







前言:
闲来无聊,把《Pyhton3网络爬虫开发实战(第二版)》看完了Js逆向部分。
最后的实战部分感觉挺有挑战性的,正好崔佬也有详细的教程。
平时的逆向都是野路子,刚好快回学校了有时间。
那为什么不自己动手下呢?下面记录下过程,只会更加详细。
观察页面:
废话不多说,直接上靶场:https://spa6.scrape.center
我们的目标是:1.拿到列表页的请求Ajax的Token加密 2. 详情页的Id加密与Token

查看网页源码可以看到:很强烈的Vue打包出来的样子,即使用的使用SPA页面

观察Js也会发现,代码压缩,变量名字十六进制转换。

好了我们将任务进行拆分,先拿到列表页面的加密规则,即去请求列表的token怎么搞到的
获取列表页面:
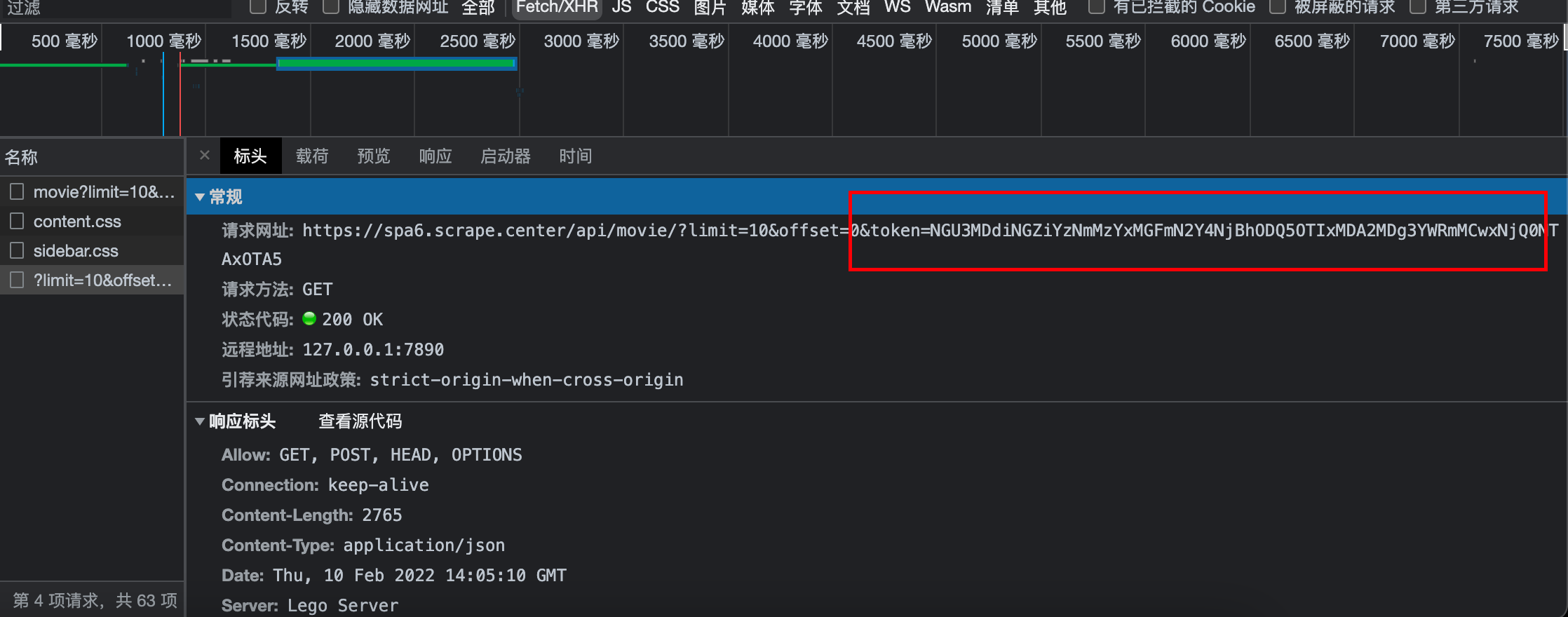
使用Ajax断点,直接拿到即将提交请求那个地方,然后使用堆栈,一点点往回找,这是基本思路
根据上面可以看到请求路径是:/api/movie/?limit=10&offset=0&token=... 打上断点刷新页面


开始针对堆栈往回找:发现axios的get方法:参数都是跟上面请求的十分符合。
到这里我们可以看到_0x263439 = Object(_0x2fa7bd['a'])(this['$store']['state']['url']['index']);这个应该就是token

因为找到具体的了,取消xhr断电在169行打上断点。把鼠标移在上面可以发现
/api/movie作为参数传入进去,前面是个函数,同样把鼠标移上去也可以看到

然后我们使用Watch监视看看对应的_0x2fa7bd:去找下面的函数


格式化后的对应的函数就是把参数传入进来生成Token的逻辑函数了:

单步调试:去看逻辑


*最后的逻辑就是:
传入地址这里是:/api/movie与时间戳用逗号拼接后,使用SHA1进行加密后,再与时间戳拼接,再用Base64编码一次就是Token
这句话有点长,谅解下QAQ,到这里就可以用Python模拟了
当然也可以使用自带的重写功能:方便看其中的某些变量
步骤是:
- 创建一个保存的文件夹
- 被格式化的文件是不能修改的但是可以复制出来
- 在编辑器里面修改好了然后在原文件里面全选然后替换
- 下次刷新会自动替换

获取详情页加密
正如最开始的时候会发现:跳转到详情页面的链接已经加密好了,而不是在请求时候进行加密:

看到请求的链接的Token的话:应该是跟着请求加密生成的。
所以可以看出来我们现在要拿到/detail/xxx是怎么来的以及Token怎么出现的。
同时可以盲猜一波Token的加密方式应该是一样的,即只是换了上面的参数。
现在我们开始分析:确定是在完成请求列表页后经过Js加密已经形成的

这样打断点即加载好了开始调试。但是这里有个问题就是接下来不知道要走多久
这个地方就是学到新东西的地方:因为token的样子应该是最后Base64编码过,而在前端Base64的库就那么几个
通常是btao或者是crypto-js等,则可以使用🪝钩子来截取到
这个意思就是func = object[attr]先拿到,然后重写之后,调用回去执行
(function(){
'use strict'
function hook(object ,attr){
var func = object[attr]
object[attr] = function(){
console.log("hooked", object, attr, arguments)
var ret = func.apply(object, arguments)
debugger
console.log("res", ret)
return ret
}
}
hook(window, 'btoa')
})()
注入方式可以是:1. 控制台 2. 重写Js 3. 油猴脚本
因为打了断点,我们在控制台重写btoa方法,这样到了方法执行的时候就会到我们写入的里面去验证
这里有几个注意点:
- 控制台输入后 可以调用
btoa('1')进入临时文件中的debugger - 因为是
SPA页面所以直接请求第二页可以触发写入的btoa,刷新则不行!

点击第二页,加密规则都是一样的。直接触发(这里我是第二页去点第一页)

往下找了一层发现已经出来了则继续往下找

发现了拼凑:一串不知道是啥的+一个啥

同时发现:_0x11a046是写死的

拼凑的那个数字继续往下找:发现就是拿到结果的ID

到这里详情页加密已经出来了。现在验证下token怎么来的,好的方式一模一样

总结
- 做Js逆向基础要懂要会
- 心要大,要敢猜,不然真的一下子跟正确答案擦肩而过
- 同时心要细,不同的写法同一种效果,不要放过觉得不可能的地方
- Python实现的方式很多,自己多捣鼓下















 2683
2683











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









