






简介
- 利用 doi 批量下载 pdf 文献。
- 只需要准备包含
Article Title和DOI两列的 excel 即可。
github 地址:https://github.com/tangpan360/download_papers
使用逻辑
- 从 wos 导出含有文献名和 doi 的 excel 文件(savedrecs.xls),或自己按需要的格式整理成 excel;
- 将 savedrecs.xls 放入文件夹 xls_folder 中;
- 直接运行 download.py 即可。
文件放置结构
批量下载文献脚本文件夹
├── xls_folder
│ └── savedrecs.xls
└── download.py
- savedrecs.xls excel 文件的内容格式如下(注意代码中的 excel 文件的后缀名是:
.xls,如果你用的excel 后缀名是.xlsx,注意在代码中的对应部分进行修改):
| Article Title | DOI |
|---|---|
| Construction of a synthetic Saccharomyces cerevisiae pan-genome neo-chromosome | 10.1038/s41467-022-31305-4 |
| Analysis of queuosine and 2-thio tRNA modifications by high throughput sequencing | 10.1093/nar/gkac517 |
| A multiplex platform for small RNA sequencing elucidates multifaceted tRNA stress response and translational regulation | 10.1038/s41467-022-30261-3 |
| De novo assembly and delivery to mouse cells of a 101 kb functional human gene | 10.1093/genetics/iyab038 |
| An isocaloric moderately high-fat diet extends lifespan in male rats and Drosophila | 10.1016/j.cmet.2020.12.017 |
download.py文件内容:
# download.py
import requests
from bs4 import BeautifulSoup
import os
import threading
import pandas as pd
import re
from queue import Queue
# 清理文件名中的非法字符
def clean_filename(title):
illegal_chars = r'[\\/:*?"<>|]'
return re.sub(illegal_chars, '', title)
# 下载文献的函数
def download_paper(doi_title_queue, success_log, error_log, failed_dois, sci_hub_domains, head, download_folder):
while not doi_title_queue.empty():
doi, title = doi_title_queue.get() # 从队列中获取 DOI 和标题
if not doi: # 如果 DOI 为空
error_log.append(f"{title}\t没有 DOI。\n") # 记录没有 DOI 的文献
failed_dois.append((title, 'No DOI')) # 将没有 DOI 的文献标题和说明记录到 failed_dois 中
doi_title_queue.task_done() # 任务完成
continue # 跳过这篇文献
download_url = None
for domain in sci_hub_domains:
url = domain + doi + "#"
try:
r = requests.get(url, headers=head, timeout=15)
r.raise_for_status()
soup = BeautifulSoup(r.text, "html.parser")
if soup.iframe is None and soup.embed:
download_url = "https:" + soup.embed.attrs.get("src", "")
elif soup.iframe:
download_url = soup.iframe.attrs.get("src", "")
if download_url:
print(f"{doi}\t正在下载\n下载链接为\t" + download_url)
download_r = requests.get(download_url, headers=head, timeout=15)
download_r.raise_for_status()
file_name = clean_filename(title) + ".pdf"
file_path = os.path.join(download_folder, file_name)
with open(file_path, "wb+") as temp:
temp.write(download_r.content)
success_log.append(f"{doi}\t下载成功.\n")
print(f"{doi}\t文献下载成功.\n")
break
except requests.exceptions.RequestException as e:
error_log.append(f"{doi}\t下载失败! 错误信息: {str(e)}\n")
continue
if not download_url:
error_log.append(f"{doi}\t下载失败! 无法从任何Sci-Hub域名获取文献.\n")
failed_dois.append((title, doi)) # 将失败的文献标题和 DOI 记录到 failed_dois 中
doi_title_queue.task_done()
def main():
# 配置变量
xls_file = './xls_folder/savedrecs.xls'
download_folder = './download_papers/'
sci_hub_domains = [
"https://www.sci-hub.ren/",
"https://sci-hub.hk/",
"https://sci-hub.se/",
"https://sci-hub.st/",
"https://sci-hub.la/",
"https://sci-hub.cat/",
"https://sci-hub.ee/",
"https://www.tesble.com/"
]
head = {
"user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.117 Safari/537.36"
}
num_threads = 5
# 创建保存下载文件的文件夹
if not os.path.exists(download_folder):
os.makedirs(download_folder)
# 读取Excel文件
df = pd.read_excel(xls_file)
# 提取DOI列和文献标题列
doi_list = df['DOI'].dropna().tolist()
titles = df['Article Title'].dropna().tolist()
# 创建一个线程安全的队列
doi_title_queue = Queue()
# 将 DOI 和标题一一对应地放入队列中
for doi, title in zip(doi_list, titles):
doi_title_queue.put((doi, title))
# 成功与失败的记录
success_log = []
error_log = []
failed_dois = [] # 使用列表来存储失败的 DOI 和文献标题
# 启动多线程下载文献
threads = []
for _ in range(num_threads):
t = threading.Thread(target=download_paper, args=(
doi_title_queue, success_log, error_log, failed_dois, sci_hub_domains, head, download_folder))
threads.append(t)
# 启动所有线程
for t in threads:
t.start()
# 等待所有线程完成
for t in threads:
t.join()
# 记录成功和失败的日志
with open(os.path.join("./download_log.txt"), "w", encoding="utf-8") as log_file:
log_file.write("成功下载的DOI:\n")
log_file.writelines(success_log)
log_file.write("\n下载失败的DOI:\n")
log_file.writelines(error_log)
# 输出下载失败的文献(包括没有 DOI 的文献)
with open(os.path.join("./failed_dois.txt"), "w", encoding="utf-8") as failed_file:
failed_file.write("以下DOI下载失败,请手动检查资源:\n")
for title, doi in failed_dois:
if doi == 'No DOI':
failed_file.write(f"{title}\t没有 DOI\n") # 没有 DOI 的文献
else:
failed_file.write(f"{title}\t{doi}\n") # 有 DOI 但下载失败的文献
print("所有任务完成!")
# 确保脚本只有在作为主程序运行时才执行下载操作
if __name__ == '__main__':
main()
图文展示具体步骤
1. 准备包含文献名和对应 doi 的 excel 文件
有两种方式都可以:从 wos 导出 excel 文件,或者自己按格式整理对应的 excel 文件。
1. 方式一:从 wos 导出 excel
-
进入 wos 网址:https://webofscience.clarivate.cn/wos/alldb/basic-search
-
如下图,输入要搜索的文章:
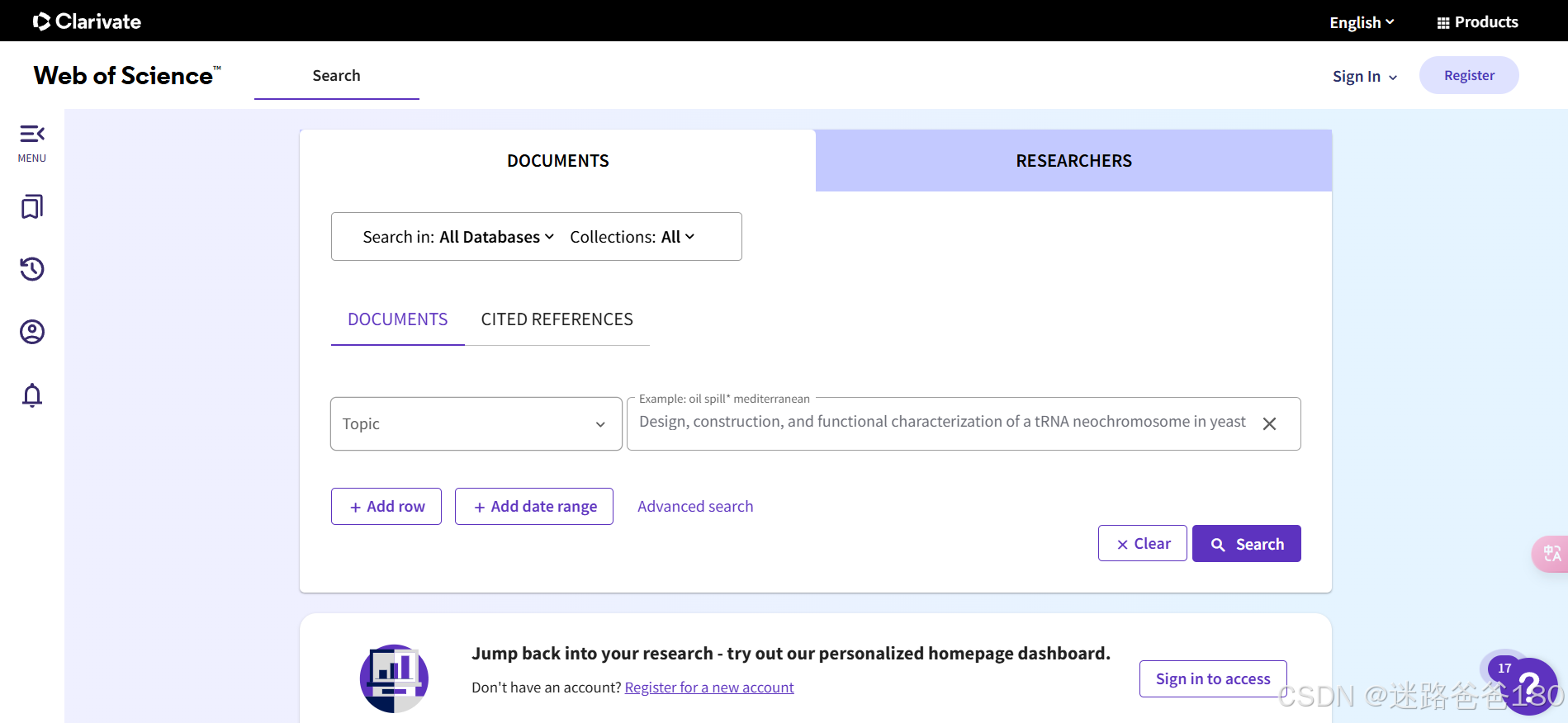
-
检索之后可以选择多篇自己检索的文章如下图中的1,为了方便,我直接用这篇文章的 112 篇 references 来演示接下来的批量下载操作,如图中2所示点击 112:
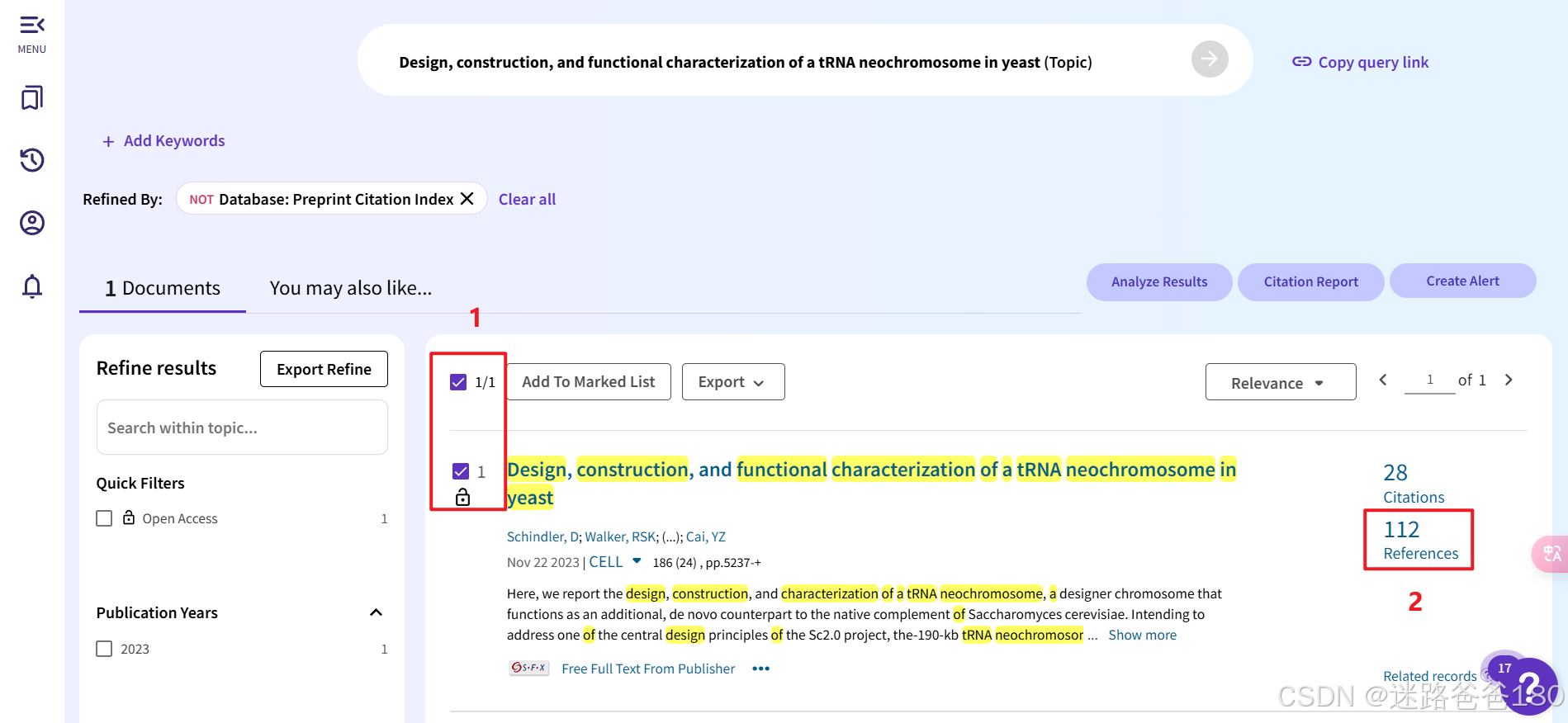
-
全选之后如图所示,导出选中的 107 篇参考文献的 excel 文件(由于一些原因,存在一些文献不可选):
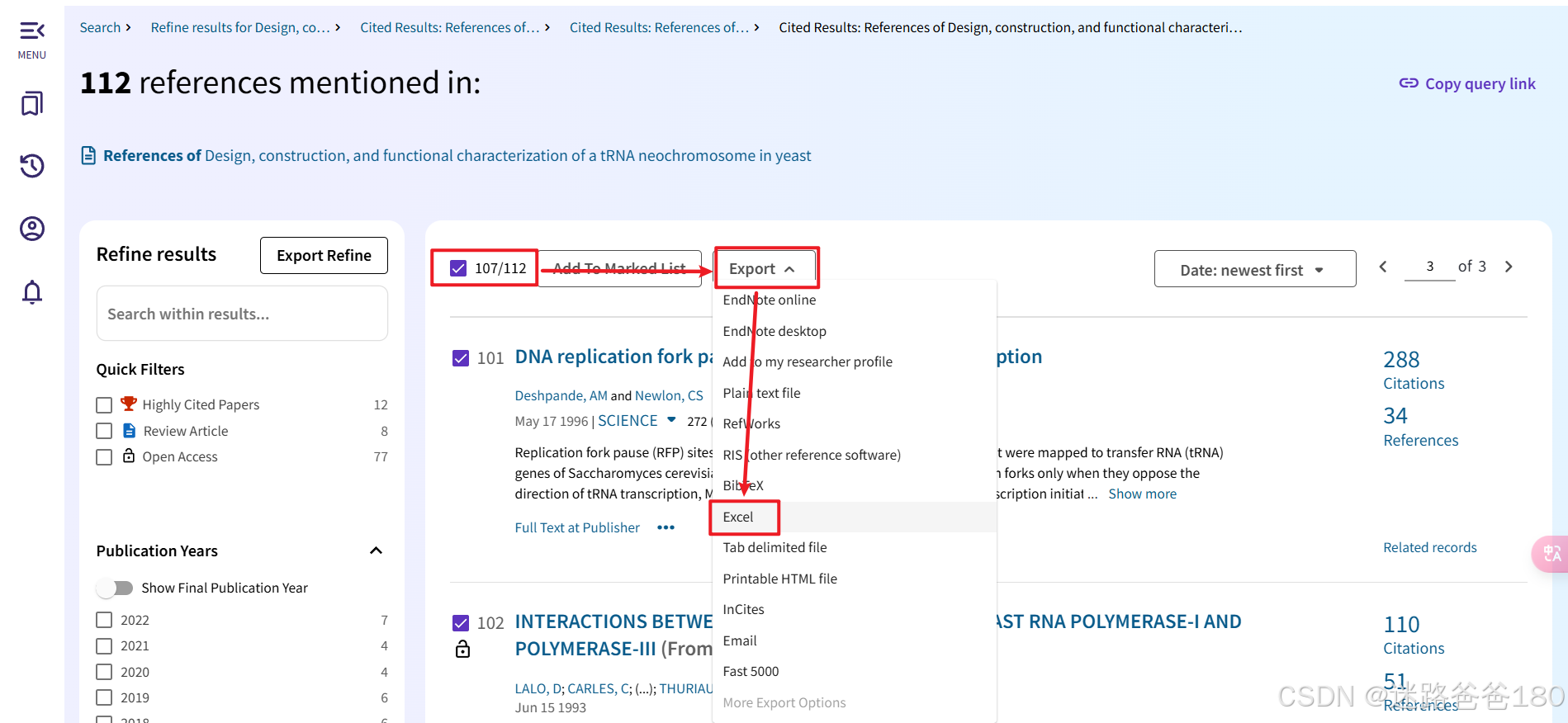
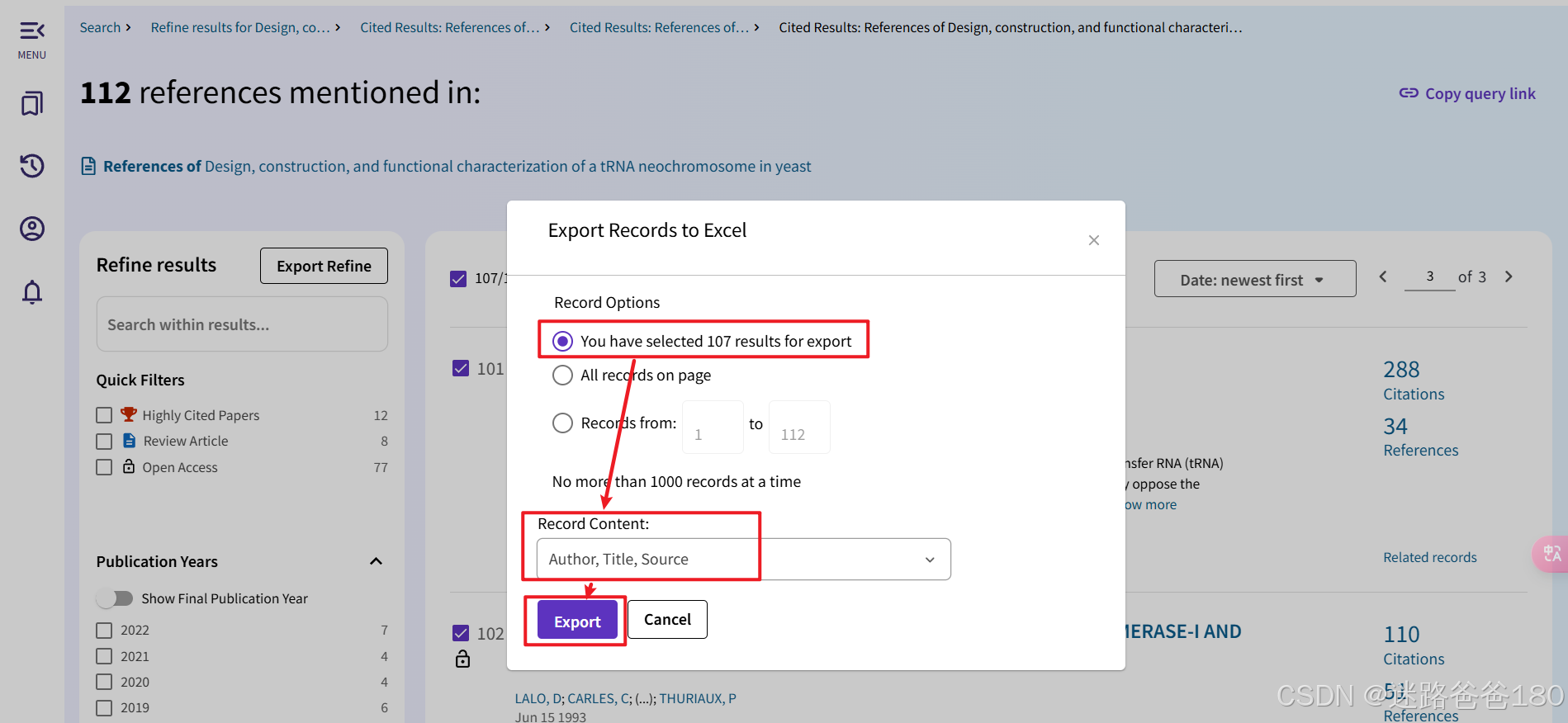
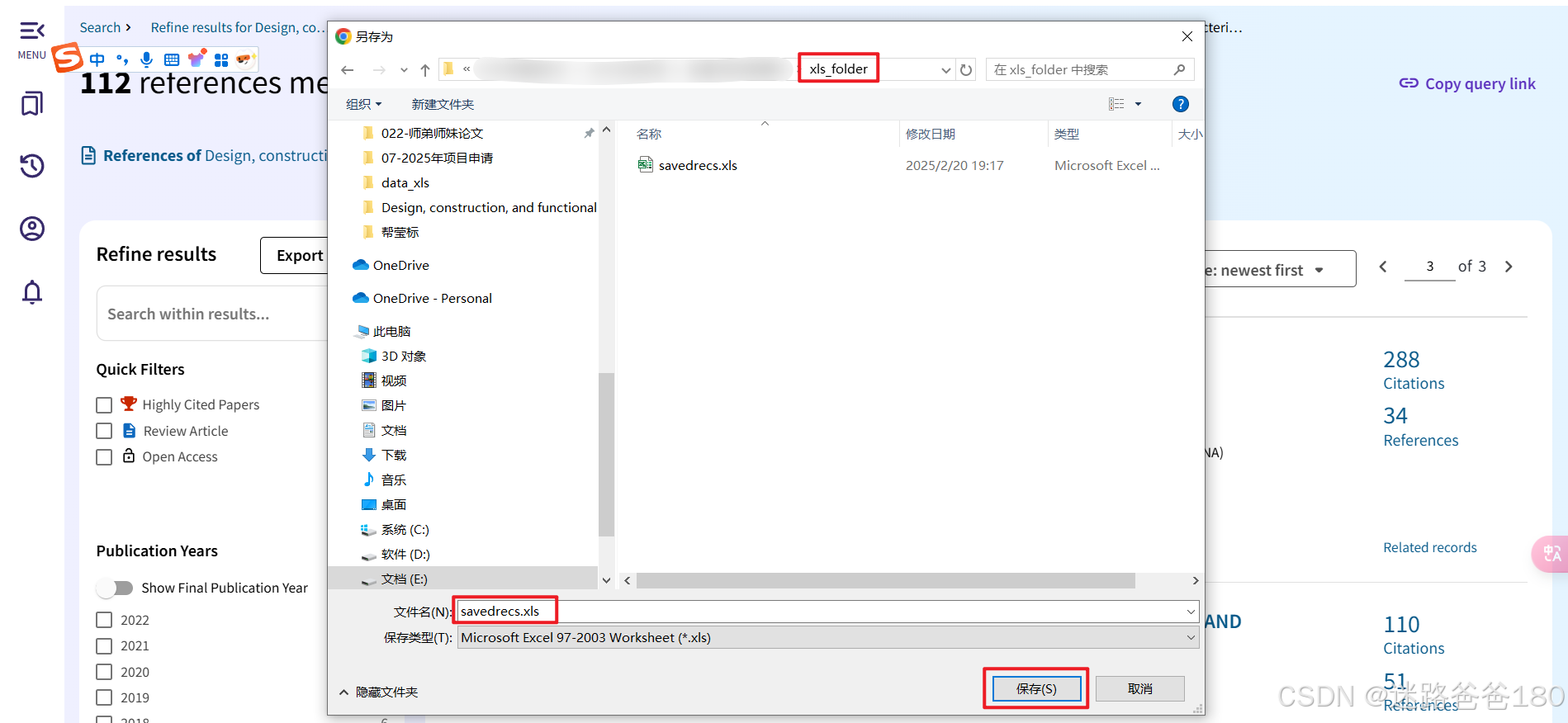
-
打开保存的 excel 文件
savedrecs.xls可以看到包含Article Title和DOI两列(有其它列也无所谓,只要包含这两列即可):
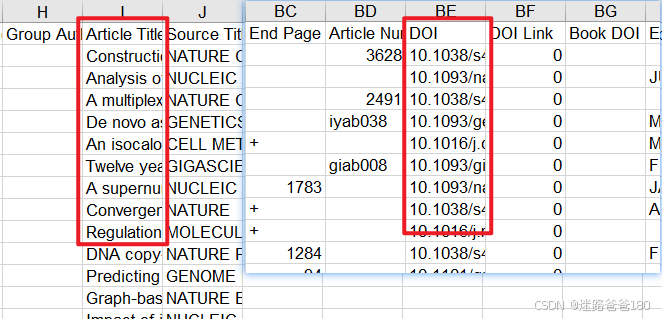
-
至此,所需要的 excel 文件准备完成。
2. 方式二:自己按格式整理对应的 excel
不从 wos 导出也可以使用,只需要有包含下面两列内容的 excel 文件即可。从 wos 导出的 excel 文件有很多列,因为包含这两列,所以导出之后直接可用。
| Article Title | DOI |
|---|---|
| Construction of a synthetic Saccharomyces cerevisiae pan-genome neo-chromosome | 10.1038/s41467-022-31305-4 |
| Analysis of queuosine and 2-thio tRNA modifications by high throughput sequencing | 10.1093/nar/gkac517 |
| A multiplex platform for small RNA sequencing elucidates multifaceted tRNA stress response and translational regulation | 10.1038/s41467-022-30261-3 |
| De novo assembly and delivery to mouse cells of a 101 kb functional human gene | 10.1093/genetics/iyab038 |
| An isocaloric moderately high-fat diet extends lifespan in male rats and Drosophila | 10.1016/j.cmet.2020.12.017 |
2. 运行 downloader.py 程序执行批量下载
- 在终端输入命令执行代码:
python download.py
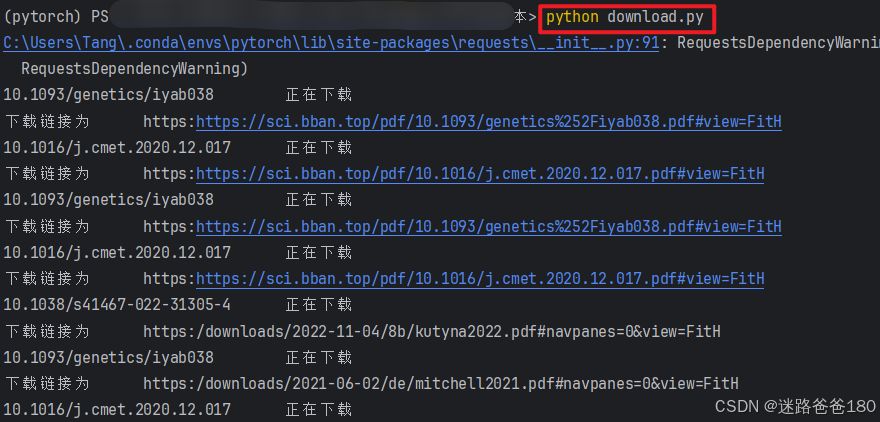
- 则可以在
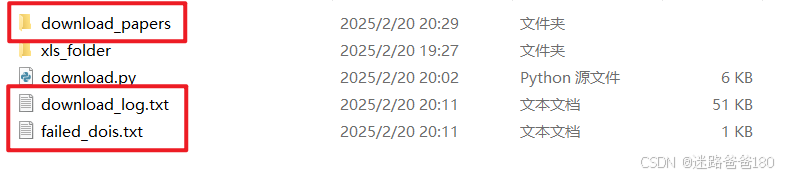
download_papers文件夹中看到下载的文件:
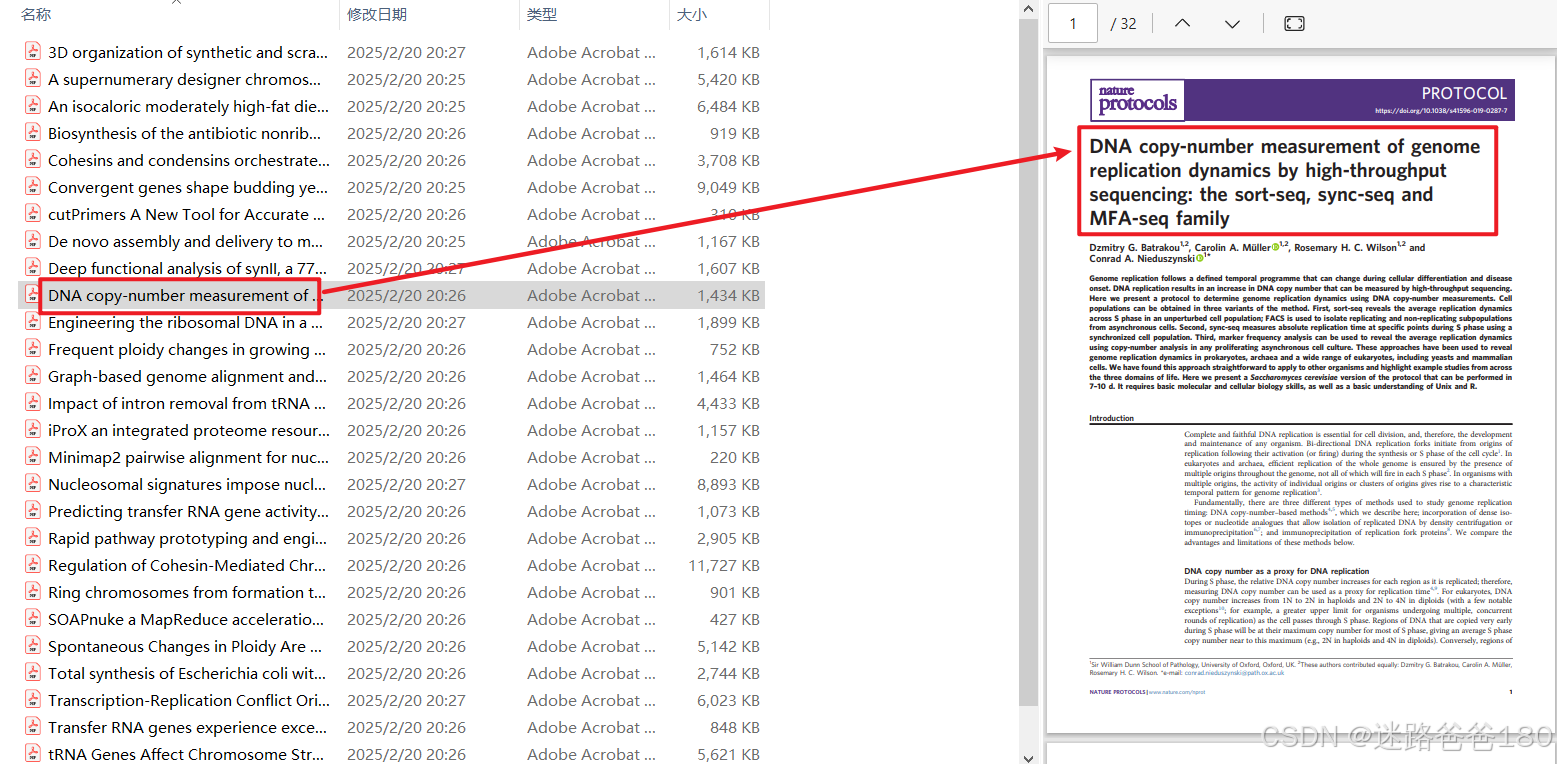
- 同时还生成了下载日志以及下载失败需要手动下载的记录文件:
3. 检查失败日志,进行手动下载
检查日志内容,对未下载成功的进行手动查询下载:


















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









