







参考链接:https://hands1ml.apachecn.org/2/#_11
创建测试集
继续你的数据工作之旅。
现在你需要再仔细调查下数据以决定使用什么算法。
如果你查看了测试集,就会不经意地按照测试集中的规律来选择某个特定的机器学习模型。再当你使用测试集来评估误差率时,就会导致评估过于乐观,而实际部署的系统表现就会差。这称为数据透视偏差。
理论上,创建测试集很简单:只要随机挑选一些实例,一般是数据集的 20%,放到一边:
import numpy as np
def split_train_test(data, test_ratio):
shuffled_indices = np.random.permutation(len(data))
test_set_size = int(len(data) * test_ratio)
test_indices = shuffled_indices[:test_set_size]
train_indices = shuffled_indices[test_set_size:]
return data.iloc[train_indices], data.iloc[test_indices]
再调用函数
train_set, test_set = split_train_test(housing, 0.2)
print(len(train_set), "train +", len(test_set), "test")
就可以得到训练集加上测试集

但是,这个方法并不完美,因为如果再次运行程序,就会产生一个不同的测试集。多次运行之后,你(或你的机器学习算法)就会得到整个数据集,这是需要避免的。
解决的办法之一是保存第一次运行得到的测试集,并在随后的过程加载。另一种方法是在调用np.random.permutation()之前,设置随机数生成器的种子(比如np.random.seed(42)),以产生总是相同的洗牌指数(shuffled indices)。
np.random.seed(42)
但是如果数据集更新,这两个方法都会失效。
一个通常的解决办法是使用每个实例的 ID 来判定这个实例是否应该放入测试集(假设每个实例都有唯一并且不变的 ID)。
例如,你可以计算出每个实例 ID 的哈希值,只保留其最后一个字节,如果该值小于等于 51(约为 256 的 20%),就将其放入测试集。这样可以保证在多次运行中,测试集保持不变,即使更新了数据集。新的测试集会包含新实例中的 20%,但不会有之前位于训练集的实例。下面是一种可用的方法:
import hashlib
def test_set_check(identifier, test_ratio, hash):
return hash(np.int64(identifier)).digest()[-1] < 256 * test_ratio
def split_train_test_by_id(data, test_ratio, id_column, hash=hashlib.md5):
ids = data[id_column]
in_test_set = ids.apply(lambda id_: test_set_check(id_, test_ratio, hash))
return data.loc[~in_test_set], data.loc[in_test_set]
使用新的方法生成训练集和测试集,不过,房产数据集没有 ID 这一列。最简单的方法是使用行索引作为 ID:
housing_with_id = housing.reset_index() # adds an `index` column
train_set, test_set = split_train_test_by_id(housing_with_id, 0.2, "index")
对于这边代码,你的解释是:
housing_with_id = housing.reset_index():
这行代码将原始的 housing DataFrame 重新索引,并将重新索引后的 DataFrame 赋值给 housing_with_id。重新索引会在 DataFrame 中添加一个名为 index 的新列,并将原始的索引列(如果有的话)移动到列中,然后用新的整数索引替换原始的索引。
split_train_test_by_id(housing_with_id, 0.2, “index”):
这行代码调用了一个名为 split_train_test_by_id 的函数,并传入了三个参数:重新索引后的 DataFrame housing_with_id、测试集的比例 0.2,以及用于拆分数据集的列名 “index”。这个函数的作用是按照指定的列(在这里是 “index”)将数据集拆分为训练集和测试集,并返回拆分后的训练集和测试集。
目前为止,我们采用的都是纯随机的取样方法。当你的数据集很大时(尤其是和属性数相比),这通常可行;但如果数据集不大,就会有采样偏差的风险。当一个调查公司想要对 1000 个人进行调查,它们不是在电话亭里随机选 1000 个人出来。调查公司要保证这 1000 个人对人群整体有代表性。例如,美国人口的 51.3% 是女性,48.7% 是男性。所以在美国,严谨的调查需要保证样本也是这个比例:513 名女性,487 名男性。这称作分层采样(stratified sampling):将人群分成均匀的子分组,称为分层,从每个分层去取合适数量的实例,以保证测试集对总人数有代表性。如果调查公司采用纯随机采样,会有 12% 的概率导致采样偏差:女性人数少于 49%,或多于 54%。不管发生那种情况,调查结果都会严重偏差。
假设专家告诉你,收入中位数是预测房价中位数非常重要的属性。你可能想要保证测试集可以代表整体数据集中的多种收入分类。因为收入中位数是一个连续的数值属性,你首先需要创建一个收入类别属性。再仔细地看一下收入中位数的柱状图
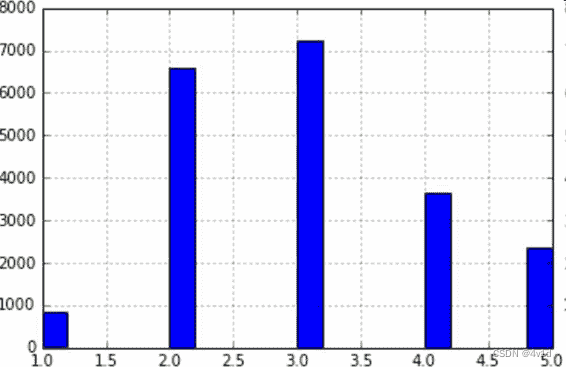
(该图是对收入中位数处理过后的图,详情可见机器学习案例:加州房产价格(二)):
大多数的收入中位数的值聚集在 2-5(万美元),但是一些收入中位数会超过
6。数据集中的每个分层都要有足够的实例位于你的数据中,这点很重要。否则,对分层重要性的评估就会有偏差。这意味着,你不能有过多的分层,且每个分层都要足够大。通过将收入中位数除以
1.5(以限制收入分类的数量),创建了一个收入类别属性,用ceil对值舍入(以产生离散的分类),然后将所有大于 5 的分类归入到分类 5:
housing["income_cat"] = np.ceil(housing["median_income"] / 1.5)
housing["income_cat"].where(housing["income_cat"] < 5, 5.0, inplace=True)
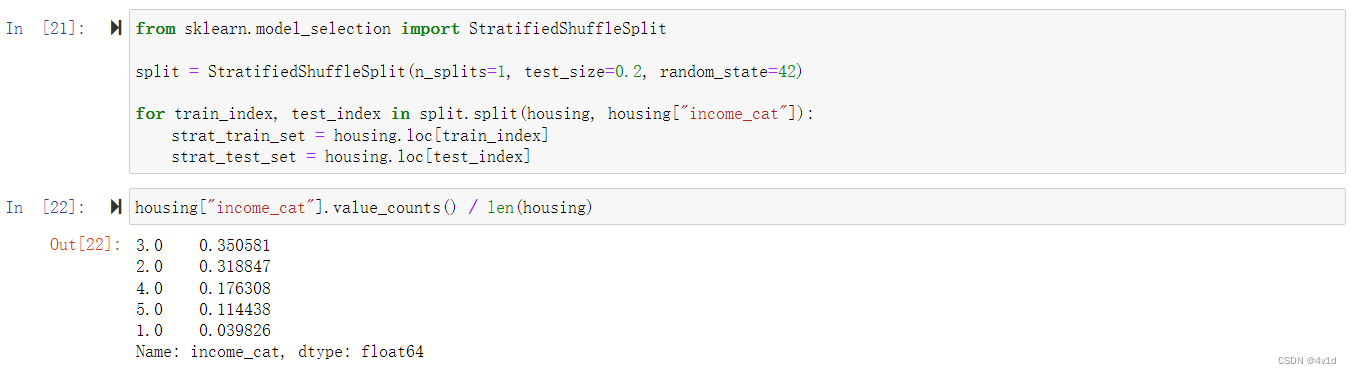
现在进行分层采样
from sklearn.model_selection import StratifiedShuffleSplit
split = StratifiedShuffleSplit(n_splits=1, test_size=0.2, random_state=42)
for train_index, test_index in split.split(housing, housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
最后,需要删除income_cat属性,使数据回到初始状态:
for set in (strat_train_set, strat_test_set):
set.drop(["income_cat"], axis=1, inplace=True)
我们用了大量时间来生成测试集的原因是:测试集通常被忽略,但实际是机器学习非常重要的一部分。还有,生成测试集过程中的许多思路对于后面的交叉验证讨论是非常有帮助的。接下来进入下一阶段:数据探索。















 2846
2846

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









