







1.导入pandas,定义DataFrame
import pandas as pd
data = pd.DataFrame({'group':['a','a','a','b','b','b','c','c','c'],
'data':[4,3,2,1,12,3,4,5,7]})
data
2.一列做升序,一列做降序,将改变后的值作用在DataFrame中
data.sort_values(by=['group','data'],ascending = [False,True],inplace=True)
data
3.数据排序
data = pd.DataFrame({'k1':['one']*3+['two']*4,
'k2':[3,2,1,3,3,4,4]})
data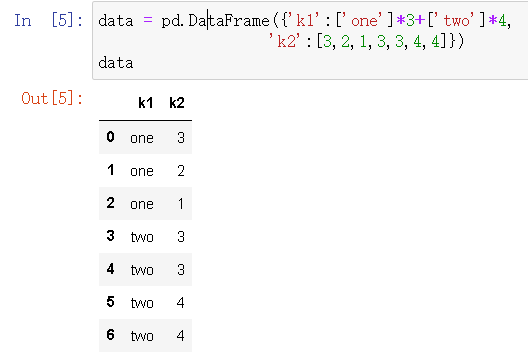
data.sort_values(by='k2')
4.去重,去掉特征值相同的项
data.drop_duplicates()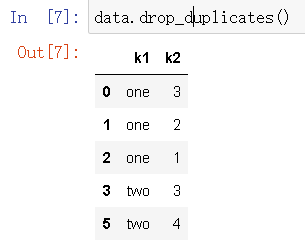
5.去重,去掉指定的特征值相同的项
data.drop_duplicates(subset='k1')
6.映射
data = pd.DataFrame({'food':['A1','A2','B1','B2','B3','C1','C2'],'data':[1,2,3,4,5,6,7]})
data
apply()用函数作为映射
def food_map(series):
if series['food'] == 'A1':
return 'A'
elif series['food'] == 'A2':
return 'A'
elif series['food'] == 'B1':
return 'B'
elif series['food'] == 'B2':
return 'B'
elif series['food'] == 'B3':
return 'B'
elif series['food'] == 'C1':
return 'C'
elif series['food'] == 'C2':
return 'C'
data['food_map'] = data.apply(food_map,axis = 'columns')
data
map()用series进行映射
food2Upper = {
'A1':'A',
'A2':'A',
'B1':'B',
'B2':'B',
'B3':'B',
'C1':'C',
'C2':'C'
}
data['upper'] = data['food'].map(food2Upper)
data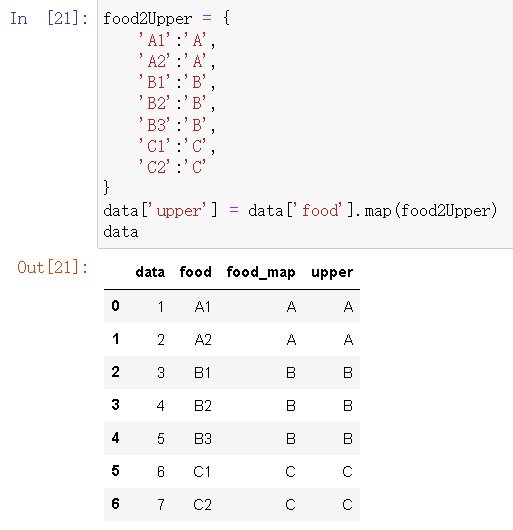
7.在已有的DataFrame基础上指定一个新的特征值并且生成一个DataFrame
import numpy as np
df = pd.DataFrame({'data1':np.random.randn(5),
'data2':np.random.randn(5)})
df2 = df.assign(ration = df['data1']/df['data2'])
df2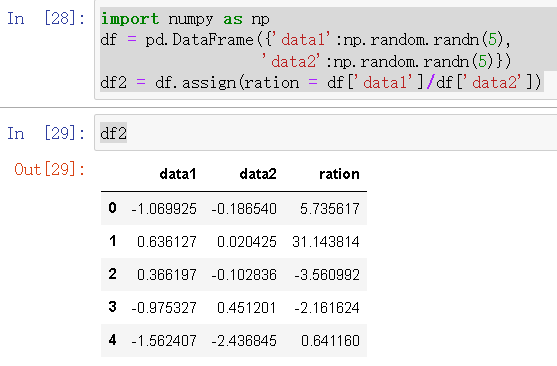
8.删除某一列特征值
df2.drop('ration',axis='columns',inplace=True)
df2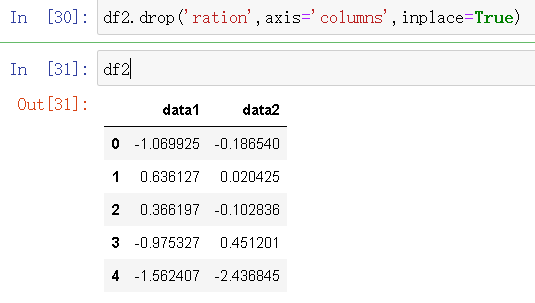
9.替换
data = pd.Series([1,2,3,4,5,6,7,8,9])
data
data.replace(9,np.nan,inplace=True)
data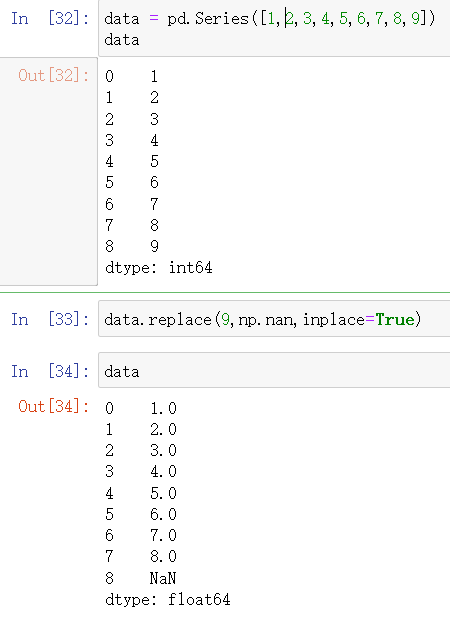
10.区间分类
ages = [15,18,20,21,22,34,41,52,63,79]
bins = [10,40,80]
bins_res = pd.cut(ages,bins)
bins_res
bins_res.labels
pd.value_counts(bins_res)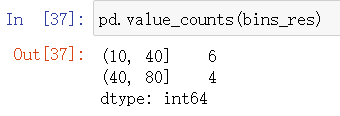
pd.cut(ages,[10,30,50,80])
group_names = ['Yonth','Mille','Old']
#pd.cut(ages,[10,20,50,80],labels=group_names)
pd.value_counts(pd.cut(ages,[10,20,50,80],labels=group_names))
11.nan和null(缺失值)操作相关
df = pd.DataFrame([range(3),[0, np.nan,0],[0,0,np.nan],range(3)])
df
判断是否是缺失值
df.isnull()
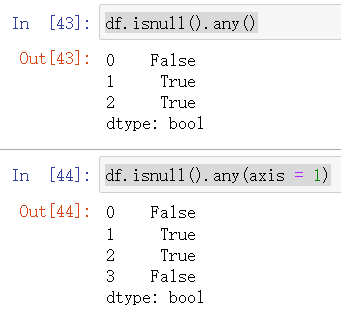
判断某一行和某一列是否有缺失值
df.isnull().any()
df.isnull().any(axis = 1)
填充缺失值
df.fillna(5)
获取缺失值的索引位置
df[df.isnull().any(axis = 1)]
















 71
71

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











