







文章目录
一、前言
在当项目规模达到一定的程度时,比如达到十万行的代码量,那么项目肯定存在有些类特别大,方法特别多、特别长。
以上因素会导致以下后果:
- 一个类没有做到单一职责,后期对这个类改动会导致其他功能出现Bug。
- 代码阅读性较差,维护困难。
- 编写单元测试麻烦,很难对类中的各方法覆盖完全。
在开发过程中,由于不同公司规范可能不一致,开发中也很少人能够去完全遵循规范,而且不同的开发的代码编写习惯不一样,久而久之,代码容易堆积和膨胀,复杂度增加,最终会导致代码维护的成本急剧增加。因此,互联网中大公司会经常下线无用代码,会做一些代码的治理,去严格把关代码的质量。但在这个治理的过程中,没有一个明确的标准去衡量代码的复杂程度,而且人工去检测代码的复杂程度是很繁琐的。因此,我们急需一个标准去检测代码结构复杂的程度,而圈复杂度和认知复杂度这两个概念能够帮我们很好的去衡量代码的可维护性和可理解性。
二、圈复杂度
2.1 圈复杂度概念
圈复杂度(Cyclomatic Complexity, CC) 由Thomas J. McCabe, Sr.在1976年 提出,其是一种用于评估代码复杂性的软件度量方法,目标是为了指导程序员写出更具可测性和可维护性的代码。圈复杂度也称为条件复杂度或循环复杂度,其常被用于检测代码的复杂程度。一般情况下,代码的分支或循环越多,圈复杂度越高。在严格的情况下,代码圈复杂度建议<=10,一般不建议超过20,当然这个数具体看公司的要求,每个公司有每个的标准,据说腾讯是要求阈值为15,携程是要求阈值为20。
圈复杂度对于代码的可测性和维护成本来说非常重要,其和代码复杂程度、维护成本的关系如下表:
| 圈复杂度 | 代码状况 | 可测性 | 维护成本 |
|---|---|---|---|
| 1~10 | 清晰 | 高 | 低 |
| 10~20 | 复杂 | 中 | 中 |
| 20~30 | 非常复杂 | 低 | 低 |
| >30 | 不可读 | 不可测 | 非常高 |
2.2 圈复杂度计算
2.2.1 手动计算
① 点边计算法
手动计算有几种方法,这里我们先介绍点边计算法,点边计算法的公式如下:
V(G) = E - N + 2
公式中的各个符合概念如下:
V(G):圈复杂度,是一种通过计算图中的节点、边和连接组件的数量来度量程序复杂性的指标
N(节点个数):表示在控制流图中节点的数量,包括起点和终点注。所有终点只计算一次,即便有多个return或者throw;节点对应代码中的分支语句)
E(边的数量):表示在控制流图中边的数量(对应代码中顺序结构的部分)
CFG:控制流图,是一个过程或程序的抽象表现,常以数据结构链的形式表示
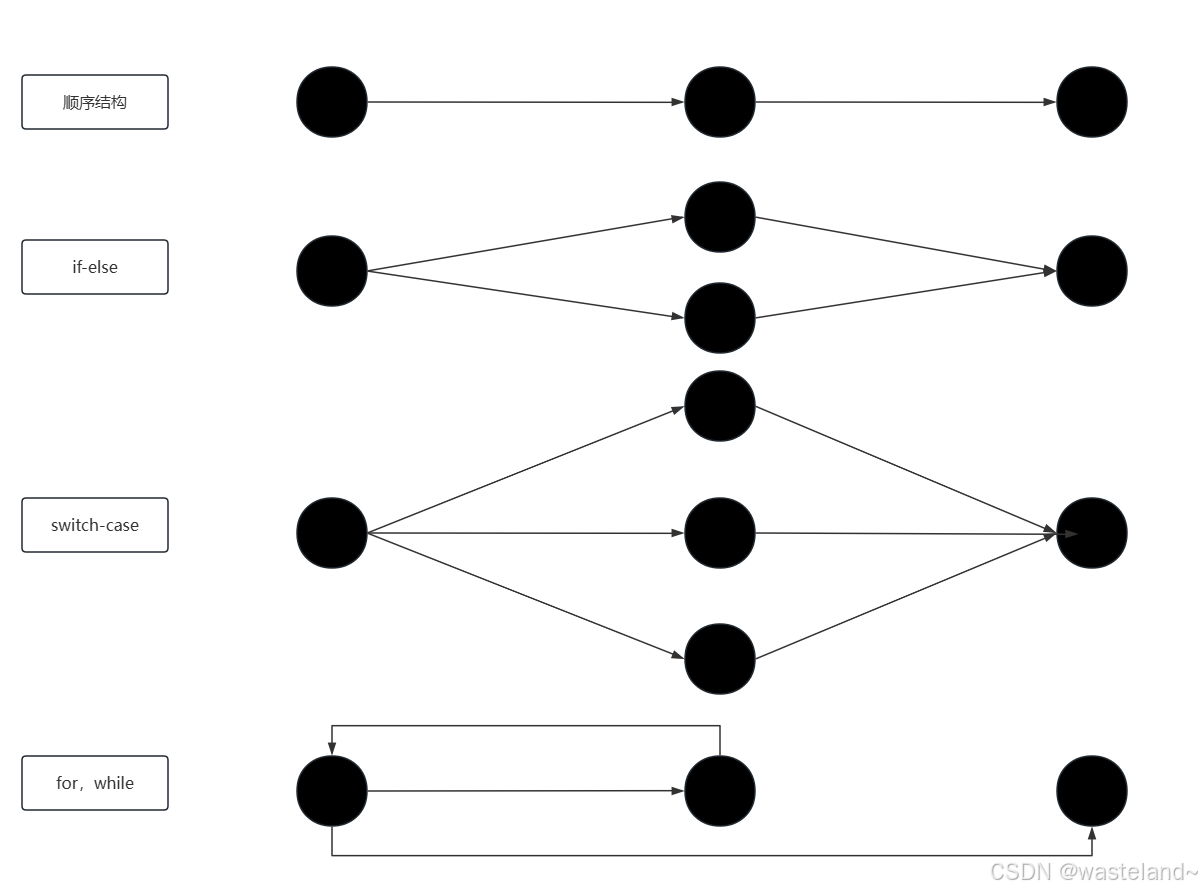
再利用点边计算法的公式计算出代码的圈复杂度之前,我们常需要先根据程序画出控制流图,然后再利用公式计算得出。因此这里先介绍一下典型的结构的控制流图,例如顺序结构,if-else,switch-case,for/while等。
下面以Gitee项目中的一段代码为例,我们尝试用点边计算法的公式来分析一下它的圈复杂度,首先我们来分析一下代码:
public ServerResponseEntity<Void> lock(List<SkuStockLockDTO> skuStockLocksParam) {
List<SkuStockLock> skuStockLocks = new ArrayList<>();
for (SkuStockLockDTO skuStockLockDTO : skuStockLocksParam) {
SkuStockLock skuStockLock = new SkuStockLock();
skuStockLock.setCount(skuStockLockDTO.getCount());
skuStockLock.setOrderId(skuStockLockDTO.getOrderId());
skuStockLock.setSkuId(skuStockLockDTO.getSkuId());
skuStockLock.setSpuId(skuStockLockDTO.getSpuId());
skuStockLock.setStatus(0);
skuStockLocks.add(skuStockLock);
// 减sku库存
int skuStockUpdateIsSuccess = skuStockMapper.reduceStockByOrder(skuStockLockDTO.getSkuId(), skuStockLockDTO.getCount());
if (skuStockUpdateIsSuccess < 1) {
throw new Mall4cloudException(ResponseEnum.NOT_STOCK, "商品skuId: " + skuStockLockDTO.getSkuId());
}
// 减商品库存
int spuStockUpdateIsSuccess = spuExtensionMapper.reduceStockByOrder(skuStockLockDTO.getSpuId(), skuStockLockDTO.getCount());
if (spuStockUpdateIsSuccess < 1) {
throw new Mall4cloudException(ResponseEnum.NOT_STOCK, "商品spuId: " + skuStockLockDTO.getSpuId());
}
}
// 保存库存锁定信息
skuStockLockMapper.saveBatch(skuStockLocks);
List<Long> orderIds = skuStockLocksParam.stream().map(SkuStockLockDTO::getOrderId).collect(Collectors.toList());
// 一个小时后解锁库存
SendStatus sendStatus = stockMqTemplate.syncSend(RocketMqConstant.STOCK_UNLOCK_TOPIC, new GenericMessage<>(orderIds), RocketMqConstant.TIMEOUT, RocketMqConstant.CANCEL_ORDER_DELAY_LEVEL + 1).getSendStatus();
if (!Objects.equals(sendStatus,SendStatus.SEND_OK)) {
// 消息发不出去就抛异常,发的出去无所谓
throw new Mall4cloudException(ResponseEnum.EXCEPTION);
}
return ServerResponseEntity.success();
}
然后根据代码再制出控制流图,流图如下所示:
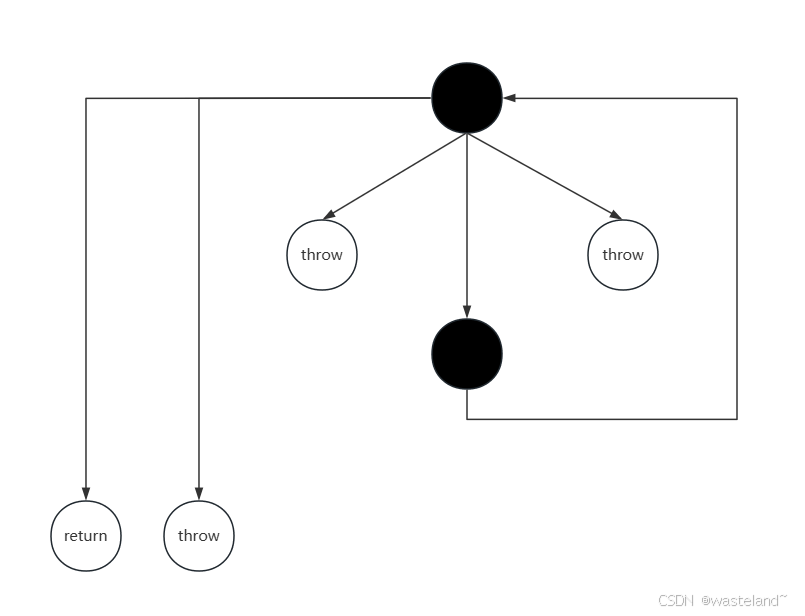
最后再根据公式 计算,V(G) = E - N + 2 = 6 – 3 + 2 = 5 ,则上面方法的圈复杂度为5。这里解释一下为什么N=3?虽然图上的真正节点有6个,但是其中有4个节点为throw或者return,这样的节点为end节点,只能记做1个。
② 节点判定法
除了上面介绍的计算方法外,圈复杂度的计算还有更直观的方法,因为圈复杂度所反映的是“判定条件”的数量,所以圈复杂度实际上就是等于判定节点的数量再加上1,也即控制流图的区域数,对应的计算公式为:
V (G) = P + 1
其中P为判定节点数,在遇到下面几种类型的时候,都需要记为一个判定节点:
🔥 if语句
🔥 while语句
🔥 for语句
🔥 case语句
🔥 catch语句
🔥 and和or布尔操作
🔥 ?:三元运算符
那么同样以上面的方法为例,这里利用节点判定法来计算一下它的圈复杂度。
public ServerResponseEntity<Void> lock(List<SkuStockLockDTO> skuStockLocksParam) {
List<SkuStockLock> skuStockLocks = new ArrayList<>();
for (SkuStockLockDTO skuStockLockDTO : skuStockLocksParam) { // 这里是一个判定节点
SkuStockLock skuStockLock = new SkuStockLock();
skuStockLock.setCount(skuStockLockDTO.getCount());
skuStockLock.setOrderId(skuStockLockDTO.getOrderId());
skuStockLock.setSkuId(skuStockLockDTO.getSkuId());
skuStockLock.setSpuId(skuStockLockDTO.getSpuId());
skuStockLock.setStatus(0);
skuStockLocks.add(skuStockLock);
// 减sku库存
int skuStockUpdateIsSuccess = skuStockMapper.reduceStockByOrder(skuStockLockDTO.getSkuId(), skuStockLockDTO.getCount());
if (skuStockUpdateIsSuccess < 1) { // 这里是一个判定节点
throw new Mall4cloudException(ResponseEnum.NOT_STOCK, "商品skuId: " + skuStockLockDTO.getSkuId());
}
// 减商品库存
int spuStockUpdateIsSuccess = spuExtensionMapper.reduceStockByOrder(skuStockLockDTO.getSpuId(), skuStockLockDTO.getCount());
if (spuStockUpdateIsSuccess < 1) { // 这里是一个判定节点
throw new Mall4cloudException(ResponseEnum.NOT_STOCK, "商品spuId: " + skuStockLockDTO.getSpuId());
}
}
// 保存库存锁定信息
skuStockLockMapper.saveBatch(skuStockLocks);
List<Long> orderIds = skuStockLocksParam.stream().map(SkuStockLockDTO::getOrderId).collect(Collectors.toList());
// 一个小时后解锁库存
SendStatus sendStatus = stockMqTemplate.syncSend(RocketMqConstant.STOCK_UNLOCK_TOPIC, new GenericMessage<>(orderIds), RocketMqConstant.TIMEOUT, RocketMqConstant.CANCEL_ORDER_DELAY_LEVEL + 1).getSendStatus();
if (!Objects.equals(sendStatus,SendStatus.SEND_OK)) { // 这里是一个判定节点
// 消息发不出去就抛异常,发的出去无所谓
throw new Mall4cloudException(ResponseEnum.EXCEPTION);
}
return ServerResponseEntity.success();
}
// 因此共计4个判定节点
根据公式 V(G) = P + 1 = 4 + 1= 5 ,则上面方法的圈复杂度为5。
2.2.2 MetricsReloaded插件统计
在IDEA中,我们可以利用MetricsReloaded插件帮忙进行Java方法的圈复杂度统计,大大提高我们的开发效率,但这里值得额外一提的是该插件目前并不支持Kotlin代码的圈复杂度统计。因此,对于使用Java和Kotlin混合编写代码的项目来说,掌握手动计算方法也显得尤为重要了。
那么MetricsReloaded插件如何使用呢?首先,我们可以去插件市场输入MetricsReloaded进行下载Install,这里因为我已经安装好,直接介绍如何使用。
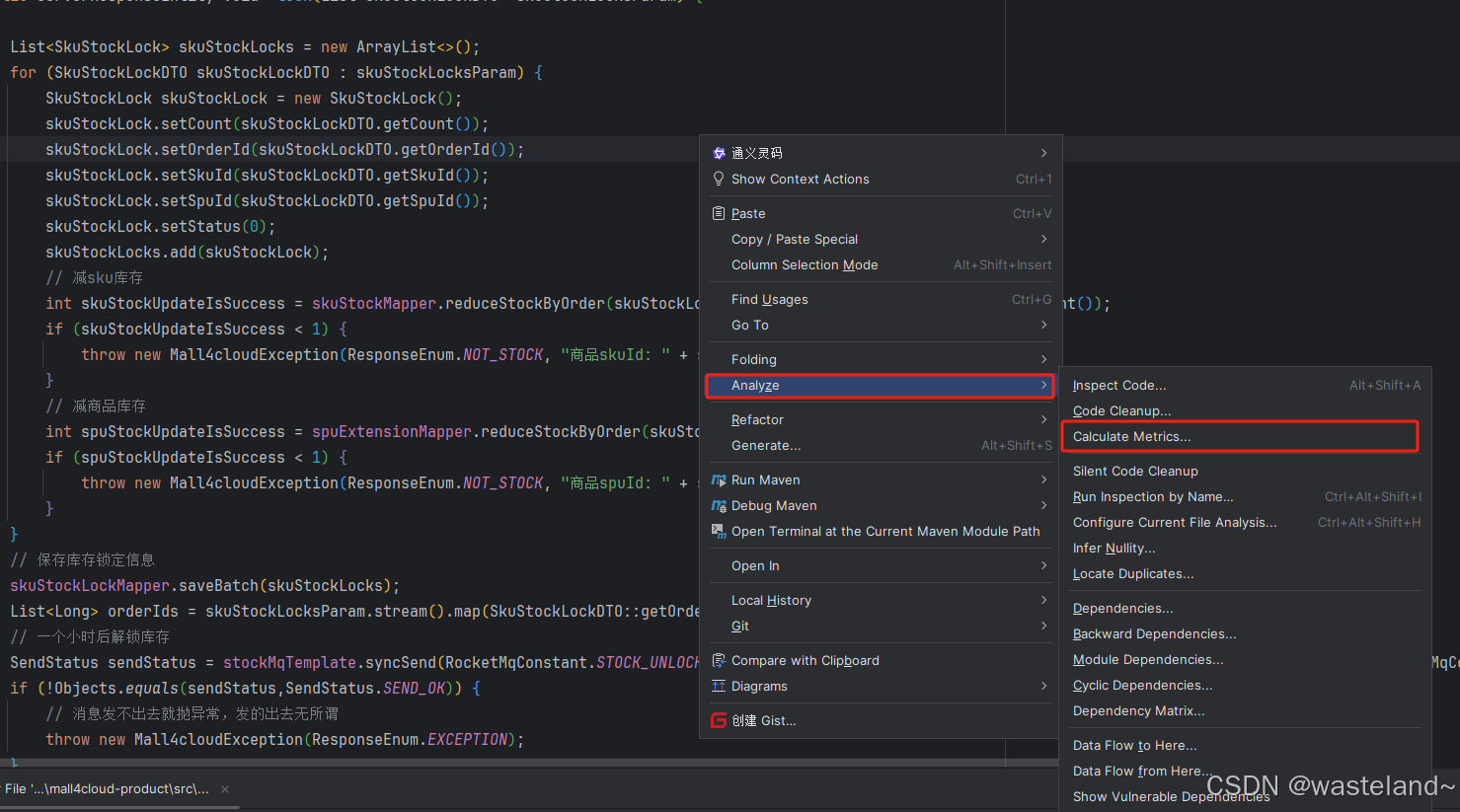
① 对要检测的类进行鼠标右键点击,然后按照下面图片的红框标出进行操作。
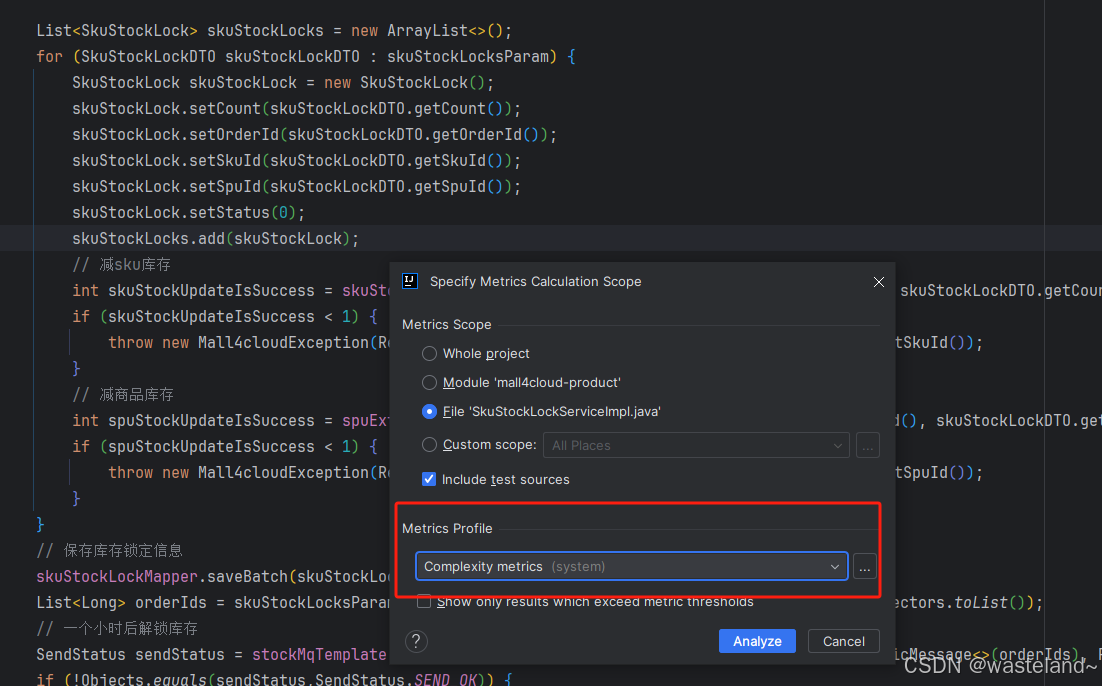
② 点击后,默认选项就好不用进行其他操作,点击Analyze。
③ 点击完Analyze按钮后,idea下面就会展示出对于该类中每个方法分析后的复杂度结果,如下图所示:
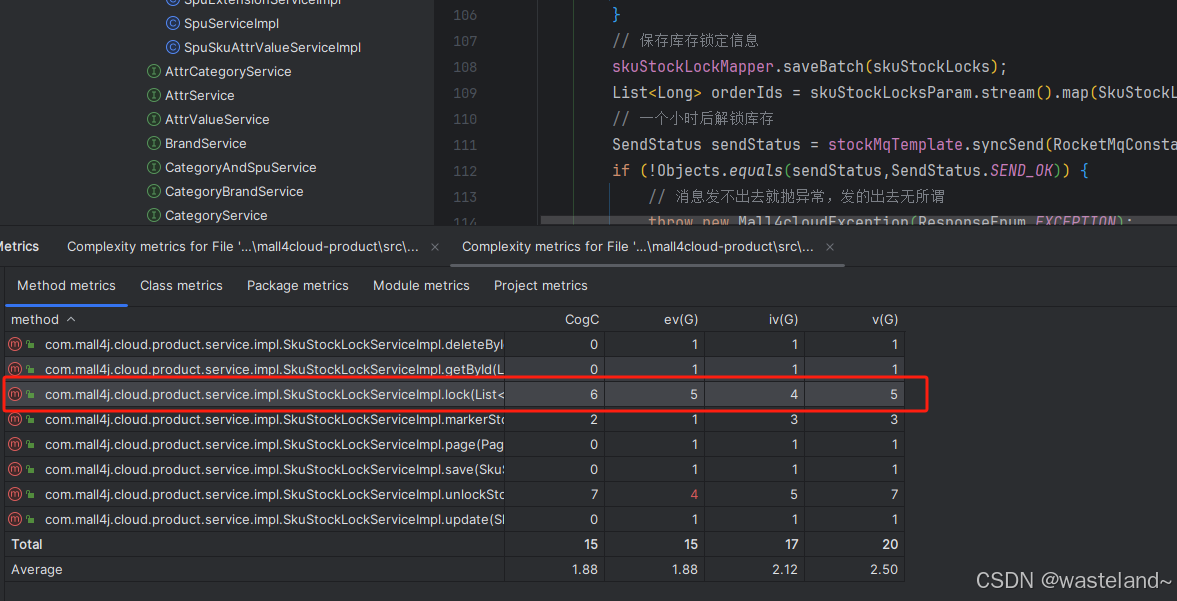
图中展示的最后一列就是圈复杂度。经过3种计算方式后,发现得出来的圈复杂度结果一致,符合预期。
2.3 降低圈复杂度的方式
当插件统计出圈复杂度后,我们应该如何去优化那些圈复杂度过高的方法呢?下面给大家介绍一下作者之前在公司治理圈复杂度时所总结的经验。
2.3.1 利用Optional类优化
其实常见的优化方式之一就是利用Optional类去优化代码,这样降低分支数后,不仅圈复杂度低,而且也更容易写单元测试。
// 优化前
public void test(Company company){
if(company != null){
// 获得公司老板
Boss companyBoss = company.getCompanyBoss();
// 获得公司员工数
Integer companyTotalNum = company.getCompanyTotalNum();
if(companyBoss != null){
if(companyTotalNum != null){
companyTotalNum -= 1;
companyBoss.setCompanyEmployeeNum(companyTotalNum);
}
}
....
}
}
// 优化后
public void test(Company company){
int num = Optional.ofNullable(company).map(Company::getCompanyTotalNum).orElse(0);
Optional.ofNullable(company).map(Company::getCompanyBoss).ifPresent(
boss -> boss.setCompanyEmployeeNum(num - 1)
);
}
2.3.2 抽取方法
我们还可以将一段功能代码按步骤抽取和拆分成小的方法,尽量保证方法的单一职责,这样也可以提高方法的复用性,常见的如一些判别平台、版本、场景等代码。这里以Gitee中开源项目一段代码为例:
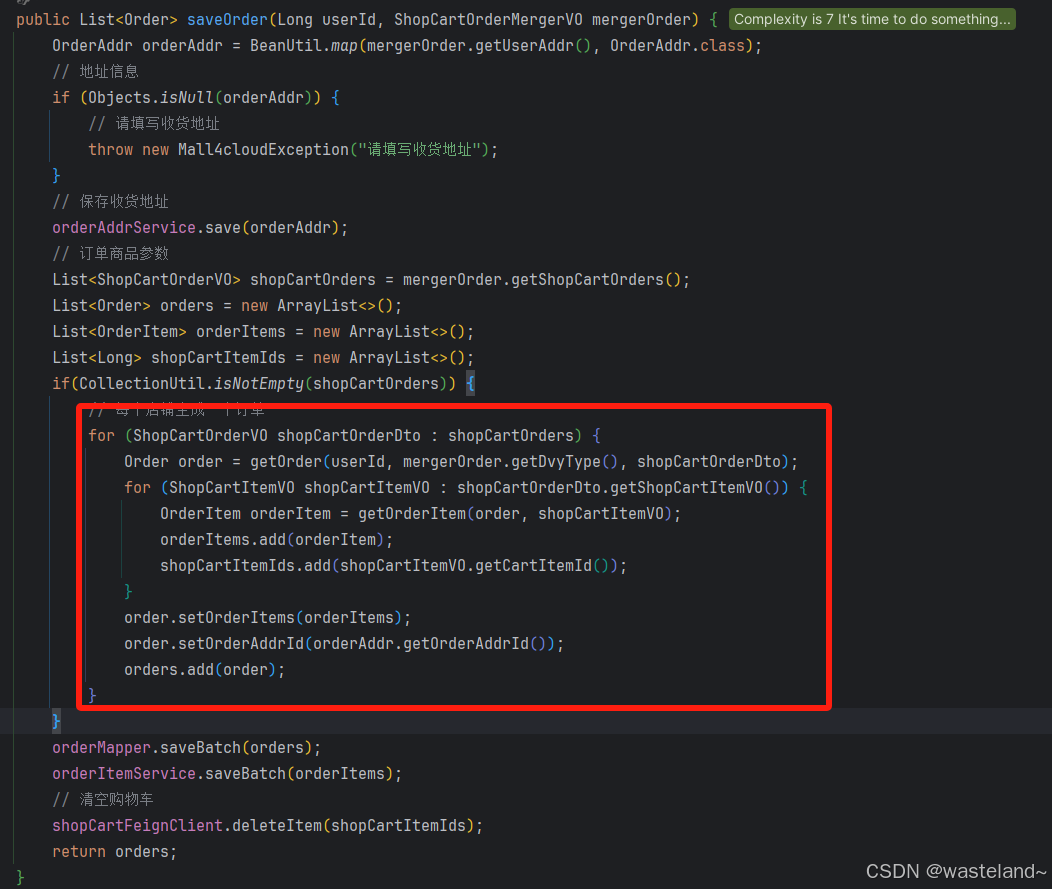
自己手动赋值提取方法其实是容易出错的,在IDEA中有快捷键可以一键提取。
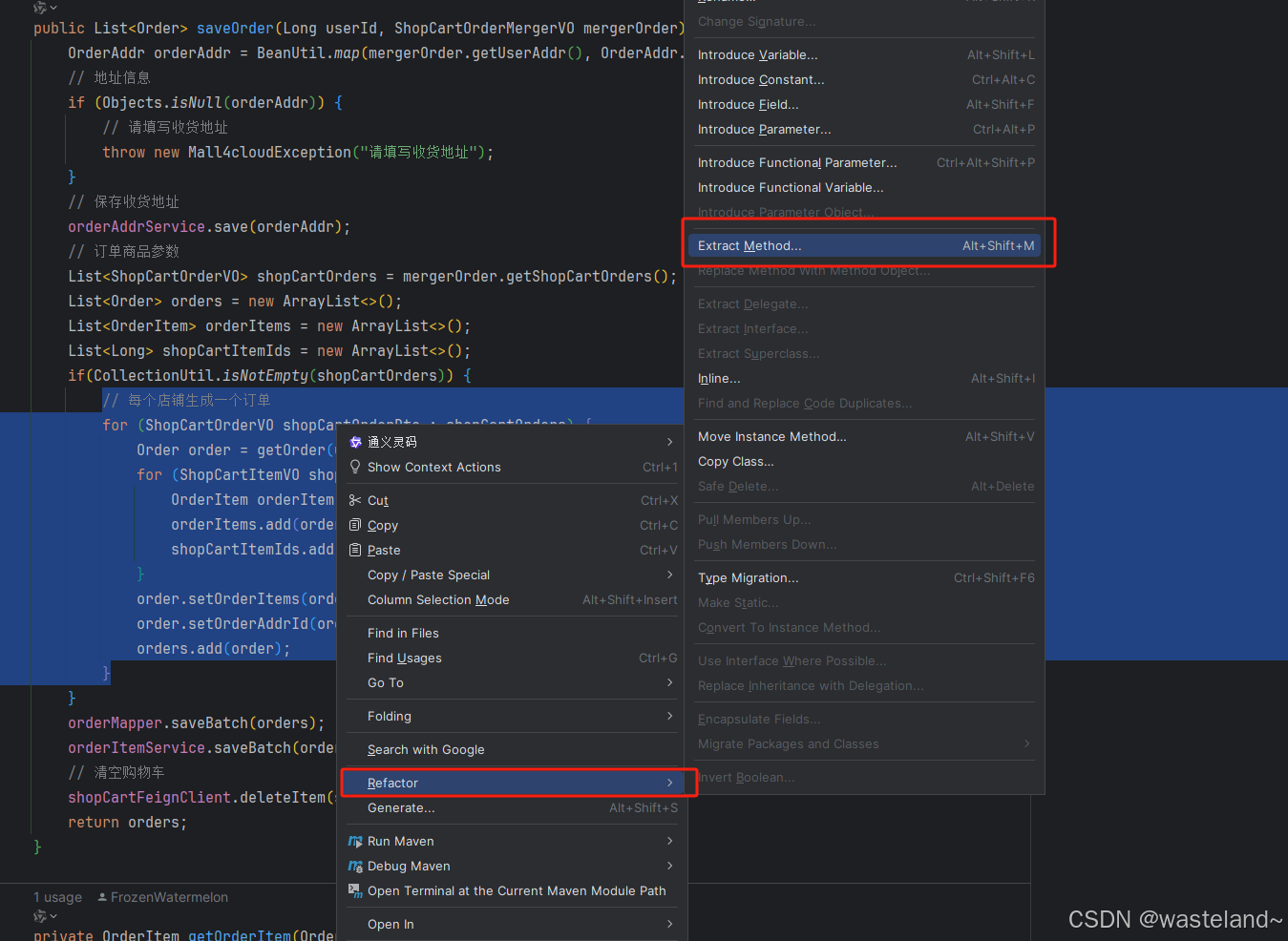
2.3.3 集合替代switch分支
在我们的代码中经常会碰到一些switch分支,像这种case我们其实有的时候就可以用数据结构去优化,比如用map或者list去替代,但可能在一定程度上又降低了我们的可读性,所以这个方法大家适量采取。这里举一个小案例:
private String getDayOfWeek(int day) {
switch (day) {
case 1:
return "星期一";
case 2:
return "星期二";
case 3:
return "星期三";
case 4:
return "星期四";
case 5:
return "星期五";
case 6:
return "星期六";
case 7:
return "星期日";
default:
return "不合法!";
}
}
像上面的代码,其实我们就可以用map集合去存储映射关系去降低圈复杂度,修改如下:
private static final Map<Integer, String> DAY_MAP = new HashMap<>();
static {
DAY_MAP.put(1, "星期一");
DAY_MAP.put(2, "星期二");
DAY_MAP.put(3, "星期三");
DAY_MAP.put(4, "星期四");
DAY_MAP.put(5, "星期五");
DAY_MAP.put(6, "星期六");
DAY_MAP.put(7, "星期日");
}
private String getDayOfWeek(int day) {
return DAY_MAP.getOrDefault(day, "不合法!");
}
2.3.4 设计模式替代if嵌套分支
利用设计模式去替代if分支是非常经典的一种优化方式,这里以策略模式来举例去优化代码,降低代码的复杂度。先假设一个简单的业务背景,假如我们是一个价格计算微服务的owner,服务职责划分为对某商城内不同场景的价格计算,但如果商城内价格计算的场景很多,例如有:秒杀算价、活动算价、跨店满减算价等等。这种业务场景下该如何设计呢?我们最简单的编码方式就是if-else来调用对应的算价方法,但是这样编写代码,不仅使得方法复杂度过高,还会使得我们不便于后续更好的接入新的算价的场景。当面临这种问题,我们可以想到采取策略模式去判断场景并优化代码。
public Result calcPrice(CalcPriceArgs calcPriceArgs){
//判断对应的计算价格的场景
Integer type = judgeType(calcPriceArgs);
//根据场景调用不同的方法 ,建议更好的编码习惯是把type改成枚举类型哈~
if(type == 1){
return calcPriceForTypeOne();
}
if(type == 2){
return calcPriceForTypeTwo();
}
if(type == 3){
return calcPriceForTypeThree();
}
......
}
这种情况下,我们可以采用策略模式对代码进行修改,使得代码变成了下面的样子:
//定义接口,供子类继承
public Interface CalcPriceInterface{
public Result calcPrice(CalcPriceArgs calcPriceArgs);
}
@Service
public class StrategyContext{
Map<Integer,CalcPriceInterface> strategyContextMap = new HashMap<>();
//注入对应的策略类
@Autowired
FirstStrategyRepsoitory firstStrategyRepository;
@Autowired
SecondStrategyRepsoitory secondStrategyRepsoitory;
@Autowired
ThirdStrategyRepsoitory thirdStrategyRepsoitory;
......
@PostConstruct
public void setStrategyContextMap(){
//设置对应的方法
strategyContextMap.set(1,firstStrategyRepository);
strategyContextMap.set(2,secondStrategyRepsoitory);
strategyContextMap.set(3,thirdStrategyRepsoitory);
......
}
//根据场景调用不同的方法
public Result calcPrice(CalcPriceArgs calcPriceArgs){
Integer type = judgeType(calcPriceArgs);
CalcPriceInterface calcPriceInstance = strategyContextMap.get(type);
return calcPriceInstance.calcPrice(calcPriceArgs);
}
}
@Controller
public class MallPriceCalController{
@Autowired
StrategyContext strategyContext;
@GetMapping("/calculatePrice")
public Result calcPrice(CalcPriceArgs calcPriceArgs){
......
strategyContext.calcPrice(calcPriceArgs);
......
}
}
......
2.3.5 使用工具类
我们可以使用一些工具类来减少判断语句,判空等操作可以使用工具类,减少||,&&的判断使用。例如StringUtils.isBlank(str)可替换str==null&&str=="",使用 hutool 工具包中的 StrUtil 工具类中的emptyToDefault() 方法。
String type = carInfo.getType();
if (StrUtil.isBlank(type)) {
type = "SUV";
carInfo.setType(type);
}
下面这段代码中使用StrUtil 工具类中的emptyToDefault() 方法可以完全平替上面这段代码,上面代码就少了一个分支,圈复杂度就降低了。
carInfo.setType(StrUtil.emptyToDefault(carInfo.getType(), "SUV"));
2.3.6 使用卫语句
卫语句(guard clauses)是一种改善嵌套代码的优化方案,将某些要害(guard)条件优先作判断,从而简化程序的流程走向。这里举个常见的例子,一般情况下对于未登录的用户,在代码中我们都会做一个拦截,这样可以避免掉大量的无效调用甚至爬虫,最终提高我们系统的稳定性。
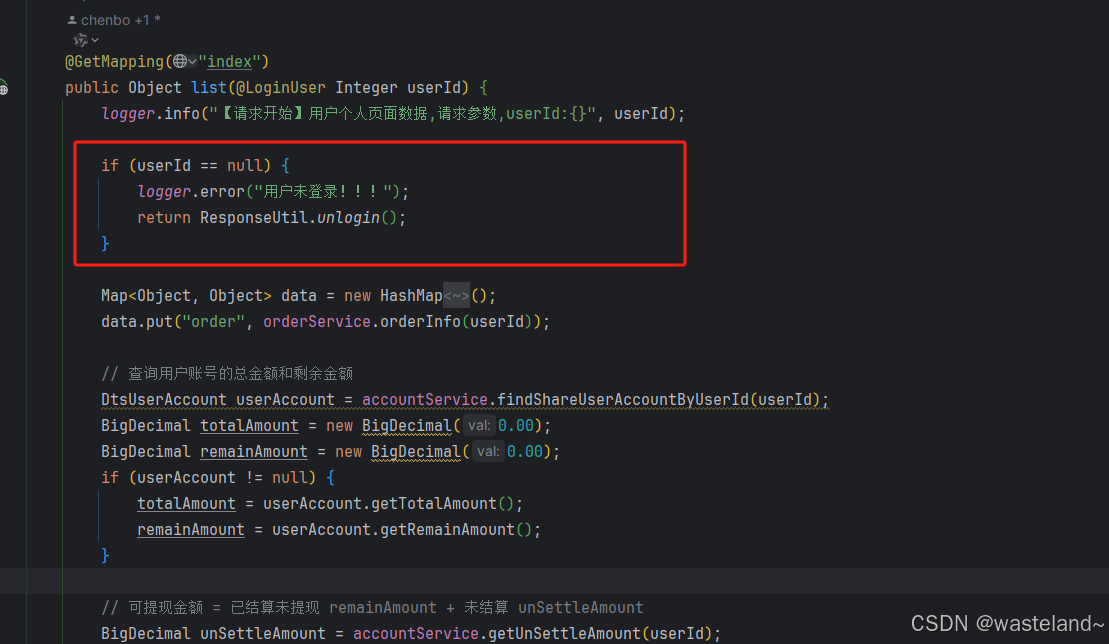
三、认知复杂度
3.1 认知复杂度概念
来到这个章节,有小伙伴可能有疑问了,既然圈复杂度已经可以衡量代码的复杂度,那么为什么还需要了解认知复杂度呢?那是因为圈复杂度最初的目的是用来识别“难以测试和维护的软件模块”,它能算出最少的全覆盖的测试用例量,但是不能测出一个让人满意的“理解难度”。而且因为每个方法的最小圈复杂度都是1,导致了类的“圈复杂度”与其方法数量相关。一个很好理解的Class(类),也可能因为包含多个简单方法,总复杂度被抬得很高。
为了解决这些问题, SonarQube制定了认知复杂度(Cognitive Complexity),一方面解决了圈复杂度在现代语言结构的不足,一方面使复杂度在方法、类、应用程序级别都有实际意义。 更重要的是,这个复杂度值与程序员理解这些代码片段所需的直觉(理解难度)相对应。我们可以用一个简单的案例来分析:
// 方法一:
public String getCalSceneName(int sceneType) { // +1
//判断对应的计算价格的场景
switch (sceneType) {
case 1: // +1
return "秒杀算价";
case 2: // +1
return "活动算价";
case 3: // +1
return "跨店满减算价";
default:
return "其他算价";
}
} // 因此方法一的圈复杂度为4
// 方法二:
public int sumOfPrice(int max) { // +1
int total = 0;
for (int i = 1; i <= max; i++) { // +1
for (int j = 2; j < i; j++) { // +1
if (i % j == 0) { // +1
continue;
}
}
total += i;
}
return total;
} // 因此方法二的圈复杂度为4
比如上面的代码,虽然其计算得出的圈复杂度是一样的,但是方法二明显比方法一更难理解,因为它嵌套的层数更多。其实认知复杂度一定程度上可以理解为衡量方法中分支的嵌套层数的指标。 在这里,我们可以用数据结构中的树的概念去理解这两个复杂度,圈复杂度的大小强调了树的分支的多少,而认知复杂度的大小强调了树的层数的多少。那么我们可以想象到树又高又胖就非常庞大,与此类比,类中的方法分支又多嵌套的又深,也会非常臃肿,最终,就会造成开发人员难以理解难以维护的问题。
3.2 认知复杂度计算
3.2.1 手动计算
认知复杂度的手动计算其实比圈复杂度的计算更为复杂,非常容易算错,但又因为插件当前不支持对Kotlin代码复杂度的统计,所以掌握手动计算的方式还是尤为重要的。如下会介绍一下面对不同的场景,认知复杂度所加的分值的差异点。
结构化场景:【+1分】
🔥 循环: for, while, do while, …
🔥 条件: 三元运算符, if else…
🔥 Catch:
一个catch表达了控制流的一个分支,就像if一样。因此每个catch语句都会增加Structural类的认知复杂度,仅加1分,无论它catch住多少种异常。(在我们的计算中try\finally被直接忽略掉)。
🔥 Switch:
一个switch语句,和它附带的全部case绑在一起记为一个Structural类,复杂度仅增加1。(不像圈复杂度,每个case都会使得控制流分支增加,进而增加圈复杂度)Switch可以视为用单个变量与一组值作匹配,是一目了然的,因此要比if-else链更容易理解,因此认知复杂度更低。
连串逻辑操作场景:【+1分】
认知复杂度不对每一个逻辑运算符计分,而是考虑对连续的一组逻辑操作加分。例如下面几个操作:
a && b
a && b && c && d
a || b
a || b || c || d
理解后一行的操作,不会比理解前一行的操作更难,上面的四种认知复杂度都是1。但是对于下面两行,理解难度有质的区别:
a && b && c && d
a || b && c || d
这是因为boolean操作表达式混合使用时,难度会显著上升,因此认知复杂度的值会不断递增。具体计算方法如下:
public void calcCog1() {
boolean a = false, b = false, c = true, d = true, e = true, f = true;
if (a // if分支+1
&& b && c // +1
|| d || e // +1
&& f) { // +1
System.out.println("圈复杂度为4");
}
}
public void calcCog2() {
boolean a = false, b = false, c = true, d = true, e = true, f = true;
if (a // if分支+1
&& // +1
!(b && c)) { // +1
System.out.println("圈复杂度为3");
}
}
嵌套场景:【基于上一层嵌套的分数+1分】
其实直观上来看连续嵌套的代码本身就要比线性代码难理解很多。嵌套会增加理解代码的成本,所以认知复杂度在计算时会将其单独归类,视为一个Nesting类的复杂度增加。
认知复杂度计算的场景基本就上面介绍的那些,接下来我们举个例子来加深对上面场景的理解。这里我们以上面引入认知复杂度概念的例子来分析其圈复杂度差异:
// 方法一:
public String getCalSceneName(int sceneType) {
//判断对应的计算价格的场景
switch (sceneType) { // +1
case 1:
return "秒杀算价";
case 2:
return "活动算价";
case 3:
return "跨店满减算价";
default:
return "其他算价";
}
} // 因此方法一的认知复杂度为1
// 方法二:
public int sumOfPrice(int max) {
int total = 0;
for (int i = 1; i <= max; i++) { // +1
for (int j = 2; j < i; j++) { // +2
if (i % j == 0) { // +3
continue;
}
}
total += i;
}
return total;
} // 因此方法二的认知复杂度为6
3.2.2 MetricsReloaded插件统计
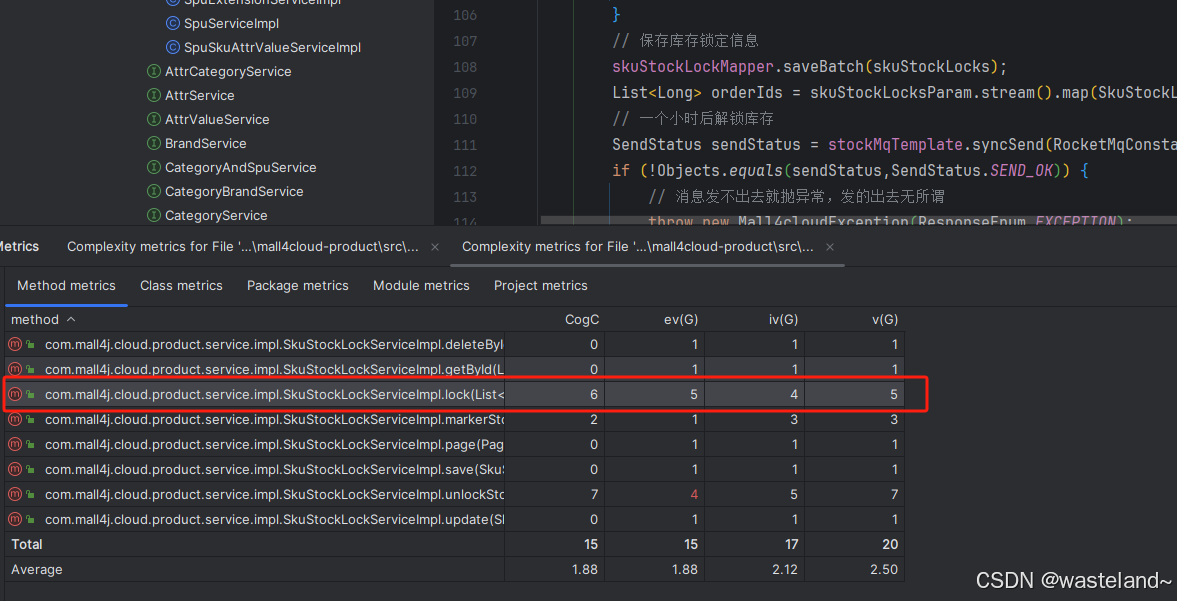
虽然上面我们介绍了手动的统计方法,但是在实际优化的大多数过程中,我们还是推荐首选插件统计的方式去帮助我们优化代码,因为那样更为准确。使用MetricsReloaded插件统计认知复杂度和统计圈复杂度的步骤完全一样,其实统计完之后,我们就能看到不同方法的认知复杂度,如下图所示,第一列CogC就是代表这方法的认知复杂度。
3.3 降低认知复杂度的方式
对于降低认知复杂度的方式,这里就不做过多的介绍,大家可以参考第二章节中降低圈复杂度的方式去优化代码,因为降低认知复杂度的方式和降低圈复杂度的方式有很多重叠之处,在降低其中一种复杂度的过程当中,一般情况下都会顺带降低了另一种复杂度。因此,这里就只额外列出一个优化方式。
语法糖优化:
在开发中我们可以用语法糖去优化我们的代码,进而降低各种复杂度。
public Map<Long, Integer> countSkuNum(List<OrderSkuQuery> orderSkuQueryList) {
Map<Long, Integer> res = Maps.newHashMap();
//累加商品id相同的sku数量
for (OrderSkuQuery orderSkuQuery : orderSkuQueryList) {
if (res.containsKey(orderSkuQuery.getItemsId())) {
res.put(orderSkuQuery.getItemsId(), orderSkuQuery.getSkuNum() + res.get(orderSkuQuery.getItemsId()));
} else {
res.put(orderSkuQuery.getItemsId(), orderSkuQuery.getSkuNum());
}
}
return res;
}
借助 java.util.Collection.stream 、java.util.Map.compute ,在一个表达式里面实现了商品数量的累加,抹除了for循环与if else带来的圈复杂度和认知复杂度。
public Map<Long, Integer> countSkuNum(List<OrderSkuQuery> orderSkuQueryList) {
Map<Long, Integer> res = Maps.newHashMap();
orderSkuQueryList.stream().forEach(orderSkuQuery -> res.compute(orderSkuQuery.getItemsId(),
(k, v) -> v == null ? orderSkuQuery.getSkuNum() : v + orderSkuQuery.getSkuNum()));
return res;
}
四、降低圈复杂度与认知复杂度的意义
复杂度与缺陷:
多研究指出一模块及方法的圈复杂度和其中的缺陷个数有相关性:圈复杂度最高的模块及方法,其中的缺陷个数也最多。因此,在降低方法的圈复杂度数后,会一定程度的帮助开发降低代码中的缺陷个数。
圈复杂度与TDD:
TDD(测试驱动的开发,test-driven development)和低CC值之间存在着紧密联系。在编写测试时,开发人员会考虑代码的可测试性,倾向于编写简单的代码,因为复杂的代码难以测试,且支太多之后,分支覆盖经常难以覆盖完全,需要编写大量且复杂的单元测试。因此TDD的“代码、测试、代码、测试” 循环将导致频繁重构,驱使非复杂代码的开发。
代码重构:
对于历史代码的维护或重构,测量圈复杂度特别有价值,我们常利用圈复杂度作为优化代码的切入点对代码进行重构。
阅读与维护:
如果不对方法中的分支数和嵌套层数加以控制,其会变的越来越难以阅读和维护,会极大的增加开发人员的维护成本。
五、总结
当公司业务发展到一定程度时,相应的项目也会跟随其蓬勃发展,如果不加强代码评审和质量把关,项目中的类会越来越多,类中的方法也会越来越长,慢慢就会出现我们所谓的"屎山",最终导致开发人员都不敢轻易更改,给开发人员带来了极大的阻碍,严重降低开发效率。因此,将圈复杂度和认知复杂度这两个概念引入到我们的项目中是非常有必要的,其不仅可以作为我们去评审代码提交质量的标准之一,也可以作为我们去优化自己项目的一个切入点。
创作不易,如果有帮助到你的话请给点个赞吧!我是Wasteland,下期文章再见!



















 791
791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











