







1.LeNet & MNIST
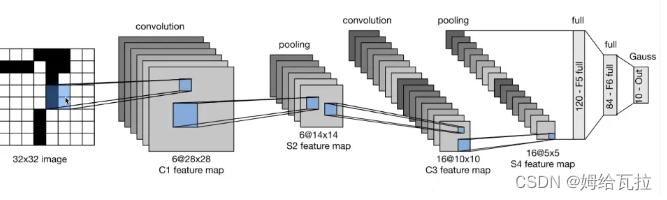
LeNet:
- 第一层:卷积核的形状(1,6,5,5),六个(5,5)的卷积核
- 第二层:池化层,窗口的形状是(6,2,2),设置stride = 2.输出大小为:(6,14,14)
- 第三层:卷积层,卷积核的形状为(6,16,5,5).
- 第四层:池化层,窗口大小为(16,2,2),设置stride = 2.输出大小为(16,5,5)
- 第五层:全连接层,120个节点
- 第六层:全连接层,84个节点
- 第七层:输出层,10个分类
MNIST:
MNIST数据库(Modified National Institute of Standards and Technology database)是一个大型数据库的手写数字是通常用于训练各种图像处理系统。该数据库还广泛用于机器学习领域的培训和测试。它是通过“重新混合” NIST原始数据集中的样本而创建的。创作者认为,由于NIST的培训数据集来自美国人口普查局员工,而测试数据集则来自美国 高中学生,这不是非常适合于机器学习实验。此外,将来自NIST的黑白图像归一化以适合28x28像素的边界框并进行抗锯齿处理,从而引入了灰度级。
包含60,000个训练图像和10,000个测试图像。训练集的一半和测试集的一半来自NIST的训练数据集,而训练集的另一半和测试集的另一半则来自NIST的测试数据集。数据库的原始创建者保留了一些经过测试的方法的列表。在他们的原始论文中,他们使用支持向量机获得0.8%的错误率。类似于MNIST的扩展数据集EMNIST已于2017年发布,其中包含240,000个训练图像和40,000个手写数字和字符的测试图像。

2.AlexNet & CIFAR
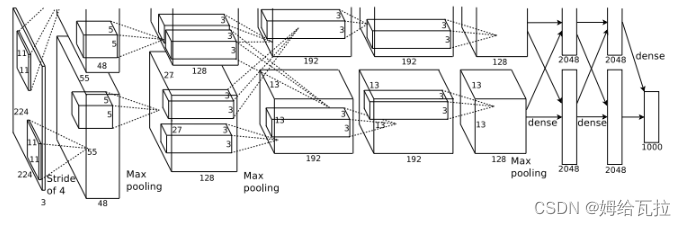
AlexNet:
AlexNet架构:5个卷积层(Convolution、ReLU、LRN、Pooling)+3个全连接层(InnerProduct、ReLU、Dropout)
(1).输入层(Input):图像大小227*227*3。如果输入的是灰度图,它需要将灰度图转换为BGR图。训练图大小需要为256*256,否则需要进行缩放,然后从256*256中随机剪切生成227*227大小的图像作为输入层的输入。
(2).卷积层1+ReLU+LRN:使用96个11*11的filter,stride为4,padding为0,输出为55*55*96,96个feature maps,训练参数(11*11*3*96)+96=34944。
(3).最大池化层:filter为3*3,stride为2,padding为0,输出为27*27*96,96个feature maps。
(4).卷积层2+ReLU+LRN:使用256个5*5的filter,stride为1,padding为2,输出为27*27*256,256个feature maps,训练参数(5*5*96*256)+256=614656。
(5).最大池化层:filter为3*3,stride为2,padding为0,输出为13*13*256,256个feature maps。
(6).卷积层3+ReLU:使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps,训练参数(3*3*256*384)+384=885120。
(7).卷积层4+ReLU:使用384个3*3的filter,stride为1,padding为1,输出为13*13*384,384个feature maps,训练参数(3*3*384*384)+384=1327488。
(8).卷积层5+ReLU:使用256个3*3的filter,stride为1,padding为1,输出为13*13*256,256个feature maps,训练参数(3*3*384*256)+256=884992。
(9).最大池化层:filter为3*3,stride为2,padding为0,输出为6*6*256,256个feature maps。
(10).全连接层1+ReLU+Dropout:有4096个神经元,训练参数(6*6*256)*4096=37748736。
(11).全连接层2+ReLU+Dropout:有4096个神经元,训练参数4096*4096=16777216。
(12).全连接层3:有1000个神经元,训练参数4096*1000=4096000。
(13).输出层(Softmax):输出识别结果,看它究竟是1000个可能类别中的哪一个。
CIFAR:
CIFAR是由Alex Krizhevsky、Vinod Nair和Geoffrey Hinton收集而来,起初的数据集共分10类,分别为飞机、汽车、鸟、猫、鹿、狗、青蛙、马、船、卡车,所以CIFAR数据集常以CIFAR-10命名。CIFAR共包含60000张32*32的彩色图像(包含50000张训练图片,10000张测试图片),其中没有任何类型重叠的情况。
因为是彩色图像,所以这个数据集是三通道的,分别是R,G,B3 个通道。后来CIFAR又出了一个分类更多的版本叫CIFAR-100,共有100类,将图片分得更细,当然对神经网络图像识别是更大的挑战了。有了这些数据,我们可以把精力全部投入在网络优化上。
不同于MNIST数据集,它的数据集是已经打好包的文件,分别为Python、MATLIB、二进制bin文件包,以方便不同的程序读取。

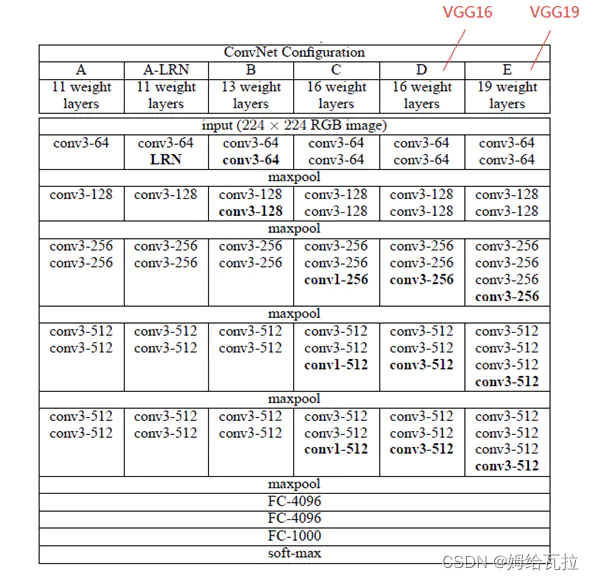
3.VGG Net

4.GoogLeNet & Inception v1
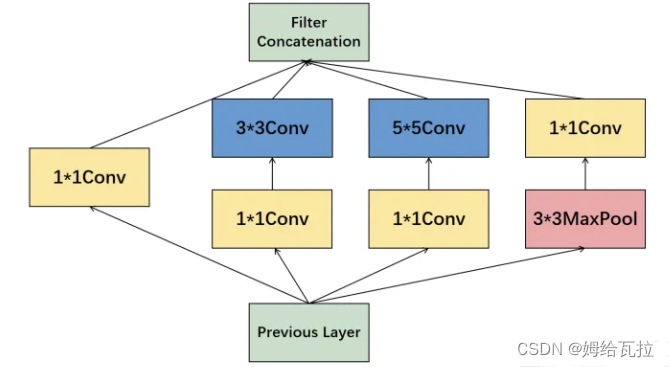
Inception-v1将多尺度的卷积层、池化层提取的特征图拼接输入下一层,提升模型多尺度特征提取能力。
Inception-v1参考看NiN的网络设计,利用1*1Conv来降维输入通道,减少模型参数量,并引入更多的非线性,提升模型泛化能力。
5.ResNet
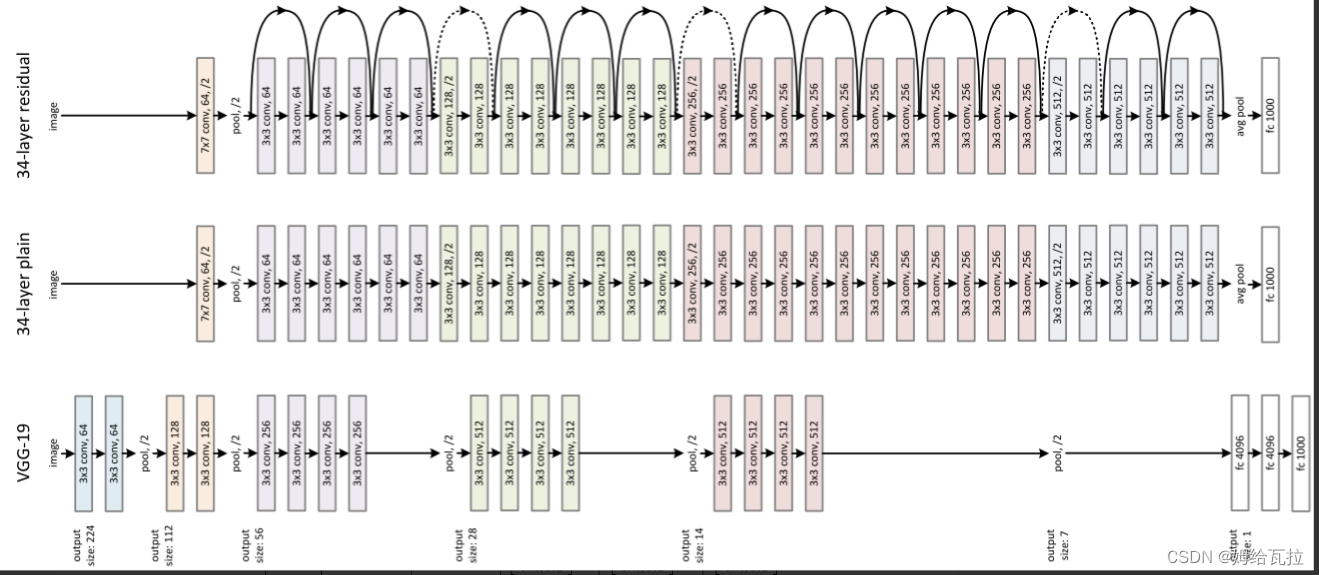
ResNet也称为残差网络。ResNet是由残差块(Residual Building Block)构建的,论文截图如下所示:提出了两种映射:identity mapping(恒等映射),指的是右侧标有x的曲线;residual mapping(残差映射),残差指的是F(x)部分。最后的输出是F(x)+x。F(x)+x的实现可通过具有”shortcut connections”的前馈神经网络来实现。shortcut connections是跳过一层或多层的连接。图中的”weight layer”指卷积操作。如果网络已经达到最优,继续加深网络,residual mapping将变为0,只剩下identity mapping,这样理论上网络会一直处于最优状态,网络的性能也就不会随着深度增加而降低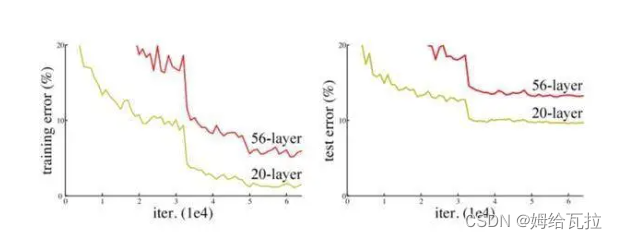















 606
606











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









