






 本文详细介绍了在OpenCompass中进行模型评估的过程,包括配置模型和数据集、并行推理与评估、以及可视化结果。还提到如何在GPU环境下进行数据准备和启动评测,以及使用--debug模式进行问题排查。
本文详细介绍了在OpenCompass中进行模型评估的过程,包括配置模型和数据集、并行推理与评估、以及可视化结果。还提到如何在GPU环境下进行数据准备和启动评测,以及使用--debug模式进行问题排查。
基础作业:
概览
在 OpenCompass 中评估一个模型通常包括以下几个阶段:配置 -> 推理 -> 评估 -> 可视化。
- 配置:这是整个工作流的起点。您需要配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
- 推理与评估:在这个阶段,OpenCompass 将会开始对模型和数据集进行并行推理和评估。推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率,但请注意,如果计算资源有限,这种策略可能会使评测变得更慢。如果需要了解该问题及解决方案,可以参考 FAQ: 效率。
- 可视化:评估完成后,OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。你也可以激活飞书状态上报功能,此后可以在飞书客户端中及时获得评测状态报告。 接下来,我们将展示 OpenCompass 的基础用法,展示书生浦语在 C-Eval 基准任务上的评估。它们的配置文件可以在 configs/eval_demo.py 中找到。
环境配置
面向GPU的环境安装


数据准备
解压评测数据集到 data/ 处
将会在opencompass下看到data文件夹
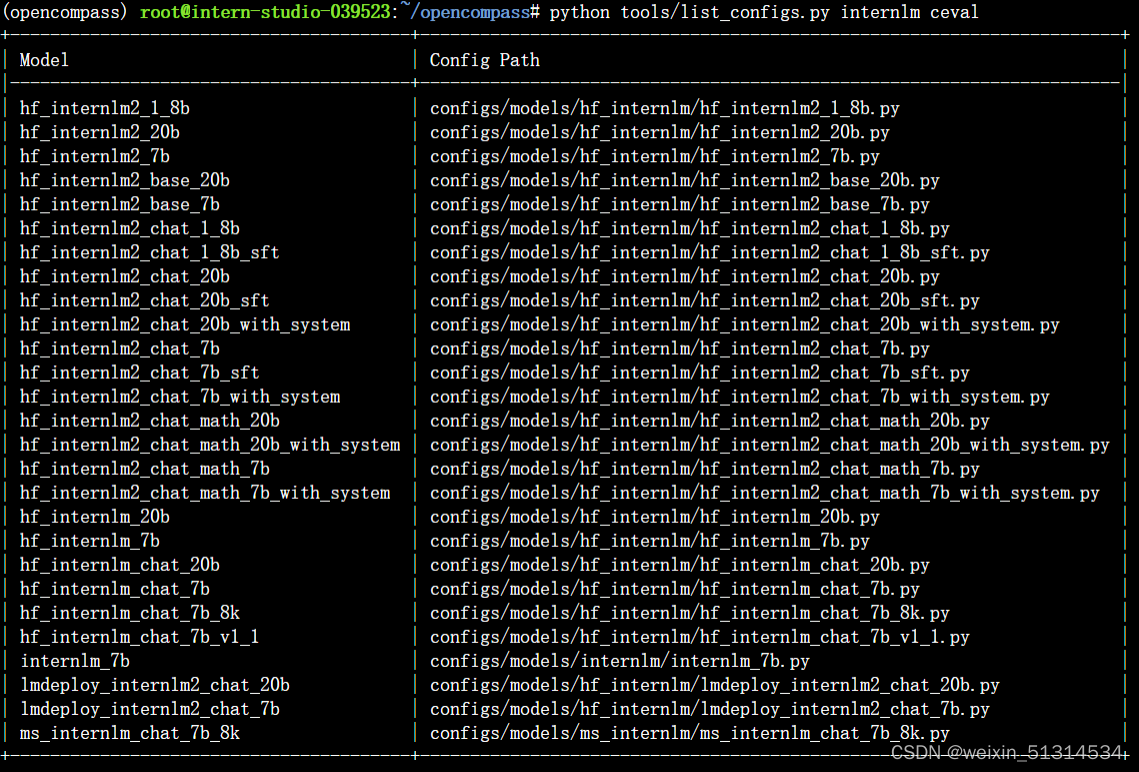
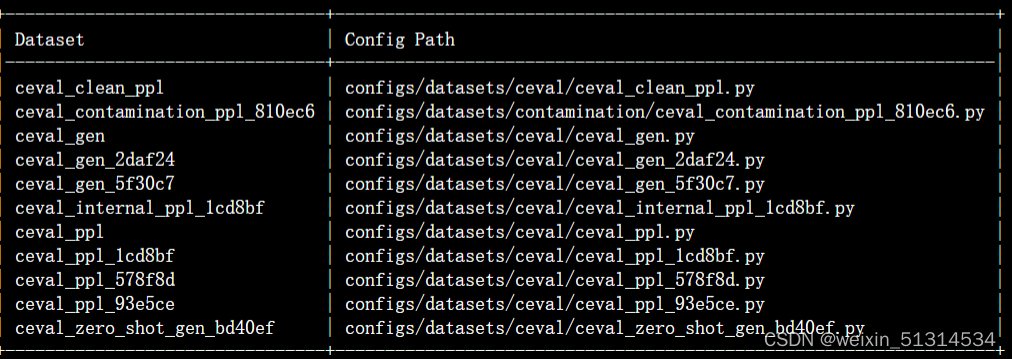
查看支持的数据集和模型
列出所有跟 internlm 及 ceval 相关的配置
启动评测 (10% A100 8GB 资源)
确保按照上述步骤正确安装 OpenCompass 并准备好数据集后,可以通过以下命令评测 InternLM2-Chat-1.8B 模型在 C-Eval 数据集上的性能。由于 OpenCompass 默认并行启动评估过程,我们可以在第一次运行时以 --debug 模式启动评估,并检查是否存在问题。在 --debug 模式下,任务将按顺序执行,并实时打印输出。
如果一切正常,应该看到屏幕上显示 “Starting inference process”:
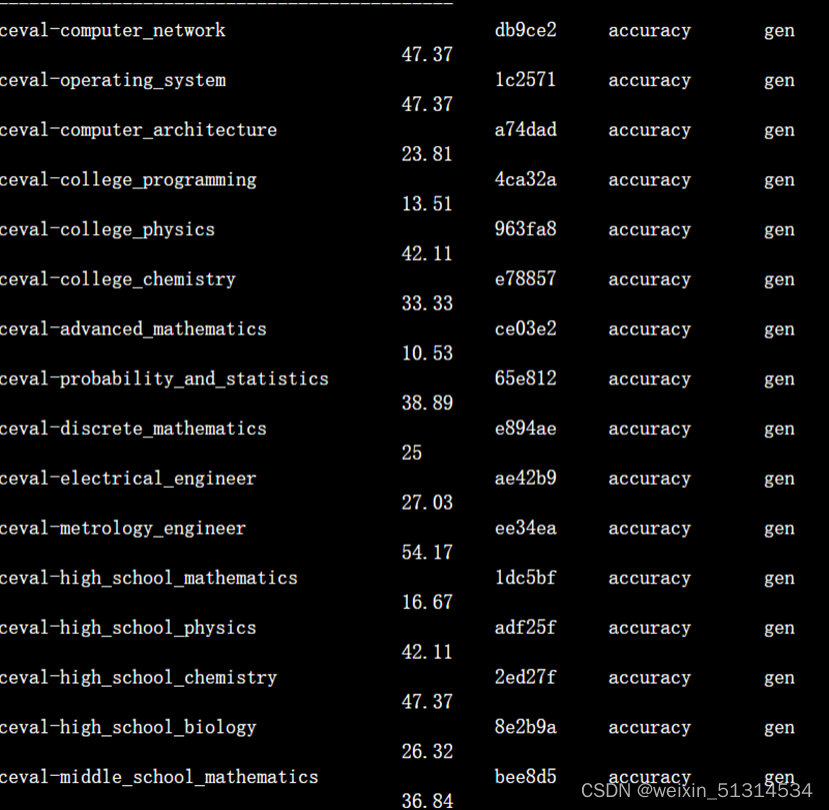
评测完成后,将会看到:
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









