







1.由前面可知,关于时间的操作可以使用datetime时间戳
%matplotlib notebook
import datetime
dt = datetime.datetime(year=2017,month=11,day=24,hour=10,minute=30)
dt
print (dt)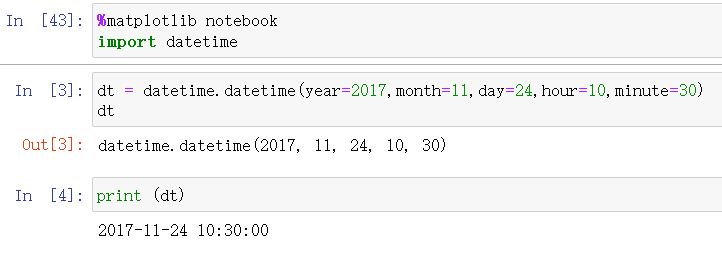
2.导入pandas,使用pandas中的Timestamp生成时间戳
import pandas as pd
ts = pd.Timestamp('2017-11-24')
ts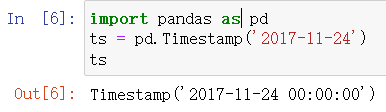
pd.to_datetime('2017-11-24')
pd.to_datetime('24/11/2017')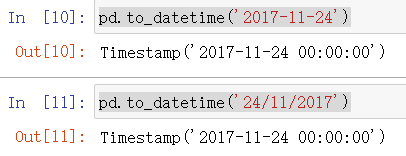
3.显示月份和日期
ts.month
ts.day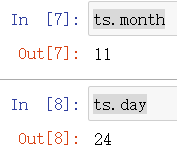
4.对日期进行操作
ts + pd.Timedelta('5 days')
5.定义时间series时间,生成时间戳组,显示小时数和周几
s = pd.Series(['2017-11-24 00:00:00','2017-11-25 00:00:00','2017-11-26 00:00:00'])
s
ts = pd.to_datetime(s)
ts
ts.dt.hour
ts.dt.weekday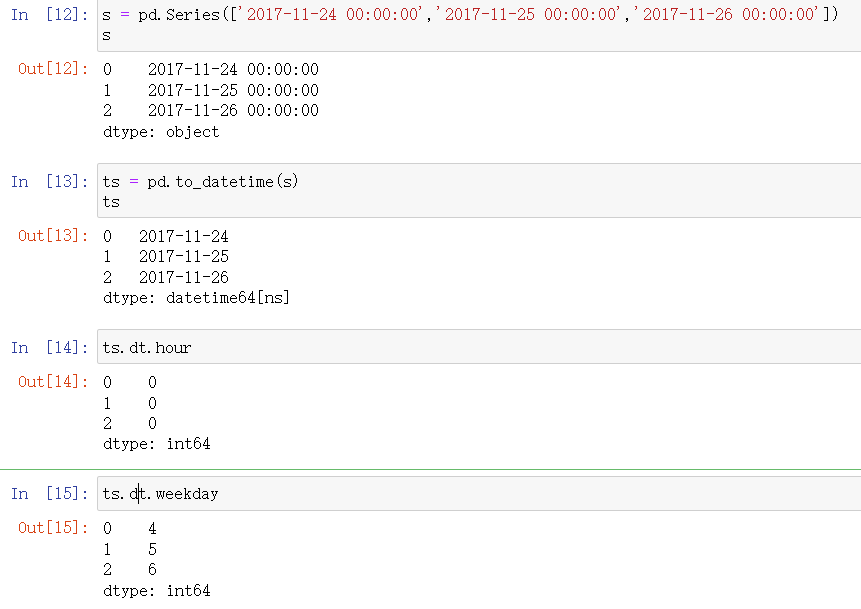
6.按照时间间隔生成时间series
pd.Series(pd.date_range(start='2017-11-24',periods = 10,freq = '12H'))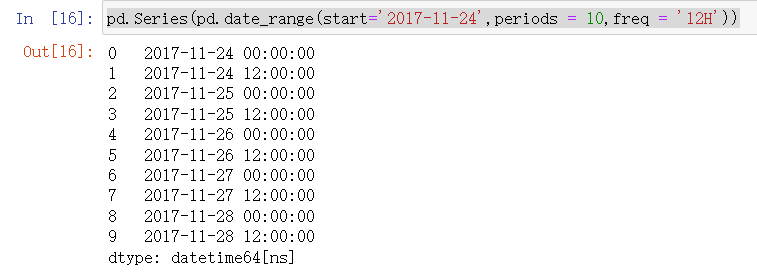
7.读取csv
data = pd.read_csv('./data/flowdata.csv')
data.head()
8.将表格中的时间字符串常量转换为时间戳,并且用时间戳作为索引显示出来
data['Time'] = pd.to_datetime(data['Time'])
data = data.set_index('Time')
data
data.index
data = pd.read_csv('./data/flowdata.csv',index_col = 0,parse_dates = True)
//index_col代表指定的列数
//parse_datas代表是否要解析数据
data.head()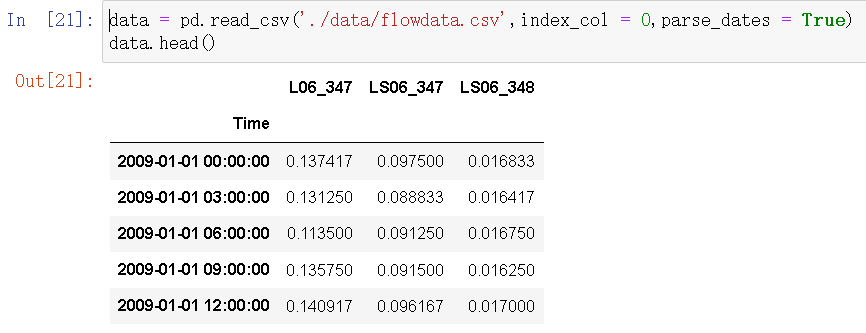
9.切片操作
data[pd.Timestamp('2012-01-01 09:00'):pd.Timestamp('2012-01-01 19:00')]
data[('2012-01-01 09:00'):('2012-01-01 19:00')]
data.tail(10)//取出最后十个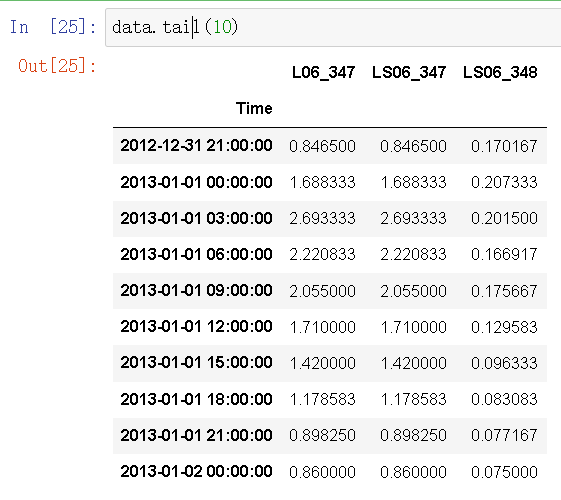
data['2013']
data['2012-01':'2012-03']
data[data.index.month == 1]
data[(data.index.hour > 8) & (data.index.hour <12)]
data.between_time('08:00','12:00')
10.计算某一段时间的统计特征值
D代表一天
3D代表三天
M代表一个月
data.resample('D').mean().head()
data.resample('D',how='mean').head()
data.resample('3D').mean().head()
data.resample('M').mean().head()
显示红色表示这个功能将被遗弃了
11.绘图
data.resample('M').mean().plot()
















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











