










1、整合springboot
创建一个springboot项目
导入es的依赖
<!--springboot-data-es-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
<version>2.7.0</version>
</dependency>
连接es
@Configuration
public class RestClientConfig extends AbstractElasticsearchConfiguration {
@Override
@Bean
public RestHighLevelClient elasticsearchClient() {
final ClientConfiguration clientConfiguration = ClientConfiguration.builder()
.connectedTo("localhost:9200")
.build();
return RestClients.create(clientConfiguration).rest();
}
}
- 特点:
索引:用来存放相似文档集合
映射:用来决定放入文档的每个字段以什么样的方式录入es中字段类型
文档:可以被索引的最小单元 json数据格式
2、相关注解
进行实体类创建
//将这个类对象转为es中一条文档进行录入
@Data
@Document(indexName = "products", createIndex = true)
public class Product {
@Id //用来将放入对象的id值 作为文档_id 进行映射
private Integer id;
@Field(type = FieldType.Keyword)
private String title;
@Field(type = FieldType.Double)
private Double price;
@Field(type = FieldType.Text,analyzer = "ik_max_word")
private String description;
}
创建索引
@SpringBootTest
public class ESOptionsTests {
private ElasticsearchOperations elasticsearchOperations;
public ESOptionsTests(ElasticsearchOperations elasticsearchOperations) {
this.elasticsearchOperations = elasticsearchOperations;
}
/*
* 方法描述
* @param: 索引一条文档
* @return:
* @author: lijinyu
* @date: 2022/6/20
*/
@Test
public void testIndex(){
Product product = new Product();
product.setId(1);
product.setTitle("小浣熊干吃面");
product.setPrice(1.5);
product.setTitle("小浣熊干吃面真好吃,曾经非常爱吃");
elasticsearchOperations.save(product);
}
}
一系列操作:
//查询
@Test
public void testSearch(){
Product product = elasticsearchOperations.get("1", Product.class);
System.out.println(product.getId()+product.getPrice()+product.getDescription());
}
//删除
public void testDelete(){
Product product = new Product();
product.setId(1);
String delete = elasticsearchOperations.delete(product);
}
public void testDeleteAll(){
elasticsearchOperations.delete(Query.findAll(),Product.class);
}
//查询所有
public void testFindAll() throws JsonProcessingException {
SearchHits<Product> search = elasticsearchOperations.search(Query.findAll(), Product.class);
System.out.println("总分数:"+search.getMaxScore());
System.out.println("符合条件总分"+search.getTotalHits());
for (SearchHit<Product> productSearchHit : search) {
System.out.println(new ObjectMapper().writeValueAsString(productSearchHit.getContent()));
}
}
3、RestHighLevelClient 推荐
3.1、创建索引与映射
public class RestHighLevClientTests extends SpringBootDataEsDemoApplicationTests {
private final RestHighLevelClient restHighLevelClient;
public RestHighLevClientTests(RestHighLevelClient restHighLevelClient) {
this.restHighLevelClient = restHighLevelClient;
}
/*
* 方法描述
* @param: 创建索引
* @return:
* @author: lijinyu
* @date: 2022/6/20
*/
public void testIndexAndMapping() throws IOException {
//参数:1、创建索引请求对象, 参数2:请求配置对象
CreateIndexRequest createIndexRequest = new CreateIndexRequest("products");
createIndexRequest.mapping("{\n" +
" \"properties\": {\n" +
" \"id\": {\n" +
" \"type\": \"integer\"\n" +
" },\n" +
" \"title\":{\n" +
" \"type\": \"keyword\"\n" +
" },\n" +
" \"price\": {\n" +
" \"type\": \"double\"\n" +
" },\n" +
" \"created_at\":{\n" +
" \"type\": \"date\"\n" +
" },\n" +
" \"description\":{\n" +
" \"type\": \"text\",\n" +
" \"analyzer\": \"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }", XContentType.JSON)//指定映射 参数1:指定映射结构json 参数2:指定数据类型
CreateIndexResponse createIndexResponse = restHighLevelClient.indices().create(createIndexRequest, RequestOptions.DEFAULT);
System.out.println("创建状态:"+createIndexResponse.isAcknowledged());
restHighLevelClient.close();
}
}
3.2、删除索引
//删除索引
public void testDeleteIndex(){
AcknowledgedResponse products = restHighLevelClient.indices().delete(new DeleteIndexRequest("products"), RequestOptions.DEFAULT);
System.out.println(AcknowledgedResponse.isAcknowledged());
}
3.3、插入一条索引
//索引一条文档
public void testCreate(){
IndexRequest indexRequest = new IndexRequest("product");
indexRequest.id("2").source(" {\"id\":3,\"title\":\"日本豆\",\"price\":1.5,\"created_at\":\"2021-11-17\",\"description\":\"不错\"",XContentType.JSON);
//1、索引的请求对象, 2、请求配置对象
restHighLevelClient.index(indexRequest,RequestOptions.DEFAULT);
System.out.println(IndexResponse.status());
}
3.4、更新文档
//更新文档
public void testUpdate(){
UpdateRequest products = new UpdateRequest("products", "1");
products.doc("{\"price\":1.22}",XContentType.JSON);
UpdateResponse update = restHighLevelClient.update(UpdateRequest, RequestOptions.DEFAULT);
System.out.println(update.status());
}
```
## 删除文档
```java
//删除文档
public void testDelete(){
DeleteResponse delete = restHighLevelClient.delete(new DeleteRequest("products", "xxxx"), RequestOptions.DEFAULT);
System.out.println(delete.status());
}
}
3.4、查询所有
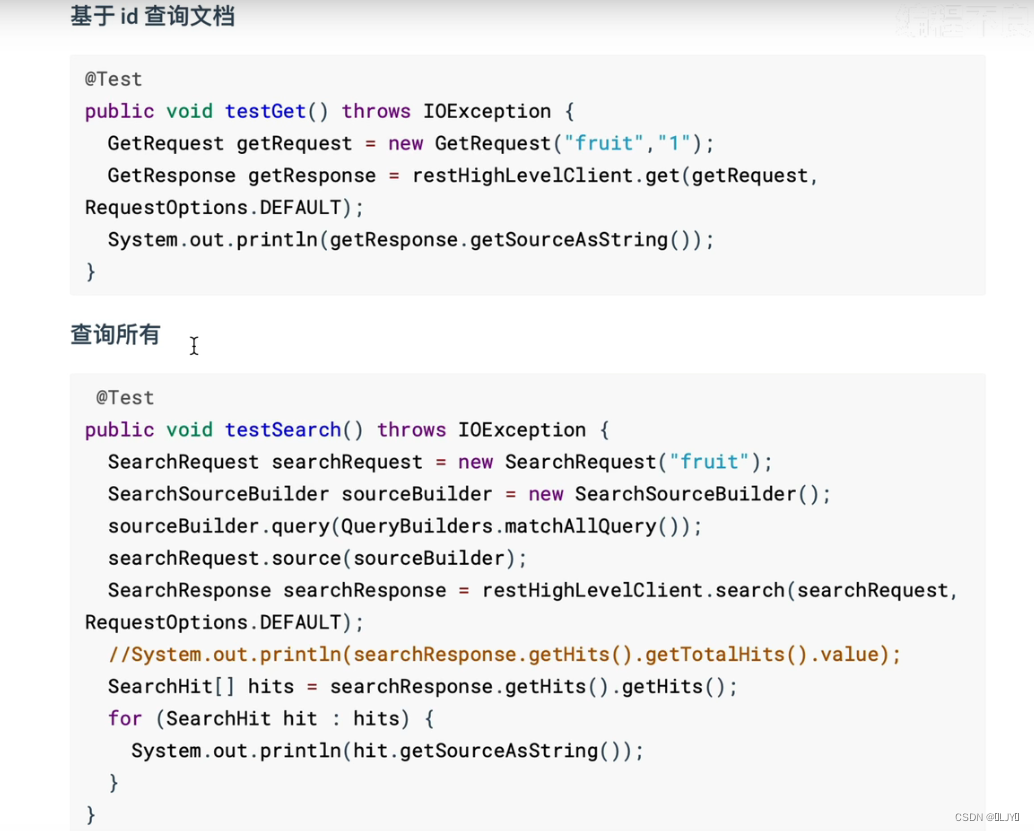
public void testMatchAll() throws IOException {
SearchRequest searchRequest = new SearchRequest("products"); //指定搜索索引
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //指定条件对象
searchSourceBuilder.query(QueryBuilders.matchAllQuery()); //查询所有
searchRequest.source(searchSourceBuilder); //指定查询条件
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT); //参数1:搜索请求对象 参数2 请求配置对象。
//总条数的获取
System.out.println("总条数:" + search.getHits().getTotalHits().value);
System.out.println("最大得分:" + search.getHits().getMaxScore());
// 获取结果
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
String id = hit.getId();
String sourceAsString = hit.getSourceAsString();
System.out.println("id:" + id + "值" + sourceAsString);
}
}
3.5、根据具体内容查询
/**
* 不同条件的查询 term(关键词)
*
* @return {@link }
* date
*/
public void testQuery() throws IOException {
SearchRequest products = new SearchRequest("products");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(QueryBuilders.termQuery("description", "浣熊"))
products.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(products, RequestOptions.DEFAULT);
System.out.println("符合条件总数:" + search.getHits().getTotalHits().value);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("值:" + hit.getSourceAsString());
}
}
3.6、封装成方法
//封装
public void query(QueryBuilder queryBuilders) throws IOException {
SearchRequest products = new SearchRequest("products");
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
sourceBuilder.query(queryBuilders);
products.source(sourceBuilder);
SearchResponse search = restHighLevelClient.search(products, RequestOptions.DEFAULT);
System.out.println("符合条件总数:" + search.getHits().getTotalHits().value);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("值:" + hit.getSourceAsString());
}
}
测试
public void test11() throws IOException {
query(QueryBuilders.termQuery("descrition", "浣熊"));
query(QueryBuilders.rangeQuery("price").gt(0).lte(1.33));
//prefix 前缀
query(QueryBuilders.prefixQuery("title", "小"));
//通配符 wildcard ? 代表一个字符 *代表多个字符
query(QueryBuilders.wildcardQuery("title", "小浣熊*"));
query(QueryBuilders.idsQuery().addIds("1").addIds("2"));
//多字段查询啊 multi_match
query(QueryBuilders.multiMatchQuery("非常").field("title").field("name"));
query(QueryBuilders.multiMatchQuery("非常", "title", "name")); //同等与上面代码
}
3.7 分页处理
/**
* 方法描述:分页查询 from 起始位置 size 页面大小
* + 排序
* +返回指定字段
* +高亮查询
*
* @param:
* @author: lijinyu
* @date: 2022/7/1
*/
public void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.requireFieldMatch(false).field("title").field("name").preTags("<span style ='color:red'").postTags("</span>");
searchSourceBuilder.query(QueryBuilders.matchAllQuery())
.from(0)
.size(1)
.sort("price", SortOrder.DESC)//根据哪个字段排序,排序方式
.fetchSource(new String[]{"title"}, new String[]{}) //参数1 包含字段数组, 参数2:排除字段数组
.highlighter(highlightBuilder);
searchRequest.source(searchSourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("符合条件总数:" + search.getHits().getTotalHits().value);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("值:" + hit.getSourceAsString());
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
if (highlightFields.containsKey("title")) {
System.out.println("高亮结果" + highlightFields.get("title").fragments()[0]);
}
if (highlightFields.containsKey("name")) {
System.out.println("高亮结果" + highlightFields.get("name").fragments()[0]);
}
}
}
3.8、过滤查询
/**
* 方法描述:过滤查询
* query 精确查询
* filter query : 过滤查询 在大量数据中去进行筛选 筛选出本次查询相关的数据
* 注意:一旦使用了filter query 和query es会先执行filter query
*
* @param:
* @author: lijinyu
* @date: 2022/7/1
*/
public void testFilterQuery() throws IOException {
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder
.query(QueryBuilders.matchAllQuery())
.postFilter(QueryBuilders.termQuery("descriotion", "好吃")); //指定过滤条件
searchRequest.source(searchSourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println("符合条件总数:" + search.getHits().getTotalHits().value);
SearchHit[] hits = search.getHits().getHits();
for (SearchHit hit : hits) {
System.out.println("值:" + hit.getSourceAsString());
}
}
4、ES的应用
public class RestHighLevClientForObject extends SpringBootDataEsDemoApplicationTests {
private final RestHighLevelClient restHighLevelClient;
public RestHighLevClientForObject(RestHighLevelClient restHighLevelClient) {
this.restHighLevelClient = restHighLevelClient;
}
public void test() throws IOException {
Product product = new Product();
product.setId(1);
product.setTitle("11");
product.setPrice(11.2);
product.setDescription("jahaj");
// 录入es中
IndexRequest indexRequest = new IndexRequest("products");
indexRequest.id(product.getId().toString())
.source(new ObjectMapper().writeValueAsString(product), XContentType.JSON);
IndexResponse indexResponse = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
}
public void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder
.query(QueryBuilders.matchAllQuery())
.from(0)
.size(2);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(searchResponse.getHits().getTotalHits().value);
System.out.println(searchResponse.getHits().getMaxScore());
SearchHit[] hits = searchResponse.getHits().getHits();
List<Product> productList = new ArrayList<>();
for (SearchHit hit : hits) {
System.out.println(hit.getSourceAsString());
Product product1 = new ObjectMapper().readValue(hit.getSourceAsString(), Product.class);
productList.add(product1);
}
for (Product product : productList) {
System.out.println(product.getId() + product.getPrice() + product.getDescription());
}
}
}
4.1、聚合查询
聚合:英文为Aggregation Aggs,是es除搜索功能外提供的针对es数据做统计分析的功能。聚合有助于根据搜索查询提供聚合数据。聚合查询是数据库中重要的功能特性,ES作为搜索引擎兼数据库,同样提供了强大的聚合分析能力。它基于查询条件来对数据进行分桶、计算的方法。有点类似于SQL中的group by 再加一些函数方法的操作。
注意:text类型不支持聚合。
测试数据:

代码演示:
/**
* 方法描述
*
* @param: 基于term类型 聚合
* @author: lijinyu
* @date: 2022/7/1
*/
void testAggs() {
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.terms("price_group").field("price")) //设置聚合
.size(0);
searchRequest.source(searchSourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
//处理聚合结果
Aggregations aggregations = search.getAggregations();
// ParsedStringTerms price_group = aggregations.get("price_group"); 基于字段进行分组聚合
ParsedDoubleTerms price_group = aggregations.get("price_group");
List<? extends Terms.Bucket> buckets = price_group.getBuckets();
for (Terms.Bucket bucket : buckets) {
System.out.println(bucket.getKey() + " " + bucket.getDocCount());
}
}
/**
* 方法描述
*
* @param: max min sun avg 聚合函数 只有一个返回值
* @author: lijinyu
* @date: 2022/7/4
*/
public void testAggsFunction() {
SearchRequest searchRequest = new SearchRequest("products");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
searchSourceBuilder.aggregation(AggregationBuilders.sum("sum_price").field("price")) //设置聚合
.size(0);
searchRequest.source(searchSourceBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
Aggregations aggregations = search.getAggregations();
ParsedSum aggregation = aggregations.get("sum_price");
//ParsedAvg aggregation = aggregations.get("sum_price");
//ParsedMin aggregation = aggregations.get("sum_price");
System.out.println(aggregation.getValue());
}
5、集群
5.1、相关概念
5.1.1、集群
一个集群就是由一个或多个节点组织在一起,它们共同持有你整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是elasticsearch。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
5.1.2、节点
一个节点是你集群中的一个服务器,作为集群的一部分,它存储你的数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的漫威漫画角色的名字,这个名字会在启动的时候赋予节点。
5.1.3、索引
一组相似文档的集合
5.1.4、映射
用来定义索引存储文档的结构如:字段、类型等。
5.1.5、文档
索引中一条记录,可以被索引的最小单元
5.1.6、分片
Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个索引可以被放置到集群中的任何节点上。
5.2、集群搭建
5.2.1、集群规划
#准备三个es节点, ES9200 9300
- web : 9201 tcp : 9301 node -1 elasticsearch.yml
- web : 9202 tcp : 9302 node -2 elasticsearch.yml
- web : 9203 tcp : 9303 node -3 elasticsearch.yml
- 注意:
所有节点集群名称必须一致cluster.name
每个节点必须有一个唯一名字node.name
开启每个节点远程连接network.host: 0.0.0.0
指定使用IP地址进行集群节点通信network.publish_host:
修改web端口tcp端口http.port: transport.tcp.port
指定集群中所有节点通信列表discovery.seed_hosts: nod e-1 node-2 node-3相同
允许集群初始化 master节点节点数: cluster.initial_master_nodes: [ “node-1”, “node-2”," node-3"]
集群最少几个节点可用gateway.recover_after_nodes: 2
开启每个节点跨域访问http.cors.enabled: true http.cors.allow-origin: “*”
5.2.2、配置文件
# 指定集群名称 3个节点必须一致
cluster.name: es-cluster
#指定节点名称,每个节点唯一
node.name: node-1
#开放远程连接
network.host: 0.0.0.0
#指定使用 发布地址进行集群间通信
network.publish_host: 192.168.137.1
#指定web端口
http.port: 9201
#指定tcp端口
transport.tcp.port: 9301
# 指定所有节点的tcp通信
discovery.seed_hosts: ["192.168.137.1:9301",
"192.168.137.1:9302","192.168.137.1:9303"]
#指定可以初始化集群的节点名称
cluster.initial_master_nodes: ["node-1","node-2","node-3"]
#集群最少几个几点可用
gateway.recover_after_nodes: 2
#解决跨域问题
http.cors.enabled: true
http.cors.allow-origin: "*"















 2453
2453











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









