







为机器学习算法准备数据
现在来为机器学习算法准备数据。不要手工来做,你需要写一些函数,理由如下:
1.函数可以让你在任何数据集上(比如,你下一次获取的是一个新的数据集)方便地进行重复数据转换。
2.你能慢慢建立一个转换函数库,可以在未来的项目中复用。
3.在将数据传给算法之前,你可以在实时系统中使用这些函数。
先回到干净的训练集(通过再次复制strat_train_set),将预测量和标签分开
housing = strat_train_set.drop("median_house_value", axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
数据清洗
大多机器学习算法不能处理缺失的特征,因此先创建一些函数来处理特征缺失的问题。
通过前面的工作,你应该注意到了属性total_bedrooms有一些缺失值,缺失值的处理是需要着重解决的。
那现在有三个解决选项:
1.去掉对应的街区;
2.去掉整个属性;
3.进行赋值(0、平均值、中位数等等)
# 用DataFrame的dropna(),drop(),和fillna()方法,可以方便地实现:
housing.dropna(subset=["total_bedrooms"]) # 选项 1
housing.drop("total_bedrooms", axis=1) # 选项 2
median = housing["total_bedrooms"].median()
housing["total_bedrooms"].fillna(median) # 选项 3
总结一下这三种办法

如果选择选项 3,你需要计算训练集的中位数,用中位数填充训练集的缺失值,不要忘记保存该中位数。后面用测试集评估系统时,需要替换测试集中的缺失值,也可以用来实时替换新数据中的缺失值。
Scikit-Learn 提供了一个方便的类来处理缺失值:Imputer。
下面是其使用方法:首先,需要创建一个Imputer实例,指定用某属性的中位数来替换该属性所有的缺失值:
from sklearn.preprocessing import Imputer
imputer = Imputer(strategy="median")
因为只有数值属性才能算出中位数,所以我们需要先创建一份不包括文本属性ocean_proximity的数据副本,再用fit()方法将imputer实例拟合到训练数据
housing_num = housing.drop("ocean_proximity", axis=1)
imputer.fit(housing_num)

imputer计算出了每个属性的中位数,并将结果保存在了实例变量statistics_中。
虽然此时只有属性total_bedrooms存在缺失值,但我们不能确定在以后的新的数据中会不会有其他属性也存在缺失值,所以安全的做法是将imputer应用到每个数值:

现在,你就可以使用这个“训练过的”imputer来对训练集进行转换,将缺失值替换为中位数,结果是一个包含转换后特征的普通的 Numpy 数组
X = imputer.transform(housing_num)
处理文本和类别属性
前面,我们丢弃了类别属性ocean_proximity,因为它是一个文本属性,不能计算出中位数。
大多数机器学习算法更喜欢和数字打交道,所以让我们把这些文本标签转换为数字。
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder()
可以查看映射表,编码器是通过属性classes_来学习的(<1H OCEAN被映射为 0,INLAND被映射为 1
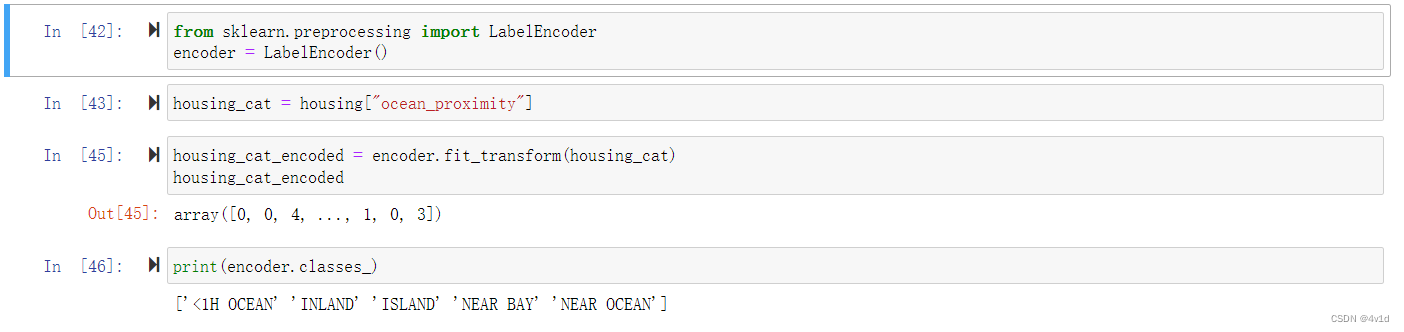
这种做法的问题是,ML 算法会认为两个临近的值比两个疏远的值要更相似。
显然这样不对(比如,分类 0 和分类 4 就比分类 0 和分类 1 更相似)。要解决这个问题,一个常见的方法是给每个分类创建一个二元属性:当分类是<1H OCEAN,该属性为 1(否则为 0),当分类是INLAND,另一个属性等于 1(否则为 0),以此类推。
这称作独热编码(One-Hot Encoding),因为只有一个属性会等于 1(热),其余会是 0(冷)。
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder()
housing_cat_1hot = encoder.fit_transform(housing_cat_encoded.reshape(-1,1))
housing_cat_1hot
如果你真的想将其转变成一个(密集的)NumPy 数组,只需调用toarray()方法
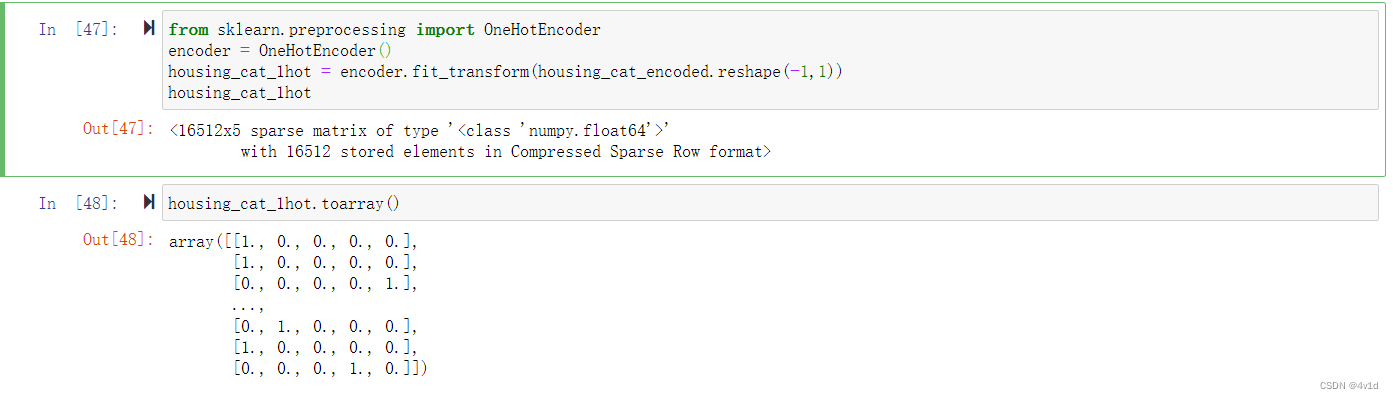
使用类LabelBinarizer,我们可以用一步执行这两个转换(从文本分类到整数分类,再从整数分类到独热向量):
from sklearn.preprocessing import LabelBinarizer
encoder = LabelBinarizer()
housing_cat_1hot = encoder.fit_transform(housing_cat)
housing_cat_1hot
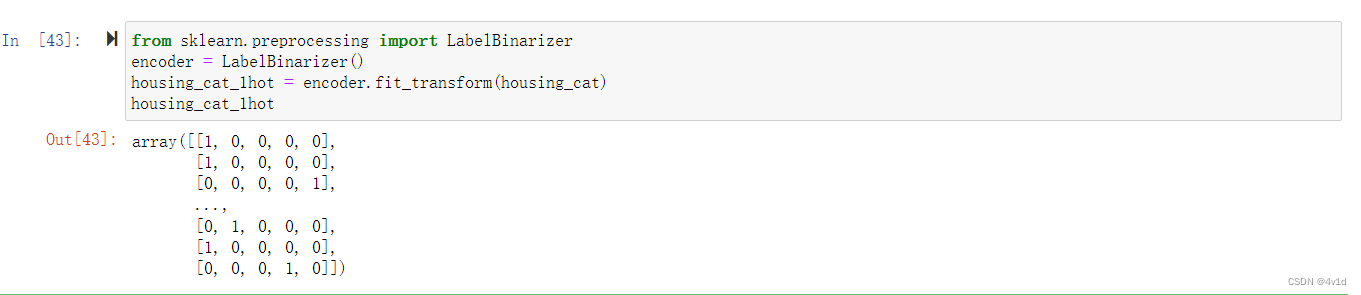
注意默认返回的结果是一个密集 NumPy 数组。向构造器LabelBinarizer传递sparse_output=True,就可以得到一个稀疏矩阵。















 2529
2529











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









