






 本文深入探讨了循环神经网络(RNN),包括基本的RNN结构、Elman和Jordan网络、双向RNN、LSTM和GRU。解释了LSTM的工作原理,以及在序列学习中的挑战和解决方案,如梯度消失问题。此外,还讨论了RNN在多种任务中的应用,如情感分析、语音识别和机器翻译,并对比了RNN与结构化学习方法。
本文深入探讨了循环神经网络(RNN),包括基本的RNN结构、Elman和Jordan网络、双向RNN、LSTM和GRU。解释了LSTM的工作原理,以及在序列学习中的挑战和解决方案,如梯度消失问题。此外,还讨论了RNN在多种任务中的应用,如情感分析、语音识别和机器翻译,并对比了RNN与结构化学习方法。
Recurrent Neural Network
- slot filling




将一个词输入进去,输出的为该词属于slot的概率分布

input相同词的slot不同


每一个hidden layer 产生的 output会被存储在a1和a2中,再输入其他input时,memory 也会被考虑

第一次输入
将sequence第一组input输入到neural network中,设定memory的initial value 为0.所有的节点权值为1,无偏移量,所有的activation functions 都是线性的。

经过绿色的节点的计算,每个绿色节点的output都为2
最后y1和y2的output为4,同时2,2会被存储在memory中。



第二次输入

对于RNN,即使输入的input是一样的,它的output也可能不一样
第三次输入

changing the sequence order will change the output

同一个network在三个时间点被使用了三次,对于第二次输入来说,taipei这个词产生的output会同时考虑储存在a1中arrive的特征,从而产生一个关于arrive Taipei这个词组的output


Elman Network & Jordan Network

Jordan Network 储存的是output的值,在target上有更好的performance
Bidirectional RNN (可以是双向的)
可以同时train 正向和逆向的NN,把两个nn的output拿出来产生最后的y
好处:产生output产生的范围比较广,对于正向的nn,它考虑的只是input前sequence的所有特征,对于双向,考虑了前后所有时刻的input

LSTM Long short-term Memory

input gate 和output gate 可以打开或关闭控制memory变量的输入与输出
四个input
- 想要被存入memory cell的值,depend on input gate
- 操控input gate 的讯号
- 操控output gate 的讯号
- 操控 forget gate的讯号
- 三个gate是打开还是关闭由学习得到
sigmoid 的值表示被打开的程度,即概率
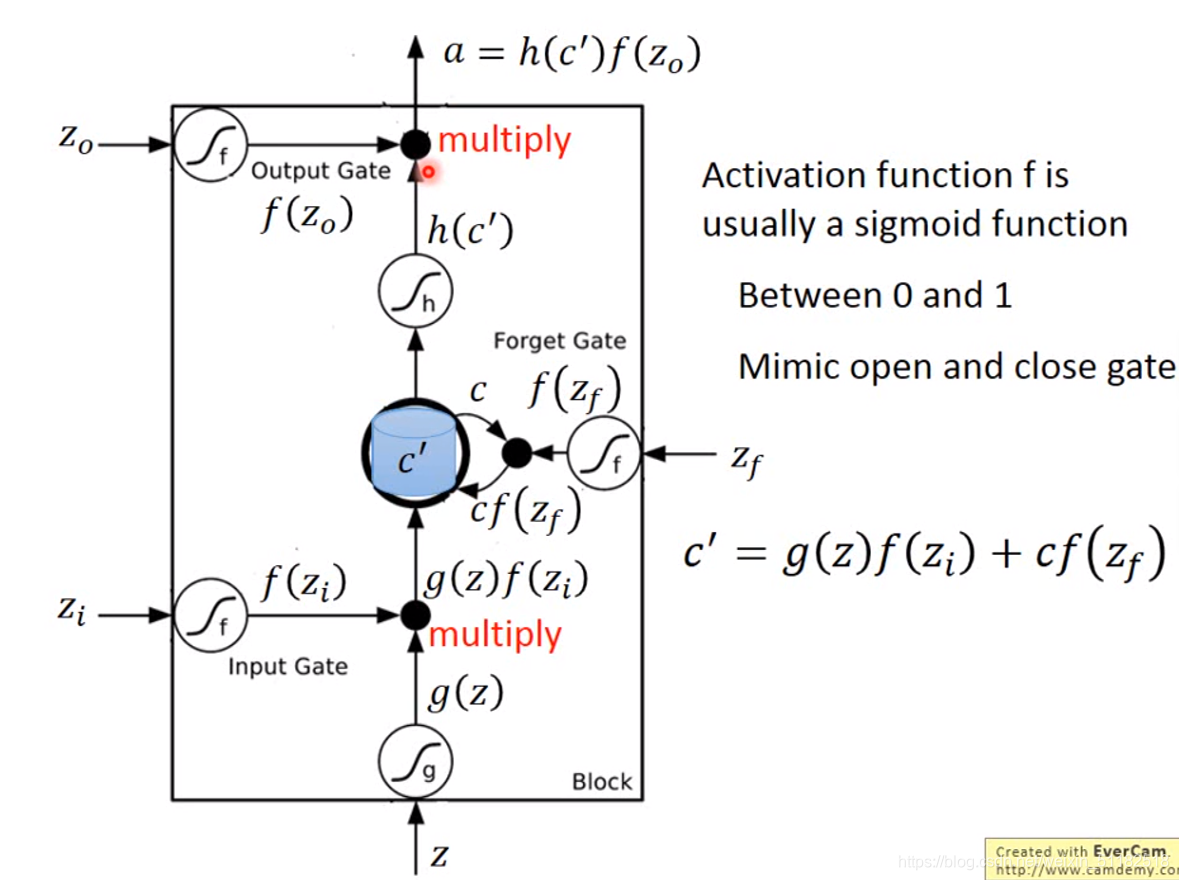
当三个gate其中一个的概率密度为0时,经过gate后输出的值也变为0,此时表示该门关闭,input无法传递到memory cell,或更新memory或输出memory的值
LSTM-Example

第一次input

第二次input

第三次input

第四次input
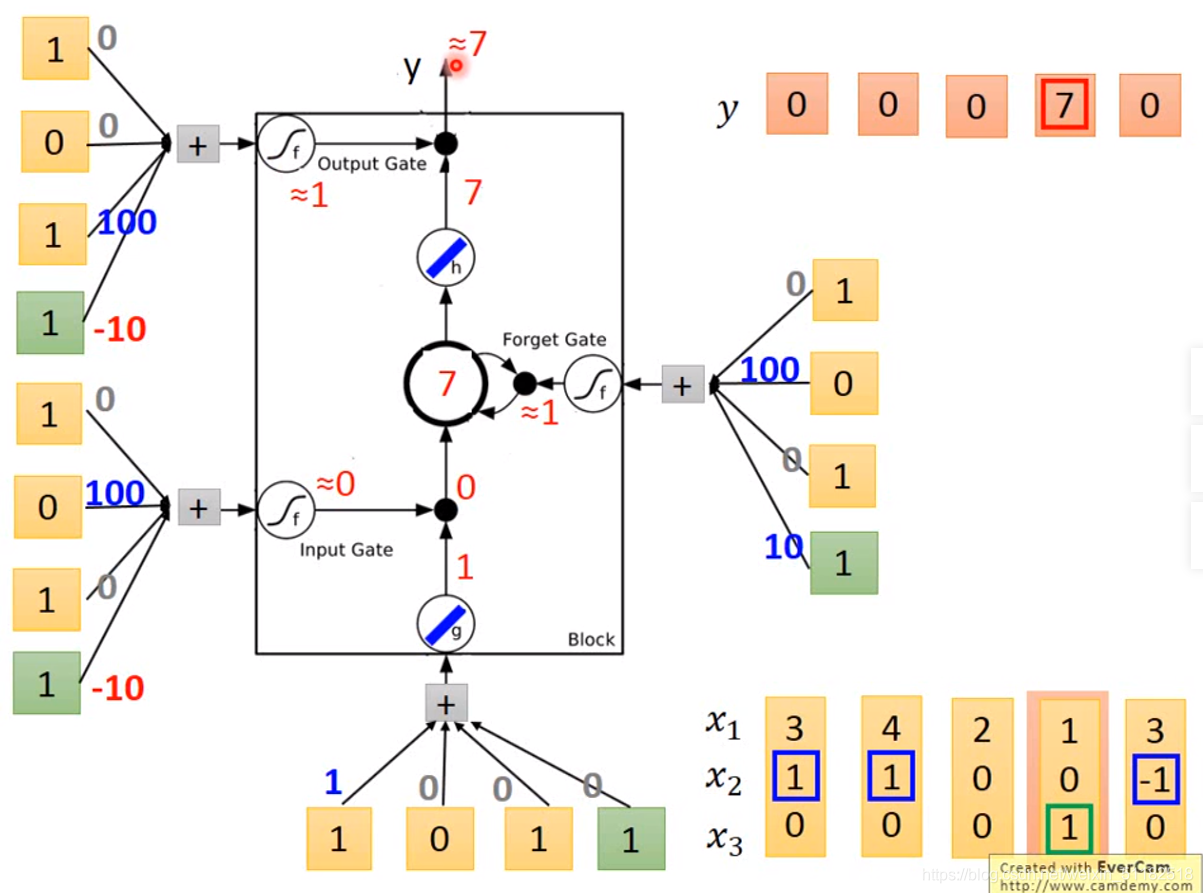
第五次input

LSTM与Neural network的关系


lstm有四个input和一个output,将输入的值分别输入到四组input 的weight
4 times of parameters
z的dimension是lstm的数量

将 x t x^t xt经过四组transform为 z f , z i , z , z o z^f, z^i ,z ,z^o zf,zi,z,zo分别作为forget gate,input gate,input 和output gate的input值,每一个z的dimension控制一个memory cell。z的dimension数量=memory cell 的总数。所有的cell可以共同一起被运算
对于t时刻

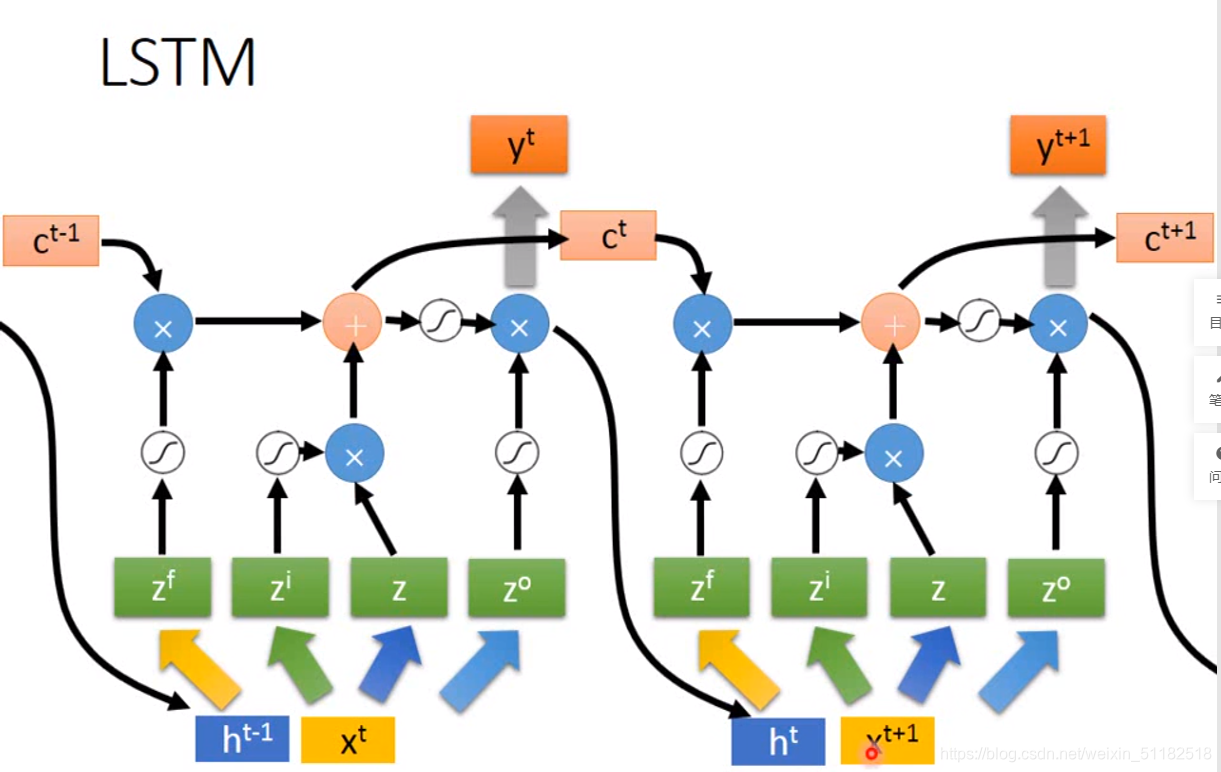
对于t+1时刻,操控四个input口的input值不仅仅看当前时刻的输入,还要考虑上个时刻t的output值 h t h^t ht。
Peephole,Multiple-layer LSTM

每一个时刻的input值,由当前时刻的input,上一时刻的output和上一时刻的memory cell的值共同决定
Learning Target

cost是每一个时间点的cross-entropy

使用gradient descent train
RNN-based network is not always easy to learn


会造成的问题:

随着gradient descent可能会使w的值在loss较大的区域和loss较小的区域反复横跳,导致total loss的暴增会骤减。当w的值踩在交界处时,之前的gradient都很小,learning rate又很大,导致参数会直接飞出去
引入clipping
当gradient大于某个参数值时,设置gradient为该参数值
如果将sigmoid function换成RELU通常performance更差,所以activation function的种类并不是导致total loss在gradient descent 波动较大的因素

因为对于一个1000次序列的rnn来说,如果将第一个输入的值定为1,后续输入的值变为0,则第1000个时刻,输出的值为 w 999 w^{999} w999,即w的高次方项,由此可见,只要些微改变w的值就会对output的值产生很大的影响,也对gradient descent的偏导数产生大的影响,从而影响学习率。
helpful techniques
1、LSTM
让error surface 不要那么崎岖,将平坦的地方拿掉,有些区域依然会变化很剧烈,但没有很平缓的地方,可以将learning rate统一设的小一点
那么LSTM是如何处理gradient vanishing的?
对于RNN来说,每一个时刻,上个时刻的memory和output都会参与当前时刻的input的计算。在LSTM上,上一时刻的memory和output会乘上一个sigmoid函数再以相加的形式计算到下一时刻的input中。需要注意的是,只要weight可以影响到memory的值时,它会一直造成影响。除非forget gate clean 掉上一时刻的memory

Gated Recurrent Unit simpler than LSTM
前者有两个gate,后者有三个LSTM。当使用LSTM产生很严重的过拟合现象,可以选用GRU
GRU的input gate 和forget gate 会联动,当input gate 打开时,forget gate 会关闭并自动洗掉上一时刻memory cell里的值。这意味着只有当memory cell的值清掉后,新的memory的值才可以从input gate中放进来
Other helpful techniques
- Clockwise RNN
- Structurally Constrained Recurrent Network(SCRN)

RNN can do more

many to one
- Sentiment Analysis

上述是个分类的问题,将一句话作为vector sequence 输入进RNN,得到output后经过transform 转变为分类问题,判断这句话属性的好坏
document keyword

many to many(output is shorter)
- speech recognition
Both input and output are both sequences, but the output is shorter
将一个很短的时间段作为vector sequence经过rnn输出,对于好棒这两个词可能会在每0.1s为时间间隔输出在连续三个时刻输出好,连续五个时刻输出棒,为了得到好棒的最终output,使用trimming 将原有输出进行裁剪得到好棒

如何解决many to many 情况下,ABB叠字的情况
在两个字间隔下加入null作为额外的输出符号

CTC Training

通过穷举出所有可能的sequence

Many to Many(no limitation)
- sequence to sequence learning with different length
不确定input和output哪个长,如中英翻译

在输入learning 后的output中包含了前面所有时刻的信息。

输出为===时,会停下来
句法分析



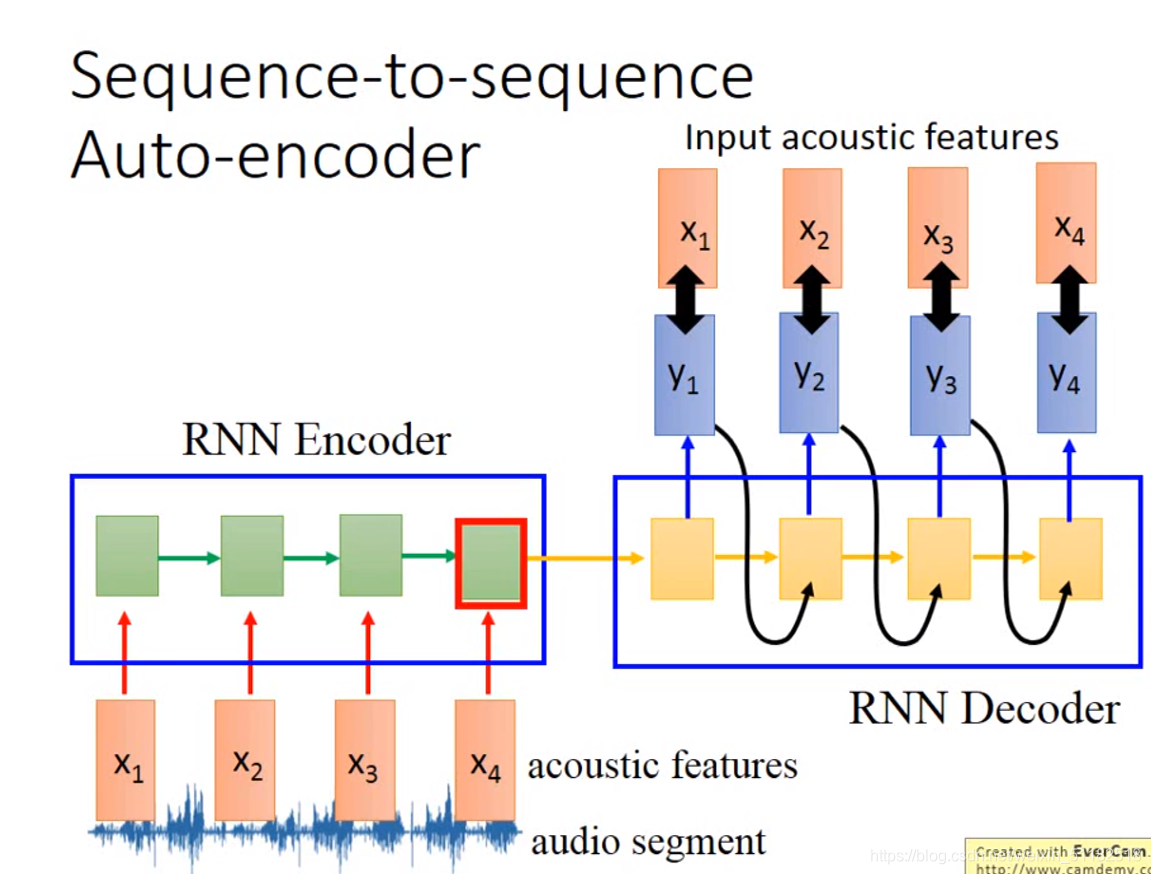
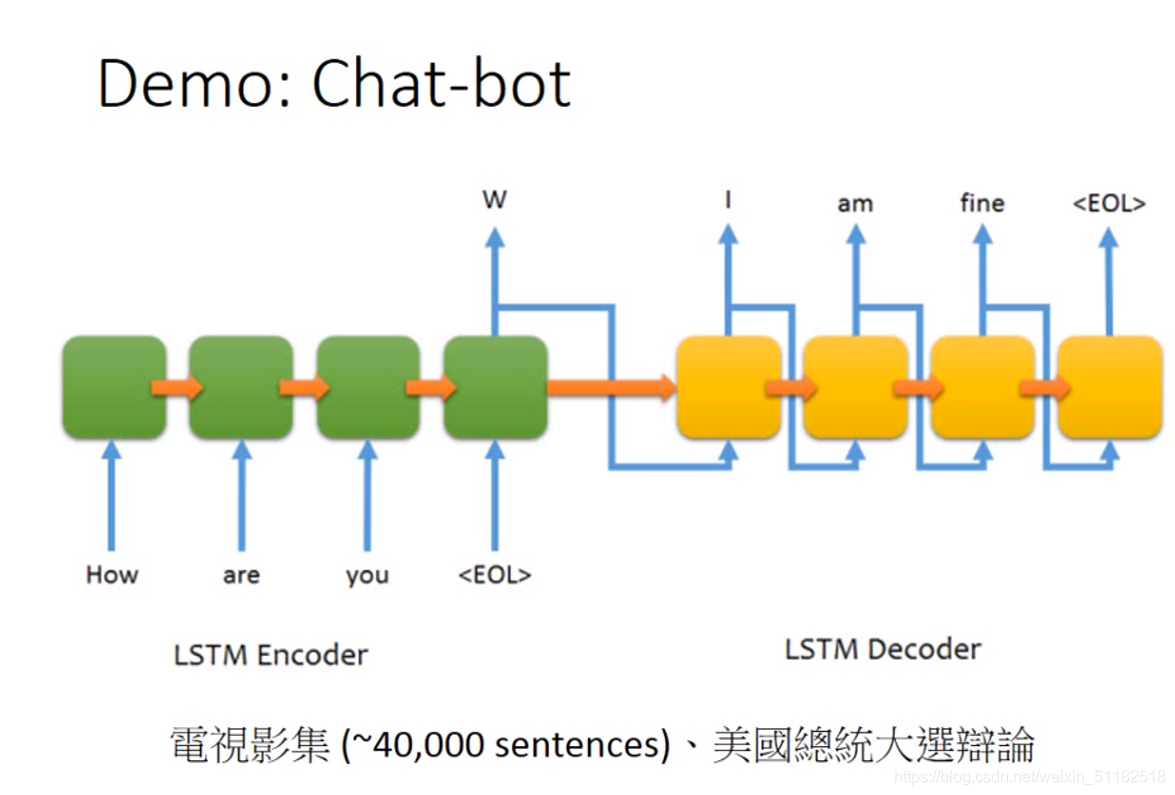
The RNN encoder and decoder are jointly trained
Attention-based Model

将input放入cpu,可以是dnn或者rnn,其通过reading head controller 控制 reading head 的位置,从而读取machine‘s memory,然后通过rnn/dnn产生output
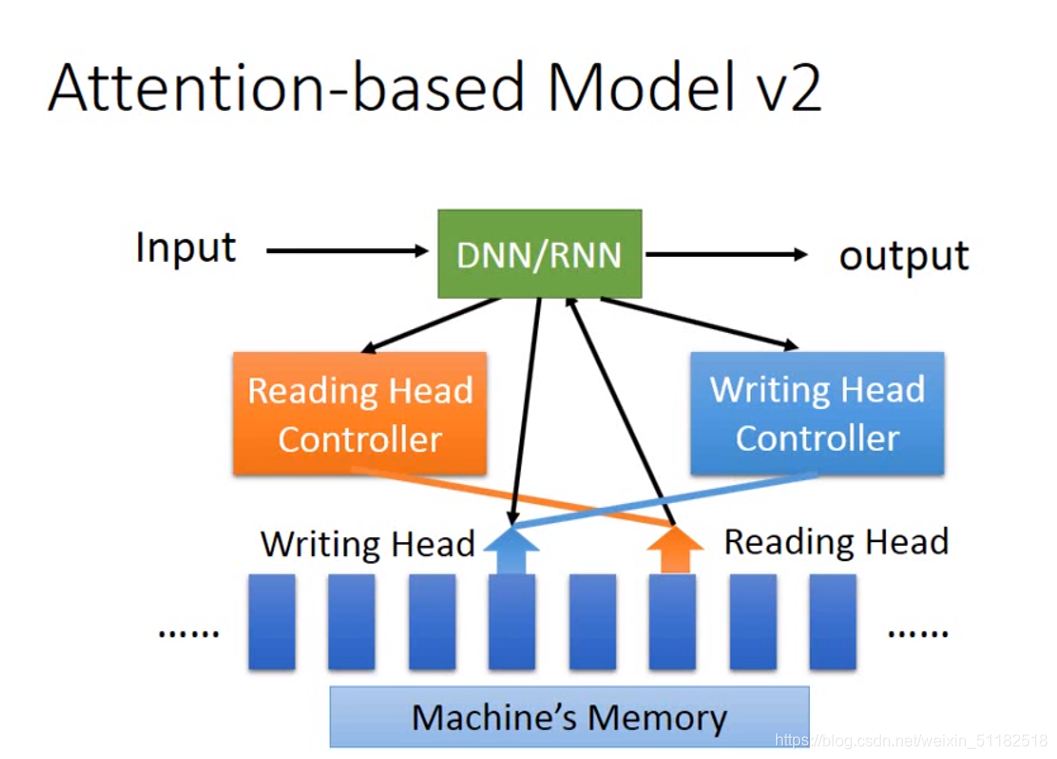
它还可以将discover后的东西通过writing head controller 写入machine’s memory。 成为neural turing machine
Reading comprehension
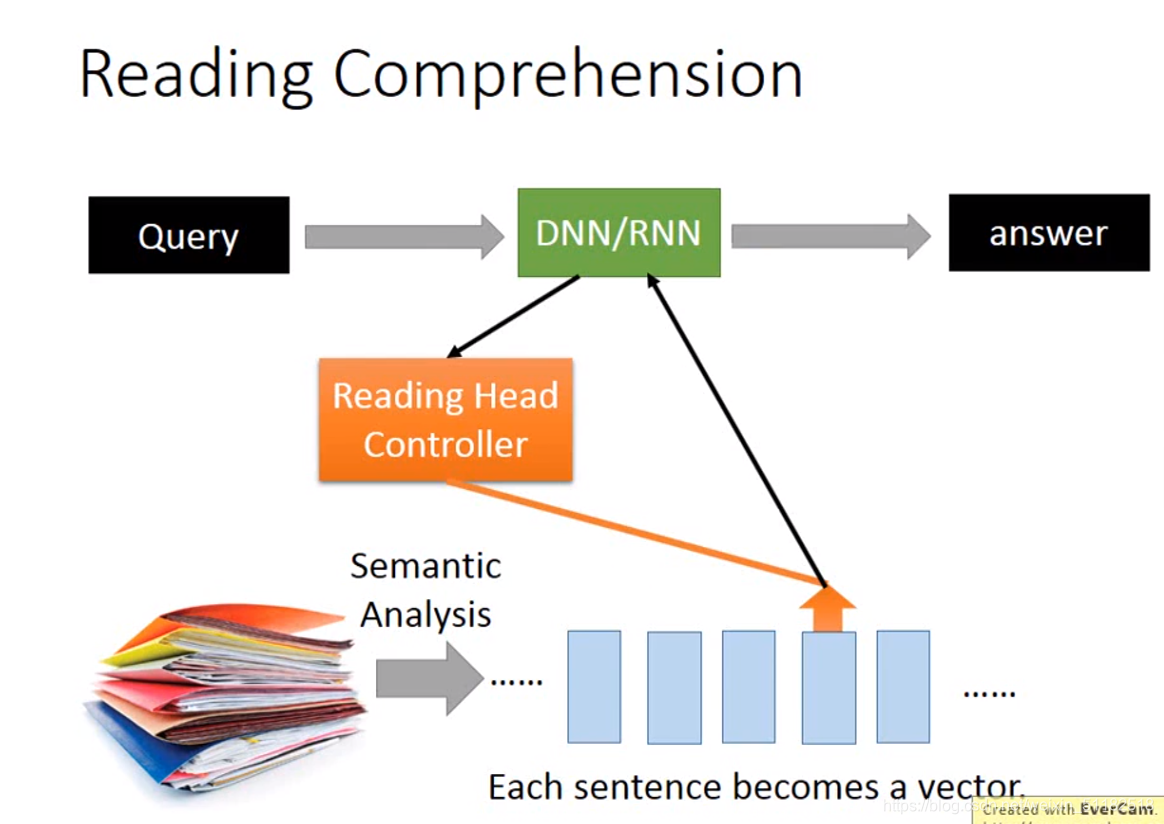
将一些文本输入,使每一句话变成一个向量,提出一个问题,通过DNN/RNN 以及reading head controller定位到与该问题相关的sentence,返回DNN/RNN作为output的答案
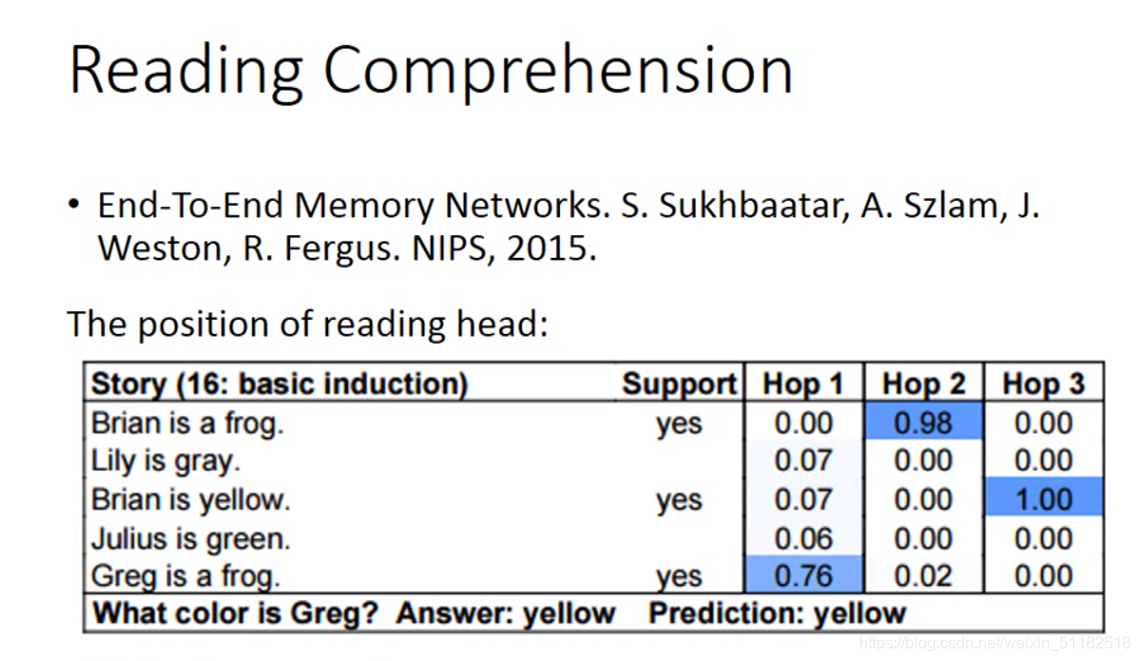
对于what color is Greg的问题,在hop1位置,定位到greg is a frog,在hop2时,定位到brian is a frog,最后在hop3,定位到brian is yellow。综合三个定位到的sentence vectors,得出对于答案的预测:yellow。
Visual Question Answering
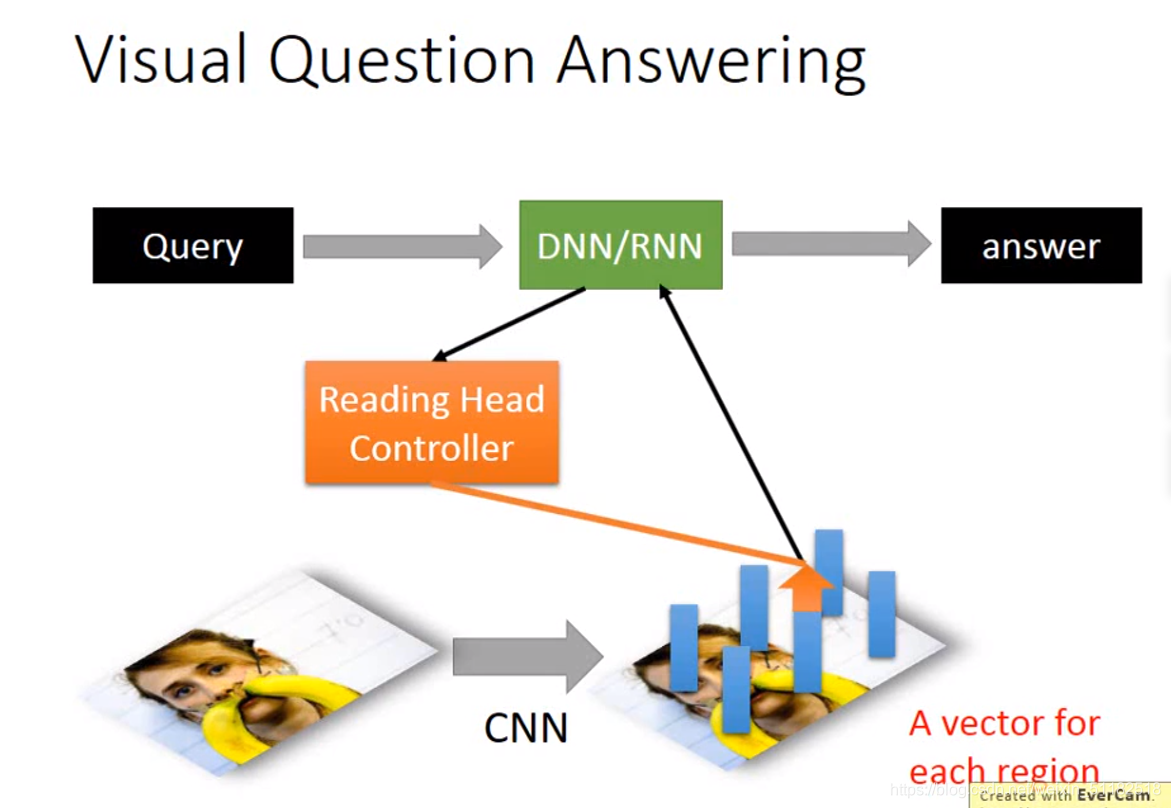
Speech Question Answering
Model Architecture

首先对question做语意分析得到question的语义,对于audio,先用speech recognition辨识转为文字,再把这些文字做语意分析。做attention,根据重点产生答案,最后选择与答案相似度最高的选项

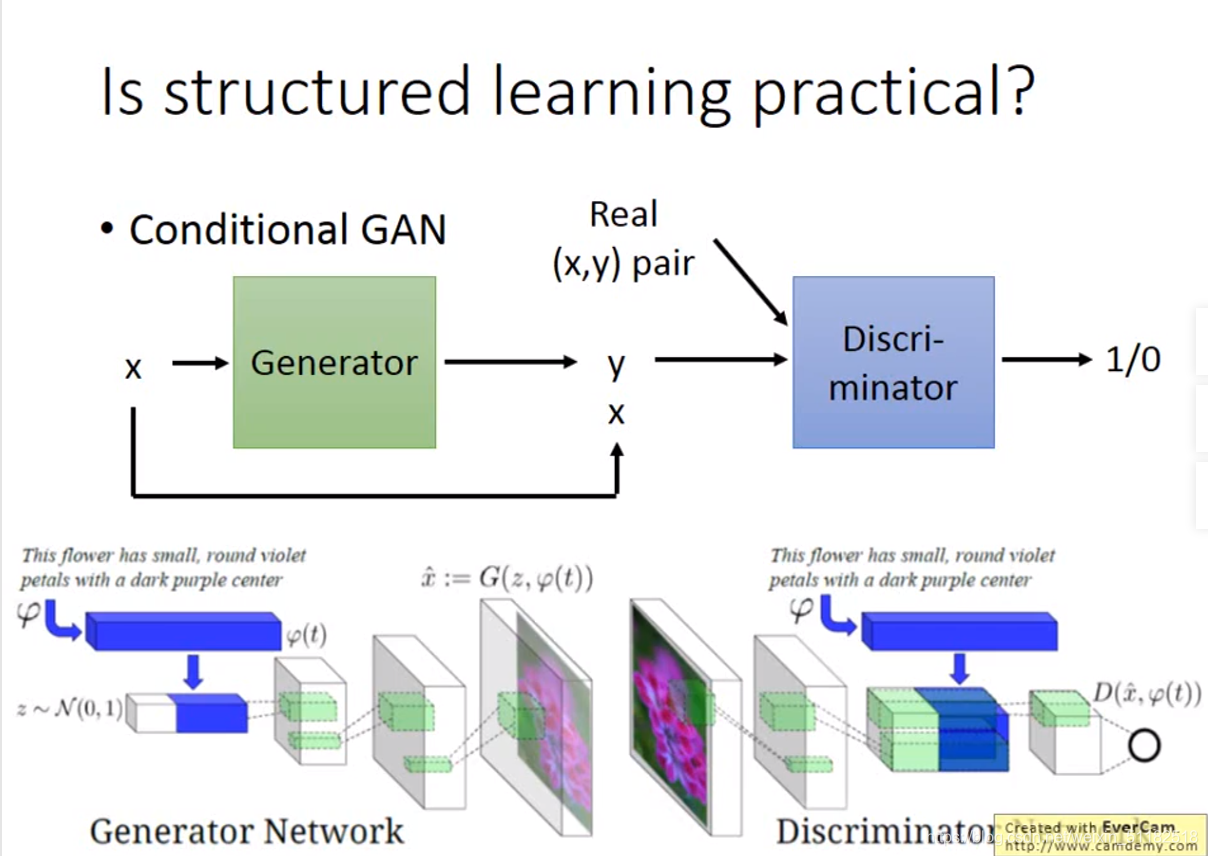
RNN vs Structured Learning

RNN,LSTM
- 单向的rnn并没有考虑整个序列对于某时刻的影响
- 损失和错误并不是总是相关的,cost计算的是每一时刻的交叉熵
- 可以使用deep learning
HMM,CRF,SVM
- 使用维特比算法,可以考虑整个序列对某时刻造成的影响
- 可以考虑到输出标签之间的依赖关系
- cost is the upper bound of error
- 可以应用在简单的线性模型上
Integrated Together
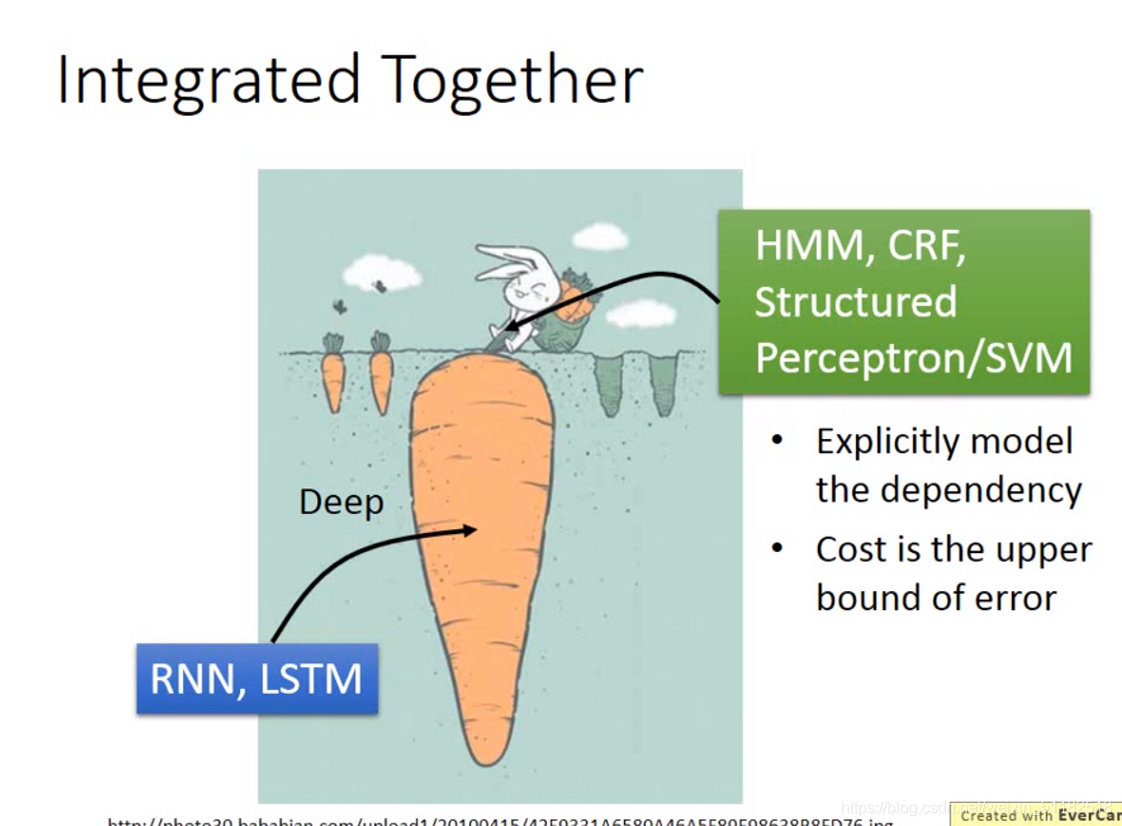
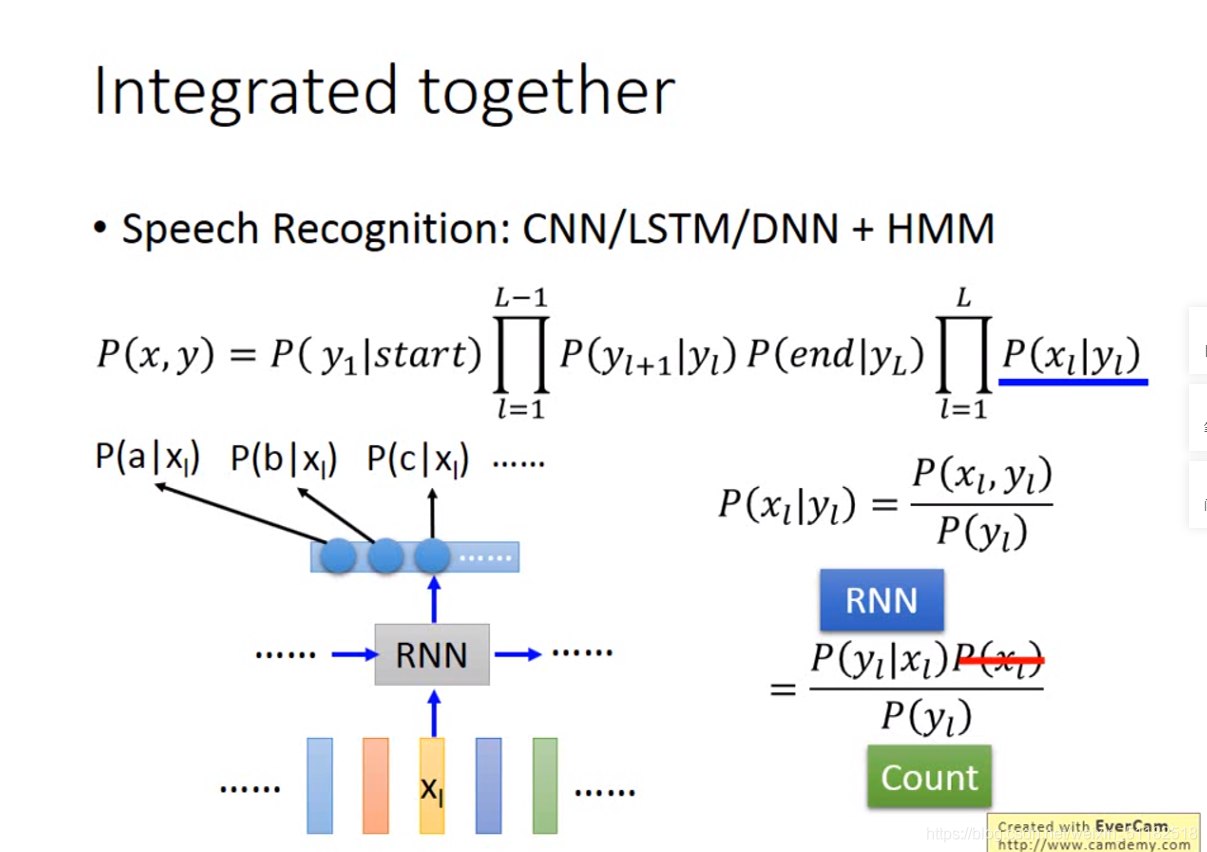
先用rnn/lstm产生的output作为HMM的input,可以更加容易地观察到模型的dependency和损失
一起用gradient descent learning


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









