.08293
Introduction
贡献
- 提出了一个两阶段的框架组成的音频到地标生成器和地标到视频渲染模型,以解决在先验地标和外观信息的指导下的通用说话人脸生成任务;
- 设计了一个音频地标生成器,可以有效地融合先前的地标信息与音频功能;
- 设计了一个地标到视频的渲染模型,它可以充分利用多个源信号,包括先验视觉外观信息,地标和听觉特征;
Method
给定音频序列和初始输入视频,本文目标是逐帧完成输入视频的下半部分被遮挡的脸部来生成口型同步的说话脸部视频。概述如图 2 所示。第一阶段将音频信号和说话者面部的先前标志作为输入来预测嘴唇和下巴的标志。第二阶段由对齐模块和翻译模块组成。

3.1 Audio-To-Landmark Generation
此处输入数据主要由三部分组成,取连续5帧,音频数据和先前的landmarks为输入,主要是嘴唇和下巴位置的坐标。
3.1.1 Audio-To-Landmark Generation
通过一维和二维卷积层构造的编码器提取姿势和参考embeding。

引入三个可学习的编码向量,分别作为音频、先验坐标和参考坐标的embedding嵌入。再引入由正弦位置编码计算所得的时间位置编码向量,加入到原有的三种变量中,如下,

通过transfomer模块捕获三种类型embedding的类中和类间信息。初始输入是上方的嵌入后变量。使用L层transformer编码器,使用多头自注意力机制(MSA)和层正则化(LN)、MLP层,进行计算如下,

第 l l l层的transformer模块输出的维度是 ( N l + 2 T ) ∗ d (N_l+2T) * d (Nl+2T)∗d,其中两个 T T T的token分别为预测得到的下巴和嘴唇处的landmarkds:

上方公式左侧代表第t层,下巴和嘴唇处预测得到的坐标。
3.1.2 Loss Function for Landmark Generation
损失函数有两部分:
- L1重建损失
- 连续正则化约束预测landmarks,提高时间平滑度



3.2 Landmark-To-Video Rendering
本文设计了对齐模块Ga和平移模块Gr,将预测标志和姿势先验标志组合,形成完整面部标志集合。在合成第t帧目标图像时,在第t帧周围选择2k+1个目标作为输入。其次再将多个参考图像及其提取的草图输入到对齐模块,计算其运动场。
3.2.1 Reference Images Warping
首先,参考图像 I I I和草图 L L L通过对齐模块,与卷积层的逐通道级联编码为两个分辨率的视觉特征。为了预测运动场 F i F_i Fi,通过SPADE层将2k+1个目标草图逐通道级联到对齐模块中。SPADE层根据目标草图调节视觉特征。PixelShuffle层用于上采样。

对多个参考图像及其对应的被运动场扭曲的视觉特征进行聚合,对齐模块中增加一个输出层以预测 I I I的2D权重 w i w_i wi。聚合后变形的图像如下,

其中 F i F_i Fi是由运动场扭曲得到的图像。两种不同的空间分辨率下的聚合扭曲特征分别计算如下:

其中 F i F_i Fi仍是由运动场扭曲的视觉特征。其中 F i F_i Fi和 w i w_i wi被下采样,来匹配 h I s h_I^s hIs的尺寸。
3.2.2 Sketch-To-Face Translation
此模块目的为将与mask的目标面部
I
t
m
I^m_t
Itm连接的目标草图转换为最终面部图像。这是在聚合的变形图像和特征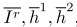 的辅助下执行的。此外本文还通过AdaIN层将音频编码器提供的特征注入到翻译模块中,
的辅助下执行的。此外本文还通过AdaIN层将音频编码器提供的特征注入到翻译模块中,

如图中所示,先将mask图和草图按通道级联并馈送到卷积层获取编码特征。通过SAPDE层融合到翻译模块中,以调制编码特征,随后进行AdaIN操作。同时通过PixelShuffle层实现上采样。
在推理过程中,将生成的全脸粘贴到原始帧上,由于生成的人脸可能包括一小部分伪影背景,通过高斯平滑的人脸mask将生成人脸与原始帧的背景合成,如图。

3.2.3 Loss Function for Rendering
聚合的扭曲图像和groundtruth之间的扭曲损失,约束运动场的对齐模块:

特征函数由VGG网络计算,i表示层数。
重建损失与风格损失:


Experiments
定量对比:

消融实验



Conclusion
本文提出了一个两阶段的音频驱动的说话人脸生成方法。首先,我们设计了一个transformer为基础的地标生成器,从音频获得准确的唇和下巴的标志。然后将多个参考图像与目标表情和姿势对齐,为渲染人脸视频提供更多的外观先验。此外,在渲染阶段,利用声学特征来增强嘴唇同步。通过实验验证了方法的性能。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









