







KNN算法
算法流程:
1) 计算已知类别数据集中的点与当前点之间的距离
2) 按距离递增次序排序
3) 选取与当前点距离最小的k个点
4) 统计前k个点所在的类别出现的频率
5) 返回前k个点出现频率最高的类别作为当前点的预测分类
参考地址:https://zhuanlan.zhihu.com/p/25994179
KNN取距离度量的方式
k近邻算法是在训练数据集中找到与该实例最邻近的K个实例,这K个实例的多数属于某个类,我们就说预测点属于哪个类。
定义中所说的最邻近是如何度量呢?我们怎么知道谁跟测试点最邻近。这里就会引出我们几种度量俩个点之间距离的标准。

(1)特征归一化(feature scaling)
在进行距离有关的计算时,单位的不同会导致计算结果的不同,尺度大的特征会起决定性作用,而尺度小的特征其作用可能会被忽略,为了消除特征间单位和尺度差异的影响,以对每维特征同等看待,需要对特征进行归一化。
参考地址:https://zhuanlan.zhihu.com/p/265411459
①:Rescaling (min-max normalization、range scaling):
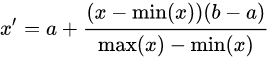
将每一维特征线性映射到目标范围[公式] ,即将最小值映射为a,最大值映射为b,常用目标范围为[ 0 , 1 ]和[ − 1 , 1 ],特别地,映射到[ 0 , 1 ] 计算方式为: 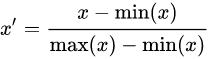
②:Mean normalization:
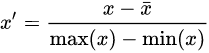
将均值映射为0,同时用最大值最小值的差对特征进行归一化,一种更常见的做法是用标准差进行归一化,如下。
③:Standardization (Z-score Normalization):
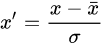
每维特征0均值1方差(zero-mean and unit-variance)。
④:Scaling to unit length:
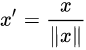
将每个样本的特征向量除以其长度,即对样本特征向量的长度进行归一化,长度的度量常使用的是L2 norm(欧氏距离),有时也会采用L1 norm,不同度量方式的一种对比可以参见论文https://link.zhihu.com/?target=https%3A//lear.inrialpes.fr/people/triggs/pubs/Dalal-cvpr05.pdf
什么时候需要feature scaling?
涉及或隐含距离计算的算法,比如K-means、KNN、PCA、SVM等,一般需要feature scaling,因为
zero-mean一般可以增加样本间余弦距离或者内积结果的差异,区分力更强,假设数据集集中分布在第一象限遥远的右上角,将其平移到原点处,可以想象样本间余弦距离的差异被放大了。在模版匹配中,zero-mean可以明显提高响应结果的区分度。
就欧式距离而言,增大某个特征的尺度,相当于增加了其在距离计算中的权重,如果有明确的先验知识表明某个特征很重要,那么适当增加其权重可能有正向效果,但如果没有这样的先验,或者目的就是想知道哪些特征更重要,那么就需要先feature scaling,对各维特征等而视之。
什么时候不需要feature scaling
与距离计算无关的概率模型,不需要feature scaling,比如Naive Bayes;
与距离计算无关的基于树的模型不需要feature scaling,比如决策树、随机森林等,树中节点的选择只关注当前特征在哪里切分对分类更好,即只在意特征内部的相对大小,而与特征间的相对大小无关。
sklearn中的用法
在sklearn中,sklearn.preprocessing.StandardScaler是一种用于特征归一化的方法。
可解释性
人类能够理解决策原因的程度
knn算法实例1
import math
movie_data = {"宝贝当家": [45, 2, 9, "喜剧片"],
"美人鱼": [21, 17, 5, "喜剧片"],
"澳门风云3": [54, 9, 11, "喜剧片"],
"功夫熊猫3": [39, 0, 31, "喜剧片"],
"谍影重重": [5, 2, 57, "动作片"],
"叶问3": [3, 2, 65, "动作片"],
"伦敦陷落": [2, 3, 55, "动作片"],
"我的特工爷爷": [6, 4, 21, "动作片"],
"奔爱": [7, 46, 4, "爱情片"],
"夜孔雀": [9, 39, 8, "爱情片"],
"代理情人": [9, 38, 2, "爱情片"],
"新步步惊心": [8, 34, 17, "爱情片"]}
# 测试样本 唐人街探案": [23, 3, 17, "?片"]
#下面为求与数据集中所有数据的距离代码:
x = [23, 3, 17]
KNN = []
for key, v in movie_data.items():
d = math.sqrt((x[0] - v[0]) ** 2 + (x[1] - v[1]) ** 2 + (x[2] - v[2]) ** 2)
KNN.append([key, round(d, 2)])
# 输出所用电影到 唐人街探案的距离
print(KNN)
#按照距离大小进行递增排序
KNN.sort(key=lambda dis: dis[1])
#选取距离最小的k个样本,这里取k=5;
KNN=KNN[:5]
print(KNN)
#确定前k个样本所在类别出现的频率,并输出出现频率最高的类别
labels = {"喜剧片":0,"动作片":0,"爱情片":0}
for s in KNN:
label = movie_data[s[0]]
labels[label[3]] += 1
labels =sorted(labels.items(),key=lambda l: l[1],reverse=True)
print(labels,labels[0][0],sep='\n')
原文链接:https://blog.csdn.net/sinat_30353259/article/details/80901746
KNN算法实例2
# 导包
import operator
from numpy import *
import numpy as np
from sklearn import datasets # 数据集
from sklearn.model_selection import train_test_split
# 加载数据
iris = datasets.load_iris()
x = iris.data
y = iris.target
# 划分数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=2000)
#f 手写kNN算法
def classify0(inX,dataSet,labels,k):
dataSetSize = dataSet.shape[0]#查看矩阵的维度
diffMat = tile(inX,(dataSetSize,1)) - dataSet
#tile(数组,(在行上重复次数,在列上重复次数))
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
#sum默认axis=0,是普通的相加,axis=1是将一个矩阵的每一行向量相加
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
#sort函数按照数组值从小到大排序
#argsort函数返回的是数组值从小到大的索引值
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
#get(key,k),当字典dic中不存在key时,返回默认值k;存在时返回key对应的值
sortedClassCount = sorted(classCount.items(),
key=operator.itemgetter(1),reverse=True)
#python2中用iteritems,python3中用items代替;operator.itemgetter(k),返回第k个域的值
return sortedClassCount[0][0]
# 测试
pre_test = [classify0(data,x_train,y_train,3) for data in x_test]
correct = np.count_nonzero((pre_test==y_test)==True)
print('准确率%.3f'%(correct/(len(y_test))))
# 准确率0.921
# 可以通过修改random_state,提高准确率
KNN sk-learn库运用
# 导包
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
#加载数据
iris = datasets.load_iris()
x = iris.data
y = iris.target
#划分数据集
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=42)
#调用sklearn库函数
clf = KNeighborsClassifier(n_neighbors=3)
clf.fit(x_train,y_train)
pre_test = clf.predict(x_test)
correct = np.count_nonzero((pre_test==y_test)==True)
print('准确率%.3f'%(correct/(len(y_test))))
#准确率1.000
#这里并不是库函数比手写kNN效果要好,而是数据集划分不同,这里random_state=42
random_state设定
种子(seed)值会控制生成伪随机数所用公式产生的第一个值,由于公式是确定的,改变种子也就设置了整个要生成的序列。
seed()的参数可以是任意可散列对象。默认会使用平台特定的随机源(如果有的话)。否则,会使用当前时间。
sklearn.model_selection.train_test_split随机划分训练集和测试集
一般形式:
train_test_split是交叉验证中常用的函数,功能是从样本中随机的按比例选取train data和testdata,形式为:
X_train,X_test, y_train, y_test =
cross_validation.train_test_split(train_data,train_target,test_size=0.4, random_state=0)
参数解释:
train_data:所要划分的样本特征集
train_target:所要划分的样本结果
test_size:样本占比,如果是整数的话就是样本的数量
random_state:是随机数的种子。
随机数种子:其实就是该组随机数的编号,在需要重复试验的时候,保证得到一组一样的随机数。比如你每次都填1,其他参数一样的情况下你得到的随机数组是一样的。但填0或不填,每次都会不一样。
随机数的产生取决于种子,随机数和种子之间的关系遵从以下两个规则:
种子不同,产生不同的随机数;种子相同,即使实例不同也产生相同的随机数。
Lambda用法

round用法
返回浮点数x的四舍五入值。
x – 数值表达式。
n – 数值表达式,表示从小数点位数。
sklearn.metrics中的评估方法
accuracy_score,recall_score,roc_curve,roc_auc_score,confusion_matrix

① accuracy_score
概念:分类准确率分数是指所有分类正确的百分比。分类准确率这一衡量分类器的标准比较容易理解,但是它不能告诉你响应值的潜在分布,并且它也不能告诉你分类器犯错的类型。
不适用场景:在正负样本不平衡的情况下,准确率这个评价指标有很大的缺陷。比如在互联网广告里面,点击的数量是很少的,一般只有千分之几,如果用acc,即使全部预测成负类(不点击)acc也有 99% 以上,没有意义。因此,单纯靠准确率来评价一个算法模型是远远不够科学全面的。在类别不平衡没那么太严重时,该指标具有一定的参考意义。
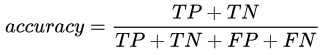
y_true:真实标签。二分类和多分类情况下是一列,多标签情况下是标签的索引。
y_pred:预测标签。二分类和多分类情况下是一列,多标签情况下是标签的索引。
normalize:bool, optional (default=True),如果是false,正确分类的样本的数目(int);如果为true,返回正确分类的样本的比例,必须严格匹配真实数据集中的label,才为1,否则为0。
sklearn.metrics.accuracy_score(y_true, y_pred, *, normalize=True, sample_weight=None)
>>>import numpy as np
>>>from sklearn.metrics import accuracy_score
>>>y_pred = [0, 2, 1, 3]
>>>y_true = [0, 1, 2, 3]
>>>accuracy_score(y_true, y_pred)
0.5
>>>accuracy_score(y_true, y_pred, normalize=False)
2
② recall_score
召回率 =提取出的正确信息条数 /样本中的信息条数。通俗地说,就是所有准确的条目有多少被检索出来了。
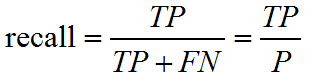
sklearn.metrics.recall_score(y_true, y_pred, labels=None, pos_label=1,average=‘binary’, sample_weight=None)
将一个二分类matrics拓展到多分类或多标签问题时,我们可以将数据看成多个二分类问题的集合,每个类都是一个二分类。接着,我们可以通过跨多个分类计算每个二分类metrics得分的均值,这在一些情况下很有用。你可以使用average参数来指定。
macro:计算二分类metrics的均值,为每个类给出相同权重的分值。当小类很重要时会出问题,因为该macro-averging方法是对性能的平均。另一方面,该方法假设所有分类都是一样重要的,因此macro-averaging方法会对小类的性能影响很大。
各类的precision,recall,f1加和求平均
weighted:对于不均衡数量的类来说,计算二分类metrics的平均,通过在每个类的score上进行加权实现。
对每一类别的f1_score进行加权平均,权重为各类别数在y_true中所占比例
micro:给出了每个样本类以及它对整个metrics的贡献的pair(sample-weight),而非对整个类的metrics求和,它会每个类的metrics上的权重及因子进行求和,来计算整个份额。Micro-averaging方法在多标签(multilabel)问题中设置,包含多分类,此时,大类将被忽略。
计算总体的TP, FN, FP
samples:应用在multilabel问题上。它不会计算每个类,相反,它会在评估数据中,通过计算真实类和预测类的差异的metrics,来求平均(sample_weight-weighted)
average:average=None将返回一个数组,它包含了每个类的得分。
精确率、精度(Precision)
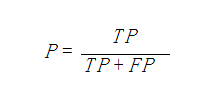
Macro Average
宏平均是指在计算均值时使每个类别具有相同的权重,最后结果是每个类别的指标的算术平均值。(先算各自TP概率加起来除平均)
参考地址:https://blog.csdn.net/hfutdog/article/details/88085878
Micro Average
微平均是指计算多分类指标时赋予所有类别的每个样本相同的权重,将所有样本合在一起计算各个指标。
如果每个类别的样本数量差不多,那么宏平均和微平均没有太大差异
如果每个类别的样本数量差异很大,那么注重样本量多的类时使用微平均,注重样本量少的类时使用宏平均
如果微平均大大低于宏平均,那么检查样本量多的类来确定指标表现差的原因
如果宏平均大大低于微平均,那么检查样本量少的类来确定指标表现差的原因
ROC
ROC曲线指受试者工作特征曲线/接收器操作特性(receiver operating characteristic,ROC)曲线,是反映灵敏性和特效性连续变量的综合指标,是用构图法揭示敏感性和特异性的相互关系,它通过将连续变量设定出多个不同的临界值,从而计算出一系列敏感性和特异性。ROC曲线是根据一系列不同的二分类方式(分界值或决定阈),以真正例率(也就是灵敏度)(True Positive Rate,TPR)为纵坐标,假正例率(1-特效性)(False Positive Rate,FPR)为横坐标绘制的曲线。
(还没写完···没学到~)
tile用法
>>> import numpy
>>> numpy.tile([0,0],5)#在列方向上重复[0,0]5次,默认行1次
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
>>> numpy.tile([0,0],(1,1))#在列方向上重复[0,0]1次,行1次
array([[0, 0]])















 7383
7383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









