







任务描述
本关任务:根据相关知识内容完成右侧选择题。
相关知识
为了完成本关任务,你需要掌握: 1.HDFS 的背景; 2.HDFS 的概述; 3.HDFS 的优缺点; 4.HDFS 的基本架构。
HDFS 的背景
在大数据场景中,每天新增的数据量可能多达 GB 级别,甚至 TB 级,新增文件数据可能多达十万级别,为了应对数据存储扩容问题,存在两种解决方案:纵向扩展(scale-up)和横向扩展(scale-out)。纵向扩展利用现有的存储系统,通过不断增加存储容量来满足数据增长的需求;横向扩展则是以网络互连的节点为单位扩大存储容量(集群)。由于纵向扩展存在价格昂贵、升级困难以及总存在物理瓶颈(理论上,由于物理硬件的制约,单台设备总存在瓶颈)等问题,目前大数据领域通常会采用横向扩展方案。横向扩展的难点在于如何构建一个分布式文件系统,解决以下这些问题。
因故障导致丢失数据:横向扩展集群中采用的节点通常是普通的商用服务器,因机器故障、网络故障、人为事务、软件Bug 等原因导致服务器宕机过服务挂掉是常见的现象,这就要求分布式文件系统能很好地处理各种故障(即良好的容错性)。
文件通常较大:在大数据应用场景中,GB 级别的文件是很常见的,且这样的文件数量较多,这与传统文件系统的使用场景是很不同的,这要求分布式文件系统在 IO 操作以及块大小方面进行重新设计。

一次写入多次读取:一部分文件时通过追加方式(append-only)产生的,且一旦产生之后不会再随机修改,只是读取(且为顺序读取),也就是说,这些文件是不可修改的。在实际应用中,相当一部分文件拥有这种“一次写入多次读取”的特性,包括 OLAP 场景处理的数据、应用程序流式产生的数据、历史归档数据等。针对这种应用场景,文件追加成为重点性能优化和原子性保证的操作。
为了解决以上横向扩展方案中的几个问题,Google 构建了分布式文件系统 GFS(Google File System),并于 2003 年发表论文《The Google File System》介绍了 GFS 的产生背景、架构以及现实等,而 HDFS 正是 GFS 的开源实现。
HDFS 概述
HDFS 是 Hadoop 自带的分布式文件系统,即 Hadoop Distributed File System。HDFS 是一个使用 Java 语言实现的分布式、可横向扩展的文件系统。
HDFS的优点和缺点
HDFS的优点
-
高容错性:数据自动保存多个副本,副本丢失后自动恢复。
-
适合批处理:移动计算而非数据,数据位置暴露给计算机框架。
-
适合大数据处理:GB、TB,甚至PB级数据,百万规模以上的文件数量,10k+节点。
-
可构建在廉价机器上:通过副本提高可靠性,提供了容错和恢复机制。
HDFS的缺点
-
不适合低延时数据访问:寻址时间长,适合读取大文件,低延迟与高吞吐率。
-
不适合小文件存取:占用NameNode大量内存,寻找时间超过读取时间。
-
并发写入、文件随机修改:一个文件只能有一个写入者,仅支持append(日志),不允许修改文件。
HDFS 的基本架构
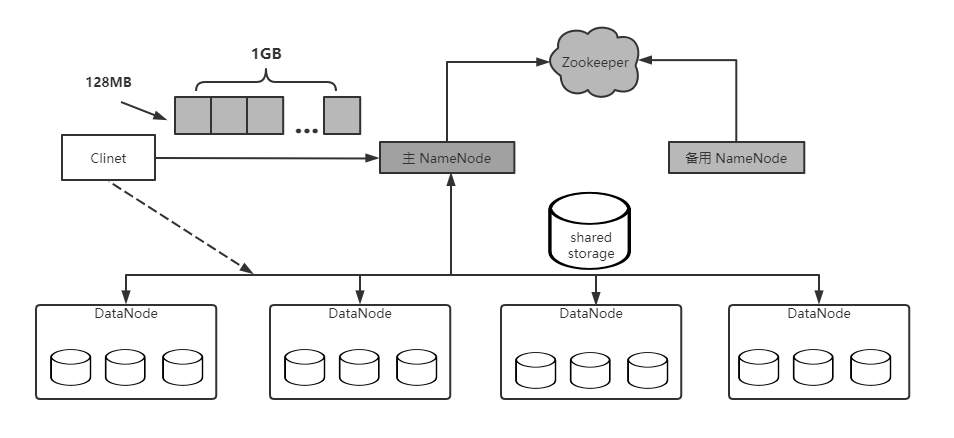
HDFS 采用主从架构,主节点被称为 NameNode ,只有一个,管理元信息和所有从节点,从节点称为DataNode,通常存在多个,存储实际的数据块,HDFS 各组件功能如下所示:
HDFS 基本架构
1.NameNode
NameNode 是 HDFS 集群管理者,负责管理文件系统元信息和所有 DataNode。
- 管理元信息:NameNode 维护着整个文件系统的目录数,各个文件的数据块信息等。
- 管理 DataNode : DataNode 周期性向 NameNode 汇报心跳以表明自己活着,一旦 NameNode 发现某个 DataNode 出现故障,会在其他存活 DataNode 上重构丢失的数据块。
一个HDFS 集群中只存在一个对外服务的 NameNode,称为 Active NameNode,为了防止单个 NameNode 出现故障后导致整个集群不可用,用户可启动一个备用 NameNode,称为 Standby NameNode,为了实现 NameNode HA(High Availability,高可用),需解决好两者的切换和状态同步问题。 主/备切换:HDFS 提供了手动方式和自动方式完成主备 NameNode 切换,手动方式是通过命令显示修改 NameNode 角色完成的,通常用于 NameNode 滚动升级;自动模式是通过 Zookeeper 实现的,可在主 NameNode 不可用的,自动将备用 NameNode 提升为主 NameNode,以保证 HDFS 不间断对外提供服务。 状态同步:主/备 NameNode 并不是通过强一致协议保证状态一致的,而是通过第三方的共享存储系统,备用 NameNode 则从共享存储系统中读取这些修改日志,并重新执行这些操作,以保证与主 NameNode 的内存信息一致。目前 HDFS 支持两种共享存储系统:NFS(Network File System)和 QJM(Quorum Journal Manager),其中 QJM 是 HDFS 内置的高可用日志存取系统,其基本原理是用 2N+1 台 JournalNode 存储 EditLog,每次写数据操作大多数(≥N+1 )返回成功确认即认为该次写成功,该算法所能容忍的是最多有 N 台机器挂掉,如果多于 N 台挂掉,这个算法就失效。QJM 能够建在普通商用机器之上,比 NFS 更加廉价,因此受众更广。
DataNode
DataNode 存储实际的数据块,并周期性通过心跳向 NameNode 汇报自己的状态信息。
Client
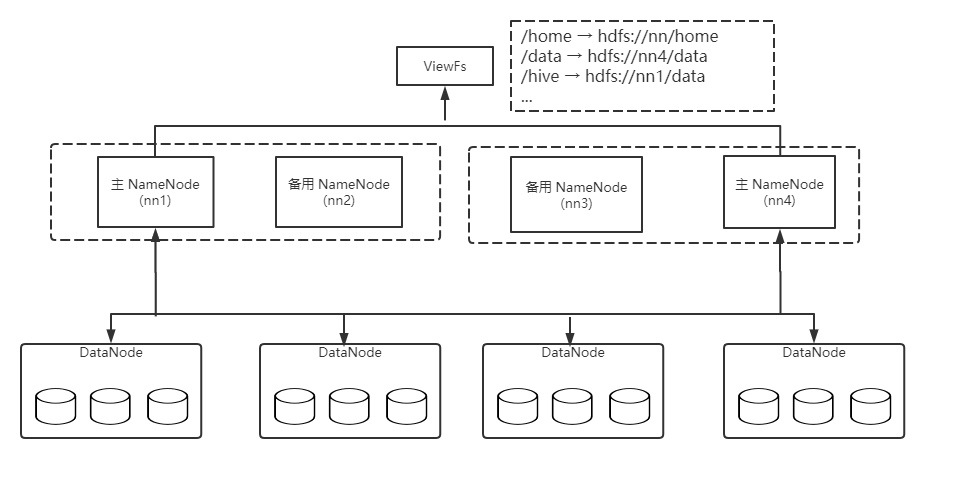
用户通过客户端与 NameNode 和 DataNode 交互,完成 HDFS 管理(比如服务启动与停止)和数据读写等操作。此外,文件的分块操作也是在客户端完成的。当向 HDFS 写入文件时,客户端首先将文件分成等大的数据块(默认一个数据块大小为 128 M),之后从 NameNode 上领取三个 DataNode 地址,并在它们之间建立数据流水线,进而将数据块流式写入这些节点。 随着数据块和访问量的增加,单个 NameNode 会成为制约 HDFS 扩展性的瓶颈,为了解决该问题,HDFS 提供了 NameNode Federation 机制,允许一个集群中存在多个对外服务的 NameNode,它们各自管理目录树的一部分(对目录水平分片),如下图:
启用 NameNode Federation 的 HDFS 架构
-
1、以下哪个是 HDFS 的缺点(C)
A、适合批处理
B、适合大数据处理
C、并发写入、文件随机修改
D、高容错性 -
2、HDFS 采用主从架构,主节点被称为 NameNode ,只有一个,管理元信息和所有从节点,从节点称为 DataNode,通常存在多个,存储实际的数据块。以上说法是否正确(A)
A、正确
B、错误 -
3、对于 HDFS 的说法正确的是:(ABCD)
A、HDFS 可以解决文件较大的存储问题
B、HDFS 能够一次写入多次读取
C、HDFS 是一个可横向扩展的文件系统
D、HDFS 可以防止因故障导致丢失数据















 1994
1994











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









