









一、什么是Transormer?
- Transformer是一个用于解决Seq2Seq问题的模型,用来解决输出长度不确定的问题
- Transformer是一个利用自注意力机制来提高模型训练速度的深度学习模型
- 它适用于并行化计算
- 它本身模型的复杂程度较高
- 它在精度和性能上都要高于之前流行的RNN循环神经网络。
二、Seq2Seq模型
2.1 什么是Seq2Seq?
Seq2Seq模型是输出的长度不确定时采用的模型,这种情况一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以输出的长度就不确定了。它的输入是一个序列,输出也是一个序列。
2.2 Seq2Seq的具体应用
语音辨识(输入语音,输出文字)

语音合成(输入文字,输出语音)
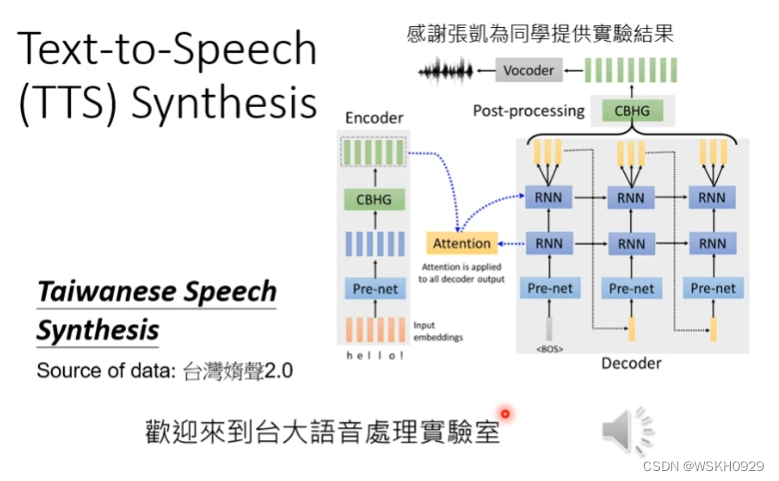
聊天机器人(输入一段话,输出一段话)
三、Transformer网络结构
前面说过,Transormer属于Seq2Seq模型的一种,所以其也是Encoder-Decoder的结构。

3.1 Encoder
输入一个向量,输出一个同样长度的向量
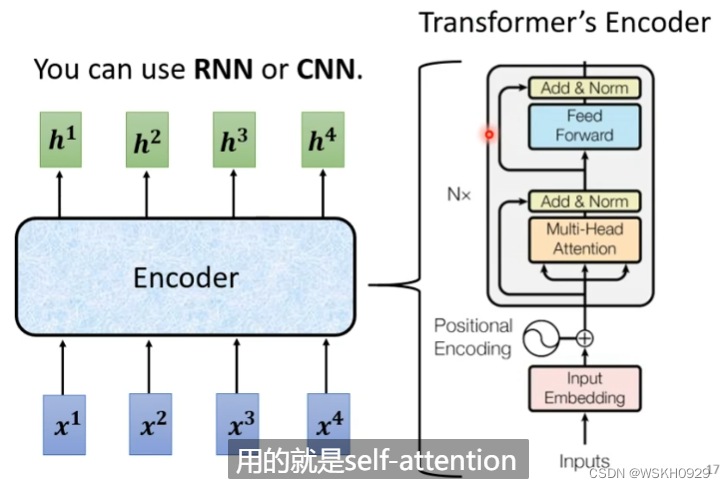
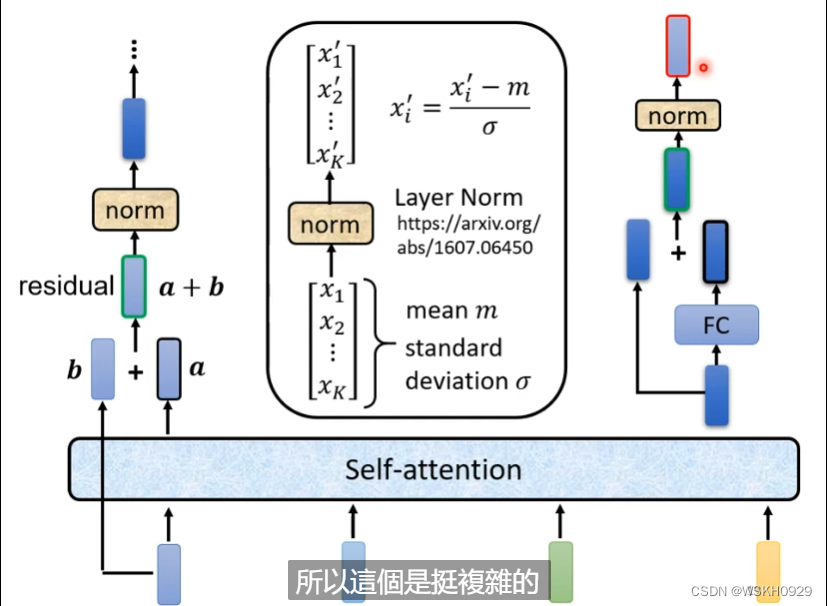
输入和输出之间有很多个Block,每个Block里面一般有好几层,例如下图所示,输入先通过一层Self-Attention收集自身咨询,然后再通过全连接层进行特征提取
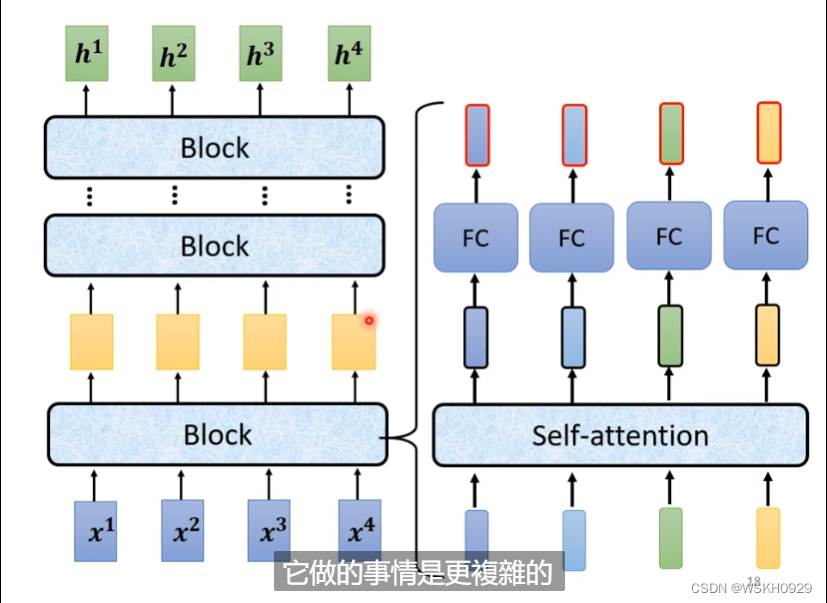
实际上,它还会更复杂一些。如下图所示,通过Self-Attention地输出还会加上其本身,这被称为Residual Connection,残差连接,主要为了缓解梯度弥散和梯度爆炸的问题。然后a+b的结果会进行Layer Normalization,最终得到输出。
在FC层也是一样,用到了残差连接和层标准化。
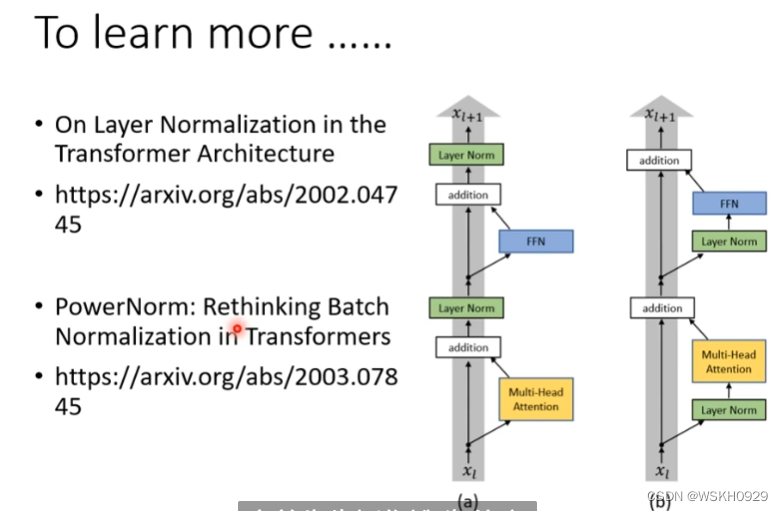
关于Encoder的设计不一定要局限于上面的结构,有人做了研究,如果把层标准化放在addition之前效果会更好(下图右边的结构)。
3.2 Decoder
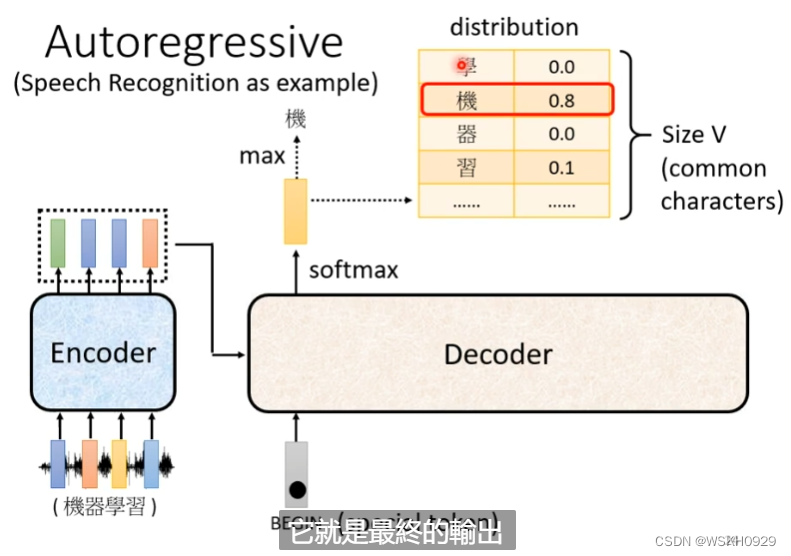
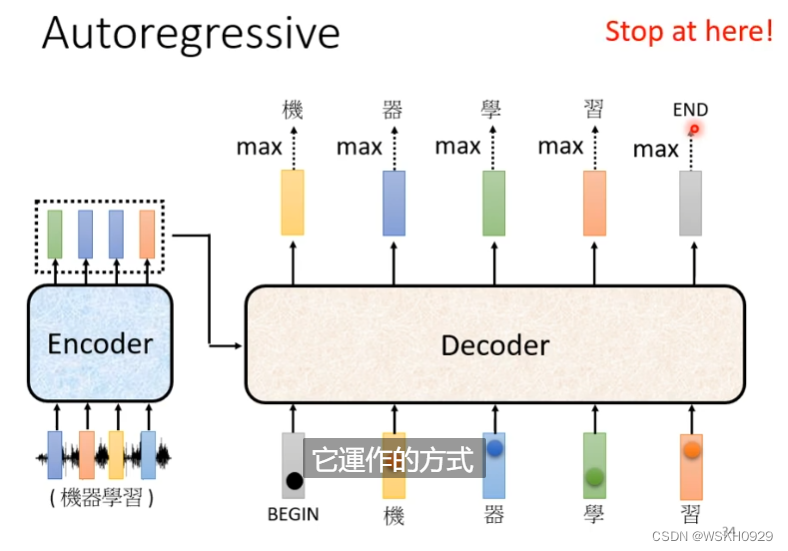
3.2.1 Autoregressive(AT)
Decoder的输入是Encoder的输出和一个开始标识符(One-Hot向量表示),Decoder的输出是一个长度等于字典大小的概率分布(输出之前用SoftMax做归一化),然后以概率最大的字作为最终的输出。
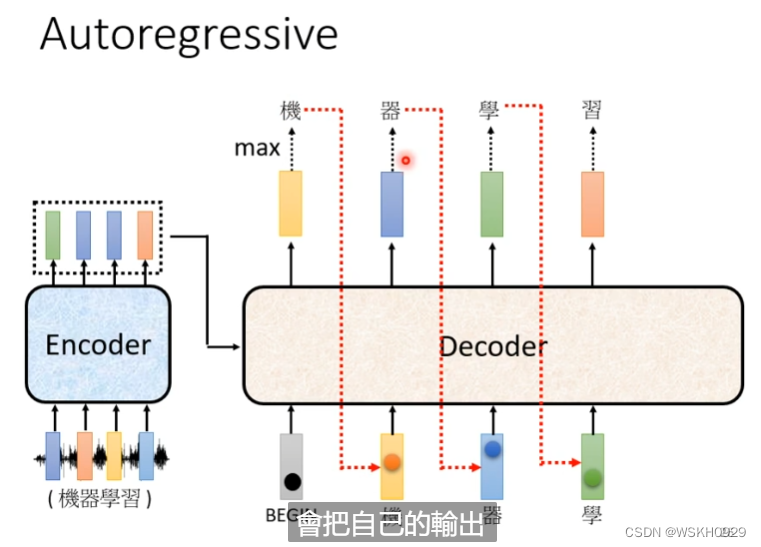
接下来,Decoder会把自己上一阶段的输出,当成现阶段的输入,继续输出。
比较一下Encoder和Decoder的差异
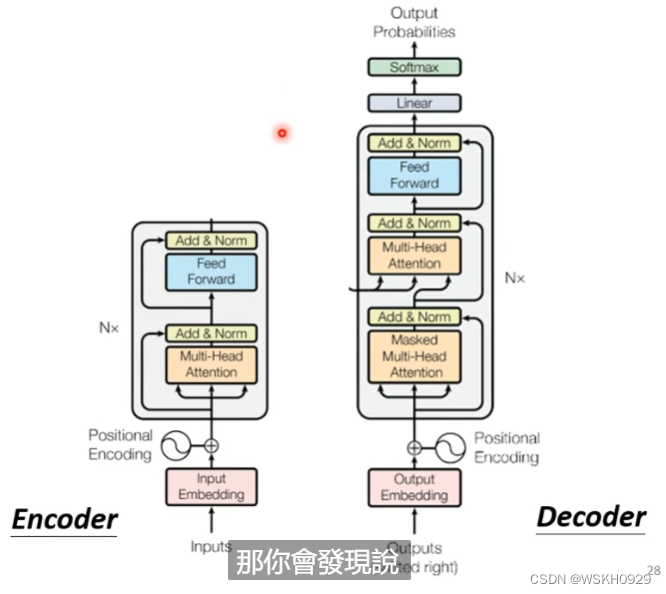
把Decoder中间部分遮挡起来,先不看,我们发现Encoder和Decoder其实非常相似。
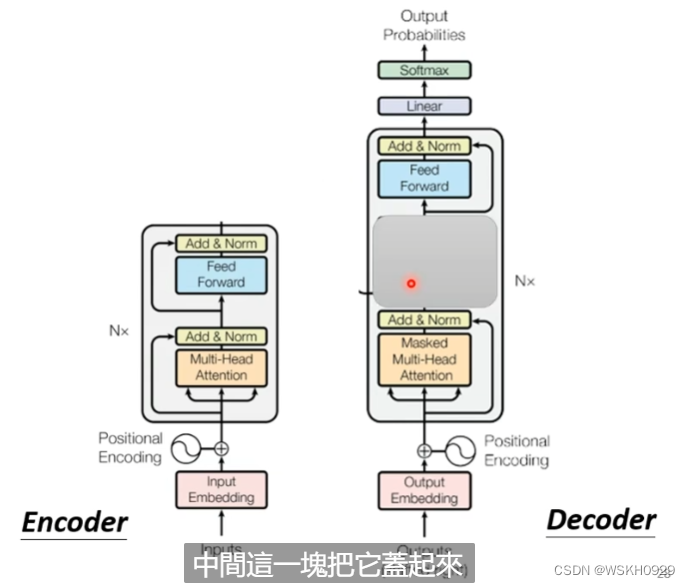
有点不同的是,Decoder最后还加了一个线性层和SoftMax进行概率的输出;Decoder使用了比较特殊的Masked Self-Attention,什么是Masked Self-Attention呢?
Masked Self-Attention 要求每一个输出,不能考虑其右边的资讯。如下图所示,输出b1,只考虑了a1的资讯;输出b2,只考虑了a1和a2的资讯,以此类推。
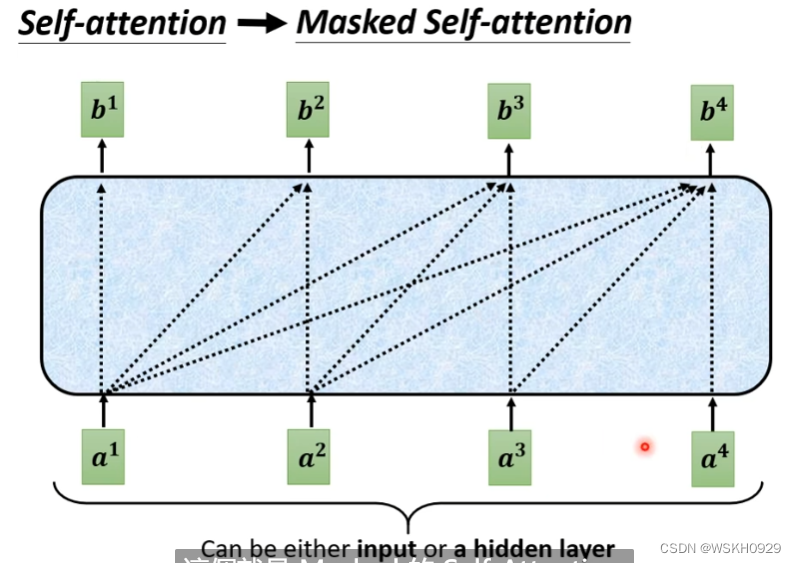
为什么Decoder要用Masked Self-Attention呢?这是因为Decoder在运作的时候,是依靠前面的输出,作为当前输入的,也就是说,在当前时刻,Decoder没有办法知道后面的咨询,所以就使用了Masked Self-Attention
END终止符:存在于字典里的一个特殊符号,当Decoder输出END符号时,其运作就可以停止了。
Tips:因为BEGIN开始符只在最开始作为输入使用了一次,所以其实END终止符和BEGIN起始符可以是同一个符号,以缩小字典大小
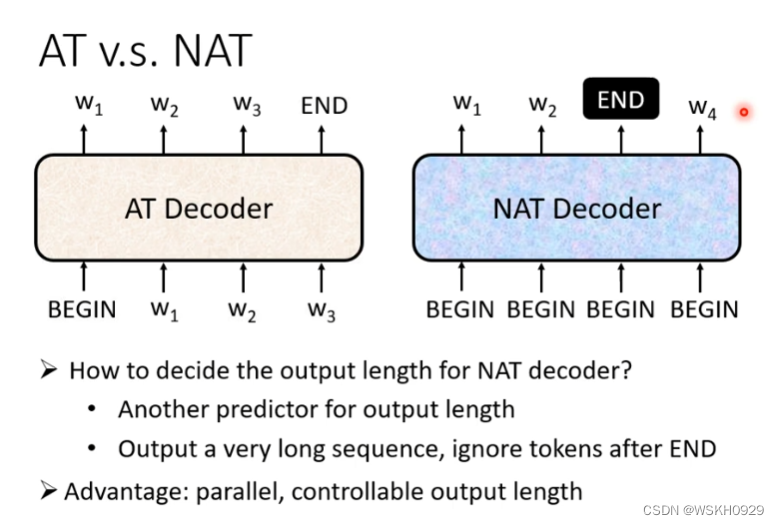
3.2.2 Non-Autoregressive(NAT)
NAT的做法是:一次性丢给DecoderN个BEGIN起始符,然后Decoder输出长度为N的字符,如果输出的N个字符中没有END符,则N个字符就是最终输出,否则以第一个出现的END符左边的内容作为最终的输出。
所以NAT的关键点是如何确定一次性丢给Decoder多少个BEGIN。有两种思路:
- 训练另一个Classifier,它的输入是Encoder的输出,它的输出是一个数字,比如输出6,则代表要给Decoder输入6个BEGIN
- 不管三七二十一,直接丢给Decoder足够多的BEGIN,比如一次性给300个(其使用前提是,已知输出文本最多不超过300字)
使用NAT的好处:
- 平行化,AT的Decoder在输出句子的时候,是一个一个字产生的(如果句子长度为100,那就药要进行101次的Decoder);而NAT的Decoder是一次性产生整个句子的,所以,在速度上NAT要快于AT
- NAT可以更好地控制输出句子的最大长度
使用NAT的缺点:
- NAT的表现往往不如AT的好
3.3 Encoder-Decoder
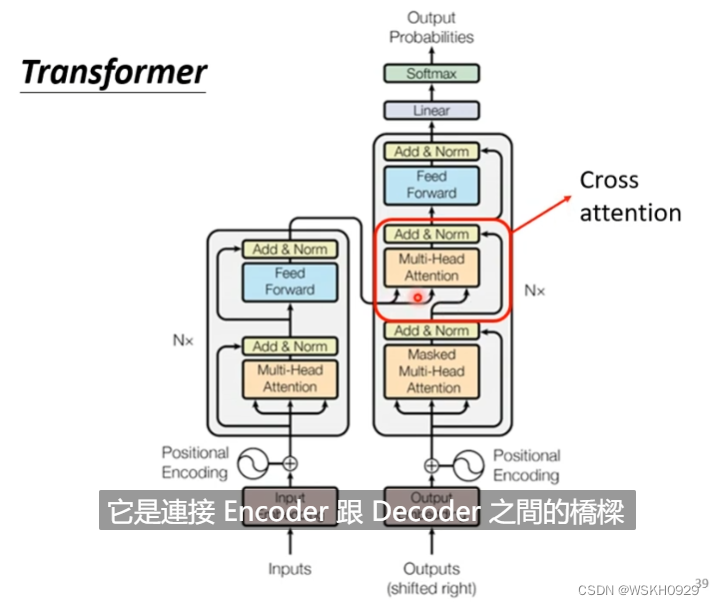
还记得之前讲Decoder的时候,有一块我们将其暂时忽略了吗?现在我们就来揭开它的神秘面纱。
如下图所示,它其实是Encoder和Decoder之间的桥梁,被称为 Cross Attention
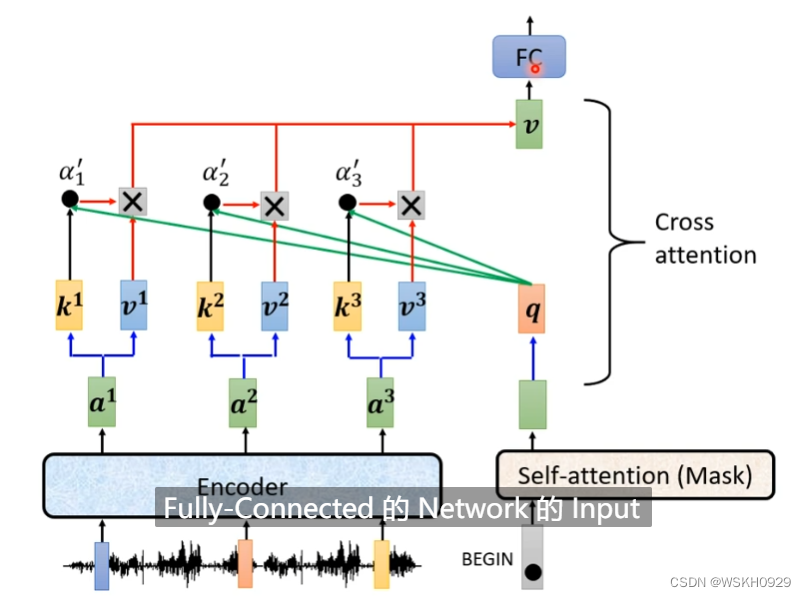
在计算Attention的时候,Q来自Decoder,K和V来自Encoder,然后进行Attention的计算,这被称为是Cross Attention
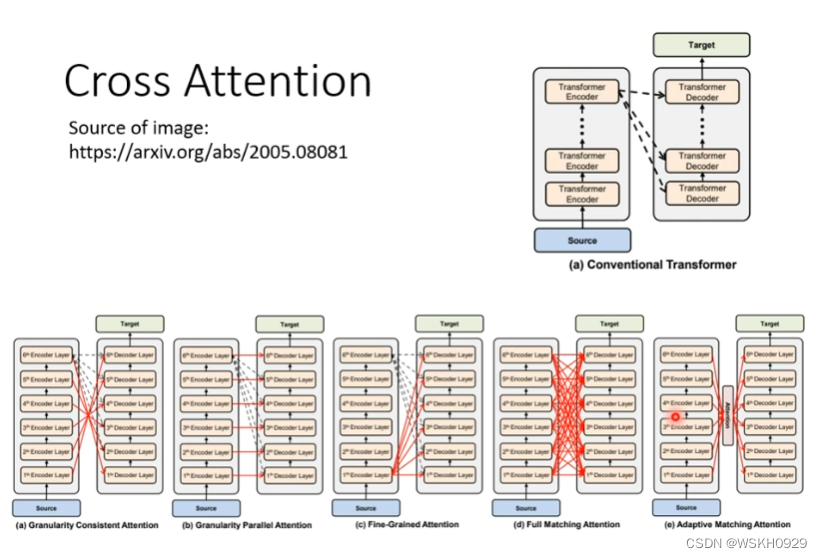
在原始论文中,Cross Attention是拿Encoder最后一层进行Cross的,但是一定要拿Encoder最后一层吗?下面这篇论文给出了答案:不一定。可以尝试各种各样的Cross方式,这都是可以研究的课题。
3.4 Training 训练过程
假设Label是“机器学习”四个字,那我们希望Decoder输出的第一个字和“机”越接近越好,对应的损失用“机”字对应One-Hot向量和Decoder输出的概率分布计算一个交叉熵损失
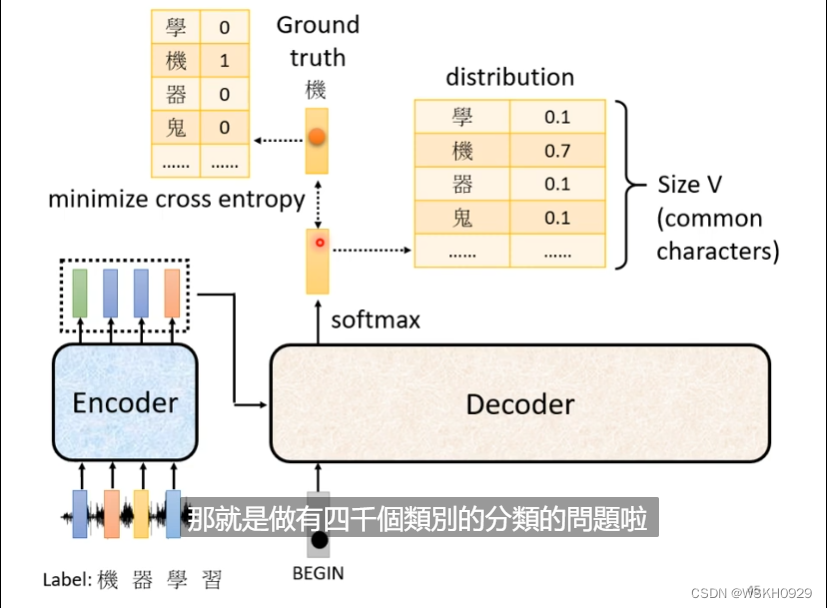
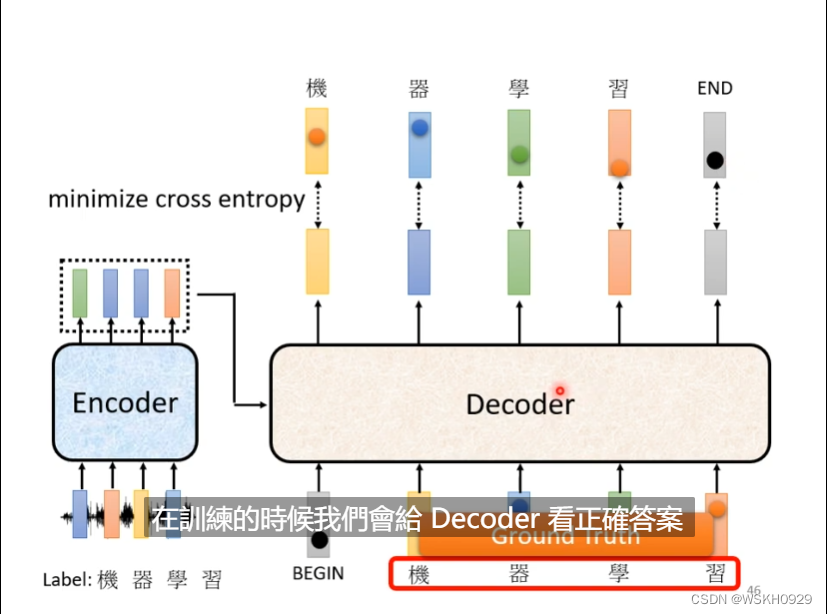
假设Decoder输出了四个字,和一个END符号,那我就希望前四个字和Label的交叉熵总和+后面的字符和END符号的交叉熵损失总和越小越好;
在训练的时候,我们不会拿上一时刻的输出作为Decoder的输入,而是会直接拿正确的Label作为Decoder的输入。这个技术叫做 Teacher Forcing
3.5 Tips 小技巧
3.5.1 Copy Mechanism 复制机制
聊天机器人:有时候,当聊天机器人听不懂对方说的话的时候,需要“复制”它听不懂的话,并进行询问,例如下图的第二个案例所示。

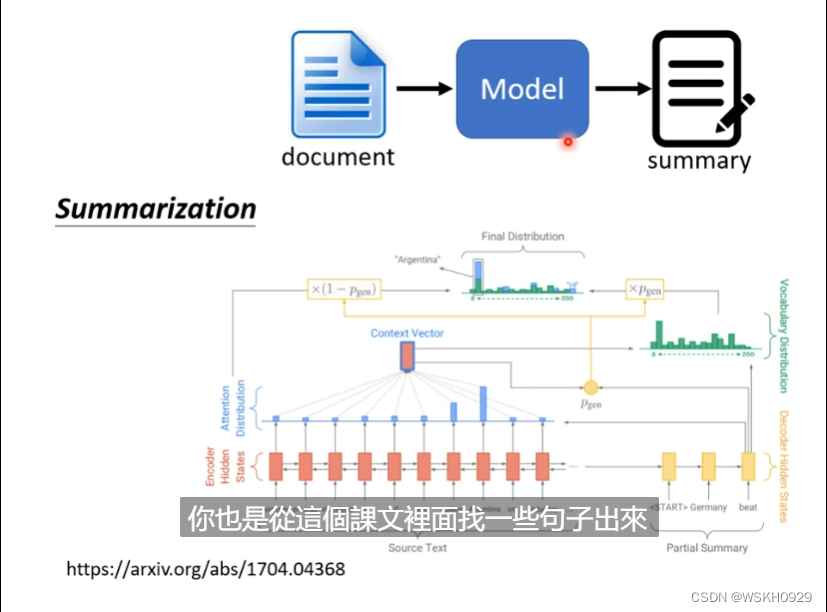
自动生成文章摘要:根据文章生成摘要的时候,其实摘要中大部分词汇都是从原文中复制的。
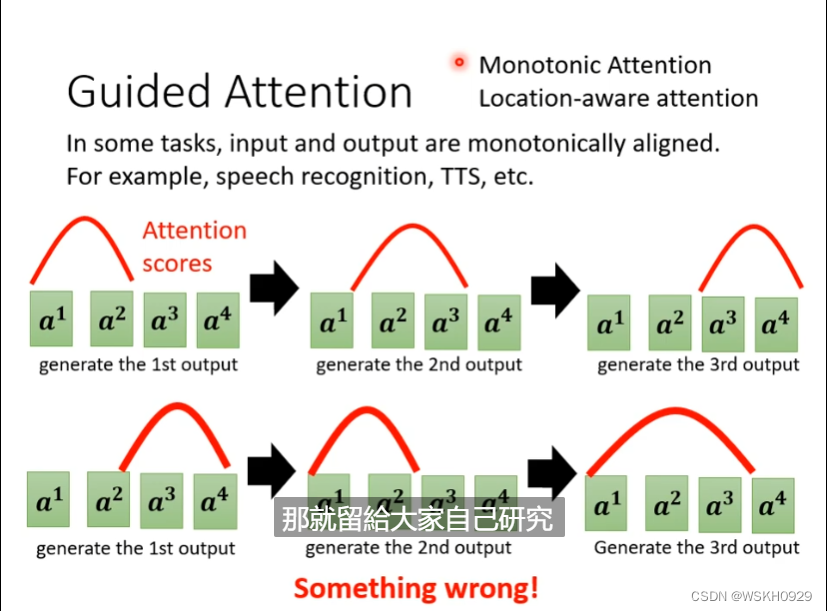
3.5.2 Guided Attention 引导性注意力机制
guided attention把该条件带入到attention的限制中,每当对齐的值偏离该对角线,就要对齐惩罚。
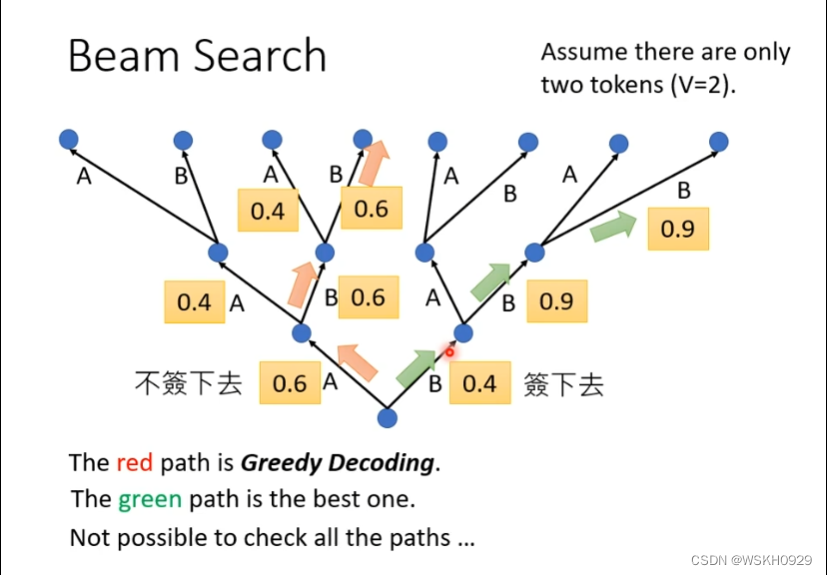
3.5.3 Beam Search
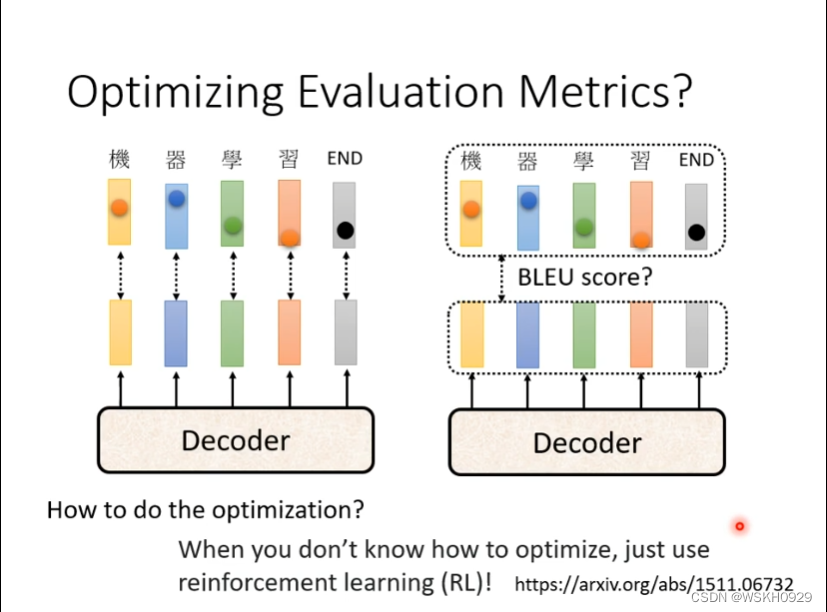
3.5.4 Optimizing Evaluation Metrics
3.5.4.1 BLEU Score评估模型
BLEU的全名为:bilingual evaluation understudy,即:双语互译质量评估辅助工具。它是用来评估机器翻译质量的工具。BLEU的设计思想:机器翻译结果越接近专业人工翻译的结果,则越好。BLEU算法实际上就是在判断两个句子的相似程度。想知道一个句子翻译前后的表示是否意思一致,直接的办法是拿这个句子的标准人工翻译与机器翻译的结果作比较,如果它们是很相似的,说明我们的翻译很成功。
BLEU Score的缺点是它不能微分。所以不能直接作为神经网络的损失函数进行梯度下降优化。遇到这种不能微分的函数,我们有一个方法,就是使用强化学习,将BLEU Score作为RL的奖励,Decoder作为RL的智能体,进行训练和学习。
3.5.5 Scheduled Sampling
之前我们说过,Train的过程中,我们会给Decoder输入正确的Label,但是这样有个缺点,就是在训练的时候,Decoder只看过正确的输入,所以可能在正确的输入下,它也能正确的输出,但是一旦有错误输出,它就很难得到正确的输出了,即很容易出现“一步错,步步错”的情况。
最简单的做法:为了缓解这种问题,我们可以在训练时就输入一些错误的Label给Decoder,以增强它的容错能力。
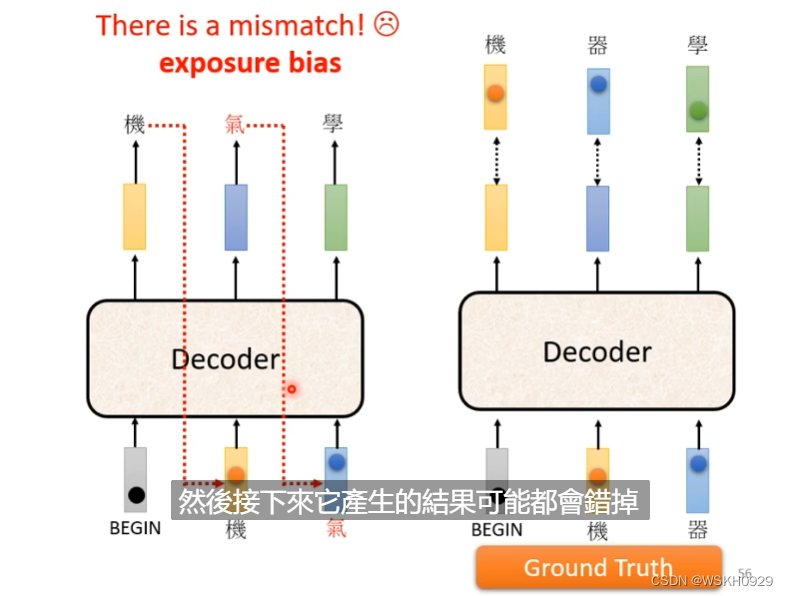
正如上面所说,标准的序列到序列模型中,如果序列前面生成了错误的元素,后面的输入状态将会收到影响,而该误差会随着生成过程不断向后累积。
Scheduled Sampling以一定概率将生成的元素作为解码器输入,这样即使前面生成错误,其训练目标仍然是最大化真实目标序列的概率,模型会朝着正确的方向进行训练。因此这种方式增加了模型的容错能力
















 2865
2865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











