







本篇主要总结了为MIPS指令集的两种不同实现方式分别建立数据通路和控制单元:单周期设计和流水线设计。
文章目录
前言
对MIPS指令集实现的最终设计,非一日之功。在学习的时候,可以把它想象成没有精确图纸的盖房子工程,先设计一个雏形,遇到需求和问题,再一点一点增添修改,最终盖好一个比较皆大欢喜的房子。以下将总结它的最终设计是怎样的(每个部分分别有什么功能)、具体是如何实现MIPS的核心指令的,以及最终设计的一些很amazing的地方,和其从0到1的大体的思路历程
一、单周期实现
1.何为 单周期实现
即一个时钟周期执行一条指令的实现机制。它的时钟周期对所有指令是一样的,故由执行时间最长的那条指令决定。显然它造成了一些部件的等待浪费,效率太低,总体性能不太好。
2.如何实现
实现每条指令的前两步都是一样的,PC先指向指令所在的存储单元,并从中取指令,通过指令段内容选择读取一个或两个寄存器。
(1)部件图
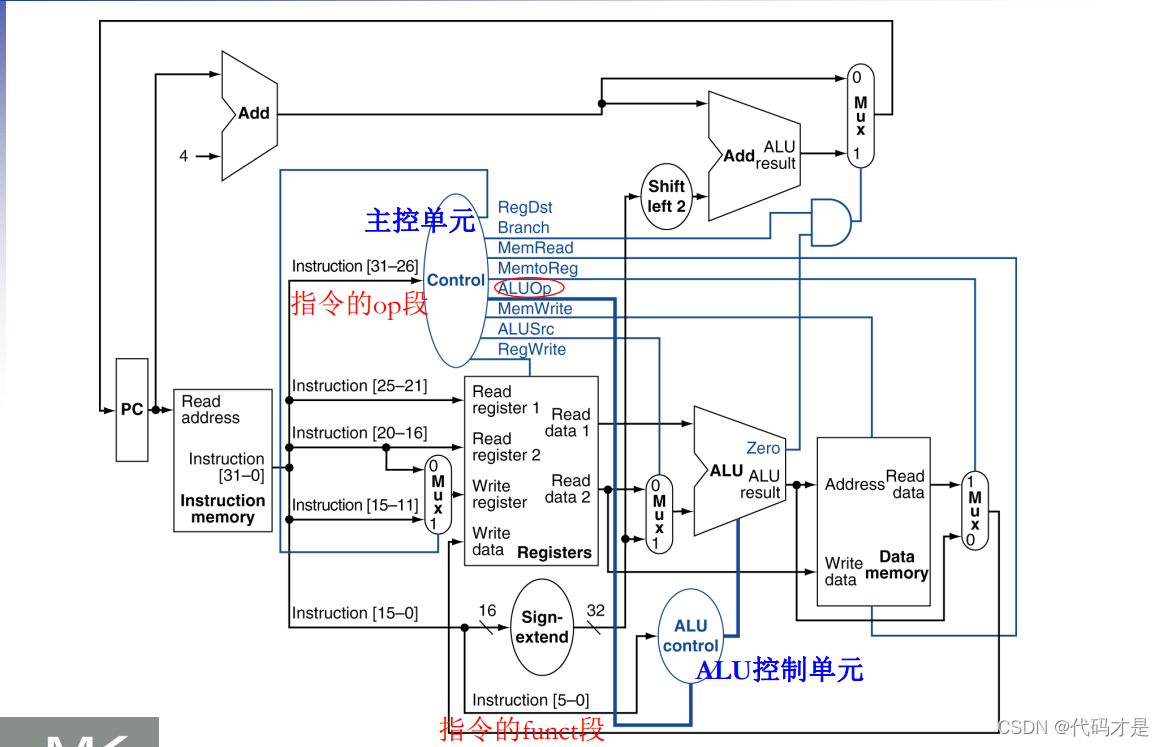
注:jump指令在此基础上于branch add后增加了一个mux
(2)部件分类:
- 组合单元:一个操作单元,输出只取决于输入。上图中的ALU,ADD,mux,sign-extend,shift-left 2,control,ALU control。
- 状态单元:一个存储单元。上图中的Instruction memory, registers, data memory。
其中几个部件的介绍:
- PC:存放指令地址,每次当前指令运行时,都会向PC写入下一条指令地址,要么是PC+4,要么是条件分支的地址,要么是一个无条件分支的立即数
- sign-extend:符号扩展偏移量。为增加数据项的最高位复制到新数据项多出来的高位。
- shift-left 2:将符号位扩展后的偏移量左移2位,以指示以字为单位的偏移量,这样偏移量的有效范围就扩大了4倍。
- control:主控单元。这个单元会根据指令的OP段产生以下 7个控制信号,每个信号占1位:(这里没有包含 ALUOP)
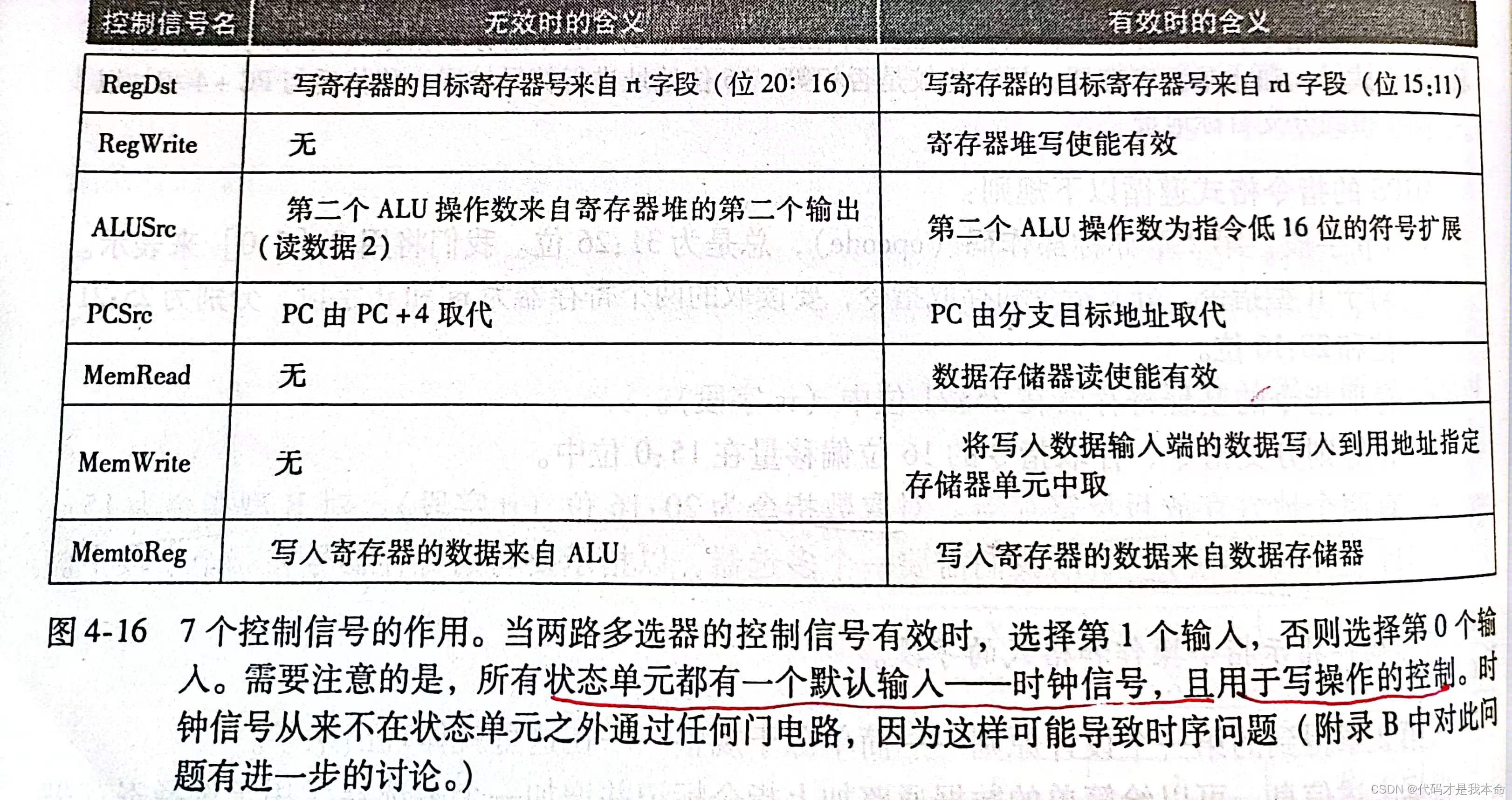
注:这里的 PCsrc 在部件总图中没写,是因为它等于 Branch信号 与 ALU的零输出信号(判断条件分支时,是直接两个寄存器值相减,为0则代表相等,来判断分支)的 “与” 结果。
ALU控制信号:占4位。用以告诉ALU(即部件总图中的ALU control)应该执行什么运算操作。ALU控制信号是由2位 ALUOP 和6位的 funct字段 决定的:

(3)具体怎样实现MIPS核心指令
-
R型指令:(灰色部分代表没有使用)
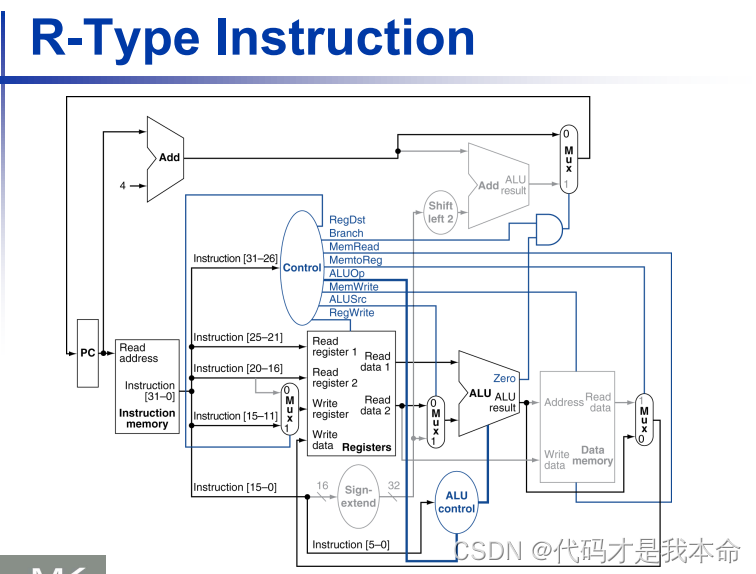
-
数据存取指令:
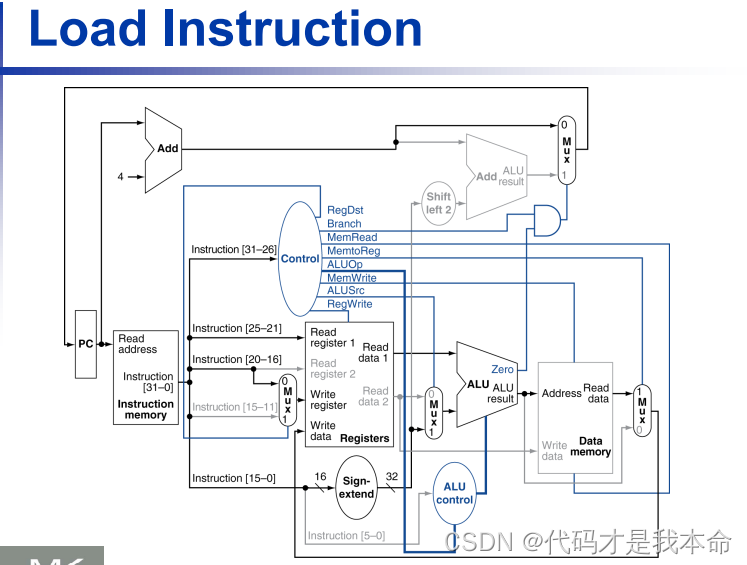
-
条件分支指令:
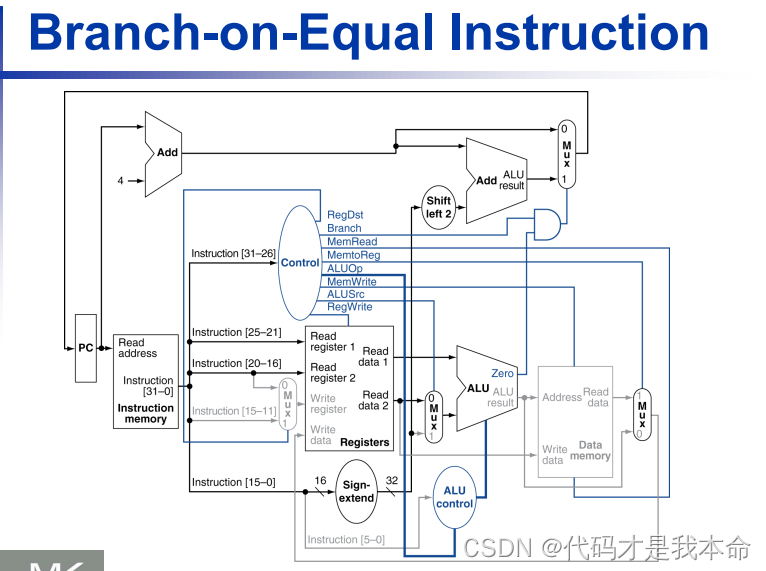
-
无条件跳转指令:
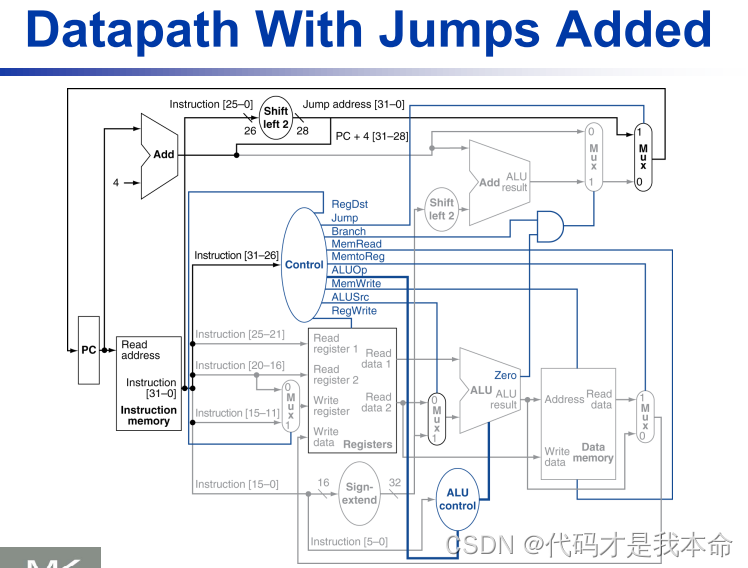
二、流水线实现
1.选它的原因
就像前面介绍单周期实现方式的缺点时说的那样,一个时钟周期执行一条指令效率太低,代价很大,尽管它对小指令集来说或许可以接受,但对于要实现包含浮点数或更复杂指令的指令集,根本不能胜任。
而流水线设计不同。
流水线:一种实现多指令重叠的技术,与生产流水线类似。它把每条指令分成固定的几个步骤(尽管有些指令不完全执行),尽可能榨干流水线上的每个“工人”,实现效率最大化。但流水线
通常,一个MIPS指令包含以下5个处理步骤:
1)IF: 从指令存储器中读取指令(Instruction Memory)
2)ID: 指令译码的同时读取寄存器。MIPS的指令格式允许同时进行指令译码和读寄存器。(Registers)
3)EX: 执行操作或计算地址(ALU)
4)MEM: 从数据存储器中读取操作数(Data Memory)
5)WB: 将结果写回寄存器(Registers)

单周期设计 vs 流水线设计(以下例为例)
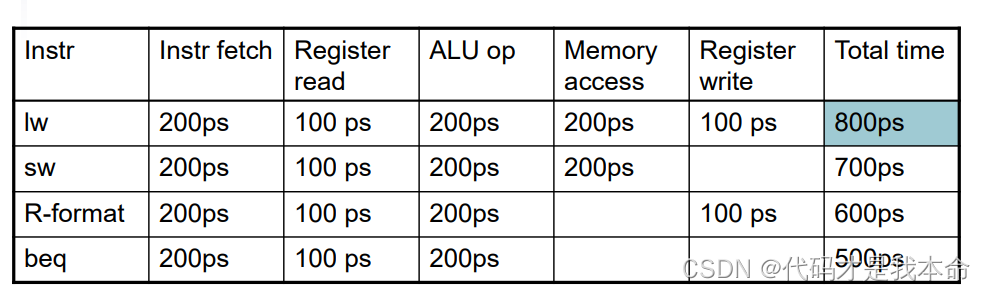

.
.
2.流水线实现总图
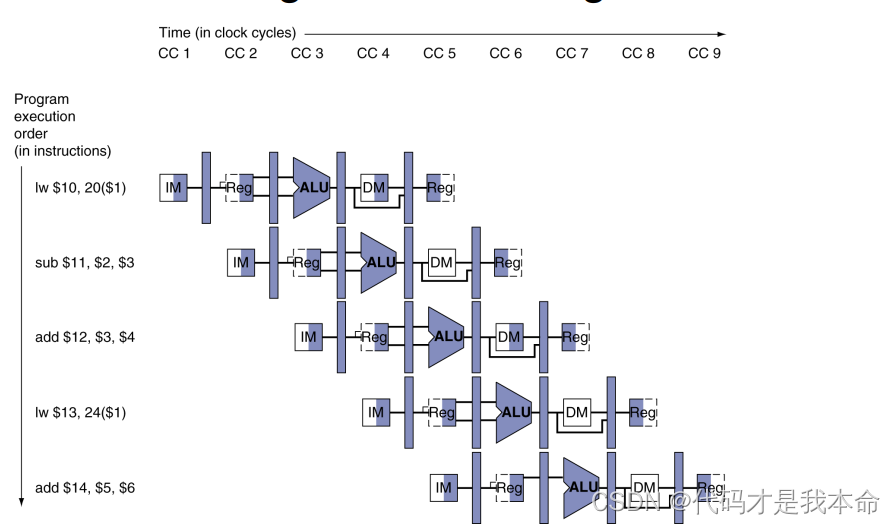
(1)多时钟周期流水线图:
当寄存器或存储器被读取时,在图中阴影表示右半部分;被写入时用阴影表示左半部分。
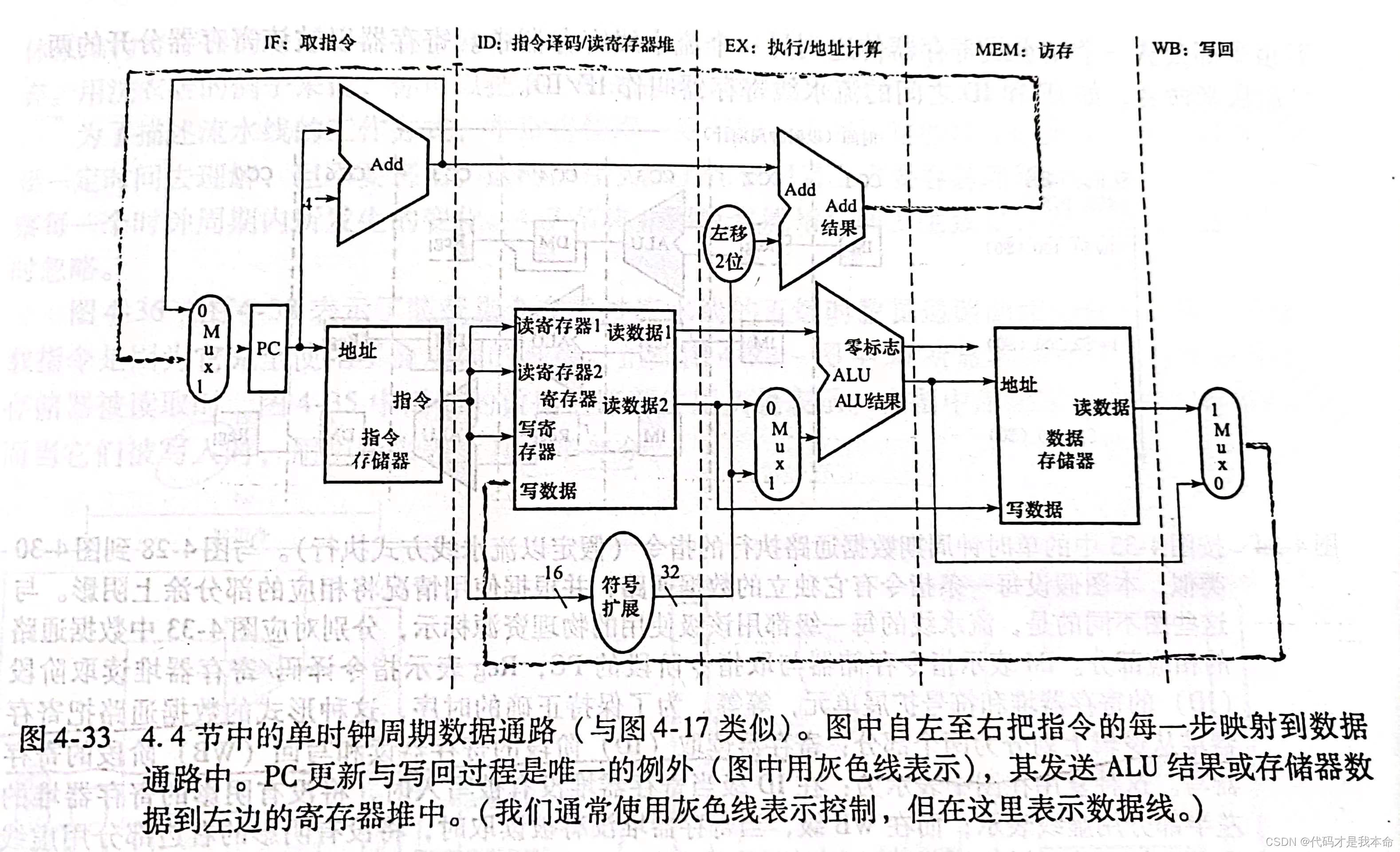
(2)单时钟周期流水线数据通路:
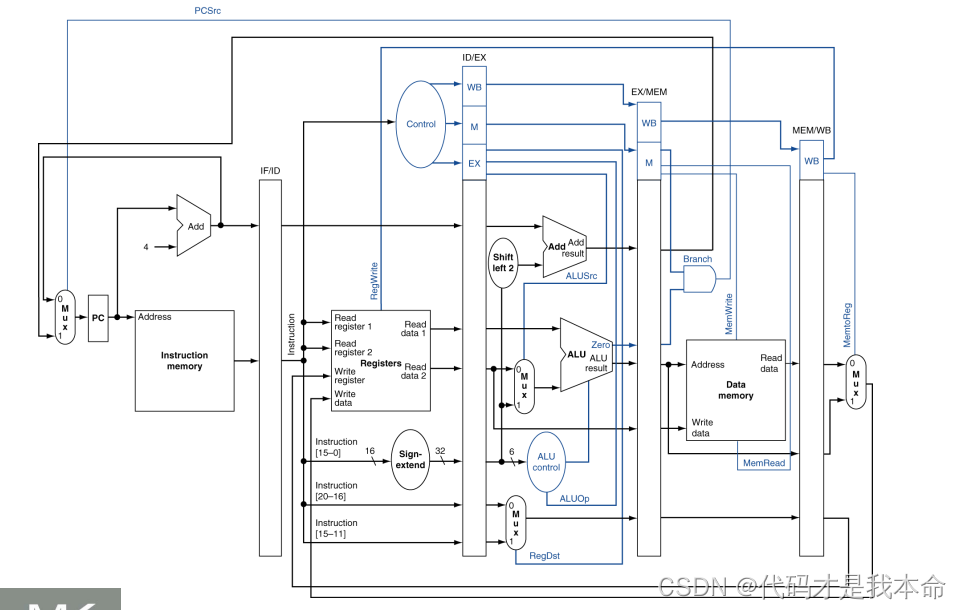
(3)相关部件介绍:
和单时钟周期设计比较,把结构按照5个步骤进行了划分,并且新增了4个流水线寄存器。
在下图的基础上划分:
流水线寄存器:
为什么要增加它:运行n条指令似乎要n条数据通路,因为每条指令所用到的数据都有所不同,混在一起会覆盖数据,造成指令异常。那何不增加几个寄存器来存储中间数据,这样指令执行过程中就可以共享数据通路,n条指令就只需要1条数据通路即可了。
例如,指令存储器只在每条指令的第一个步骤用到,假如有3条指令,当指令1运行到步骤2时,指令存储器就空出来了,指令2就可以去用指令存储器,但是,在此之前,必须要先把指令1放在指令存储器里的数据copy一份传给IF/ID级流水线寄存器,指令1后面还要用到该数据,然后再由指令2去使用指令存储器,去覆盖掉原有的数据。后面几个步骤类似,都是把数据一步一步往下一个流水线寄存器传递。
大小:
IF/ID寄存器:64位。32位指令+32位PC自增地址
ID/EX寄存器:128位。符号扩展后的32位偏移量+32位PC自增地址+32位寄存器1的数据+32位寄存器2的数据
EX/MEM寄存器:97位。32位Branch Add结果+1位ALU零标志+32位ALU结果+32位寄存器2的数据
MEM/WB寄存器:64位。32位从数据存储器读出的数据+32位不需要经过数据存储器的值
控制信号:
由于采用流水线方式的数据通路不会改变控制信号的意义,因此可以使用与简单数据通路相同的控制信号,故在上述流水线寄存器的大小的基础上进行了扩展。
同样的,控制信号也需要通过流水线寄存器层层传递,每个流水级使用相应的控制信号,并将剩余的控制信号传递给下一个流水级:
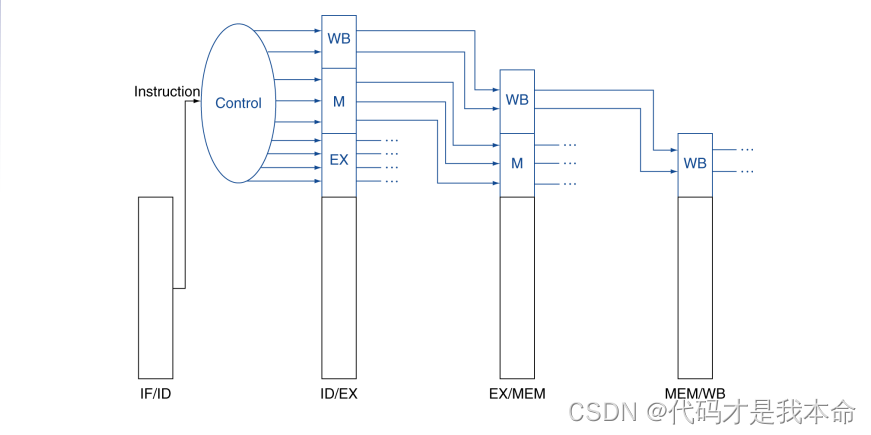
.
.
.
3. 产生的问题:流水冒险
1.结构冒险
即硬件不支持流水线(多条指令在同一时钟周期执行)。比如洗衣店例子里的洗衣烘干是一体机,不能把两个步骤分开运行,就会发生结构冒险。
.
.
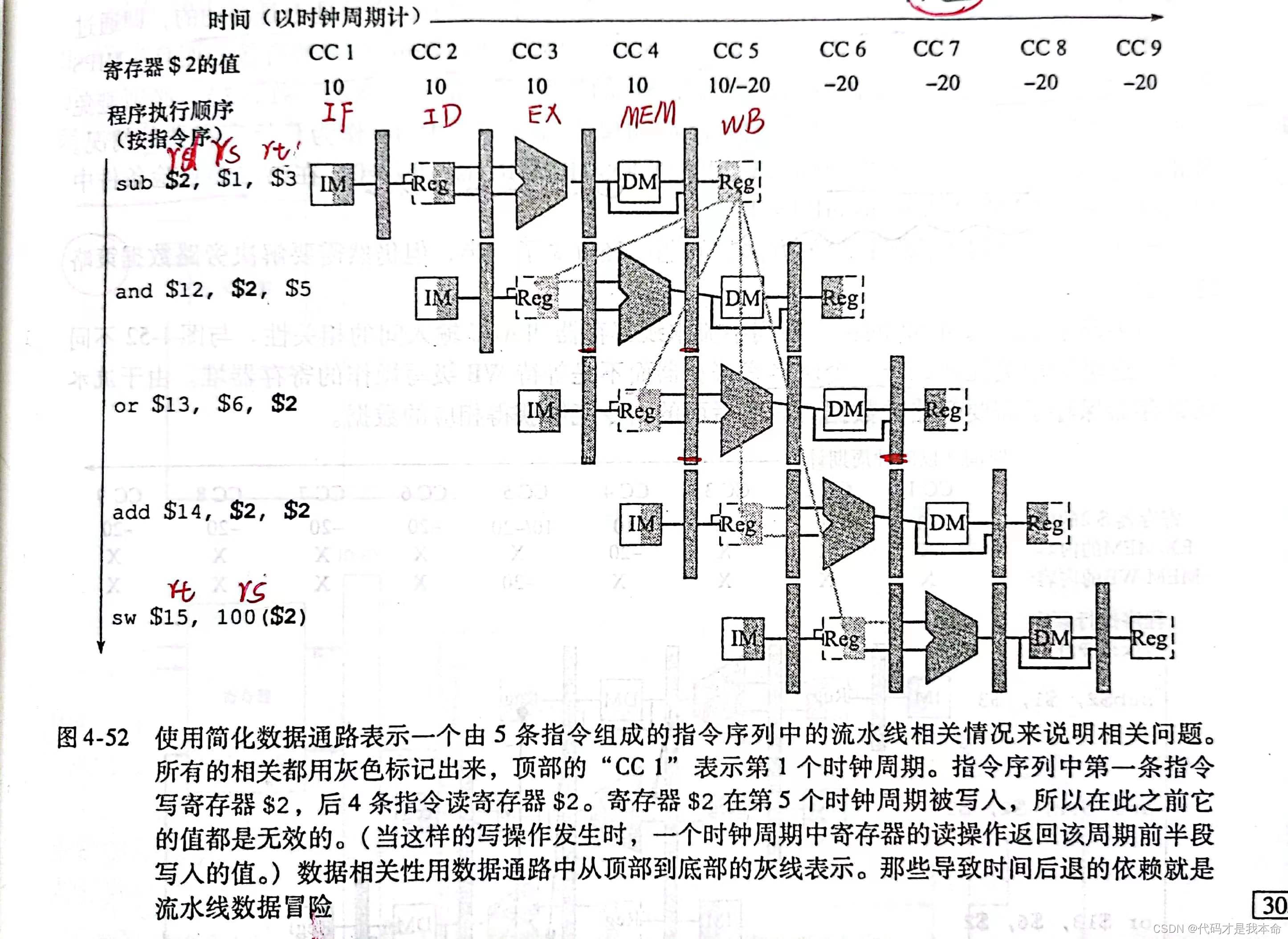
2.数据冒险
定义:因无法提供指令执行所需数据导致指令不能再预定的时钟周期内执行的情况。具体来说就是由于一条指令必须等待另一条指令完成来获得所需数据而造成流水线暂停的情况。
例如:

解决:旁路和阻塞
旁路
既然下一条指令要等待上一条指令通过 ALU 计算出的数据,那何不在其一计算出来就弄一根线把它传到下一条指令要用到的位置,这样就不用等到它写入寄存器再去取。当然这个方法能解决大多数指令的数据冒险,但对某些指令不行(这些需要另一个方法:阻塞)。
我们让流水线寄存器保存需要旁路的数据,这样后面的指令都能获得相应的数据。
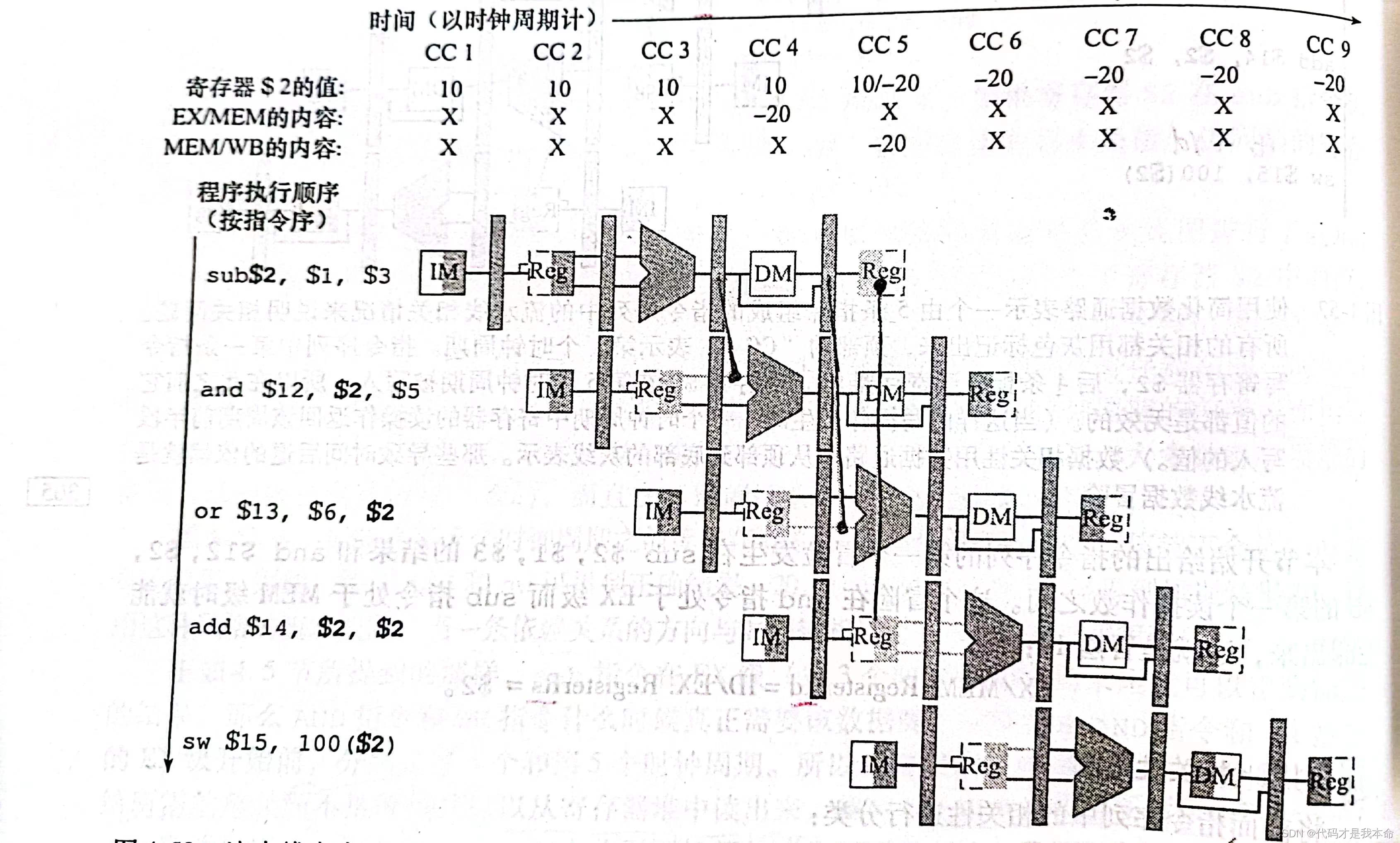
.
为了更直观更精确的表示冒险条件,我们采取了流水线寄存器字段,通俗来说,就是在寄存器号前加一个表示它来自哪个流水线寄存器的前缀标号,比如 EX/MEM.RegisterRd 。观察总结后,数据冒险要至少满足以下4个冒险条件之一:
//两条指令紧接着,例如上图中的 sub 和 and 指令
1a. EX/MEM.RegisterRd=ID/EX.RegisterRs
1b. EX/MEM.RegisterRd=ID/EX.RegisterRt
//两条指令中隔了指令,例如上图中的 sub 和 or 指令
2a. MEM/WB.RegisterRd=ID/EX.RegisterRs
2b. MEM/WB.RegisterRd=ID/EX.RegisterRt
.
接下来解决旁路数据策略的问题,即光把数据全传给流水线寄存器是不够的的,要用它还需要控制选择。同控制单元的设置一样,我们还是利用控制信号和几个多选器来完成这一过程。
下图中,相比之前的,为了支持旁路,在ID/EX级流水线寄存器中增加了指令的 rs (25-21位)段。
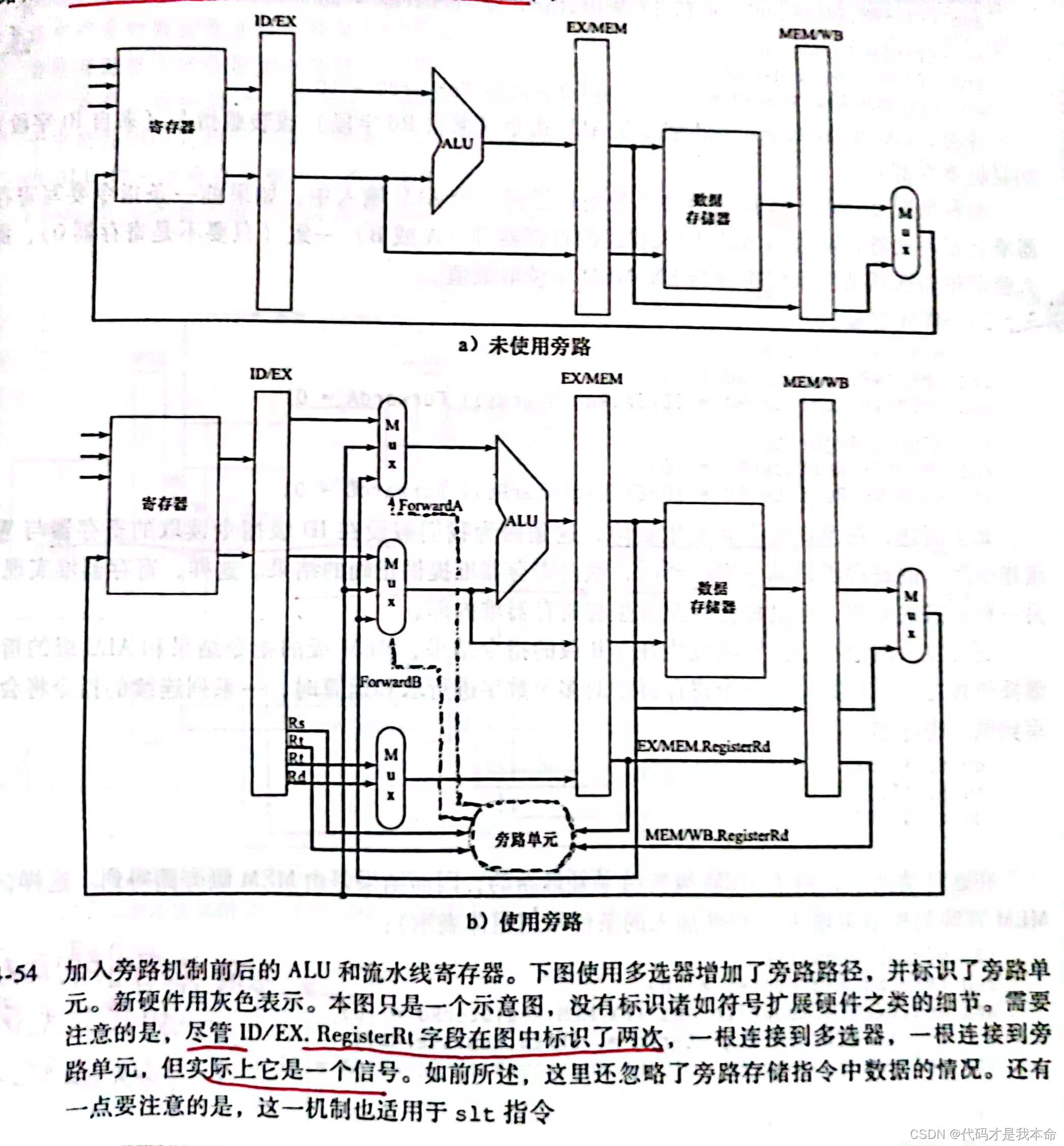
图中的旁路单元同控制单元一样,通过指令的某部分(ID/EX.RegisterRs,ID/EX.RegisterRt,EX/MEM.RegisterRd,MEM/WB.RegisterRd)来确定控制信号(ForwardA,ForwardB)的值,从而控制相应多选器 MUX 的选择,最终达到决定 ALU 的两个操作数来自哪里(寄存器堆/数据储存器/上一个ALU运算结果旁路得到)。具体的逻辑实现用到了前面的冒险条件判断。
.
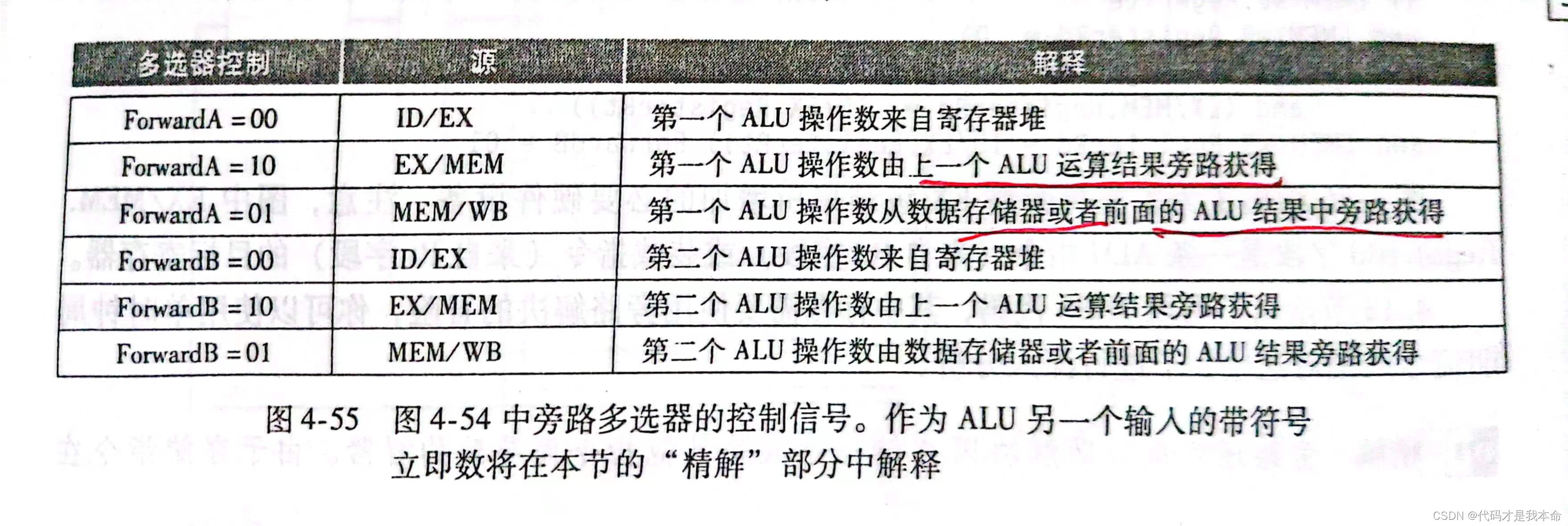
控制信号取值及其含义如下图:
.
.
至此,我们大概知道了,每条指令在译码后并不会直接就流水线运行,还需要先判断它和前两条指令是否存在冒险,如果存在,那么就要设置相应的控制信号的值,来控制ALU的输入,避免冒险。
具体检测冒险以及解决冒险的方法如下:
//1)EX 冒险(1a,1b)
if(EX/MEM.RegWrite
and(EX/MEM.RegisterRd!=0)
and(EX/MEM.RegisterRd = ID/EX.RegisterRs)) ForwardA = 10
if(EX/MEM.RegWrite
and(EX/MEM.RegisterRd!=0)
and(EX/MEM.RegisterRd = ID/EX.RegisterRt)) ForwardB = 10
//2)MEM 冒险(2a,2b)这个是比较简单的冒险,即中间隔着的那条指令和此条指令没有冒险,它只跟上上条冒险
//sub $2,$1,$3
//and $12,$2,$5
//or $13,$6, $2
if(EX/MEM.RegWrite
and(EX/MEM.RegisterRd!=0)
and(MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01
if(EX/MEM.RegWrite
and(EX/MEM.RegisterRd!=0)
and(MEM/WB.RegisterRd = ID/EX.RegisterRt)) ForwardB = 01
//复杂版MEM 若此条指令和上一条也有冒险怎么办,比如:
//add $1,$1,$2
//add $1,$1,$3
//add $1,$1,$4
//可以知道,这种情况下MEM级结果是最新的,第三条指令应该旁路第二条的MEM级,而非第一条
if(EX/MEM.RegWrite
and(EX/MEM.RegisterRd!=0)
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd!=0)//新增
and(EX/MEM.RegisterRd != ID/EX.RegisterRs))//新增
and(MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01
if(EX/MEM.RegWrite
and(EX/MEM.RegisterRd!=0)
and not(EX/MEM.RegWrite and (EX/MEM.RegisterRd!=0)//新增
and(EX/MEM.RegisterRd != ID/EX.RegisterRt))//新增
and(MEM/WB.RegisterRd = ID/EX.RegisterRs)) ForwardA = 01
//新增指令的含义:判断中间间隔的那条指令和此条有无冒险,有的话就就近,此条指令旁路前一条
解释相关含义:
-
目的:
EX冒险:如果前一条指令要写寄存器堆且要写的寄存器号与ALU要读的寄存器号(rs或rt)一致,那么就调整多选器的这从流水线寄存器EX/MEM中读取。(比如前面的:sub $2,$1,$3 and $12,$2,$5) -
if(EX/MEM.RegWrite:由于数据冒险只在指令有写回寄存器的操作时才会发生,所以为了避免一些不必要的旁路,先检测 RegWrite 信号是否活动(具体是通过 EX/MEM级 的流水线寄存器的 WB 控制字段确定 RegWrite 的)
-
and(EX/MEM.RegisterRd!=0):由于MIPS要求 $0 寄存器的值始终为0,它不能作为目标寄存器进行写。所以要先进行判断该目标寄存器是不是 $0 ,是的话就不能把其结果按非0值旁路。
.
.
阻塞
前面讲旁路的时候提到,有些指令光靠旁路无法解决冒险问题,需要用 阻塞 来解决。比如需要去内存中的数据存储区取到值才能用的 lw 指令:
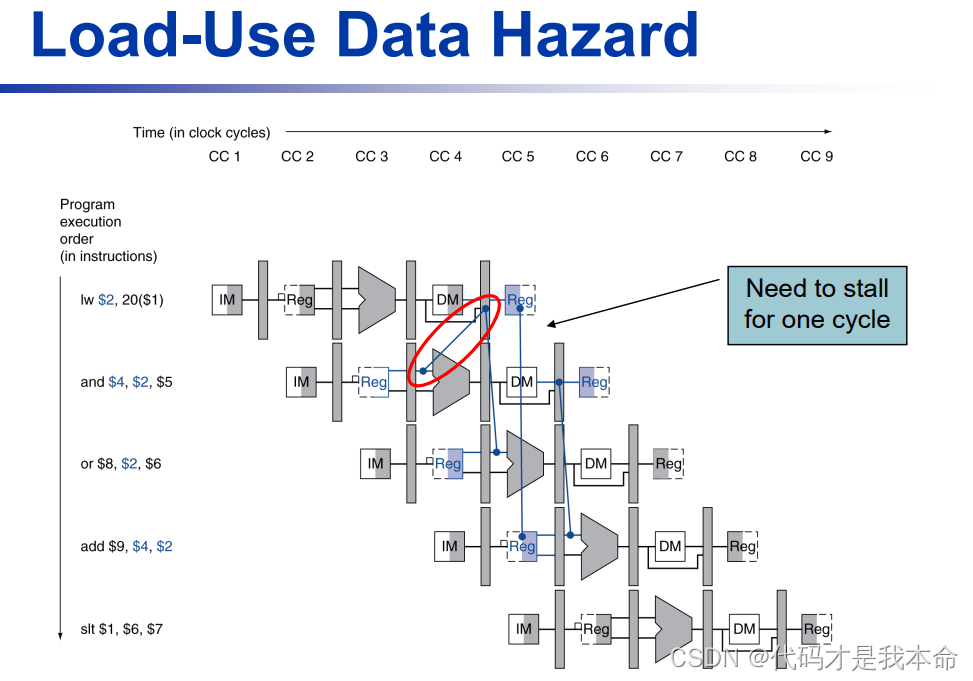
如上图所示,lw 和 and 指令之间存在数据冒险,但旁路也无法解决,必须要采用相应的机制阻塞流水线,直到这条指令得到数据。
因此,除了一个旁路单元,还需要一个冒险检测单元,它工作在ID级,从而可以在 lw 指令与 紧随其后需要它结果的指令间插入阻塞。以上图为例,add指令在 CC4 阻塞,等 lw 指令执行到 CC5 再从原来位置启动。
//该冒险单元的控制满足以下条件
if(ID/EX.MemRead and //检查是否是lw指令
((ID/EX.RegisterRt = IF/ID.RegisterRs)) or
(ID/EX.RegisterRt = IF/ID.RegisterRs))
stall the pipeline
如果满足条件,就会阻塞一个周期,然后就能正常用旁路了。需要注意的是,比如上图的and指令阻塞时,and之后所有的指令都会相应阻塞(可以由 冒险控制单元 通过保持PC寄存器和IF/ID级流水线寄存器内容内容不变来实现)。
加入冒险控制单元后的流水线图:
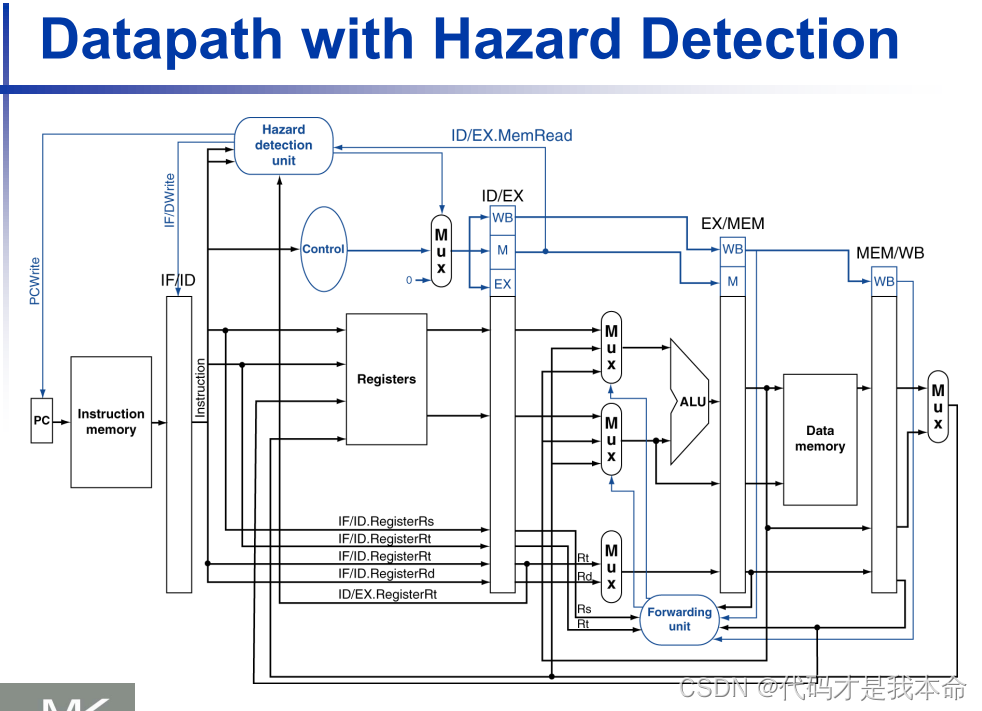
其中冒险控制单元的功能:
通过控制PC和IF/ID级流水线寄存器的写入,以及在实际控制信号与全0中进行选择的多选器(实现插入空指令)来实现阻塞。
.
.
.
3.控制冒险
控制冒险主要是分支指令引起的,因为MIPS中,条件分支指令需要等到MEM级才能确定是否执行分支,故它对流水线会产生影响,不处理的话,分支指令后面的指令会执行直到分支指令在MEM级确定是否执行。
书上写的主要有32不算太好的处理方法,不知道目前有没有提出新的方法。分别是 缩短分支的延迟时间和 分支预测。
.
缩短分支的延迟
就是将本来要在MEM级才能确定分支结果改进为提前几级知道。具体做法感兴趣的可自行查阅资料。
分支预测
假定分支不发生
该方法算是比较粗略的分支预测方法。总是预测分支不发生,如果错误就清空流水线。
动态分支预测
就是通过查找指令的地址,观察上一次执行该指令时分支是否发生,如果发生,就假设这次也发生,从上次分支的地方开始取新的指令。如果预测错误的话,就删除预测错误的指令,返回原来的位置,正确执行。
可以想到,如果一条分支指令几乎总是发生,那么预测将总是错误。
.
.
小结
处理以上流水线冒险后的流水线总图:(此图省略了一些符号位扩展等硬件)
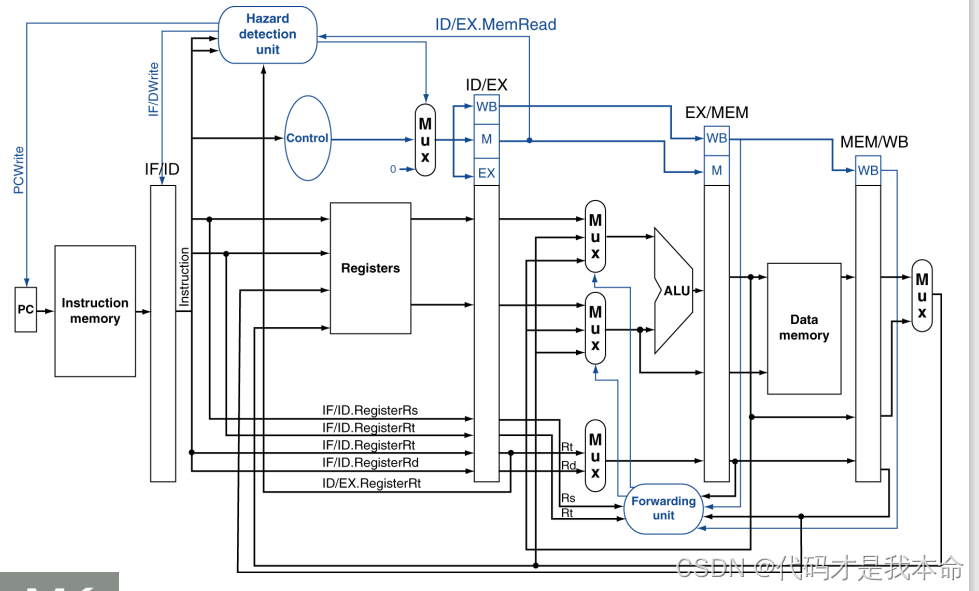
下图是未加冒险处理的总图:
总结
本文主要简单总结了一下为MIPS指令集的两种不同实现方式分别的建立数据通路和控制单元:单周期设计和流水线设计。其中流水线的理解比较难懂,建议通过软件模拟的方式,一步一步实际执行指令,看其真实执行的时候是怎样的来帮助理解(如有该模拟软件需要可以私信我)。















 437
437











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









