






综合评价方法
1.综合评价的基本理论和数据预处理
综合评价方法的基本理论和数据预处理
前言
所谓综合评价是指根据一个系统同时受多个因素影响的特点,在综合考察多个有关因素,依照多个相关指标对系统进行总评价的方法。目前,已经提出了很多综合评价方法,如:TOPSIS法,层次分析法,模糊综合评价法、灰色系统法等。本系列将介绍一些常用的评价方法的基本原理、主要步骤、在Python中的实现以及利弊。
一、综合评价的基本概念
一般地,一个综合评价问题是由评价对象、评价指标、权重系数、综合评价模型和评价者五个基本要素组成。
1.评价对象
评价对象就是综合评价问题中所研究的对象,或称为系统,通常情况下,在一个问题中评价对象是属于同一类的,且个数要大于 1,不妨假设一个综合评价问题中有n个评价对象,分别记为
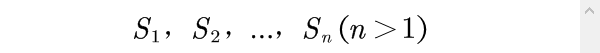
2.评价指标
评价指标是反映对象的运行(或发展)状况的基本要素。通常的问题都是有多项指标构成,每一项指标都是从不同的侧面刻画系统所具有某种特征大小的一个度量。
一个综合评价问题的评价指标一般可用一个向量表示,称为评价指标向量,其中每一个分量就是从一个侧面反映系统的状态;也称为综合评价的指标体系。在建立评价指标体系时,一般应遵循以下原则:1)系统性;2) 独立性;3)可观测性;4) 科学性;5) 可比性。不失一般性,设系统有m个评价指标,分别记为
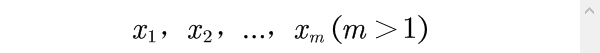
即评价指标向量为
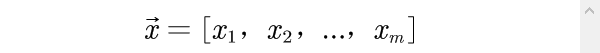
3.权重系数
每一个综合评价问题都有相应的评价目的,针对某种目的,各评价指标之间的相对重要性是不同的,评价指标之间的这种相对重要性的大小,可用权重系数来刻画。如果用
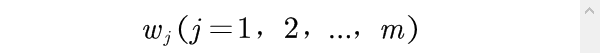
来表示评价指标
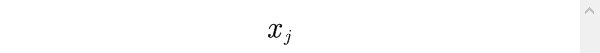
的权重系数,一般应满足
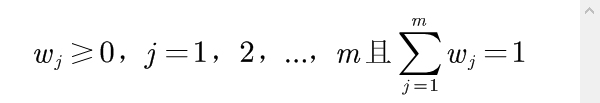
当各评价对象和评价指标值都确定以后,综合评价结果就依赖于权重系数的取值了。即权重系数的合理与否,直接关系到综合评价结果的可信度,甚至影响到最后决策的正确性。因此权重系数的确定要特别谨慎,应按一定的方法和原则来确定。
4.综合评价模型
对于多指标(或多因素)的综合评价问题,就是要通过建立一定的数学模型将多个综合评价值综合成为一个整体的综合评价值,作为综合评价的依据,从而得到相应的评价结果。
不妨假设第i(i=1,2,…,n)个评价对象的m个评价指标值构成的向量为
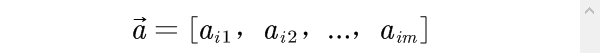
指标权重向量为
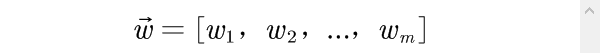
由此构造综合评价模型
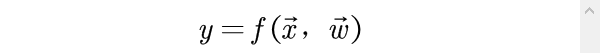
并计算出第i个评价对象的综合评价值
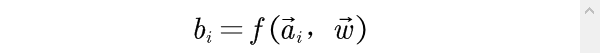
根据
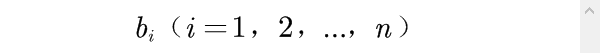
值的大小,将这n个评价对象进行排序或分类,即得到综合评价结果。
5.评价者
评价者是直接参与评价的人,对于评价目的的选择、评价指标的确定、权重系数的确定和评价模型的建立都与评价者有关。
二、综合评价体系的构建
综合评价过程包括评价指标的建立、评价指标的预处理、指标权重的确定和评价模型的选择等重要环节。其中评价指标体系的构建与评价指标的筛选是综合评价的重要基础,也是做好综合评价的保证。
1.评价指标和评价指标体系
所谓指标就是用来评价系统的参量。例如,河流的含氧量、PH值、细菌总数、植物性营养物量等,可以作为评价河流水质情况的主要指标。一般来说,任何一个指标都反映和刻画事物的一个侧面。
从指标的变化对评价目的的影响来看,可以将指标分为以下四类:
1)极大型指标(又称效益型指标)是标值越大越好的指标;
2)极小型指标(又称成本型指标)是标值越小越好的指标;
3)中间型指标是标值越接近某个值越好的指标;
4)区间型指标是标值落在某个区间最好的指标;
例如,在评价河流的水质情况时,含氧量作为指标,其值越大,水质情况越好,这就是极大型指标;细菌总数作为指标,其值越小,水质情况就越好,这就是极小型指标;PH值既不能太高也不能太低,这就是中间型指标;植物性营养物量既不能太高也不能太低,这就是区间型指标。
从指标的特征来看,指标可以分为定性指标和定量指标。定性指标是用定性的语言作为指标描述值。例如,食品服务视频安全监督量化分级。
在实际中,不论按什么方式对指标进行分类,不同类型的指标可以通过相应的数学方法进行相互转换。所谓评价指标体系就是由众多评价指标组成的指标系统。在指标体系中,每个指标对系统的某种特征进行度量,共同形成对系统的完整刻画。
2.评价指标的筛选方法
筛选评价指标,要根据综合评价的目的,针对具体的评价对象,评价内容收集有关指标信息,采用适当的筛选方法对指标及进行筛选,合理地选取主要指标,剔除次要指标,以简化评价指标体系。
前文介绍评价指标时曾提及建立评价指标体系的一般原则,以下为其详细说明:1)系统性,即全面考虑影响决策目标的因素,注意选取影响力(或重要性)较强的属性;2) 独立性,即各个属性之间尽量独立,至少相关性不能太强;3)可观测性,即尽量选取能够定量的属性,定性的也要能分出明确的优劣程度;4) 科学性,即当属性数量太多时应该将它们分类,上层的每一属性包含下层的若干子属性;5) 可比性,即如果某个属性对各备选方案的差别很小,根据该属性就难以辨别方案的优劣,那么这个属性就不必选入(即使它对决策目标的影响力很强)。
常用的评价指标筛选方法主要有专家调研法、最小均方差法、极大极小离差法等。
1)专家调研法(Delphi法)
评价者根据评价目标和评价对象的特征,首先设计出一系列指标的调查表,向若干专家咨询和征求对指标的意见,然后进行统计处理,并反馈意见处理结果,经过几轮咨询后,当专家意见趋于集中时,将专家意见集中的指标作为评价指标,从而建立起综合评价指标体系。
缺点:在实际中,该方法较难实现。首先,数学建模比赛赛程紧迫;其次,向专家咨询和征求意见难度高。
2)最小均方差法
对于n个评价对象
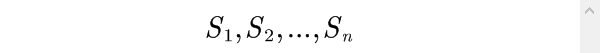
每个评价对象有m个指标,其观测值分别为
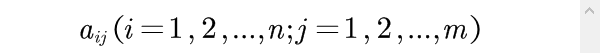
如果n个评价对象对于某项指标的观测值都差不多,那么不管这个评价指标重要与否,对于评价对象的评价结果所起的作用将是很小的。因此在评价过程中就可以删除这样的评价指标,即建立评价指标体系一般原则中的5)可比性。
最小均方差法的筛选过程如下:
(1)求出第j项指标的平均值和均方差
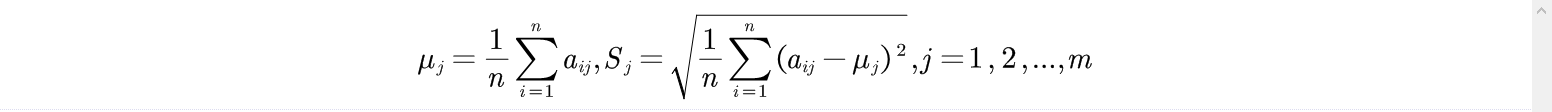
(2)求出最小均方差
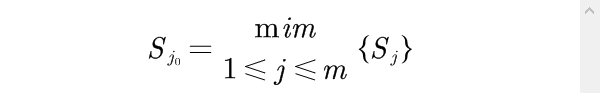
(3)如果最小均方差
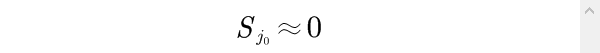
则可删除对应的指标,考察完所有评价指标,即可得到最终的评价指标体系。
缺点:最小均方差法只考虑了指标的差异程度,容易将重要的指标删除。
3)极大极小离差法
对于n个评价对象
每个评价对象有m个指标,其观测值分别为
极大极小离差法的筛选过程如下:
(1)求出第j项指标的最大离差
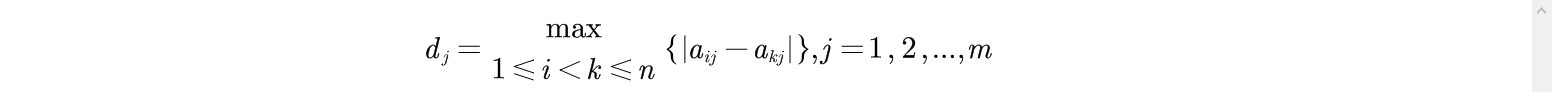
(2)求出最小离差
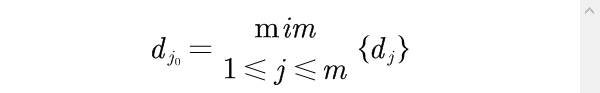
(3)如果最小离差约等于0,则可删除对应的指标,考察完所有指标,即可得到最终的评价指标体系。
常用的评价指标筛选方法还有条件广义方差极小法、极大不相关法等。
4)小结
数学建模比赛中,赛题附件所给的数据指标一般满足建立评价指标体系的一般原则,故一般无需进行评价指标的筛选。评价指标的筛选可用于模型的灵敏度分析。
三、评价指标的预处理方法
一般情况下,在综合评价指标中,各指标值可能属于不同类型、不同单位或不同数量级,从而使得各指标之间存在着不可公度性,给综合评价带来了诸多不便。为了尽可能地反映实际情况,消除由于各项指标间的这些差别带来的影响,避免出现不合理的评价结果,就需要对评价指标进行一定的预处理,包括对指标的一致化处理和无量纲化处理。
1.指标的一致化处理
所谓一致化处理就是将评价指标的类型进行统一。若指标体系中存在不同类型的指标,必须在综合评价之前将评价指标的类型做一致化处理。例如,将各类指标都转化为极大型指标或极小型指标。一般的做法是将非极大型指标转化为极大型指标,即指标正向化。但是,在不同的指标权重确定方法和评价模型中,指标一致化处理也有差异。
1)极小型指标化为极大型指标
对极小型指标将其转化为极大型指标时,只需对指标取倒数
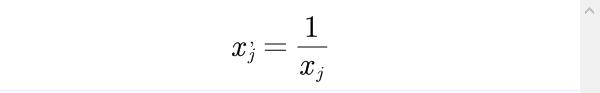
或做平移变换
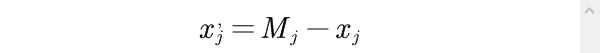
其中
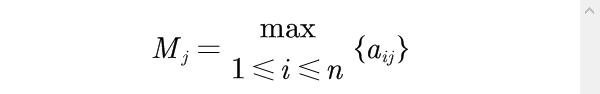
即n个评价对象第j项指标值
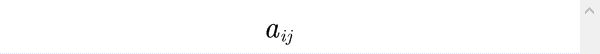
最大者。
在Python中的实现
data_array[:, j] = np.subtract(1, data_array[:, j]) # 对指标取倒数
data_array[:, j] = np.subtract(np.max(data_array[:, j]), data_array[:, j]) # 对指标做平移变换
2)中间型指标化为极大型指标
对中间型指标
令
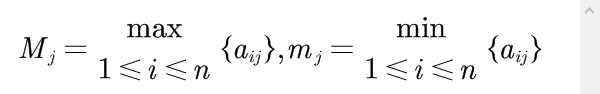
取
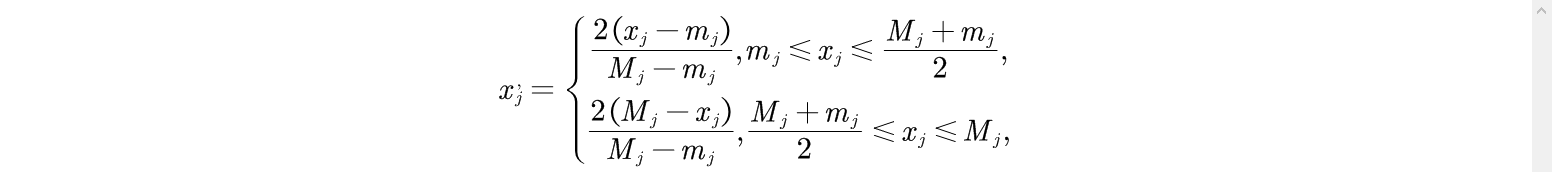
就可以将
转化为极大型指标。
对中间型指标
取某特定值最好。令最佳的数值为
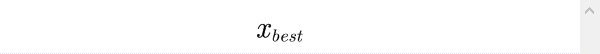
令
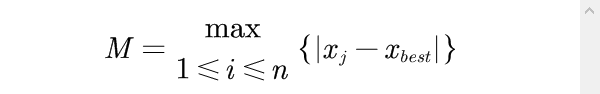
取
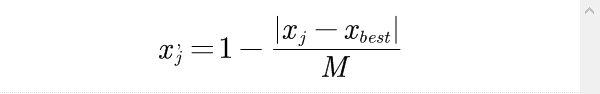
就可以将
转化为极大型指标。
在Python中的实现
answer_one = int(input("有最佳值吗?有请输入1,没有请输入0。"))
if answer_one: # 有最佳值
xbest = int(input("请输入最佳值。"))
M = np.max(np.abs(np.subtract(data_array[:, j], xbest)))
data_array[:, j] = np.subtract(1, np.divide(np.abs(np.subtract(data_array[:, j], xbest)), M))
else: # 无最佳值
Mj = np.max(data_array[:, j])
mj = np.min(data_array[:, j])
for i in range(row_len):
if data_array[i, j] <= (Mj + mj) / 2:
data_array[i, j] = np.divide(np.multiply(2, np.subtract(data_array[i, j], mj)), np.subtract(Mj, mj))
else:
data_array[i, j] = np.divide(np.multiply(2, np.subtract(Mj, data_array[i, j])), np.subtract(Mj, mj))
3)区间型指标化为极大型指标
对区间型指标
取值属于
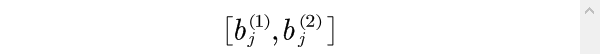
时为最好,指标值离该区间越远就越差。令
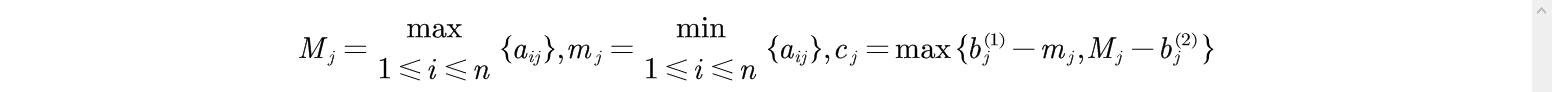
取
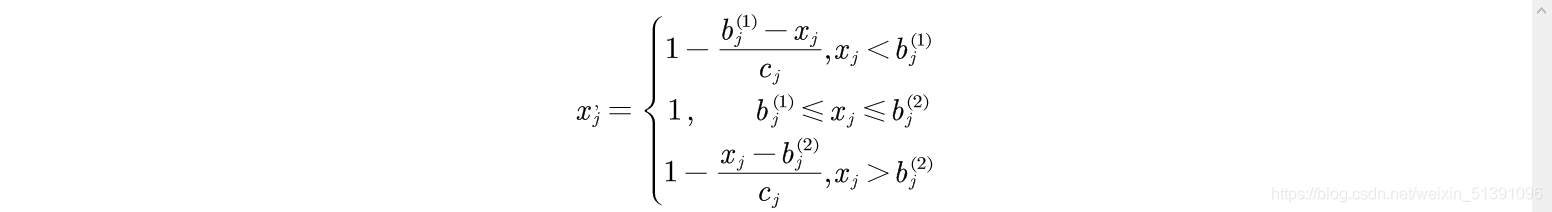
就可以将区间型指标
转化为极大性指标。
在Python中的实现
Mj = np.max(data_array[:, j])
mj = np.min(data_array[:, j])
bj1 = int(input("请输入区间的下界。"))
bj2 = int(input("请输入区间的上界。"))
cj = max(np.subtract(bj1, mj), np.subtract(Mj, bj2))
for i in range(n):
if data_array[i, j] < bj1:
data_array[i, j] = np.subtract(1, np.divide(np.subtract(bj1, data_array[i, j]), cj))
elif bj1 <= data_array[i, j] <= bj2:
data_array[i, j] = 1
else:
data_array[i, j] = np.subtract(1, np.divide(np.subtract(data_array[i, j], bj2), cj))
总结
以上就是今天介绍的内容。本文仅仅简单介绍了综合评价方法的基本理论和数据预处理的一部分,请继续关注接下来的文章,并且指正本文存在的问题,谢谢大家!
参考文献
[1] 司守奎, 孙玺菁. Python数学实验与建模. 北京:科学出版社, 2020.
[2] 姜启源, 谢金星, 叶俊. 数学模型, 5版. 北京:高等出版社, 2018.















 445
445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









