







根据损失函数与优化方法可知,线性回归模型的目的很明确:预测值尽可能地接近真实值,即预测值与真实值之间的误差尽可能的小 ,我们可以在训练好的模型上计算测试数据的误差来直观的了解这个模型的“好坏”
那么用什么来定义这个“误差”呢?
通常,有以下几种方式:
① Mean Absolute Error MAE平均绝对误差
② Mean Squared Error MSE均方误差
③ Root Mean Square Error RMSE均方根误差
④ R^2 决定系数
一、 Mean Absolute Error MAE平均绝对误差
MAE用来衡量预测值与真实值之间的平均绝对误差,它表达的是平均每个样本预测值与真实值的距离(差距),它的定义是
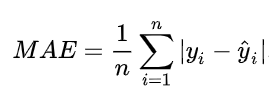
MAE 具有和y一样的量纲,可以更好的反应地反映预测值误差的实际情况
误差嘛,当然也是越小越好啦。
例子 1 波斯顿房价预测
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression as LR # 性线回归函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE # 均方误差
from sklearn.datasets import load_boston as bs
housevalue = bs() # 获取数据集
X = pd.DataFrame(housevalue.data)
Y = housevalue.target
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3, random_state=0)
reg = LR().fit(Xtrain, Ytrain)
yhat = reg.predict(Xtest)
print(MAE(yhat, Ytest)) # 3.799847083754532
print(MAE(yhat, Ytest)/yhat.mean()) # 0.16572231804711068
平均绝对误差MAE:3.799,每个样本的平均偏差率大约为0.165*100% = 16.5% (效果显然不太好,稍后的 score 会进一步证明 得分确实并不高!)
二、 Mean Squared Error MSE均方误差
MSE 是回归任务中最常用的一种评估指标,它表达的是预测值与真实值的误差平方和的平均值(其实想打公式,无奈我不会在markdown中编辑数学公式,@_@…)
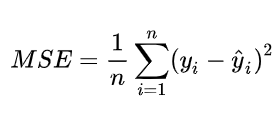
均方误差,得到了每个样本量上的平均误差。有了平均误差,我们就可以将平均误差和我们的标签的取值范围在一起比较,以此获得一个较为可靠的评估依据。当然是希望 MSE 越小越好了
例子1 电池容量预测
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression as LR # 性线回归函数
from sklearn.linear_model import Ridge as RD # 岭回归
from sklearn.metrics import mean_squared_error as MSE # 均方误差
from sklearn.metrics import mean_absolute_error as MAE # 平均绝对误差
from sklearn.model_selection import cross_val_score # 交叉验证得分
import matplotlib.pyplot as plt
# 获取训练数据
xtrain = pd.read_excel(r'C:\Users\YANG\Desktop\【源代码】\ch04\x6718.xlsx')
ytrain = pd.read_excel(r'C:\Users\YANG\Desktop\【源代码】\ch04\y6718.xlsx')
# 获取测试数据
xtest = pd.read_excel(r'C:\Users\YANG\Desktop\【源代码】\ch04\xB5.xlsx')
ytest = pd.read_excel(r'C:\Users\YANG\Desktop\【源代码】\ch04\yB5.xlsx')
reg = LR().fit(xtrain, ytrain) # 训练数据的拟合
yhat = reg.predict(xtest)
print('均方误差MSE: %s' % MSE(yhat, ytest)) # 0.011045989054690012
print(ytest.mean()) # 0.509262
print(MSE(yhat, ytest)/ytest.mean()) # 0.02169
在这个案例中,MSE的值为:0.01145,相比于标签值介于0-1,预测值介于-0.06 ~1.017,算是一个比理想的误差了,我们对预测值取了一个平均值得 ytest.mean = 0.509262,用MSE除以该均值,可算出在每个样本上的平均错误率有0.02169*100% = 2.169%
例子2 加利福尼亚房屋价值预测
import pandas as pd
from sklearn.linear_model import LinearRegression as LR # 性线回归函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE # 均方误差
from sklearn.datasets import fetch_california_housing as fch
housevalue = fch() # 获取数据集
X = pd.DataFrame(housevalue.data)
Y = housevalue.target
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3, random_state=0)
reg = LR().fit(Xtrain, Ytrain)
yhat = reg.predict(Xtest)
print(MSE(yhat, Ytest)) # 0.5431489670037231
print(yhat.mean()) # 2.078195063109549
print(MSE(yhat, Ytest)/Ytest.mean()) # 0.26248134342378177
,MSE的值为:0.5431,相比于标签值介于0.15-5,预测值介于-1~ 7.28,算是一个比较大的误差了,对预测值取了一个平均值得 ytest.mean =2.078,用MSE除以该均值,可算出在每个样本上的平均错误率有0.2624*100% = 26.24% (哼,不能接受!!)
三、Root Mean Square Error RMSE均方根误差
RMSE是在MSE的基础之上开根号而来,目的是使结果与标签值统一量纲,RMSE越小模型越好~
例 波斯顿房价预测
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression as LR # 性线回归函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE # 均方误差
from sklearn.datasets import load_boston as bs
housevalue = bs() # 获取数据集
X = pd.DataFrame(housevalue.data)
Y = housevalue.target
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3, random_state=0)
reg = LR().fit(Xtrain, Ytrain)
yhat = reg.predict(Xtest)
print(MSE(yhat, Ytest)) # 27.195965766883234
print(np.sqrt(MSE(yhat, Ytest))) # 5.214975145375406
RMSE : 5.21
不同评估指标的对同一个模型评分是不一样的,很难定义统一的规则来衡量模型的好坏,由此,引出一个无量纲化的指标 R^2 决定系数
四、 R^2 决定系数
R^2 的定义是
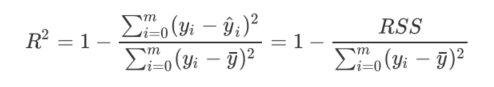
在 R^2中,分子是真实值和预测值之差的差值,也就是我们的模型没有捕获到的信息总量,分母是真实标签所带的信息量,所以其衡量的是我们的模型没有捕获到的信息量占真实标签中所带的信息量的比例,所以, 越接近1越好。
在sklearn 中,score打分函数使用的就是R^2,还有一种就是使用 r2_score
例子 波斯顿房价预测
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression as LR # 性线回归函数
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error as MSE # 均方误差
from sklearn.datasets import load_boston as bs
housevalue = bs() # 获取数据集
X = pd.DataFrame(housevalue.data)
Y = housevalue.target
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X, Y, test_size=0.3, random_state=0)
reg = LR().fit(Xtrain, Ytrain)
yhat = reg.predict(Xtest)
print(reg.score(Xtest, Ytest)) # 0.6733825506400193
print(r2_score(y_pred=yhat, y_true=Ytest)) # 0.6733825506400193
R^2 = 0.6733825506400193
参考文献:1.https://zhuanlan.zhihu.com/p/36305931
2. https://zhuanlan.zhihu.com/p/271911178















 8094
8094











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









