







RDD理解检测
任务描述
本关任务:根据下面的相关知识,完成与数据认知相关的选择题。
相关知识
RDD介绍
RDD 是Spark的核心抽象,即 弹性分布式数据集(residenta distributed dataset)。代表一个不可变,可分区,里面元素可并行计算的集合。其具有数据流模型的特点:自动容错,位置感知性调度和可伸缩性。 在Spark中,对数据的所有操作不外乎创建RDD、转化已有RDD以及调用 RDD操作进行求值。
RDD结构图
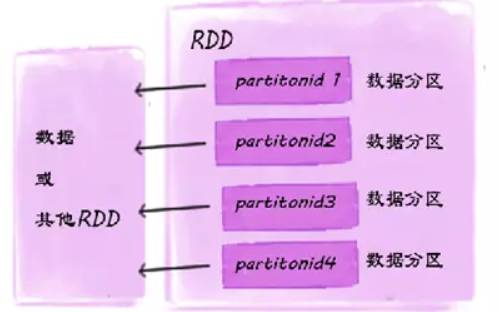
RDD具有五大特性
-
一组分片(
Partition),即数据集的基本组成单位(RDD是由一系列的partition组成的)。将数据加载为RDD时,一般会遵循数据的本地性(一般一个HDFS里的block会加载为一个partition)。 -
RDD之间的依赖关系。依赖还具体分为宽依赖和窄依赖,但并不是所有的RDD都有依赖。为了容错(重算,cache,checkpoint),也就是说在内存中的RDD操作时出错或丢失会进行重算。 -
由一个函数计算每一个分片。
Spark中的RDD的计算是以分片为单位的,每个RDD都会实现compute函数以达到这个目的。compute函数会对迭代器进行复合,不需要保存每次计算的结果。 -
(可选)如果
RDD里面存的数据是key-value形式,则可以传递一个自定义的Partitioner进行重新分区。 -
(可选)
RDD提供一系列最佳的计算位置,即数据的本地性。
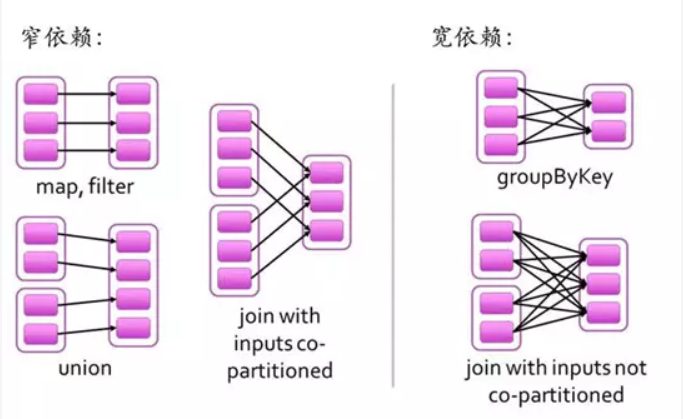
RDD之间的依赖关系
RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖。
窄依赖:父RDD和子RDD partition之间的关系是一对一的。或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的,也可以理解为没有触发shuffle。
宽依赖:父RDD与子RDD partition之间的关系是一对多。 父RDD的一个分区的数据去到子RDD的不同分区里面。也可以理解为触发了shuffle。
特别说明:对于join操作有两种情况,如果join操作的使用每个partition仅仅和已知的Partition进行join,此时的join操作就是窄依赖;其他情况的join操作就是宽依赖。
RDD创建
-
从
Hadoop文件系统(或与Hadoop兼容的其他持久化存储系统,如Hive、Cassandra、HBase)输入(例如HDFS)创建。 -
通过集合进行创建。
算子
算子可以分为Transformation 转换算子和Action 行动算子。 RDD是懒执行的,如果没有行动操作出现,所有的转换操作都不会执行。
-
1、
下面哪个不是 RDD 的特点 ( C)
A、可分区
B、可序列化
C、可修改
D、可持久化 -
2、
关于Spark RDD的弹性,哪项是错误的(D)
A、容错性
B、数据调度弹性
C、内存和磁盘切换
D、固定大小 -
3、
Spark的算子类型(AC)
A、转换算子
B、迭代算子
C、动作算子
D、核心算子















 517
517

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









