







本文总结的是某呼用户文章
导语
transformer打破了传统的卷积网络的垄断,我这里插一些别的东西,其实一直都不太理解很多的词语之间的关系,首先深度学习模型有
MLP多层感知机,由多个全连接层组成,用于解决分类与回归问题
CNN卷积神经网络,用于处理图像与视频,具有卷积层和池化层,能够很好的提取图像特征
RNN循环神经网络,用于处理序列数据,如自然语言,具有循环结构可以捕捉序列中的依赖关系
LSTM长短时记忆网络,是一种特殊的RNN,通过记忆单元解决了传统RNN中梯度消失的问题,适用于处理长序列数据
GRU门控循环单元,与LSTM类似,也是一种处理序列数据的RNN结构,但是参数少,计算简单
Transformer自注意力机制,用于处理序列数据的模型,特别适合自然语言处理任务,引入了注意力机制,能够在输入序列中更好的捕捉长距离依赖关系
GAN生成对抗网络,包括生成器和判别器,用于生成逼真的数据样本,用于图像生成和风格迁移任务
VAE变分自编码器,用于学习潜在变量表示的生成模型,用于图像与音频数据的生成
强化学习模型,包括深度Q网络,深度确定性策略梯度,用于解决决策和控制问题
ResNet深度残差网络:引入残差连接,解决了深度神经网络训练时梯度消失和梯度爆炸的问题,常用于图像分类任务
机器学习模型有:
Linear Regression线性回归:用于建模输入特征与输出变量之间的线性关系,适用于回归问题
Logistic Regression逻辑回归:用于解决分类问题,通过逻辑函数将输入映射到二元输出
Decision Trees决策树:每个节点表示一个特征,每个叶子节点表示一个输出
Random Forest随机森林:由多个决策树组成通过投票和平均方式来提高模型的鲁棒性和准确性
SVM支持向量机:用于分类与回归任务,通常在特征空间中找到最大的间隔来划分不同的类别
KNN近邻算法:通过测试样本之间的距离,将新样本分类为其最近邻居的多数类别
朴素贝叶斯:用于处理分类任务垃圾邮件
神经网络:用于处理复杂的模式识别任务
聚类算法:k均值聚类,层次聚类
降维算法:PCA,t-SNE
增强学习:通过智能体与环境的交互
集成学习:包括Bagging和Boosting
ok回到正题,谷歌的BERT模型中起关键作用的是Transformer,通过利用self-attention机制改进RNN训练慢的问题
宏观视角

剖开第一层
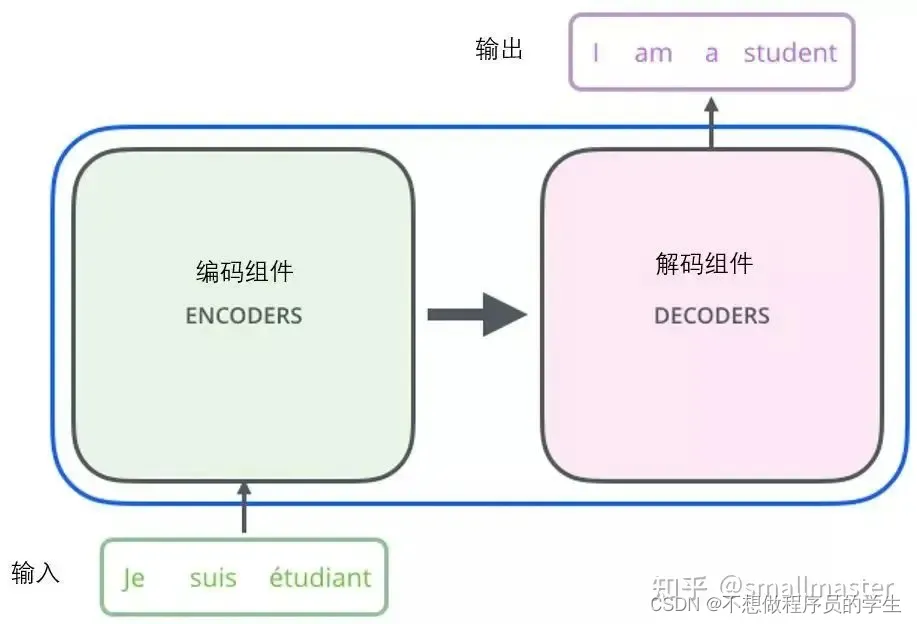
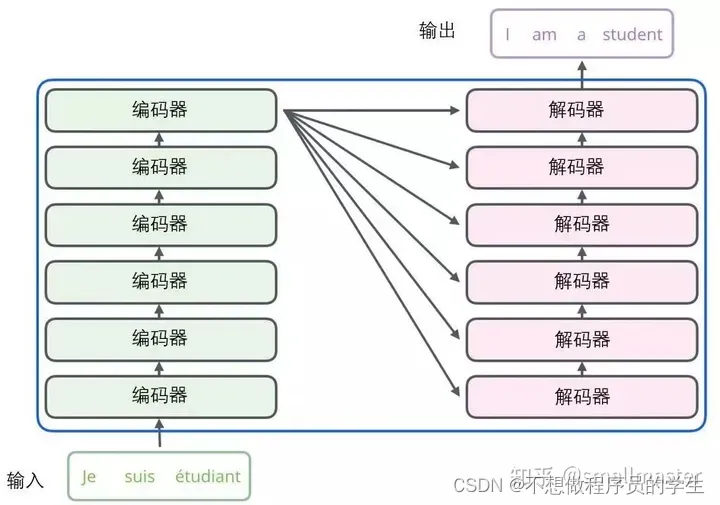
剖开两个器件
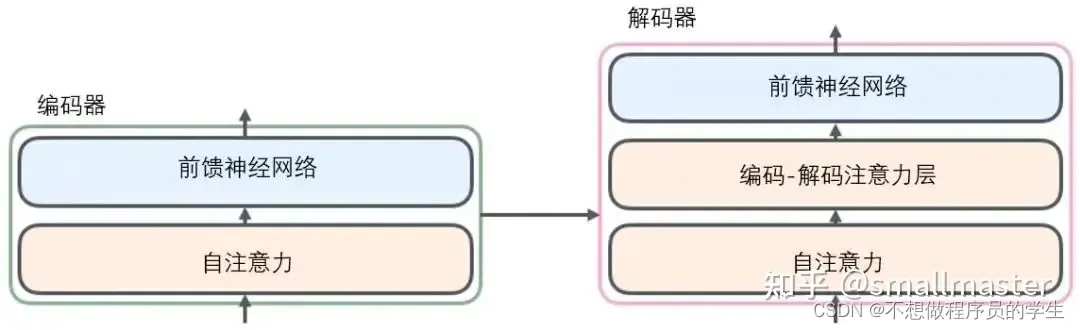
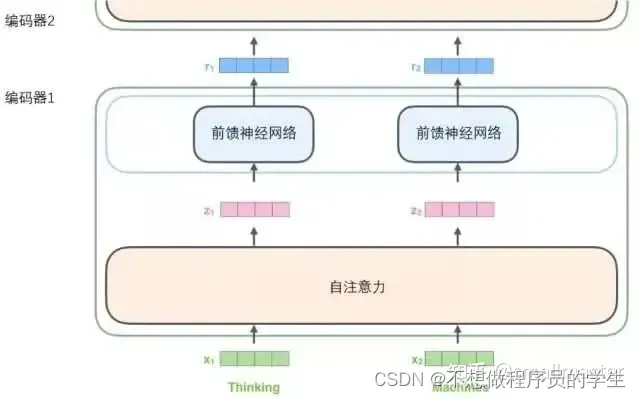
自注意力层帮助编码器在对每个单词编码是关注输入句子的其他单词,每个位置的单词对应的前反馈神经网络都是一样的(一层窗口为一个单词的一维卷积神经网络)难懂,解码器中的注意力层是用来关注输入句子的相关部分
将每个单词通过词嵌入算法转化为词向量,每个单词被嵌入为512维的向量,词嵌入只发生在最底层的编码器,每一层编码器都接受向量列表,向量列表的大小是我们设置的超参数一般为我们训练集中最长句子的长度,在子注意力层中,路径存在依赖关系,前馈层没有这些依赖关系,所以可以并行执行各种路径(transformer的核心特性就是输入序列中的每个位置的单词都有自己独特的路径流经编码器)
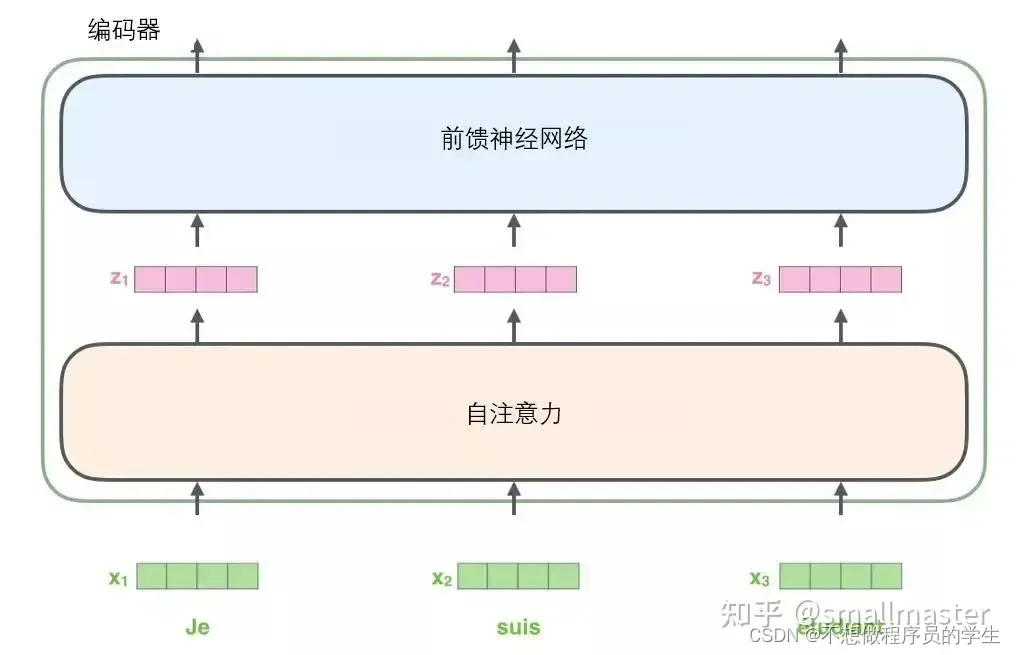
现在focus编码
输入序列每个单词自编码过后,各自通过前馈神经网络。
对于自注意力机制宏观上理解就是将所有相关单词的理解融入到我们正在处理的单词中,微观上来看就是精确的计算过程
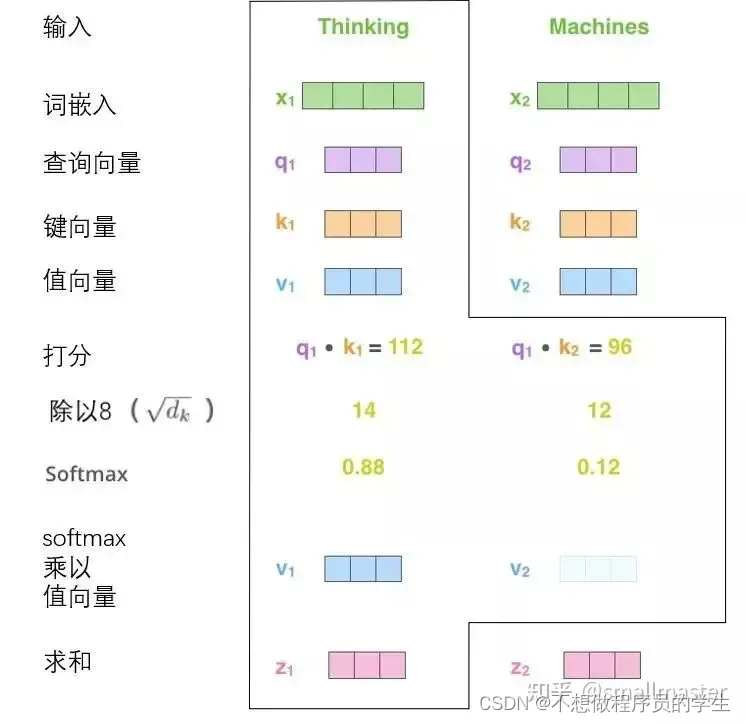
从上图可以看出
1.通过词向量生成的三个向量,查询向量,键向量,值向量,通过三个权重矩阵得来的,
2.计算得分,比如计算一个单词的得分,这个分数决定了在编码这个单词时候有多重视句子中的其他成分,通过所有输入句子中的单词的键向量和这个单词的查询向量点积来计算得到的
3.将分数除以8,会让梯度更稳定,然后通过softmax传递结果,目的是围巾将所有单词的分数归一化,都是正值的分数且和为1。此时的8softmax分数决定了每个单词对编码当前位置的贡献*
4.将每个值向量乘softmax分数,这里是为了后续的求和
5.对加权值进行求和,最终就得到了输出z,这个向量就可以传给前馈神经网络
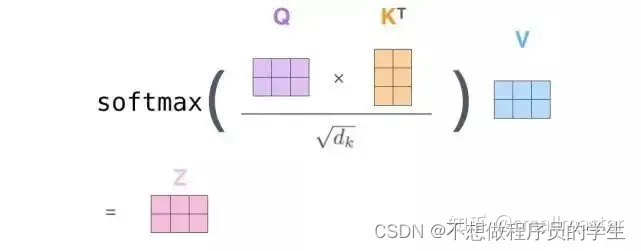
自注意力的矩阵运算形式:通过增加一个叫做“多头”注意力的机制,论文进一步完善了自注意力层性能提高在1.扩展了模型专注于不同位置的能力2.他给出了注意力层的多个“表示子空间”,在训练之后,每个集合都被用来将输入词嵌入投影到不同的表示子空间中。
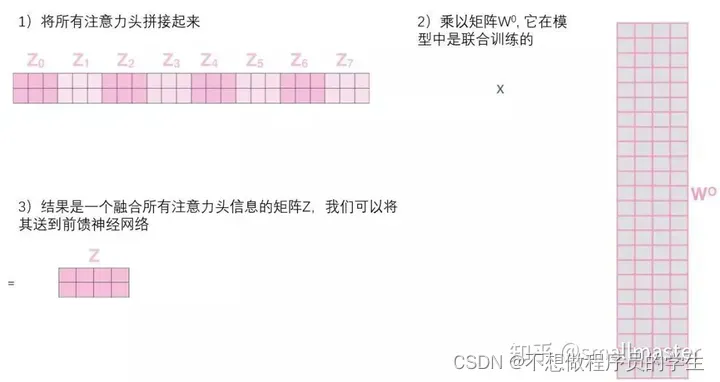
在“多头”注意机制下,我们进行八次矩阵运算得到八个不同的Z矩阵,通过拼凑之后附加一个权重矩阵与他想乘运算。
使用位置编码表示序列的顺序
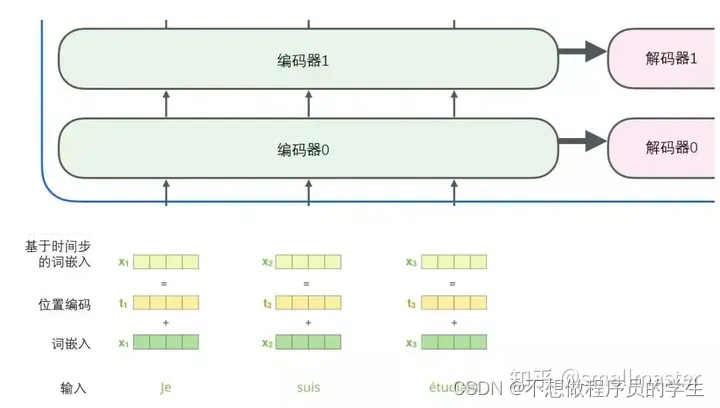
如图所示,由于对模型的描述缺少一种理解输入单词顺序的方法,所以添加了位置编码向量这块可能看代码原论文更清楚
残差模块
每个编码器中的每个子层的周围都有一个残差连接,并且跟随着一个归一化步骤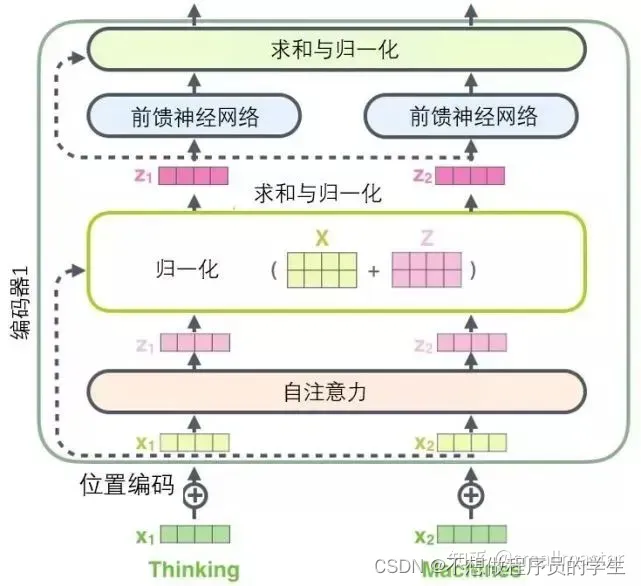
在解码器中也是一样的,图示为一个两层的编码解码结构的transformer模型
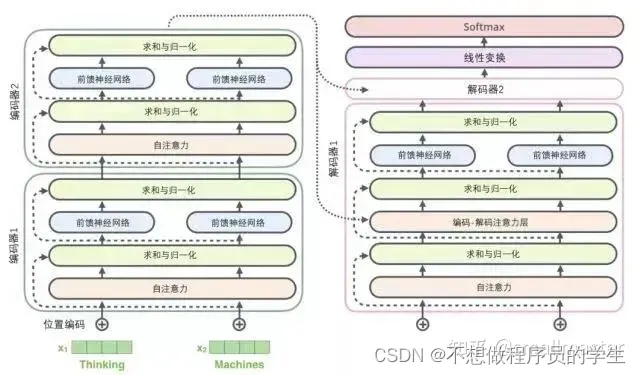
解码器
顶端编码器的输出之后会转化为包含向量KV的注意力向量集,用在解码器的编码-解码注意力层。解码阶段的每个步骤都会输出一个输出序列,直到到达一个特殊的终止符号,也会像编码器那样嵌入位置编码来表示每个单词的位置。
在解码器中,自注意力层制备允许处理输出序列中更靠前的位置,在softmax之前,他会把后面的位置隐去
编码-解码注意力层工作方式类似于多头自注意力层以掩护,通过下面的层来创建查询矩阵,并且从编码器中取得键/值矩阵
最终的线性变换和softmax层
线性变换层做的就是将浮点数变成一个单词,他就是一个简单的全连接神经网络,可以把解码组件产生的向量投影到一个比他大的被称为对数几率的向量中去,比如有一万个单词,那么对数几率向量中就有一万个单元格长度的向量
softmax层就把这些分数变成概率,概率最高的单元格被选中,并且按照对应的单词作为这个时间步的输出。
后续还有一个全面的博客打算在深入的看一下transformer。
我希望通过上文已经让你们了解到Transformer的主要概念了。如果你想在这个领域深入,我建议可以走以下几步:阅读Attention Is All You Need,Transformer博客和Tensor2Tensor announcement,以及看看Łukasz Kaiser的介绍,了解模型和细节。
Attention Is All You Need:https://arxiv.org/abs/1706.03762Transformer博客:https://ai.googleblog.com/2017/08/transformer-novel-neural-network.htmlTensor2Tensor announcement:https://ai.googleblog.com/2017/06/accelerating-deep-learning-research.htmlŁukasz Kaiser的介绍:https://colab.research.google.com
本文参考博客:https://zhuanlan.zhihu.com/p/660267333














 2395
2395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









