







17.4 输入输出流–文件操作与文件流
文章目录
4.1 文件的分类
- 按数据的组织形式可以分为ASCII码文件与二进制文件:
例如:
存储int型整数100000,前者为6byte,后者4byte;
double型双精度数123.45,前者分别存储6个字符(‘1’,‘2’,‘3’,’.’,‘4’,‘5’)6byte,后者为double 8byte.
- C++对文件的访问可以分为:低级I/0(字符流方式I/O),高级I/O(转换为数据指定形式I/O)
4.2 文件流类与文件流对象
- 与磁盘文件有关的流类:
输入:ifstream类,派生自istream类
输出:ofstream类,派生自ostream类
输入/输出:fstream类,派生自iostream类
4.3 文件的打开与关闭
#include <fstream>
ofstream out1("../aa.dat",ios::out|ios::app);
/*另一种方式*/
ofstream out2;
out2.open("../aa.dat",ios::out|ios::app);
打开方式(用位或’|'组合):
| 方式 | 作用 |
|---|---|
| ios::in | 输入方式 |
| ios::out | 输出方式(默认方式),如果已存在该名称文件:清空原有内容 |
| ios::app | 输出方式,写入数据添加于文件末尾 |
| ios::ate | 打开一个已有文件,文件指针指向文件末尾 |
| ios::trunc | 打开一个文件,若已存在,则删除其中全部数据;若不存在,则建立新文件.如果已经指定ios::out方式,而未指定ios::app,ios::ate,ios::in,则同时默认此方式 |
| ios::binary | 二进制方式打开,否则默认ASCII方式 |
| ios::nocreate | 打开已有的文件,若不存在,则不建立新文件打开失败 |
| ios::noreplace | 若文件不存在则建立新文件,若存在则操作失败,不更新替代原有文件 |
- 注意:
- DevC++和Linux下不支持nocreate和noreplace,VS下写为_Nocreate,_Noreplace
- 目录分隔符建议使用’/’,Linux/Windows均适用.
- 打开方式需要兼容,例如:ifstream对象以ios::out形式打开无意义,认为ios::in.
- 判断打开成功:
if(!out1) if(out1.is_open()==0) out1.close();
4.4 对ASCII文件的操作
基本与cin/cout相同,且可以使用get/getline/put/eof/peek/puchar/ignore等成员函数.同时对空格/回车等等处理方式也相同.事实上流插入流提取已经对二进制数据做了十进制处理.
- 一个关于eof的辨析:
文件共5字节大小:内容为12345
#include <iostream>
#include <fstream>
using namespace std;
int main()
{
ifstream in;
char ch;
in.open("D:/f1.dat", ios::in);
/*省略is_open()*/
int cnt = 0;
while (!in.eof()) {
in.get(ch);
putchar(ch);
cnt++;
}
//while ((ch = in.get()) != EOF)
//{
// putchar(ch);
// cnt++;
//}
cout << '\n' << cnt;
in.close();
return 0;
}
执行结果1:
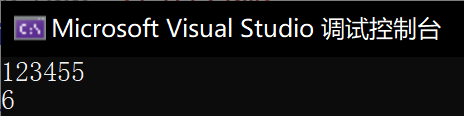
执行结果2:

可以简单理解文件中内容为:1 2 3 4 5 EOF,按1方式,in只有读到(get)EOF之后才会置eof为1.方法二最终ch为-1,但方法一为’5’.
- 接上:
char ch;
ifstream in("D:/f1.dat", ios::in);
ofstream out("D:/f2.dat", ios::out);
/*省略打开成功判断*/
/*方法一会比源文件多输出FF(-1)*/
while (!in.eof()) {
ch = in.get();
out.put(ch);
}
//while (in.get(ch))
// out.put(ch);
综上,还是推荐 (ch = in.get()) != EOF 这种判断写法.
4.5 对二进制文件的操作
ASCII读写存在两个问题:
- 仅能按照字节读写
- 若文件中有字符’0x1A’则无法继续读取(文本文件不可能有)
- 一般用read/write进行二进制读写的操作:

- 与指针相关的流成员函数:
| 输入 | |
|---|---|
| gcount() | 返回最后一次读入的字节数.read参数中的长度为最大读取长度,并非实际读取长度,用gcount()可知真实读取字节数. |
| tellg() | 当前指针位置,按get记忆 |
| seekf(位移量,位移方式) | 移动指针 |
| 输出 | |
| tellp() | 当前指针位置,按put记忆 |
| seekp(…) | … |
| 位移方式 | |
| ios::beg | 从头位移量为正 |
| ios::cur | 从当前 |
| ios::end | 从尾,位移量为负 |
fstream的tellg和tellp是同步的.
4.6 差异比较
1. 不同方式下输出endl
十进制方式写(ios::out):endl在Windows下为’\r’ ‘\n’ 在Linux下为’\n’;
二进制方式写(ios::out|ios::binary)均为’\n’
2. 不同方式下读取"\r\n"
十进制读(ios::in),Windows下"合二为一",视为’\n’,即一个字符处理;
二进制读(ios::in|ios::binary),Windows仍为"\r\n"
3. >>和getline()
差别就是>>识别’\r’或’\n’,遇之结束读取不丢弃,getline识别’\n’为止,读完’\n’丢弃之.
全部以十进制方式读写:
读取输出的fout<<“hello”<<endl,实际上读取的内容为"hello\n",
- char buf[80];
fin>>buf;
cout<<in.peek()<<endl;
这种方式读到"hello"结束,’\n’留在缓冲区(同cin),peek()输出’\n’;- fin.getline(buf,80);
这种方式尽管strlen(buf)也为5,但是’\n’被读掉,未入buf,但也不在缓冲区了,此时in.peek()读到EOF返回-1.
十进制写,二进制读,即测试"\r\n",仍然按上述方式来:
- fin.peek()读到’\r’,缓冲区此时为’\r’ ‘\n’;
- fin.peek()读到EOF,缓冲区’\n’被读走并丢弃,此时buf中的字符串长度strlen()首次变为6,即"hello\r"
4. 十进制方式下写入特殊字符的测试
均在 ios::out 方式下
- 写入含’\0’的文件
out<<“ABC\0\x61\x62\x63”<<endl;
最终结果Windows下为"ABC\r\n",Linux少一个’\r’,说明out遇\0视为字符串的结束.
- 写入非图形字符
out<<“ABC\x1\x2\x1A\t\v\b\xff\175()-=def”<<endl;
最终结果Windows下文件大小20字节,即一字不拉的输出了,而Linux下19字节,理由同前.说明非图形字符不影响输出,但不应包含\0.
- 写入’\x1A’ (Ctrl+Z)
实际上写入不存在任何问题,和写入非图形字符是一样的;
读取时,注意只有Windows下的ios::in(十进制方式)才会将’\x1A’特殊处理为EOF,Windows二进制读和Linux下均不存在该问题!
- 写入’\xFF’ (-1)
这是一个很有意思的区别:- in加上binary也一样:

- in加上binary也一样:

为啥后者会被\xff截断而前者不会?其实道理也很简单,因为in.get()实际上返回的是int型值,而非char型值,因此读入\xff实际上返回的是255而非-1.这个地方需要多加注意,尤其是字符方式读取非文本文件时,常常会出现超出ASCII范围的值,需要考虑是不是应该使用int代替char.
- in加上binary也一样:
5. 对read()的一些辨析
- 对比格式化读>>和read()
- in>>读入字符串和cin并无区别,读到’\n’或’\r’停止,并自动添加’\0’;read()方式不会管你这些’\n’’\0’的规则,因此若不人工管一管尾0,再使用<<输出时会越界;
- 此外,tellg两种方式都有效,gcount仅对read有效;
- read()读取的大小超出文件长度时,以gcount为准可知实际读取的长度,tellg()置为-1,good()置为0.这点和sstream是一样的.此时若不重新置位(in.clear()),之后的tellg()/seekg()/gcount()均不可信.
if(!in.good()) in.clear();
- 若读取不超过文件长度,则good()为1,tellg()为实际位置.
- 若同时使用ios::in|ios::out,这两个指针将完全同步,使用其一即可.
6. 对ios::app的一些辨析
加入ios::app后,尽管seekg()/seekp()可以移动文件指针,但是写入的位置始终位于文件的末尾.















 3551
3551











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









