







文章目录
前言
上回书说道data-web单机部署,这次聊一下集群部署
提示:以下是本篇文章正文内容,下面案例可供参考
一、安装环境准备(每台服务器环境同样部署)
由于上一篇cdh01服务器已安装完毕,这里只部署cdh02 cdh03,以部署cdh02为例,cdh03同理。
集群部署服务器角色分配:
datax-admin:cdh01
datax-executor:cdh01 cdh03 cdh03
二、DataX 安装(每台服务器同样安装部署)
由于上一篇cdh01服务器已安装完毕,这里只部署cdh02 cdh03
参考上一篇:
:https://blog.csdn.net/weixin_51485976/article/details/122062993
三、DataX-WEB 安装部署
由于上一篇cdh01服务器已安装完毕,这里只部署cdh02 cdh03
1.IDEA编译打包(由于集群为CDH5.13.0,为了版本适配自己编译打包)
下载链接:https://pan.baidu.com/s/13a8nIpz6FL8y4fdE94trjQ
提取码:data
备注:官方提供的版本tar版本包
https://pan.baidu.com/s/13yoqhGpD00I82K4lOYtQhg 提取码:cpsk
2.解压安装包
在选定的安装目录,解压安装包
[root@cdh02 soft]# tar -zxvf datax-web-2.1.2.tar.gz -C /data/
3.执行一键安装脚本
如果cdh02或者cdh03服务器没有mysql客户端,建议安装mysql客户端,便于下面安装。
进入解压后的目录,找到bin目录下面的install.sh文件,如果选择交互式的安装,则直接执行
[root@cdh02 bin]# ./install.sh
然后按照提示操作即可。包含了数据库初始化,如果你的服务上安装有mysql命令,在执行安装脚本的过程中则会出现以下提醒:
Scan out mysql command, so begin to initalize the database
Do you want to initalize database with sql: [{INSTALL_PATH}/bin/db/datax-web.sql]? (Y/N)y
Please input the db host(default: 127.0.0.1):
Please input the db port(default: 3306):
Please input the db username(default: root):
Please input the db password(default: ):
host输入cdh01的IP,
port username password 依次输入。
3.其他配置
3.1邮件服务
在项目目录:/data/datax-web-2.1.2/modules/datax-admin/bin/env.properties 配置邮件服务(可跳过)
MAIL_USERNAME=""
MAIL_PASSWORD=""
此文件中包括一些默认配置参数,例如:server.port,具体请查看文件。
3.2指定PYTHON_PATH的路径
vim /data/datax-web-2.1.2/modules/datax-executor/bin/env.properties
### 执行datax的python脚本地址
PYTHON_PATH=/data/datax/bin/datax.py
### 保持和datax-admin服务的端口一致;默认是9527,如果没改datax-admin的端口,可以忽略
DATAX_ADMIN_PORT=
此文件中包括一些默认配置参数,例如:executor.port,json.path,data.path等,具体请查看文件。
3.3datax-executor配置文件
/data/datax-web-2.1.2/modules/datax-executor/conf/application.yml
建议将application.yml文件中的cdh01改成cdh01的IP
vim /data/datax-web-2.1.2/modules/datax-executor/conf/application.yml
addresses: http://cdh01的ip:${datax.admin.port}
ip: cdh02的ip
4.启动服务
启动datax-executor服务即可
[root@cdh02 datax-web-2.1.2]# cd /data/datax-web-2.1.2
[root@cdh02 datax-web-2.1.2]# ./bin/start.sh -m datax-executor
5.查看服务
在Linux环境下使用JPS命令,查看是否出现DataXExecutorApplication进程,如果存在这表示项目运行成功。
如果项目启动失败,请检查启动日志:
modules/datax-admin/bin/console.out
或者
modules/datax-executor/bin/console.out
ips: 脚本使用的都是bash指令集,如若使用sh调用脚本,可能会有未知的错误
四、DataX-WEB 添加执行器
参考:https://blog.csdn.net/weixin_51485976/article/details/122062993

可以把每台服务器作为一个执行器,也可以将所有服务器作为一个执行器组,便于容错任务。

五、datax配置hadoop HA(高可用)
方法一:将原来的"defaultFS":“hdfs://xxxx:8020”,替换成下面的,解决高可用问题
"defaultFS":"hdfs://nameservice1",
"hadoopConfig":{
"dfs.nameservices":"nameservice1",
"dfs.ha.namenodes.nameservice1":"nn01,nn02",
"dfs.namenode.rpc-address.nameservice1.nn01":"hdfs://xxxx:8020",
"dfs.namenode.rpc-address.nameservice1.nn02":"hdfs://xxxx:8020",
"dfs.client.failover.proxy.provider.nameservice1": "org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider",
"dfs.ha.automatic-failover.enabled.yournamespace":"true"
},
方法二:将hdfs-site.xml,core-site.xml,hive-site.xml放到datax/plugin/reader/hdfsreader/hdfsreader-0.0.1-SNAPSHOT.jar包中。
用压缩工具打开hdfsreader-0.0.1-SNAPSHOT.jar(如好压工具打开,非解压),将上面三个文件直接拖入即可。如果是拷贝hdfsreader-0.0.1-SNAPSHOT.jar到其他路径下操作的,将操作完的jar包替换掉原来datax对应hdfsreader路径下的hdfsreader-0.0.1-SNAPSHOT.jar
六、datax-web数据源配置
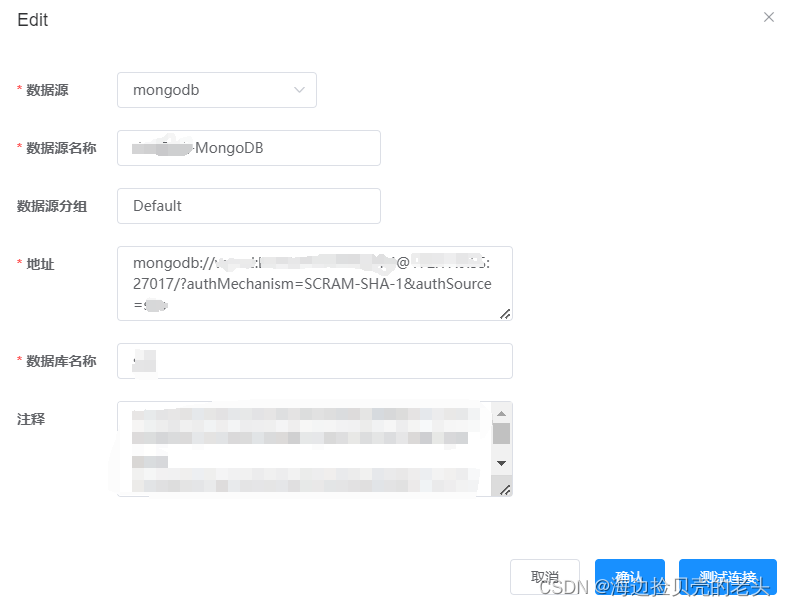
1.配置mongodb数据源
mongodb://用户名:密码@ip:端口号/?authMechanism=SCRAM-SHA-1&authSource=库名
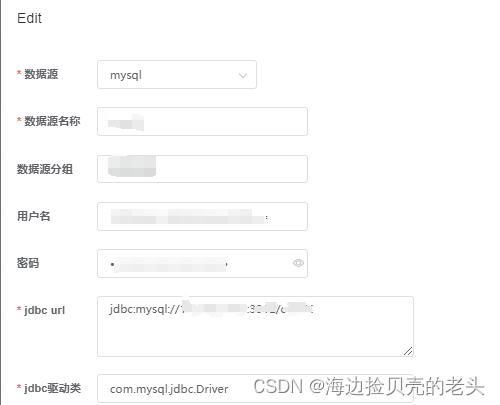
2.配置mysql数据源
jdbc:mysql://ip:端口号/库名
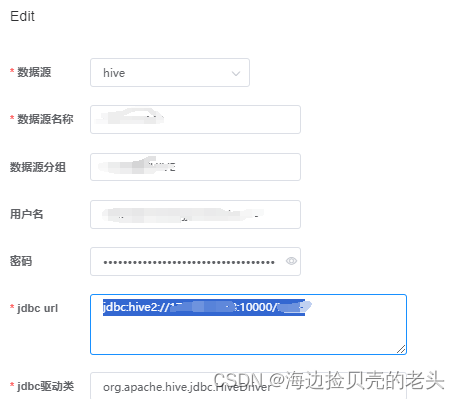
3.配置hive数据源
jdbc:hive2://ip:10000/库名
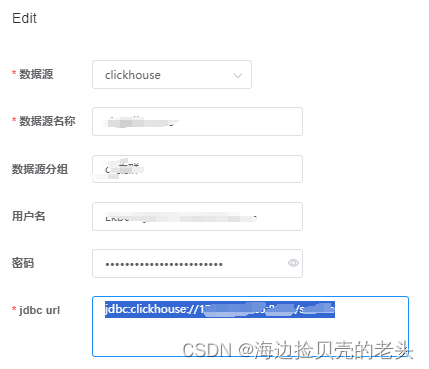
4.配置clickhouse数据源
jdbc:clickhouse://ip:端口号/库名
综上 欢迎大家在评论区留言,知识共享!!!
参考网址
data-web一键部署
链接:https://gitee.com/WeiYe-Jing/datax-web#linux%E4%B8%80%E9%94%AE%E9%83%A8%E7%BD%B2
链接:https://github.com/WeiYe-Jing/datax-web
如需其他CDH版本datax-web下载,评论区留言,或者关注,给您私发链接
dataX阿里开源
链接:https://github.com/alibaba/DataX
MYSQL 5.7安装
链接:https://blog.csdn.net/weixin_51485976/article/details/110529351
DataX介绍以及优缺点分析
链接:https://zhuanlan.zhihu.com/p/81817787
DATAX踩坑路
链接:https://www.icode9.com/content-4-1085267.html
链接:https://blog.csdn.net/weixin_39939661/article/details/110659224?spm=1001.2101.3001.6650.9&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-9.essearch_pc_relevant&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7EBlogCommendFromBaidu%7Edefault-9.essearch_pc_relevant
DataX在有赞大数据平台的实践
链接:https://blog.csdn.net/weixin_33778544/article/details/91379471
其他流行开源ETL工具
链接:https://github.com/DTStack/flinkx
链接:https://nightlies.apache.org/flink/flink-docs-release-1.14/zh/docs/dev/table/sqlclient/
链接:https://ververica.github.io/flink-cdc-connectors/master/
链接:http://streamxhub.com/zh/
————————————————
版权声明:本文为CSDN博主「海边捡贝壳的老头」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_51485976/article/details/122062993
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 2145
2145











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









