







实验环境
Linux Ubuntu 16.04 前提条件:
1)Java 运行环境部署完成
2)Hadoop 的单点部署完成 上述前提条件,我们已经为你准备就绪了。
实验内容
在上述前提条件下,学习HDFS的架构原理与HDFS的启动与关闭操作
实验步骤
1.简介
Hadoop Distributed File System,Hadoop分布式文件系统
2.架构图
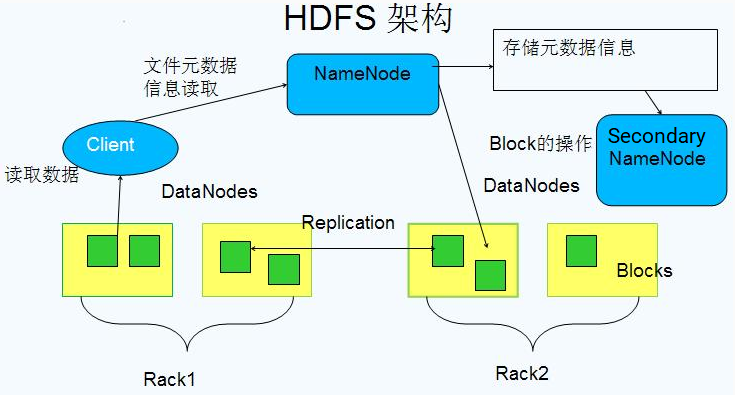
3.Block数据块
(1)基本存储单位,一般大小为64M(配置大的块主要是因为:1.减少搜寻时间,一般硬盘传输速率比寻道时间要快,大的块可以减少寻道时间;2.减少管理块的数据开销,每个块都需要在NameNode上有对应的记录;3.对数据块进行读写,减少建立网络的连接成本)
(2)一个大文件会被拆分成一个个的块,然后存储于不同的机器。如果一个文件少于Block大小,那么实际占用的空间为其文件的大小
(3)基本的读写单位,类似于磁盘的页,每次都是读写一个块
(4)每个块都会被复制到多台机器,默认复制3份
4.NameNode
(1)存储文件的metadata,运行时所有数据都保存到内存,整个HDFS可存储的文件数受限于NameNode的内存大小
(2)一个Block在NameNode中对应一条记录(一般一个block占用150字节),如果是大量的小文件,会消耗大量内存。同时map task的数量是由splits来决定的,所以用MapReduce处理大量的小文件时,就会产生过多的map task,线程管理开销将会增加作业时间。处理大量小文件的速度远远小于处理同等大小的大文件的速度。因此Hadoop建议存储大文件
(3)数据会定时保存到本地磁盘,但不保存block的位置信息,而是由DataNode注册时上报和运行时维护(NameNode中与DataNode相关的信息并不保存到NameNode的文件系统中,而是NameNode每次重启后,动态重建)
(4)NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性
5.Secondary NameNode
定时与NameNode进行同步(定期合并文件系统镜像和编辑日志,然后把合并后的传给NameNode,替换其镜像,并清空编辑日志,类似于CheckPoint机制),但NameNode失效后仍需要手工将其设置成主机
6.DataNode
(1)保存具体的block数据
(2)负责数据的读写操作和复制操作
(3)DataNode启动时会向NameNode报告当前存储的数据块信息,后续也会定时报告修改信息
(4)DataNode之间会进行通信,复制数据块,保证数据的冗余性
7.点击桌面的"命令行终端",打开新的命令行窗口
8.启动HDFS
启动HDFS,在命令行窗口输入下面的命令:
/apps/hadoop/sbin/start-dfs.sh运行后显示如下,根据日志显示,分别启动了NameNode、DataNode、Secondary NameNode:
dolphin@tools:~$ /apps/hadoop/sbin/start-dfs.sh
Starting namenodes on [localhost]
localhost: Warning: Permanently added 'localhost' (ECDSA) to the list of known hosts.
Starting datanodes
Starting secondary namenodes [tools.hadoop.fs.init]
tools.hadoop.fs.init: Warning: Permanently added 'tools.hadoop.fs.init,172.22.0.2' (ECDSA) to the list of known hosts.9.查看HDFS相关进程
在命令行窗口输入下面的命令:
jps运行后显示如下,表明NameNode、DataNode、Secondary NameNode已经成功启动
dolphin@tools:~$ jps
484 DataNode
663 SecondaryNameNode
375 NameNode
861 Jps10.打开浏览器
点击左下角的浏览器图标,打开火狐浏览器
11.访问HDFS webUI
在浏览器输入 localhost:9870 ,回车后进入HDFS webUI界面,如下图所示:
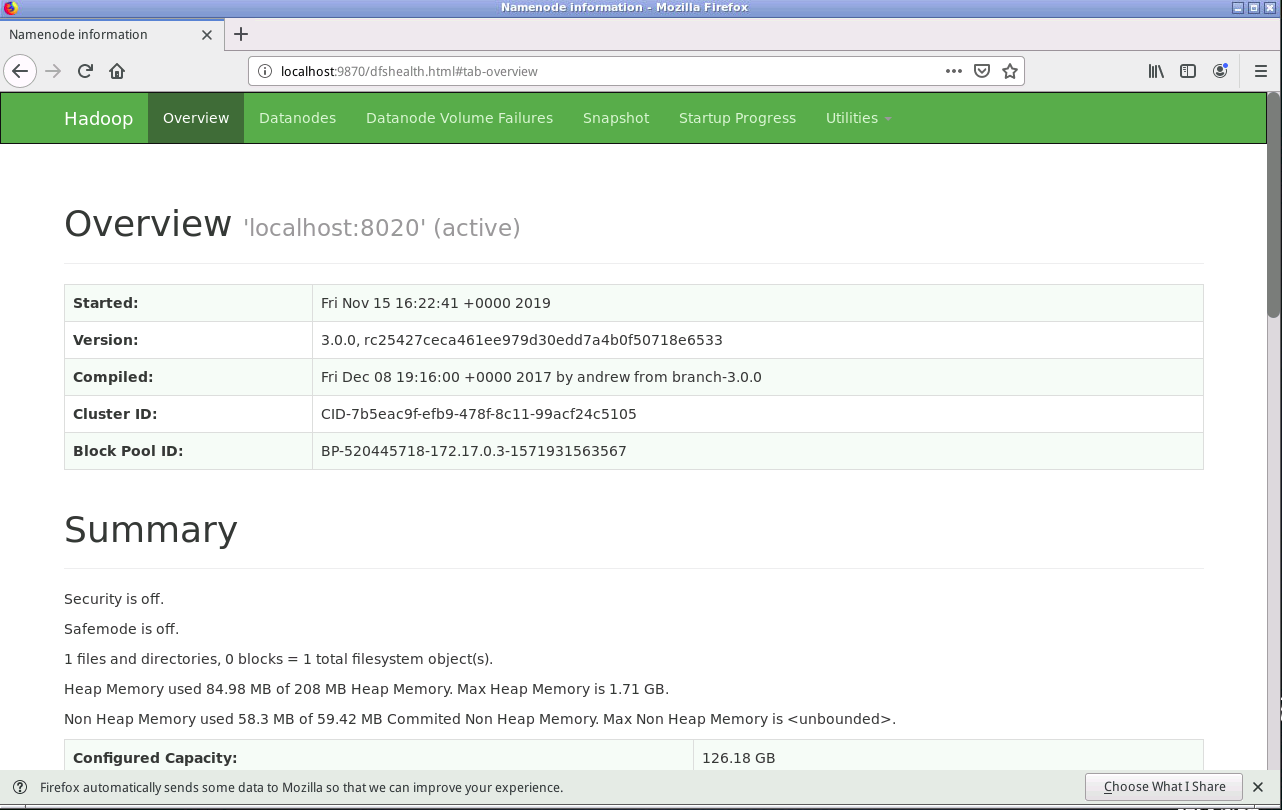
在这里可以看多HDFS很多信息,例如NameNode状态信息,DataNode数量与状态,容量大小等,还可以直接进行操作。
12.HDFS的关闭
回到命令行窗口,运行下面的命令:
/apps/hadoop/sbin/stop-dfs.sh运行后显示如下:
dolphin@tools:~$ /apps/hadoop/sbin/stop-dfs.sh
Stopping namenodes on [localhost]
localhost: WARNING: namenode did not stop gracefully after 5 seconds: Trying to kill with kill -9
localhost: ERROR: Unable to kill 375
Stopping datanodes
localhost: WARNING: datanode did not stop gracefully after 5 seconds: Trying to kill with kill -9
localhost: ERROR: Unable to kill 484
Stopping secondary namenodes [tools.hadoop.fs.init]
tools.hadoop.fs.init: WARNING: secondarynamenode did not stop gracefully after 5 seconds: Trying to kill with kill -9
tools.hadoop.fs.init: ERROR: Unable to kill 663此时,HDFS的所有进程都已经关闭。至此本实验结束啦,开始下一个实验吧。















 2617
2617











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









