







Redis缓存穿透、击穿、雪崩及其解决方案
过期时间
缓存穿透
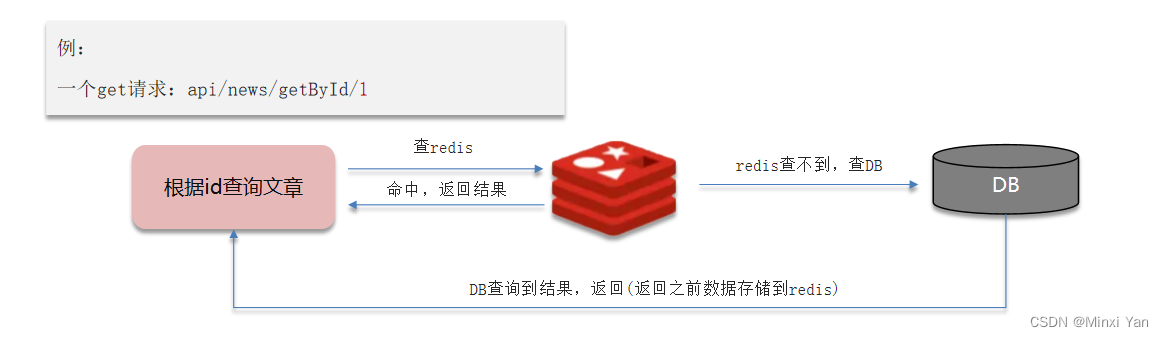
缓存穿透是指查询一个一定不存在的数据,由于缓存不命中,导致请求直接访问数据库,这将导致大量的请求打到数据库上,可能会导致数据库压力过大。
解决方案:
-
缓存空值
当查询结果为空时,也将结果进行缓存**,但是设置一个较短的过期时间**。这样在接下来的一段时间内,如果再次请求相同的数据,就可以直接从缓存中获取,而不是再次访问数据库。但这种方式在应对大量恶意请求时,可能会导致缓存系统存在大量的内存占用。
优点:简单
缺点:消耗内存,可能会发生不一致的问题 -
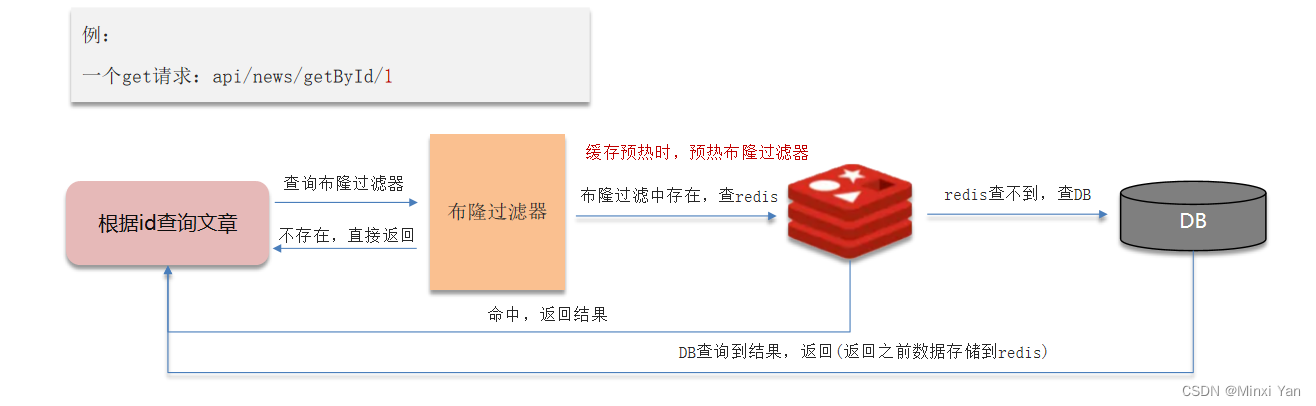
使用布隆过滤器
布隆过滤器是一种数据结构,用于快速判断一个元素是否存在于一个集合中。通过布隆过滤器,可以过滤掉不存在的数据,避免直接访问数据库。但布隆过滤器存在一定的误判率(大约0.006%)。这种方法的误判率主要来源于哈希函数的冲突,即不同的数据经过哈希函数映射后可能会落在同一个位置上,导致该位置被错误地标记为1。Bitmap数组越小误判率就越大,数组越大误判率就越小,但是同时带来了更多的内存消耗。
布隆过滤器的原理
- 数据结构:布隆过滤器由一个很长的二进制向量(位数组),也就是bitmap,和一系列随机映射函数(哈希函数)组成。
- 加入元素:当一个元素被加入集合时,通过K个散列函数(hash)将这个元素映射成位数组中的K个点,并将这些点置为1。
- 检索元素:检索时,查看这K个点是否都是1,也要进行K个哈希,只是在检索阶段不更改,只比对。如果其中任何一个点为0,则被检元素一定不在集合中;如果都是1,则被检元素很可能在集合中(但存在误判的可能性)。
优点:内存占用较少,没有多余key
缺点:实现复杂,存在误判
布隆过滤器的实现方案:
Redisson、Gauva(Java)
击穿
缓存击穿是指某个key非常热,访问非常频繁,在高并发访问的情况下,当这个key在失效(可能expire过期了,也可能LRU淘汰了)的瞬间,大量的请求进来,直接请求到了数据库,导致数据库压力骤增。
解决方案:
- 互斥锁:当缓存失效时,使用锁机制来避免多个相同的请求同时访问数据库,只让一个请求去加载数据,其他请求等待。
当缓存失效时,不是立即去加载数据库中的数据,而是先尝试获取一个分布式锁。如果成功获取到锁,则去数据库中查询数据,查询后将数据放到缓存中,并释放锁;如果获取锁失败,则等待一段时间后重试或者返回空值或默认值。这样可以确保同一时间只有一个请求去加载数据库中的数据,其他请求只需要等待即可。
-
逻辑过期:为每个key设置一个逻辑过期时间,当发现key即将过期时,通过后台异步线程主动刷新缓存。
逻辑过期时间指的是在缓存中保留数据,但通过某种方式标记该数据为“过期”,即不再被视为最新或有效。
为每个 key 设置一个逻辑过期时间,而不是依赖于缓存系统本身的过期机制。在逻辑过期时间到达之前,后台异步线程会主动刷新缓存。
具体实现时,可以有一个后台任务定时扫描所有缓存 key 的逻辑过期时间,如果发现某个 key 的逻辑过期时间即将到达,就主动从数据库中加载数据并更新缓存。这样可以保证在缓存失效之前,新的数据已经被加载到缓存中,从而避免了缓存击穿的问题。
另外,当请求发现缓存失效时,可以先返回一个空值或默认值,并触发一个异步任务去加载数据并更新缓存。这样虽然第一个请求会返回空值或默认值,但后续的请求就可以从缓存中获取数据了。
需要注意的是,逻辑过期方案需要保证后台异步线程能够及时刷新缓存,否则在大量请求同时到达时仍然可能发生缓存击穿。同时,逻辑过期方案也需要考虑如何处理并发加载同一 key 数据的情况,以避免数据不一致的问题。
雪崩
缓存雪崩是指在同一时段大量的缓存key同时失效或者Redis服务宕机,导致大量请求到达数据库,带来巨大压力。
这里要注意雪崩与击穿的区别,雪崩是一个热Key失效,而雪崩是大量的Key同时失效。
解决方案:
- 分散缓存失效时间:给不同的Key的TTL添加随机值,降低缓存过期时间的重复率,避免集体失效。
- Redis集群:利用Redis集群提高服务的可用性,比如哨兵模式、集群模式。
- 哨兵模式(Sentinel):用于监控Redis主从服务器运行状况,当主服务器宕机时,能够自动将其中一台从服务器升级为主服务器,保证服务的持续性。
- 集群模式(Cluster):将数据分散存储在多个Redis节点上,每个节点都存储了部分数据,通过分片策略实现数据的读写。
- 降级限流策略:给缓存业务添加降级限流策略,比如可以在nginx或spring cloud gateway中处理。
- 多级缓存:给业务添加多级缓存,比如使用Guava或Caffeine作为一级缓存,redis作为二级缓存等。
- 一级缓存:通常使用内存型缓存,如Guava Cache、Caffeine等,存储热点数据和常用数据。
- 二级缓存:使用Redis等分布式缓存,存储更多数据,同时提供数据持久化和容灾能力。
- 数据库:作为数据的最终存储,当缓存中不存在所需数据时,从数据库中获取。















 432
432











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









