







目录
kaggle网站(Bike Sharing Demand | Kaggle)提供了某城市的共享单车2011年到2012年的数据集。该数据集包括了租车日期,租车季节,租车天气,租车气温,租车空气湿度等数据。本次将使用r对这一数据集进行探索性分析,我觉得这个目标就是——季节、天气、温度等这些因素是如何影响共享单车使用率的?。
1.加载包和读取数据
首先加载包:
library(readr) # 文件读写
library(ggplot2) # 数据可视化
library(ggthemes) # 数据可视化
library(scales) # 把图形弄的更漂亮的,并提供用于自动地确定用于轴和图例符和标签的方法
library(plyr) #可以进行类似于数据透视表的操作,将数据分割成更小的数据,
#对分割后的数据进行些操作,最后把操作的结果汇总。比如提取首字母,提取姓氏.等等
library(stringr) # 字符串的操作
library(InformationValue) # 算IV跟WOE用的,即高价值数据和信息权重
library(MLmetrics) # 衡量回归,分类和排名表现的评估指标的集合,交叉验证的时候用
library(rpart) # 回归树的方法,用来预测缺失的数据
library(randomForest) # 随机森林
library(dplyr) # 数据操作
library(e1071) # 在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,
#通常用来进行模式识别、分类以及回归分析,文中predict就是这个包的
library(Amelia) # 多重插补(MI)是一种基于重复模拟的处理缺失值的方法。在面对复杂的
#缺失值问题时,MI是最常选用的方法,它将从一个包含缺失值的数据集中生成一组完整的数据集
library(party) # 递归分区的计算工具箱。包的核心是ctree(),这是一个条件推理树的实现,
#它将树结构的回归模型嵌入到一个明确的条件推理过程理论中。
#这种非参数类的回归树适用于各种回归问题,包括名义,序数,数字,检查以及多变量响应变量和协变量的任意测量量表。
#基于条件推理树,cforest()提供了布里曼随机森林的实现。
library(gbm) # 广义增强回归模型.Adaboost是提升树(boosting tree),
#所谓“提升树”就是把“弱学习算法”提升(boost)为“强学习算法”.
library(class) # 各种分类功能 包括KNN,学习向量量化和自组织图。
#决策树要用到的包
library(rattle) #这些库将用于为决策树模型提供良好的可视化绘图
library(rpart.plot)#绘制“rpart”模型:“plot.rpart”的增强版本
library(RColorBrewer)#配色方案然后读取数据:
#setwd是设定workspace路径的意思
setwd("E:/ShareBike")
train<-read.csv("train.csv")
test<-read.csv("test.csv")2.数据预处理
2.1观察数据并填充
观测数据,发现测试数据比训练数据少了后面3个观测分别是casual,registered,count。
怎么办呢?那就在测试数据里加上这3列数值:
#在测试数据里加上缺失的三个值
test$registered<-0
test$casual<-0
test$count<-0
data<-rbind(train,test)用str()看看这里面都包含什么数据
str(data)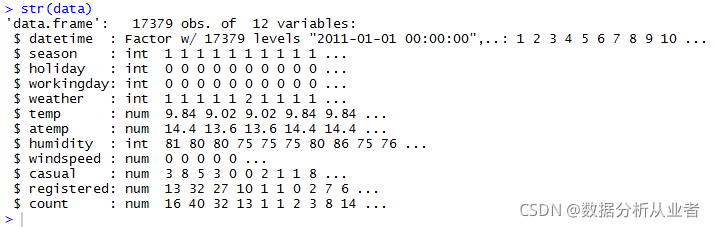
可以看出共有观测17379条,12个变量,数据字典如下:
日期时间(datetime):日期和时间以“mm-dd- yyyy hh:mm:ss”格式
季节(season):1为春,2为夏,3为秋,4为冬
假期(holiday):1/0
工作日(workingday):1/0
天气(weather):四类天气
- 清除,几朵云,部分多云,部分多云
- 迷雾+多云,雾+破碎的云雾,雾+少云,雾
- 轻雪和雨+雷暴+分散的云彩,小雨+分散的云彩
- 大雨+冰托盘+雷雨+雾,雪+雾
温度(temp):每小时摄氏温度
温度(atemp):像是一种加过权重之后的温度,反正跟temp是强正相关
湿度(humidity):湿度
风速(windspeed):风速
casual :休闲用户
registered:注册用户
count:共计数
2.2找出缺失值
table(is.na(data))
意思就是说没有缺失值!
2.3绘制频率表
了解数值变量的分布,然后生成数值变量的频率表。绘制每个数值变量的直方图,并分析。
#绘制每个观测的直方图并分析
#四行两列
par(mfrow=c(4,2))
#宽度和长度
par(mar = rep(2, 4))
hist(data$season)
hist(data$weather)
hist(data$humidity)
hist(data$holiday)
hist(data$workingday)
hist(data$temp)
hist(data$atemp)
hist(data$windspeed)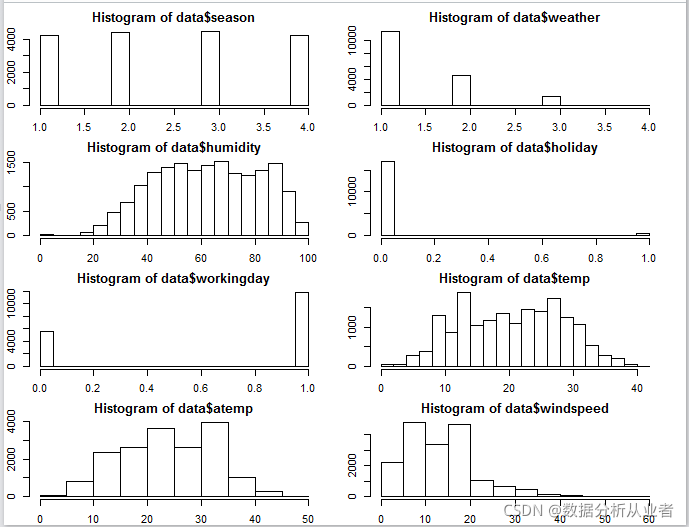
通过观察上图可以看出一些影响:
- 四季的影响不大
- 天气的影响比较大,从好到不好,自行车的使用量越来越低
- 当假期为0,工作日为1时自行车的使用量就比较大
- 温度太高或者太低了都会影响使用量
- 风速从5到20这个时候自行车使用量比较大,可以推测在这个风速里骑车是比价愉悦的
2.4将离散型转换为因子型的(季节,天气,假期,工作日),否则无法画图
data$season=as.factor(data$season)
data$weather=as.factor(data$weather)
data$holiday=as.factor(data$holiday)
data$workingday=as.factor(data$workingday)3.生成假设
现在你对数据已经有了一个大致的了解,下面让我们来根据一些基本的经验来对自行车的使用量进行假设:
- 24小时趋势:上下班高峰期使用量就很高。晚上10点到凌晨4点需求低
- 一周趋势:平日用车比节假日高
- 有雨有雪:与晴天相比,下雨(雪)天的自行车需求将会下降。同样,较高的湿度会降低需求,反之亦然。
- 温度影响:温度适宜的情况下使用量必加大
- 注册用户与时间:由于注册用户数量随着时间的推移得增多,总需求应该趋向于升高
4.假设检验
下面来逐一分析上面的假设检验
4.1每日趋势:
data$hour=substr(data$datetime,12,13)
data$hour=as.factor(data$hour)画图,判断假设是否正确
#把训练的前20天和测试的后10天左右提出来
train=data[as.integer(substr(data$datetime,9,10))<20,]
test=data[as.integer(substr(data$datetime,9,10))>19,]
#一行一列,否则还是4行2列
par(mfrow=c(1,1))
#画图
boxplot(train$count~train$hour,xlab="hour", ylab="count of users")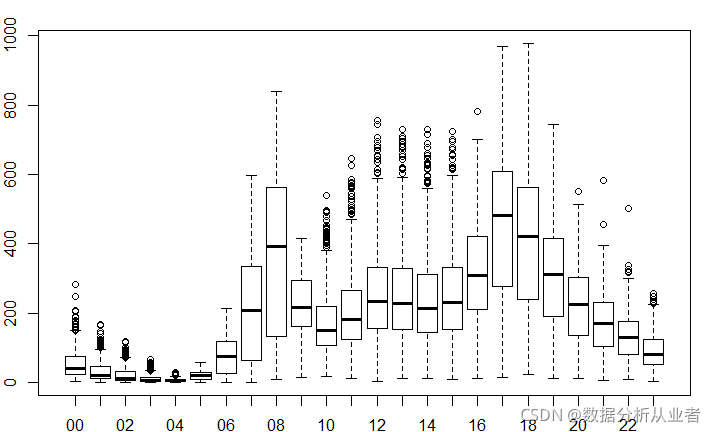
可以看出和我们的假设差不多:
上下班时间是用车高峰,而低谷期是在晚上10点到次日凌晨6点。其他时间为平均用车量。
4.2注册用户和临时用户
(1)临时用户
boxplot(train$casual~train$hour,xlab="hour", ylab="count of users")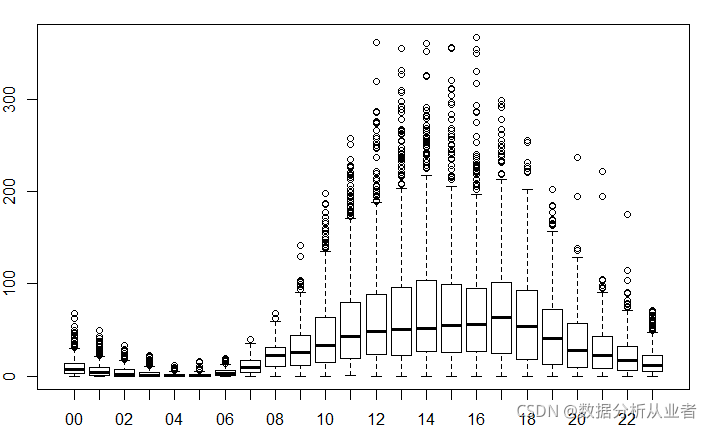
可以看出:临时用户倾向于在白天的时候随便用用,用户粘性不高,基本上都是平均值。
(2)注册用户:
boxplot(train$registered~train$hour,xlab="hour", ylab="count of users")
注册用户更倾向于上下班高峰期用。
仔细观察这2个图,你可能会发现,这2图有一些异常值,应该不是由错误导致的。我猜测他们可能是同一群人骑自行车但是未注册的结果,为了处理这些离群值,将使用对数变换:
boxplot(log(train$count)~train$hour,xlab="hour",ylab="log(count)")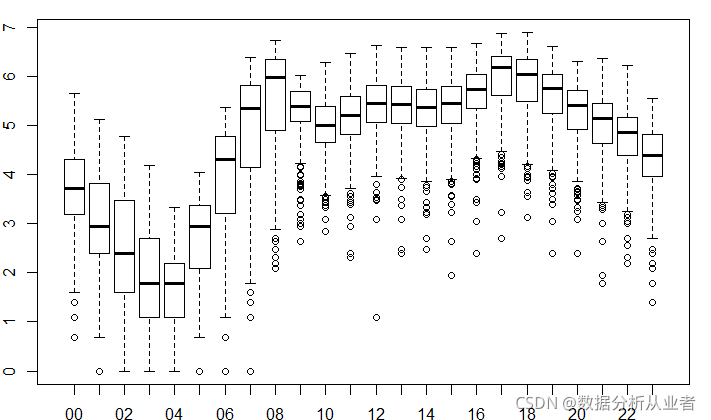
4.3一周趋势
#把date$datetime的年月日拆出来
date<-substr(data$datetime,1,10)
#拆出来之后转换成星期
days<-weekdays(as.Date(date))
data$day<-days注册用户画图:
#画注册用户的图
boxplot(data$registered~data$day,xlab="day", ylab="users")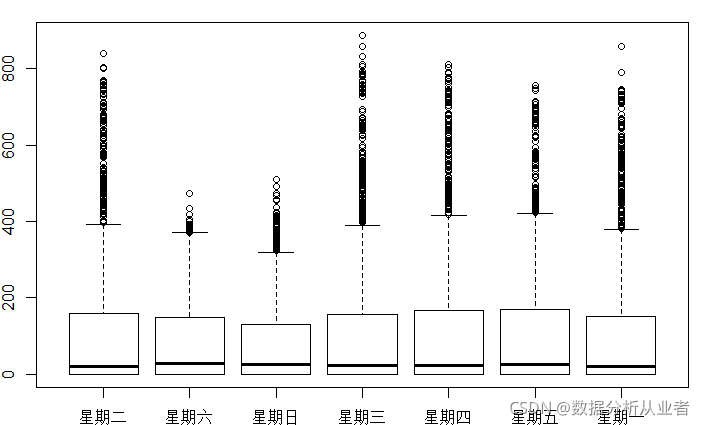
临时用户画图
#画临时用户的图
boxplot(data$casual~data$day,xlab="day", ylab="users")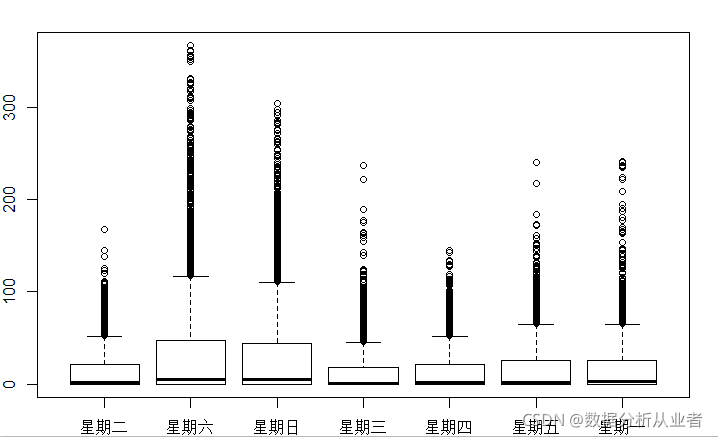
可以看出星期六星期天的临时用户是增加的。
4.4雨(雪)的影响
在变量中虽然没有专门的雨量数据,但是在天气(weather)这里面有响应的因素,3里有小雨(雪),4里有大雨(雪)。
(1)画图,天气和注册用户的关系
boxplot(train$registered~train$weather,xlab="weather", ylab="registered users")
(2)画图,天气和休闲用户的关系
boxplot(train$casual~train$weather,xlab="weather", ylab="casual users")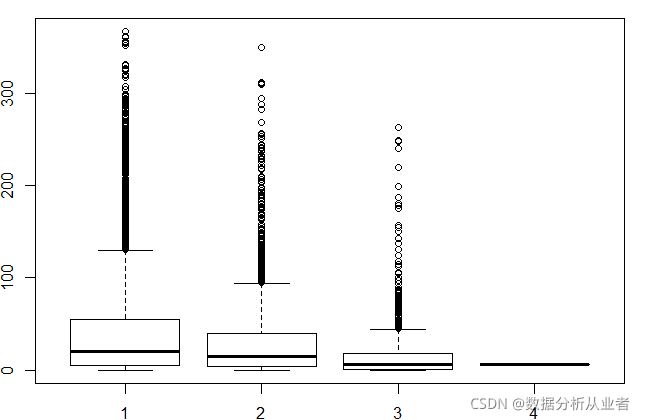
从图中可以看出非常符合我们的预期(常识嘛,呵呵!)
4.5温度,风速和湿度影响
由于温度,风速和温度这些数据不是离散型的,是连续的,所以我们用相关来验证假设。
温度,风速和湿度的相关关系:
sub<-data.frame(train$registered,train$casual,train$count,train$temp,train$humidity,train$atemp,train$windspeed)
subT<-cor(sub)如下表:
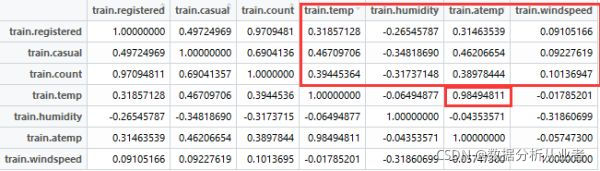
从表中可以看出,温度和注册,休闲,总计这三个变量差不多都是正相关关系,而湿度和风速跟这三兄弟的关系就不是很大了。温度和atemp是高度相关。
4.6 时间影响
看看时间对于用户数的影响。
随着时间的推移,用户数的变化:
data$year=substr(data$datetime,1,4)
data$year=as.factor(data$year)
train=data[as.integer(substr(data$datetime,9,10))<20,]
test=data[as.integer(substr(data$datetime,9,10))>19,]
boxplot(train$count~train$year,xlab="年", ylab="用户总量")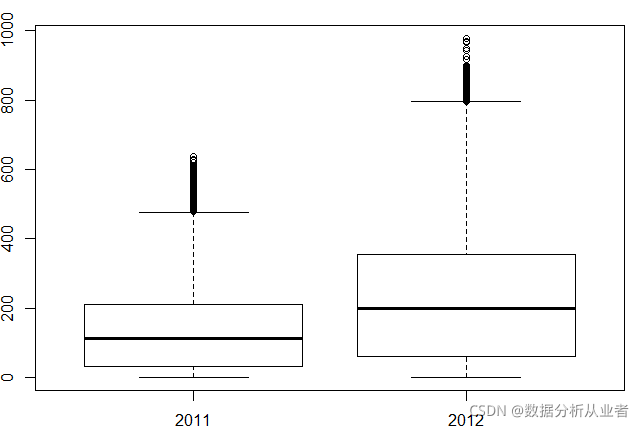
结论是用户数增加。
5.决策树
让我们用决策树来增加模型的预测能力。
画图:关于小时的决策树的图
#训练数据转换类型
train$hour=as.integer(train$hour)
#测试数据转换类型
test$hour=as.integer(test$hour)
#用小时生成决策树
d=rpart(registered~hour,data=train)
#画图
fancyRpartPlot(d)
查看节点,手动添加仓位(注册用户)
data=rbind(train,test)
data$dp_reg=0
data$dp_reg[data$hour<8]=1
data$dp_reg[data$hour>=22]=2
data$dp_reg[data$hour>9 & data$hour<18]=3
data$dp_reg[data$hour==8]=4
data$dp_reg[data$hour==9]=5
data$dp_reg[data$hour==20 | data$hour==21]=6
data$dp_reg[data$hour==19 | data$hour==18]=7添加仓位(休闲用户)
b=rpart(casual~hour,data=train)
fancyRpartPlot(b)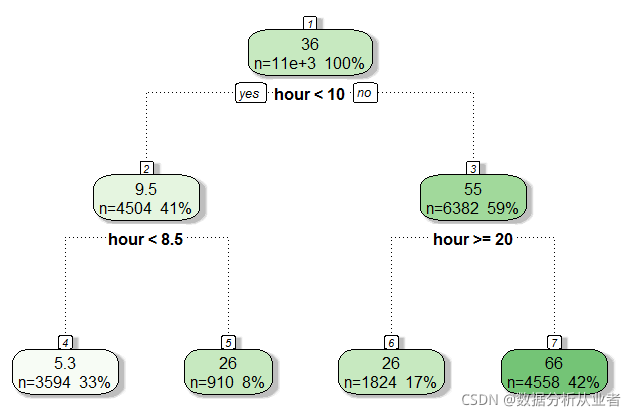
#手动添加
data$dp_cas=0
data$dp_cas[data$hour==9]=1
data$dp_cas[data$hour<=8]=2
data$dp_cas[data$hour>=10&data$hour<=19]=3
data$dp_cas[data$hour>=20]=4温度(注册用户)
t=rpart(registered~temp,data=train)
fancyRpartPlot(t)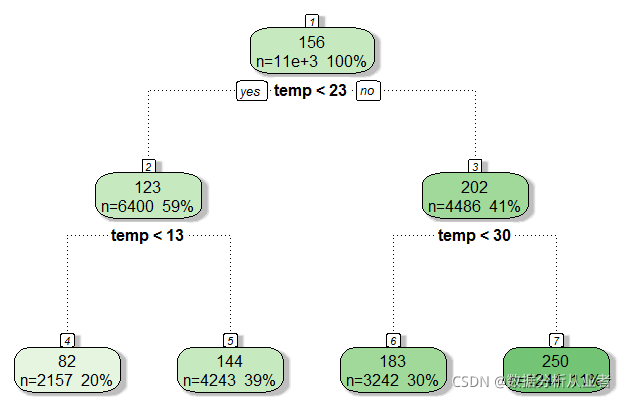
#添加注册
data$temp_reg=0
data$temp_reg[data$temp<13]=1
data$temp_reg[data$temp>=13&data$temp<23]=2
data$temp_reg[data$temp>=23&data$temp<30]=3
data$temp_reg[data$temp>=30]=4温度(休闲用户)
t1=rpart(casual~temp,data=train)
fancyRpartPlot(t1)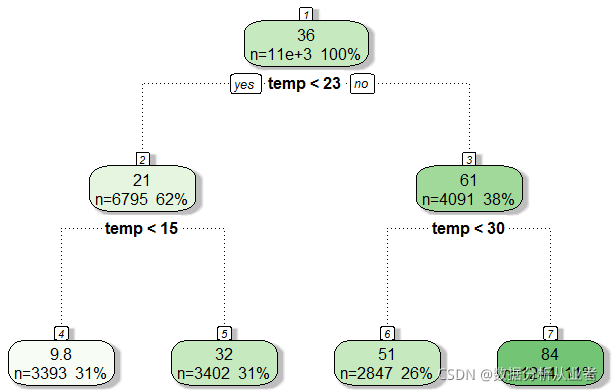
#添加休闲
data$temp_cas=0
data$temp_cas[data$temp<15]=1
data$temp_cas[data$temp>=15&data$temp<23]=2
data$temp_cas[data$temp>=23&data$temp<30]=3
data$temp_cas[data$temp>=30]=4添加年份:在这里先把月份提取出来,然后按照每个季度一个仓位,建8个仓位
#提取月份
data$month=substr(data$datetime,6,7)
data$month=as.factor(data$month)
train=data[as.integer(substr(data$datetime,9,10))<20,]
test=data[as.integer(substr(data$datetime,9,10))>19,]
#转换类型
data$month=as.integer(data$month)#手动添加
data$year_part[data$year=='2011']=1
data$year_part[data$year=='2011' & data$month>3]=2
data$year_part[data$year=='2011' & data$month>6]=3
data$year_part[data$year=='2011' & data$month>9]=4
data$year_part[data$year=='2012']=5
data$year_part[data$year=='2012' & data$month>3]=6
data$year_part[data$year=='2012' & data$month>6]=7
data$year_part[data$year=='2012' & data$month>9]=8
table(data$year_part)
日期:创建一个变量,有“平日”、“周末”和“假日”
data$day_type=""
data$day_type[data$holiday==0 & data$workingday==0]="weekend"
data$day_type[data$holiday==1]="holiday"
data$day_type[data$holiday==0 & data$workingday==1]="working day"周末:为周末创建一个独立的变量
data$weekend=0
data$weekend[data$day=="Sunday" | data$day=="Saturday" ]=16.开始建模
首先把character的数据类型都转换成factor,否则随机森林不支持。
data$day=as.factor(data$day)
data$day_type=as.factor(data$day_type)我们之前分析过由于注册,休闲,计数。这三个向量有很多自然离群值,所以这里就把他们都转换成对数。
#取对数
data$logreg<-log(data$registered+1)
data$logcas<-log(data$casual+1)加1是为了处理注册和休闲这俩观测的0值。
#将data里的所有观测和类型统统赋值给train,test
train=data[as.integer(substr(data$datetime,9,10))<20,]
test=data[as.integer(substr(data$datetime,9,10))>19,]预测
#预测注册用户的对数
set.seed(415)
fit1 <- randomForest(logreg ~ hour +workingday+day+holiday+ day_type +temp_reg+humidity+atemp+windspeed+season+weather+dp_reg+weekend+year+year_part, data=train,importance=TRUE, ntree=250)
pred1=predict(fit1,test)
test$logreg=pred1我的电脑运行速度较慢,这里运算了40分钟......
#预测休闲用户的对数
set.seed(415)
fit2 <- randomForest(logcas ~hour + day_type+day+humidity+atemp+temp_cas+windspeed+season+weather+holiday+workingday+dp_cas+weekend+year+year_part, data=train,importance=TRUE, ntree=250)
pred2=predict(fit2,test)
test$logcas=pred2半个小时又过去了.......
写入文件并上传到kaggle网站:
#重新转换预测变量,然后将count的输出写入文件
test$registered=exp(test$logreg)-1
test$casual=exp(test$logcas)-1
test$count=test$casual+test$registered
s<-data.frame(datetime=test$datetime,count=test$count)
write.csv(s,file="pre3.csv",row.names=FALSE)由于没有排名系统所以只有得分......
得了0.411111分















 2457
2457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









