







1、过拟合与欠拟合
-
过拟合:模型过于复杂(高次项参数过多),实际简单。导致模型可以在训练集上表现很好,在测试集上很差
-
欠拟合,模型过于复杂,实际数据分布复杂,导致模型在训练集和测试集上都表现得很差。
-
deep learning 得layers越来越多,参数量越来越大,model capacity越大。
2、交叉验证:减少过拟合
每经过一次迭代训练,使用验证集的数据做一次validation查看它是否过拟合。
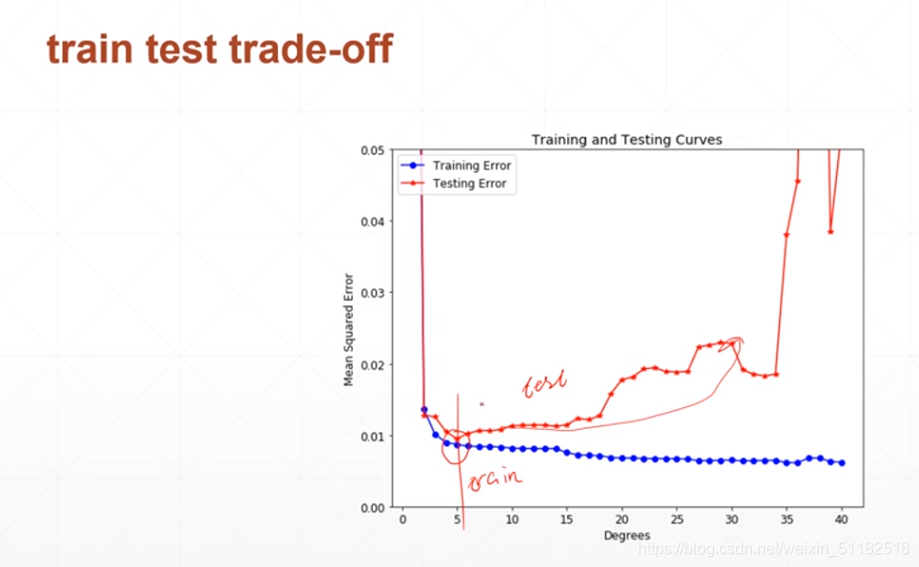
随这训练集的loss不断下降,测试集的error会升高。
使用random_split在训练集上划分测试集和验证集
train_db,val_db=torch.utils.data.random_split(train_db,[50000,10000])
train_loader=torch.utils.data.DataLoader(train_db,batch_size=batchsiz,shuffle=True)
val_loader=torch.utils.data.DataLoader(val_db,batch_size=batchsiz,shuffle=True)
K-fold cross-validation
- 将训练集划分为k份
- 随机选择每一份可以作为验证集
- 做k次train-validation, 选择acc最好的那一次。
3、Regularization
-
L1-norm
-
L2-norm
-
使参数得范数变小
-
使参数刚好可以表达数据的分布,加入正则后,loss函数无法达到global minimum
-
在每次梯度更新时,会让weight下降得更快
-
加入正则项后,分割曲面会更smooth
如何做L2-norm
device=torch.device("cuda:0")
net=MLP().to(device)
optimizer=optim.SGD(net.parameters,lr=learning_rate,weight_decay=0,01)
criteon=nn.CrossEntroploss().to(device)
如何做L1-norm
regularization_loss=0
for param in model.parameters():
regularization_loss+=torch.sum(torch.abs(param))
classify_loss=criteron(logits,target)
loss= classify_loss+0.01*regularization_loss#lambda=0.01
optimizer.zero_grad()
loss.backward()
optimizer.step()
4、动量与学习率衰减
动量

每一步梯度更新的方向会参考上一个时刻的梯度方向。随着 β \beta β的值升高,更新方向会更偏向之前的梯度方向。
适用于
- 更新点落在平缓的全面
- 更新点落在局部最小值
在pytorch中使用
optimizer=torch.optim.SGD(model.parameters(),args.lr,momentum=args.momentum,weight_decays=args.weight_decay)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 751
751











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









