






Chapter 1 时间复杂度
一、认识时间复杂度
1.常数时间的操作
一个操作如果和样本的数据量没有关系,每次都是固定时间内完成的操作,叫做常数操作。 时间复杂度为一个算法流程中,常数操作数量的一个指标。常用O(读作big O)来表示。具体来说,先要对一个算法流程非常熟悉,然后去写出这个算法流程中,发生了多少常数操作,进而总结出常数操作数量的表达式。 (取数组中i位置的值,就是常数操作,因为和数组的大小n无关)
1)在表达式中,只要高阶项,不要低阶项,也不要高阶项的系数,剩下的部分如果为f(N),那么时间复杂度为O(f(N))。
2)评价一个算法流程的好坏,先看时间复杂度的指标,然后再分析不同数据样本下的实际运行时间,也就是“常数项时间”。
二、不同排序时间复杂度
1.选择排序、冒泡排序细节的讲解与复杂度分析
时间复杂度O(N^2),额外空间复杂度O(1)
(1)选择排序
在未排序的部分找到最小值,放到已经排序的部分的末尾:
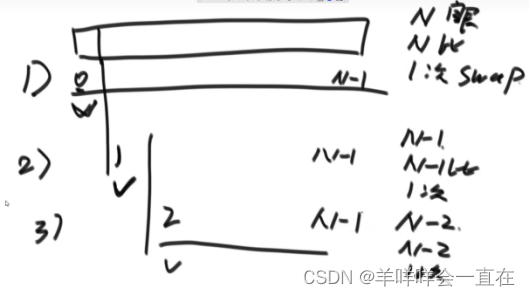

//选择排序:注意,交换的时候记录的是下标,所以设置的初始变量也是下标
void selectSort(int arr[],int len){
int index;
for(int i=0;i<len;i++){
index=i;//从i开始
for(int j=i;j<len;j++){
index=arr[j]<arr[index]?j:index;
}
swap(arr,i,index);
}
}
(2)冒泡排序
每次都会将未排序部分的最大值,移动到排序部分的最小界限:
void bubbleSort(int arr[],int len){
for(int i=len-2;i>=1;i--){
for(int j=0;j<=i;j++){
if(arr[j+1]<arr[j]){
swap(arr,j,j+1);
}
}
}
}
2.插入排序细节的讲解与复杂度分析时间复杂度
O(N^2),额外空间复杂度O(1)算法流程,按照最差情况来估计时间复杂度
(1)插入排序
每次循环做到前面的几个有序,直到0-n范围内有序:插入排序的效果和原来数据的分布是有关系的,当原来的数组就是有序的时,每次调整的复杂度为常数1,时间复杂度最佳为n,最坏的时间复杂度是完全倒序的情况,由于按照最差的情况估计时间复杂度,所以,时间复杂度为O(n^2)。
//插入排序
void insertSort(int arr[],int len){
for(int i=1;i<len;i++){
for(int j=i;j>0;j--){
if(arr[j]<arr[j-1]){
swap(arr,j,j-1);
}
}
}
}
3.二分法的详解与扩展
1)在一个有序数组中,找某个数是否存在
二分查找策略:log(n)
// 二分查找
int binarySearch(int arr[], int s, int e, int number)
{
if (s > e)
{
cout << "not exist number: " << number << endl;
return -1;
}
int m = s + (e - s) >>1;
if (arr[m] == number)
{
cout << "the index of 'm' is " << m << endl;
return m;
}
else if (arr[m] < number)
{
return binarySearch(arr, m + 1,e , number);
}
else
{
return binarySearch(arr, s, m-1, number);
}
}
2)在一个有序数组中,找>=某个数最左侧的位置
int binaryLessRight(int arr[], int s, int e, int number,int record)
{
if (s > e)
{
return record;
}
int m = s + ((e - s) >>1);
if (arr[m] >= number)//往左边找
{
record=m;
return binaryLessRight(arr, s, m-1, number,record);
}
else
{
return binaryLessRight(arr, m + 1,e , number,record);
}
}
//record 初始值为-1
void lessRight(int arr[], int s, int e, int number,int record){
int index= binaryLessRight(arr,s,e,number,record);
if(index==-1){
cout<<"not exist!!"<<endl;
}else{
cout<<"index :"<<index<<endl;
}
}
3)局部最小值问题(旋转数组同样使用)
二分法在考虑时,大多数考虑有序数组的情况,但是实际上不是有序数组也同样适用,在局部最小值问题中就是这样的考虑角度。
图 1 局部最小就在两端
图 2 一定有局部最小值,查看中值

图 3 二分查找局部最小判断依据
//求局部最小值:没有重复值
int areaMinBinary(int arr[],int s,int e){
// 1.判断两端
if(s<e){
int m=s+((e-s)>>1);
if(arr[m]>arr[m+1]){
return areaMinBinary(arr,m,e);
}
if(arr[m-1]<arr[m]){
return areaMinBinary(arr,s,m);
}
return m;
}
else{
return -1;
}
}
int areaMin(int arr[],int s,int e){
// 1.判断两端
int index;
if(s<e){
if(arr[s]<arr[s+1]){
index=s;
cout<<"局部最小值的index为:"<<index<<endl;
return s;
}
if(arr[e-1]>arr[e]){
index=e;
cout<<"局部最小值的index为:"<<index<<endl;
return e;
}
// 判断medium
index =areaMinBinary(arr,s,e);
cout<<"局部最小值的index为:"<<index<<endl;
return index;
}else{
cout<<"没有局部最小值"<<endl;//一般只有一个数值的情况
return -1;
//没有局部最小值,返回index=-1
}
}
4)排序旋转数组:二分判断
4.异或运算的性质与扩展
1)0^N == N N^N == 0 :无进位相加2二进制下最右边的1
Rightone=(~a+1)&a
2)Quchu
3)异或运算满足交换律和结合率
4)不用额外变量交换两个数

最好不要使用这种写法,当两个交换的数在同一个内存时,会出现最后的数都是0的情况,我吃过这种亏,所以还是使用带有临时变量的方法搞。
5)一个数组中有一种数出现了奇数次,其他数都出现了偶数次,怎么找到这一个数
所有数进行异或,最后得到的数,就是出现奇数次的数
int getUniqueOdd(int arr[], int len)
//我测,java写多了,数组的中括号要写在后面
{
// 1,2,2,3,3,3,4,4,1
// 相等的数异或为0,0和任何数异或结果为任何数字
int unique = 0;
for (int i = 0; i < len; i++)
{
unique = unique ^ arr[i];
}
cout << "Number occurred odd times: " << unique << endl;
return unique;
}
6)一个数组中有两种数出现了奇数次,其他数都出现了偶数次,怎么找到这两个数
void getDoubleOdd(int arr[],int len)
{
//当数组中有两个出现次数为奇数次的数字
int unique = 0;
for (int i = 0; i < len; i++)
{
unique = unique ^ arr[i];
}
//unique=a^b,既然两个数一定不一样,异或后的结果中一定有1
int rightOne=unique&(~unique+1);
int a=0;
int b=0;
for(int i=0;i<len;i++){
if(arr[i]&rightOne!=0){
a=a^arr[i];
}
}
b=a^unique;
cout<<"two Numbers occurred odd times: a= "<<a<<" b= "<<b<<endl;;
}
5.对数器的概念和使用
1)有一个你想要测的方法a,实现复杂度不好但是容易实现的方法b
2)实现一个随机样本产生器把方法a和方法b跑相同的随机样本,看看得到的结果是否一样。
3)如果有一个随机样本使得比对结果不一致,打印样本进行人工干预,改对方法a或者方法b
4)当样本数量很多时比对测试依然正确,可以确定方法a已经正确。
template <typename T>
vector<T> generateArr(int maxLength,int maxNumber){
int len=(T)(rand()%(maxLength+1));
vector<T> arr;
for(int i=0;i<len;i++){
arr.push_back((T)(rand()%(maxNumber+1)));
}
return arr;
}
template <typename T>
bool isEqual(vector<T> v1,vector<T>v2){
int len01=v1.size();
int len02=v2.size();
if(len01!=len02){return false;}
else{
for(int i=0;i<len01;i++){
if(v1[i]!=v2[i]){
return false;
break;
}
}
return true;
}
}
int maxLen=500;
int maxNumber=500;
int testTime=1;
for(int i=0;i<testTime;i++){
vector<int> arr01=generateArr<int>(maxLen,maxNumber);
vector<int> arr02=arr01;//直接复制就好了
insertSort(arr01,arr01.size());
bubbleSort(arr02,arr02.size());
// printVector(arr01);
// printVector(arr02);
isEqual(arr01,arr02);
}
6.剖析递归行为和递归行为时间复杂度的估算
1)用递归方法找一个数组中的最大值,系统上到底是怎么做的?
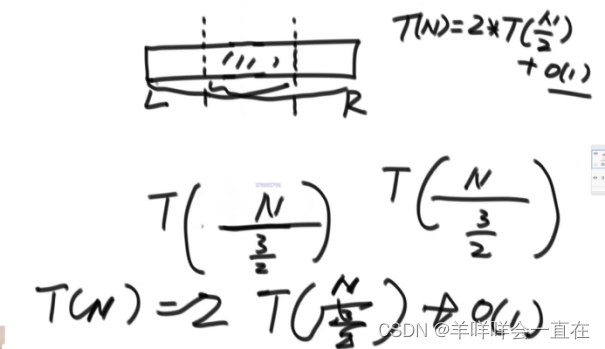
master公式的使用 :T(N) = a*T(N/b) + O(N^d)
a表示子问题的调用次数,子问题的规模N/b,O(N^d)表示除了子问题之外剩下的部分的时间复杂度,满足子问题等规模的递归都可以使用Master公式
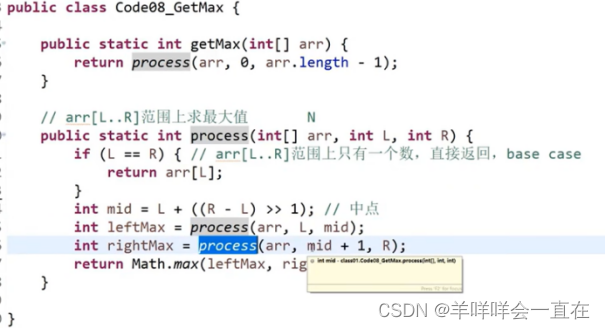

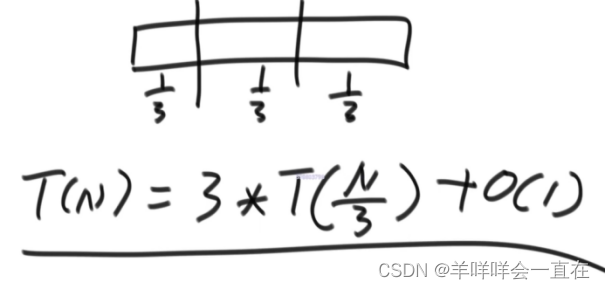
左侧2/3部分求最大值,右侧2/3求最大值,这种情况,仍然符合Master公式;分成三个部分,分别对三个区域求最大值,仍然符合;左侧1/3,右侧2/3,不符合Master公式;
1)log(b,a) > d -> 复杂度为O(N^log(b,a))
2)log(b,a) = d -> 复杂度为O(N^d * logN)
3)log(b,a) < d -> 复杂度为O(N^d)
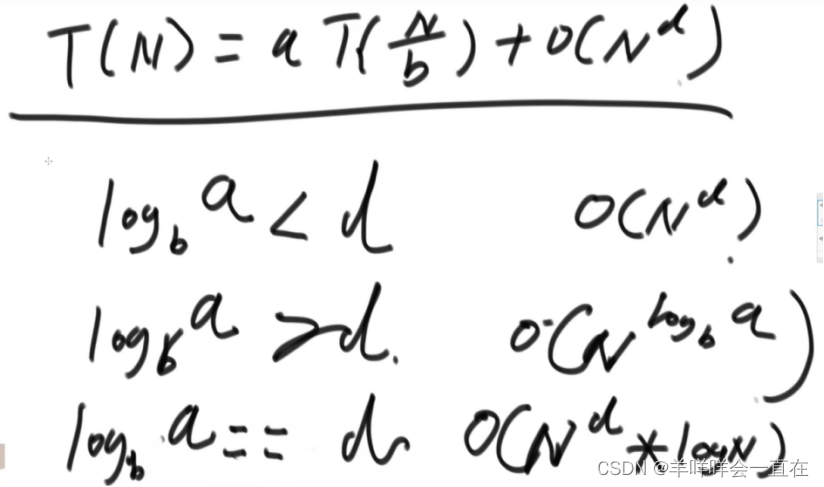
补充阅读:www.gocalf.com/blog/algorithm-complexity-and-master- theorem.html
说明二分求最大值的递归行为时间复杂度是O(N),等效于从左到右遍历求最大值
Chapter 02
一、归并排序
1)整体就是一个简单递归,左边排好序、右边排好序、让其整体有序
2)让其整体有序的过程里用了排外序方法(Merge,用到了辅助空间)
3)利用master公式来求解时间复杂度
4)归并排序的实质:时间复杂度O(N*logN),额外空间复杂度O(N)
template <typename T>
void merge(vector<T> &arr, int s, int e, int m)
{
// 左边有序,右边有序,merge
int p1 = s;
int p2 = m + 1;
int p0 = 0;
vector<T> tempArr(e - s + 1, 0);
while (p1 <= m && p2 <= e) // not overbounded
{
tempArr[p0++] = arr[p1] < arr[p2] ? arr[p1++] : arr[p2++];
}
while (p1 <= m)
{
tempArr[p0++] = arr[p1++];
}
while (p2 <= e)
{
tempArr[p0++] = arr[p2++];
}
// copyVector(arr, tempArr);
//TODO ! 这里每次copy就把原来的数组截断了,所以不能用Copy
p0=0;
while(s<=e){
arr[s++]=tempArr[p0++];
}
}
// 归并排序:Master公式--O(NlogN)
template <typename T>
void mergeSort(vector<T> &arr, int s, int e)
{
if (s >= e)
{
return;
}
else
{
int m = s + ((e - s) >> 1);
//注意在进行求中间值的时候,该用括号括起来的用括号
mergeSort(arr, s, m);
mergeSort(arr, m + 1, e);
merge(arr, s, e, m);
}
}
二、归并排序的扩展(小和问题和逆序对问题)
1.小和问题
在一个数组中,每一个数左边比当前数小的数累加起来,叫做这个数组的小和。求一个数组的小和。例子:[1,3,4,2,5] 1左边比1小的数,没有; 3左边比3小的数,1; 4左边比4小的数,1、3; 2左边比2小的数,1; 5左边比5小的数,1、3、4、2; 所以小和为1+1+3+1+1+3+4+2=16
// TODO 归并排序的推展问题:小和问题
template<typename T>
int mergeSum(vector<T> &arr ,int s,int e,int m){
int p1=s;
int p2=m+1;
int p0=0;
int minSum=0;
vector<T> tempArr(e-s+1,0);
while(p1<=m&&p2<=e){
minSum=arr[p1]<arr[p2] ? (e-p2+1)*arr[p1]+minSum:0+minSum;
tempArr[p0++]=arr[p1]<arr[p2] ? arr[p1++]:arr[p2++];
//merge过程产生小和,当两边相等时,一定是先拷贝右边的小和
}
while(p1<=m){
tempArr[p0++]=arr[p1++];
}
while(p2<=e){
tempArr[p0++]=arr[p2++];
}
//记得拷贝
p0=0;
while(s<=e){
arr[s++]=tempArr[p0++];
}
return minSum;
}
template <typename T>
int getMinSum(vector<T> &arr,int s,int e){
if(s>=e){
return 0;
}else{
//左边小和+右边小和+归并产生的小和
int m=s+((e-s)>>1);
return getMinSum(arr,s,m)+getMinSum(arr,m+1,e)+mergeSum(arr,s,e,m);
}
}
2.逆序对问题
在一个数组中,左边的数如果比右边的数大,则这两个数构成一个逆序对,请打印所有逆序对
基本上和小和问一致
三、堆
堆结构就是用数组实现的完全二叉树结构
完全二叉树中如果每棵子树的最大值都在顶部就是大根堆
完全二叉树中如果每棵子树的最小值都在顶部就是小根堆
堆结构的heapInsert与heapify操作
使用heapSize变化堆的长度
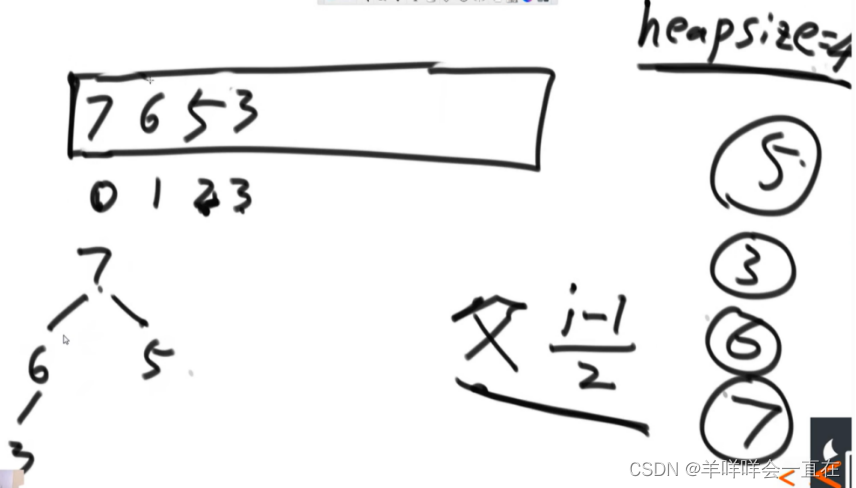
图 4 heapInsert
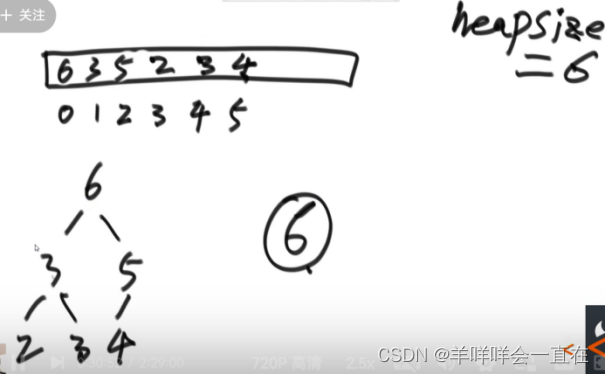
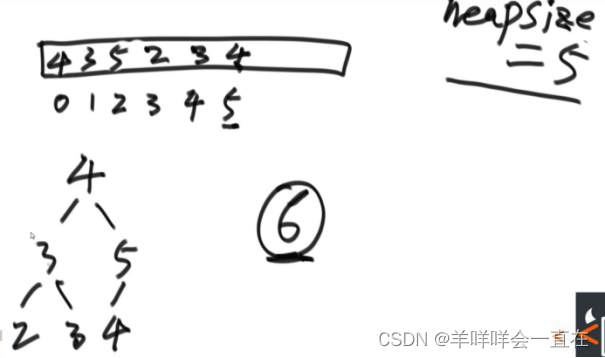
图 5 heapify过程
- 堆结构的增大和减少
- 优先级队列结构,就是堆结构,在C++中的数据结构为:
- #include Priority_queue<int ,vector,greater>
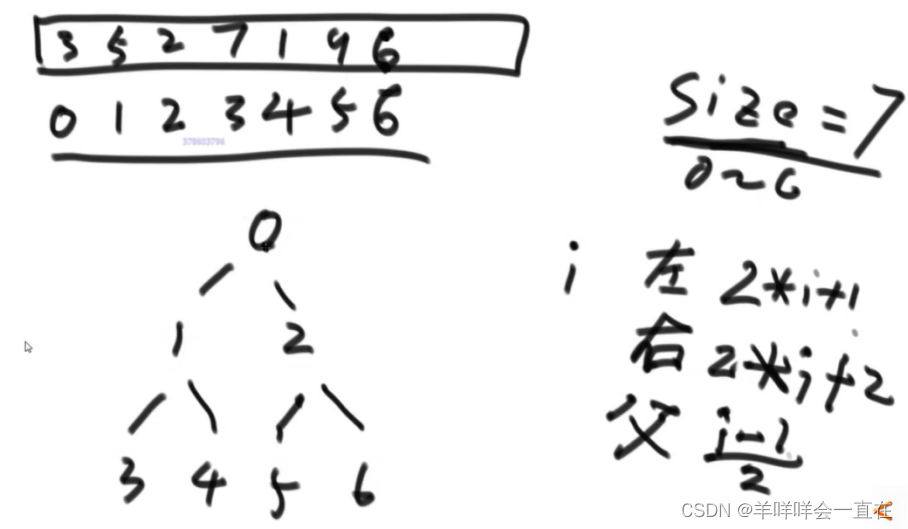
图 6 数组完全二叉树
1.堆排序
① 先让整个数组都变成大根堆结构,建立堆的过程:
1)从上到下的方法,时间复杂度为O(NlogN)
2)从下到上的方法,时间复杂度为O(N)
如果是堆排序,时间复杂度不变,以程序中时间复杂度最大的部分为标准,但是如果只要求形成大根堆的,通过从下网上进行heapy的操作可以实现加速
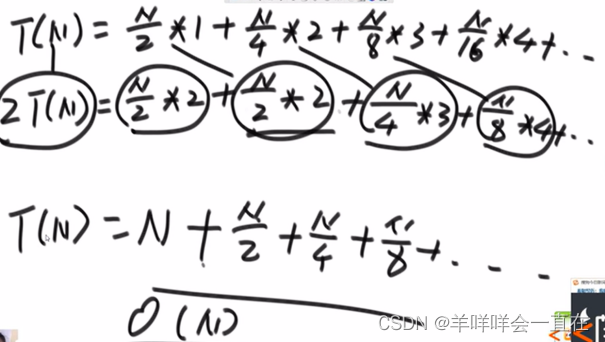
② 把堆的最大值和堆末尾的值交换,然后减少堆的大小之后,再去调整堆,一直周而复始,时间复杂度为O(NlogN) ,空间复杂度为O(1)
③ 堆的大小减小成0之后,排序完成
// TODO 堆排序问题
template <typename T>
void heapInsert(vector<T> &arr, int &heapSize)
{
// insert时检查是否比父亲大,大的时候需要进行swap
int index = heapSize;
while (arr[(index - 1) / 2] < arr[index])
{
swap(arr, (index - 1) / 2, index);
index = (index - 1) / 2;
}
heapSize++;
}
/// @brief
/// @tparam T
/// @param arr
/// @param heapSize 当前堆的大小
/// @param heapifyIndex 表示从哪个地方做heapify
template <typename T>
void heapify(vector<T> &arr, int heapSize, int heapifyIndex)
{
int index = heapifyIndex;
while (index * 2 + 1 < heapSize)
{
// 当有字节点时,才需要进行调整
int left = index * 2 + 1;
int right = left + 1;
int maxSonIndex = left;
if ((right < heapSize) && (arr[right] > arr[left]))
{
maxSonIndex = right; // 比较子节点
}
if (arr[maxSonIndex] < arr[index])
{
maxSonIndex = index; // 比较子节点最大和父节点
}
if (maxSonIndex == index)
{
break; // 不再需要进行比较
}
else
{
swap(arr, index, maxSonIndex);
// 进行交换
index = maxSonIndex;
}
}
}
template <typename T>
void heapSort(vector<T> &arr)
{
/*
1.调整大根堆:两种方案NlgN VS N
2.大根堆的最大和heapSize-1位置进行交换
3.heapify
*/
// meathod 01 :NlgN
/*int heapSize=0;
for(int i=0;i<arr.size();i++){
heapInsert(arr,heapSize);
}*/
int heapSize = arr.size();
for (int i = arr.size() - 1; i >= 0; i--)
{
heapify(arr, heapSize, i);
// 从下面开始进行调整
}
// cout<<"调整大根堆后的vector:"<<endl;
// printVector(arr);
swap(arr, 0, --heapSize);
// NlgN
while (heapSize > 0)
{
// 一直heapify到index=0;
heapify(arr, heapSize, 0);
swap(arr, 0, --heapSize);
}
// printVector(arr);
}
2.堆排序扩展题目
已知一个几乎有序的数组,几乎有序是指,如果把数组排好顺序的话,每个元素移动的距离可以不超过k,并且k相对于数组来说比较小。请选择一个合适的排序算法针对这个数据进行排序。
【解题】准备小根堆,假设K=7,遍历前8个数,小根堆的最小值一定是最小值,这样每次找最小值,这样就实现了数组的排序;
// TODO 优先级队列-->系统堆
// 基本有序问题的求解
template <typename T>
void nearlySort(vector<T> &arr, int k)
{
// 依次将前K个数进小根堆
priority_queue<int, vector<int>, greater<T>> que;
vector<int> tempArr;
// 优先级队列默认是大根堆,参数less<T>;小根堆参数是greater<T>
int i = 0;
int min = (arr.size() - 1) < k ? (arr.size() - 1) : k;
for (; i <= min; i++)
{
que.push(arr[i]);
}
int index = 0;
while (que.size() != 0)
{
tempArr.push_back(que.top());
que.pop();
if (i < arr.size())
{
que.push(arr[i++]);
}
}
arr.swap(tempArr);
}
四、快排思想-荷兰国旗问题 【partition划分】
1.问题一 大于小于区域
给定一个数组arr,和一个数num,请把小于等于num的数放在数 组的左边,大于num的数放在数组的右边。要求额外空间复杂度O(1),时间复杂度O(N)
2.问题二(荷兰国旗问题)
给定一个数组arr,和一个数num,请把小于num的数放在数组的 左边,等于num的数放在数组的中间,大于num的数放在数组的 右边。要求额外空间复杂度O(1),时间复杂度O(N)。
由于荷兰国旗为三种颜色,所以可以做出这样的划分。

五、不改进的快速排序
① 把数组范围中的最后一个数作为划分值,然后把数组通过荷兰国旗问题分成三个部分:
左侧<划分值、中间划分值、右侧>划分值
② 对左侧范围和右侧范围,递归执行分析
1)划分值越靠近两侧,复杂度越高;划分值越靠近中间,复杂度越低
2)可以轻而易举的举出最差的例子,所以不改进的快速排序时间复杂度为O(N^2)
六、随机快速排序(改进的快速排序)
1)在数组范围中,等概率随机选一个数作为划分值,然后把数组通过荷兰国旗问题分成三个部分:左侧<划分值、中间划分值、右侧>划分值
2)对左侧范围和右侧范围,递归执行
3)时间复杂度为O(N*logN);空间复杂度,由对于一个quickSort()函数会调用的栈所暂存的空间在logN的水平(每次记录中点的位置)
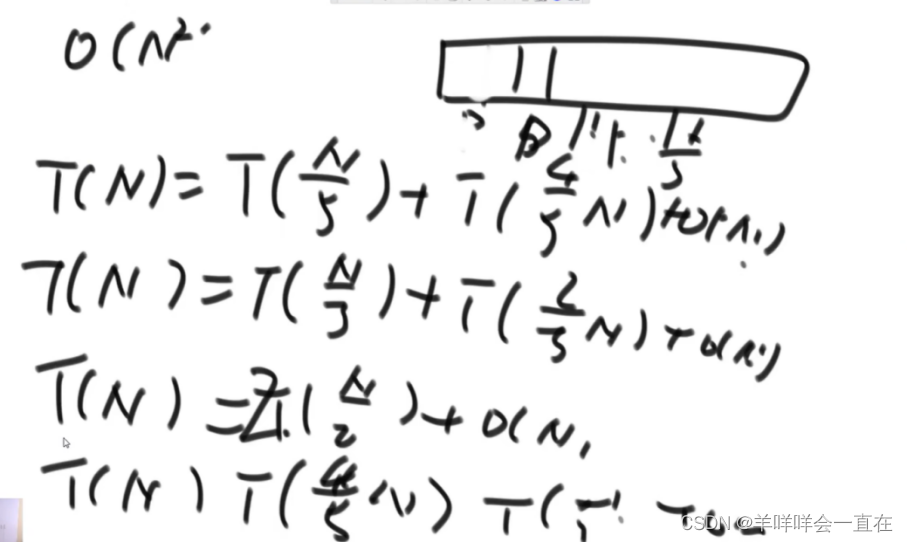
图 7 随机选择一个数作为划分:等概率事件出现各种情况
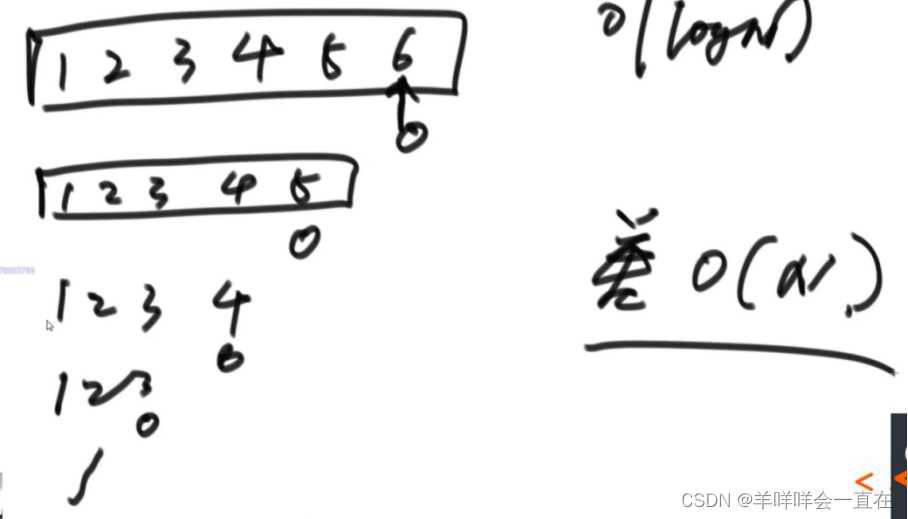
图 8 空间复杂度分析
六、随机快速排序:
随机选择划分值–>划分值被分为左边和右边,中间的位置确定不变,得到左划分和右划分–>小于区域左划分,大于区域做划分递归–》注意出口条件
//TODO 随机 快速排序
template <typename T>
pair<int,int> partition(vector<T> &arr,int s,int e){
int randIndex=s+(rand()%(e-s+1));
swap(arr,e,randIndex);//随机选择一个数,放在队尾,用来进行划分
int lessBound=s-1;
int moreBound=e+1;
//找到等于小于和大于区域的上下边界
int pointer=s;
int tempNumber=arr[e];
while(pointer<moreBound){
if(arr[pointer]<tempNumber&&moreBound>lessBound){
//和上边界的下一个交换
swap(arr,pointer,lessBound+1);
lessBound++;
pointer++;
}else if(arr[pointer]==tempNumber){
pointer++;
}else{
swap(arr,pointer,moreBound-1);
moreBound--;//pointer不能自增,因为此时还没有进行比较
}
}
return make_pair(lessBound,moreBound);
}
template <typename T>
void quickSort(vector<T> &arr,int s,int e){
if(s<e){
pair<int,int> bound=partition(arr,s,e);
int lessBound=bound.first;
int moreBound=bound.second;
quickSort(arr,s,lessBound);
quickSort(arr,moreBound,e);
//分别对大于区小于区域进行partition划分
}
}
Chapter 03
一、比较器的使用
① 比较器的实质就是重载比较运算符(在Java中就是比大小,在cpp中就是重载运算符)
② 比较器可以很好的应用在特殊标准的排序上
③ 比较器可以很好的应用在根据特殊标准排序的结构上
(83条消息) C++ 中自定义比较器的正确姿势_c++ 自定义比较器_frostime的博客-CSDN博客
(83条消息) C++中自定义比较函数和重载运算符总结_c++ 重载类的比较函数_bob62856的博客-CSDN博客
Step:
① 对一个自定义的 struct 重写它的 operator < 方法
② 定义一个 Comparator 函数
③ 定义一个 Comparator 结构体对象
//TODO 比较器的使用
// 1.函数比较器
bool cmp (const string &s1,const string &s2){
return s1.length()<s2.length();
//这里必须填的小于号,或者desc用大于号,返回布尔类型
}
// 2. https://zhuanlan.zhihu.com/p/146118861
struct Comparetor{
bool operator ()(const string &s1,const string &s2){
return s1.length()<s2.length();
}
};
// 3.自定义类型
// https://blog.csdn.net/qq_20817327/article/details/108302184
struct Str
{
string s;
bool operator < (const Str &str) const {
return s.length() < str.s.length();
}
};
vector<Str>s;
Str ss;
ss.s="a";
s.push_back(ss);
ss.s="aaaaaa";
s.push_back(ss);
ss.s="aa";
s.push_back(ss);
ss.s="aaaa";
s.push_back(ss);
ss.s="aaaaa";
s.push_back(ss);
ss.s="aaaa";
s.push_back(ss);
ss.s="aaa";
s.push_back(ss);
// stable_sort(s.begin(),s.end(),cmp);//比较函数重载
// stable_sort(s.begin(),s.end(),Comparetor());//结构体重载运算符
stable_sort(s.begin(),s.end());
// printVector(s);//!不能直接打印对象啊
for (int i = 0; i < s.size(); i++)
{
cout << s[i].s << " ";
}
cout << endl;
cout << endl;
二、桶排序思想下的排序
- 计数排序
- 基数排序
分析: 之前所有的排序都是基于比较的排序,不基于比较的排序是考虑数据的状况,使用的范围比较窄(词频数组)
① 桶排序思想下的排序都是不基于比较的排序
② 时间复杂度为O(N),额外空间负载度O(M)
③ 应用范围有限,需要样本的数据状况满足桶的划分
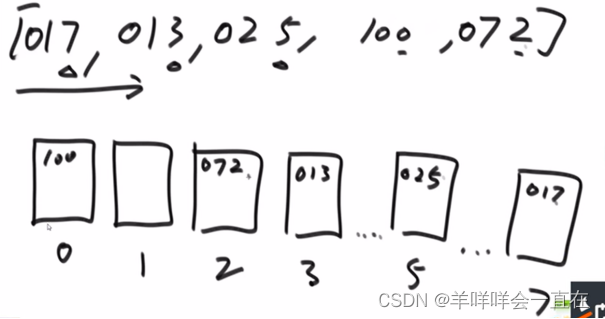
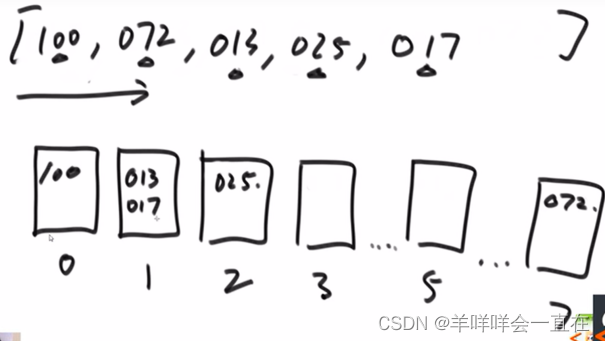
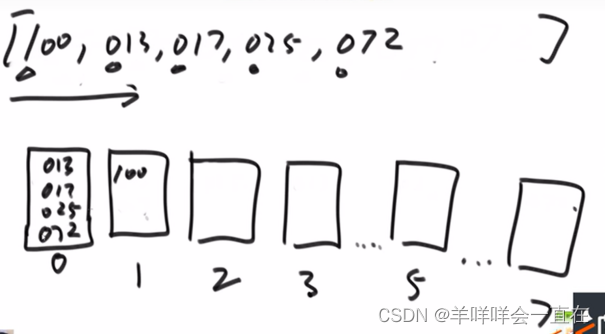
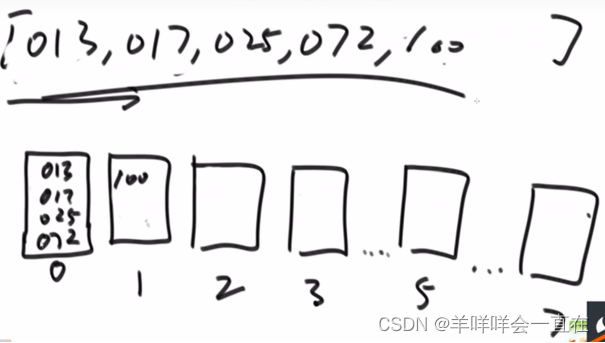
相当于优先级:百位>十位>个位
代码层次的改进:使用词频
统计个位词频(含辅助数组)–>词频数组变成前n项和–>


从右边的数字开始(<=2有四个,由于从右边开始,062倒出来一定在下表为3的位置),利用count数组实现分片,这里还使用了bucket辅助数组

三、排序算法的稳定性及其汇总
同样值的个体之间,如果不因为排序而改变相对次序,就是这个排序是有稳定性的;否则就没有。 稳定性在基础数据类型中并不是很需要被看重,但是在非基础数据类型中较为重要:学生的总成绩和各项成绩。
-
不具备稳定性的排序:
选择排序(Swap的过程不稳定)、快速排序(partition过程不稳定)、堆排序
-
具备稳定性的排序:
冒泡排序、插入排序、归并排序、一切桶排序思想下的排序 -
目前没有找到时间复杂度O(N*logN),额外空间复杂度O(1),又稳定的排序。
-
基于比较的排序,时间复杂度没有O(NlgN以下的);时间复杂度O(NlgN),空间复杂度在O(lgN)以下且稳定的

图 9 对比,一般能用快排就选快排,快排的常数复杂度低
四、常见的坑
① 归并排序的额外空间复杂度可以变成O(1),但是非常难,不需要掌握,有兴趣可以搜“归并排序 内部缓存法”
② “原地归并排序”的帖子都是垃圾,会让归并排序的时间复杂度变成O(N^2)
③ 快速排序可以做到稳定性问题,但是非常难,不需要掌握, 可以搜“01 stable sort”–》空间复杂度会变成O(N)
④ 所有的改进都不重要,因为目前没有找到时间复杂度O(N*logN),额外空间复杂度O(1),又稳定的排序。
⑤ 有一道题目,是奇数放在数组左边,偶数放在数组右边,还要求原始的相对次序不变,碰到这个问题,可以怼面试官,空间复杂度O(1),时间复杂度O(N)(快排(0,1标准问题)问题,快排在保证原来属性的情况下,快排没有办法做到稳定,可以表示自己不会,并谦虚请教)。
- 在c++中:
sort的实现是基于快速排序的,快速排序在比较算法中算是速度最快的,平均的时间复杂度为O(nlogn),虽然它的最差时间复杂度可能达到O(n2)。
stable_sort的实现是基于归并排序的,它的时间复杂度为O(nlogn),一般情况下,它比快速排序稍慢。但是它是一种稳定排序,所谓稳定排序,就是说相同大小的元素,在排序前后的相对位置不会发生改变。即相同大小的元素中,原来在前的元素,排序之后还是在前面
五、工程上对排序的改进
① 充分利用O(N*logN)和O(N^2)排序各自的优势
② 稳定性的考虑
综合排序:在小样本的情况下,插入排序,插入的成本是比较低的,而在大样本情况下,快排的调度能力表现优秀,可以结合样本量(<=60)决定排序的方案。















 384
384











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









