









质数
模板:
// 试除法判断质数
bool is_prime(int x)
{
if (x < 2) return false;
//只需枚举一部分 使得 i<= x / i, 时间复杂度为√n
for (int i = 2; i <= x / i; i ++ )
if (x % i == 0)
return false;
return true;
}
// 试除法分解质因数
void divide(int n)
{
for (int i = 2; i <= n / i; i++)
{
if (n % i == 0)
{
int cnt = 0;
while (n % i == 0)
{
n /= i;
cnt++;
}
printf("%d %d\n", i, cnt);
}
}
//本身就是质数
if (n > 1) printf("%d %d\n", n, 1);
printf("\n");
}
//
试除法判定质数
代码:
#include<iostream>
using namespace std;
int n;
bool is_prime(int x)
{
if (x == 1) return false;
for (int i = 2; i <= x / i; i++)
{
if (x % i == 0) return false;
}
return true;
}
int main()
{
scanf("%d", &n);
while (n--)
{
int a;
scanf("%d", &a);
printf(is_prime(a) ? "Yes\n" : "No\n");
}
return 0;
}
分解质因数

代码:
#include<iostream>
using namespace std;
void divide(int n)
{
for (int i = 2; i <= n / i; i++)
{
if (n % i == 0)
{
int cnt = 0;
while (n % i == 0)
{
n /= i;
cnt++;
}
printf("%d %d\n", i, cnt);
}
}
//本身就是质数
if (n > 1) printf("%d %d\n", n, 1);
printf("\n");
}
int main()
{
int n;
scanf("%d", &n);
while (n--)
{
int a;
scanf("%d", &a);
divide(a);
}
return 0;
}
筛质数
思路:
筛法求质数,有两种方式:
- 埃氏筛法
- 线性筛法
埃氏筛法
埃氏筛法每次筛掉质数的倍数(大于等于2倍),这样最后剩下的就全是质数。
s
t
[
i
]
st[i]
st[i]为
f
a
l
s
e
false
false时,表示为质数。
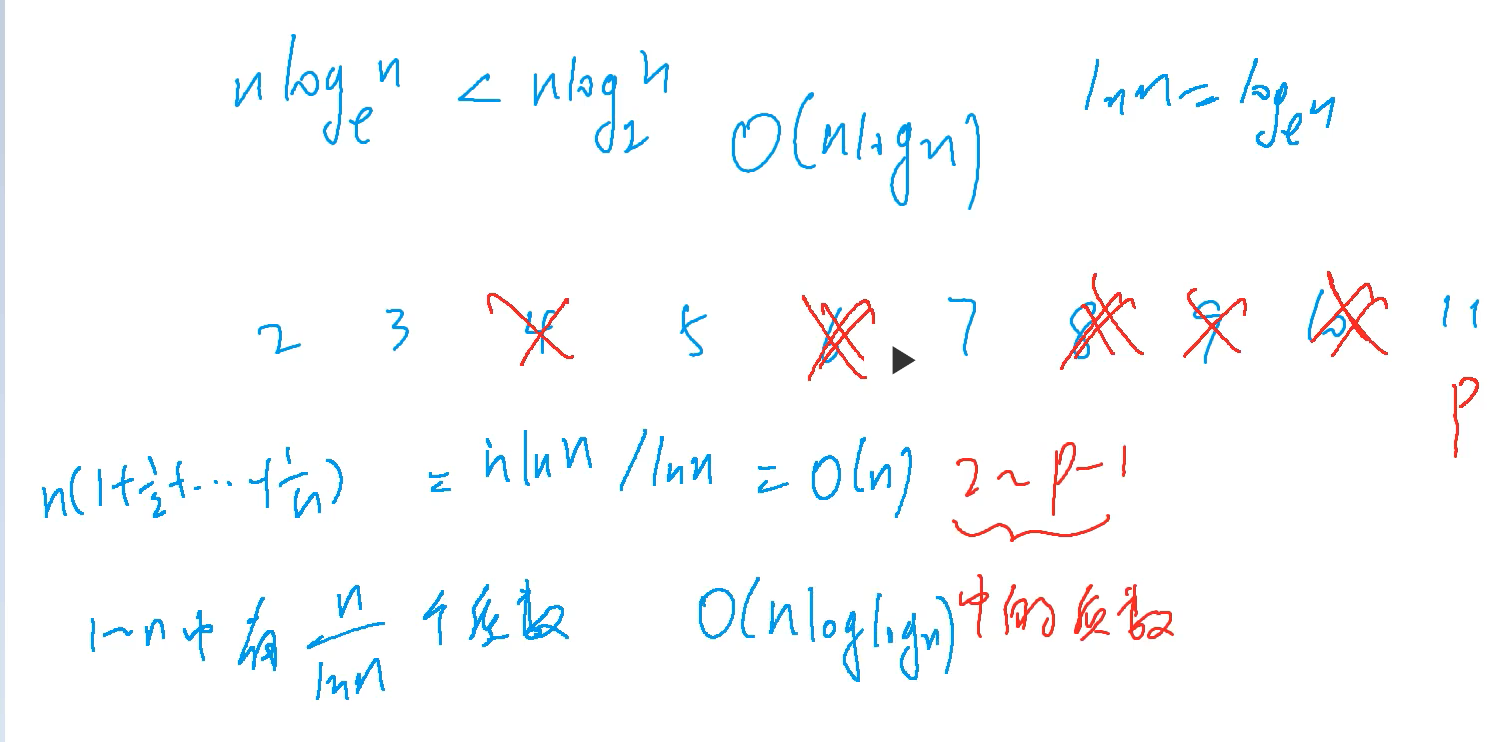
埃氏筛法代码:
#include<iostream>
using namespace std;
const int N = 1000010;
bool st[N];
int primes[N];
int cnt;
void get_primes(int n)
{
for (int i = 2; i <= n; i++)
{
if (!st[i]) primes[cnt++] = i;
for (int j = i + i; j <= n; j += i) st[j] = true;
}
}
int main()
{
int n;
cin >> n;
get_primes(n);
cout << cnt << endl;
return 0;
}
线性筛法
线性筛法保证
n
n
n只会被最小质因子筛掉。
i % primes[j] == 0,primes[j]是i的最小质因子,primes[j]是primes[j] * i的最小质因子。i % primes[j] != 0,primes[j]小于i的最小质因子,primes[j]是primes[j] * i的最小质因子。
bool st[N];
int primes[N];
int cnt;
void get_primes(int n)
{
for (int i = 2; i <= n; i++)
{
if (!st[i]) primes[cnt++] = i;
for (int j = 0; primes[j] <= n / i; j ++)
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
线性筛法代码:
#include<iostream>
using namespace std;
const int N = 1000010;
bool st[N];
int primes[N];
int cnt;
void get_primes(int n)
{
for (int i = 2; i <= n; i++)
{
if (!st[i]) primes[cnt++] = i;
for (int j = 0; primes[j] <= n / i; j ++)
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
int main()
{
int n;
cin >> n;
get_primes(n);
cout << cnt << endl;
return 0;
}
约数
试除法求约数

代码:
#include<iostream>
#include<vector>
#include<algorithm>
using namespace std;
int n;
void get_divisors(int a)
{
vector<int> res;
for (int i = 1; i <= a / i; i++)
{
if (a % i == 0)
{
res.push_back(i);
// 防止平方根多次出现
if (i != a / i) res.push_back(a / i);
}
}
//从大到小排序
sort(res.begin(), res.end());
for (int t : res) printf("%d ", t);
printf("\n");
}
int main()
{
scanf("%d", &n);
while (n--)
{
int a;
scanf("%d", &a);
get_divisors(a);
}
return 0;
}
约数个数
思路:
给定一个数
N
N
N,
p
i
p_i
pi为
N
N
N的质约数,则可以表示为:
N
=
p
1
α
1
×
p
2
α
2
×
p
3
α
3
×
.
.
.
×
p
k
α
k
N=p_{1}^{\alpha_1}\times p_{2}^{\alpha_2} \times p_{3}^{\alpha_3}\times... \times p_{k}^{\alpha_k}
N=p1α1×p2α2×p3α3×...×pkαk
N
N
N的每一个约数
d
i
d_i
di,可以表示为:
d
i
=
p
1
β
1
×
p
2
β
2
×
p
3
β
3
×
.
.
.
×
p
k
β
k
d_i=p_{1}^{\beta_1}\times p_{2}^{\beta_2} \times p_{3}^{\beta_3}\times... \times p_{k}^{\beta_k}
di=p1β1×p2β2×p3β3×...×pkβk
其中,
0
≤
β
i
≤
α
i
0 \le \beta_i \le \alpha_i
0≤βi≤αi,
β
i
\beta_i
βi的选法有
0
∼
α
i
0 \sim \alpha_i
0∼αi,共有
(
α
i
+
1
)
(\alpha_i + 1)
(αi+1)种选法 ,根据排列组合原理,约数个数为:
(
α
1
+
1
)
×
(
α
2
+
1
)
×
(
α
3
+
1
)
×
.
.
.
×
(
α
k
+
1
)
(\alpha_1 + 1) \times (\alpha_2 + 1) \times (\alpha_3 + 1) \times ... \times (\alpha_k + 1)
(α1+1)×(α2+1)×(α3+1)×...×(αk+1)
依次遍历
a
i
a_i
ai,求
a
i
a_i
ai的质因数以及每个质因数的个数,可以用哈希表保存结果

代码:
#include<iostream>
#include<unordered_map>
using namespace std;
const int mod = 1e9 + 7;
int main()
{
int n;
cin >> n;
unordered_map<int, int> primes;
while (n--)
{
int x;
cin >> x;
for (int i = 2; i <= x / i; i++)
{
while (x % i == 0)
{
x /= i;
primes[i]++;
}
}
if (x > 1) primes[x]++;
}
long long res = 1;
for (auto prime : primes)
res = res * (prime.second + 1) % mod;
cout << res << endl;
return 0;
}
约数之和
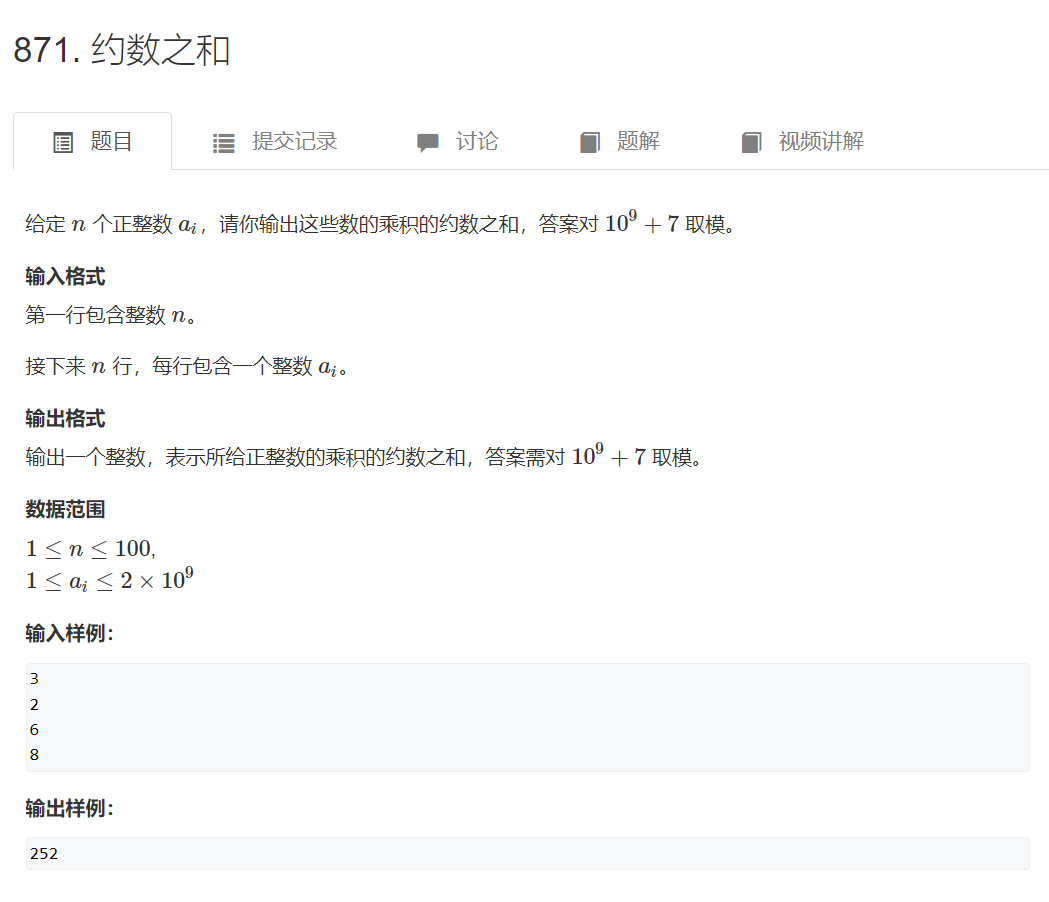
思路:
根据约数个数的思路,约数之和为
d
1
+
d
2
+
d
3
+
.
.
.
+
d
k
①
d_1 + d_2 + d_3 + ... + d_k \: \: \: ①
d1+d2+d3+...+dk①
其中,
d
i
=
p
1
β
1
×
p
2
β
2
×
p
3
β
3
×
.
.
.
×
p
k
β
k
②
d_i=p_{1}^{\beta_1}\times p_{2}^{\beta_2} \times p_{3}^{\beta_3}\times... \times p_{k}^{\beta_k} \: \: \: ②
di=p1β1×p2β2×p3β3×...×pkβk②
约数之和为
(
p
1
0
+
p
1
1
+
p
1
2
.
.
.
+
p
1
α
1
)
.
.
.
(
p
k
0
+
p
k
1
+
p
k
2
.
.
.
+
p
k
α
k
)
(p_1^0+p_1^1+p_1^2...+p_1^{\alpha_1})...(p_k^0+p_k^1+p_k^2...+p_k^{\alpha_k})
(p10+p11+p12...+p1α1)...(pk0+pk1+pk2...+pkαk)
展开可得式①,展开的每一项均为
d
i
d_i
di
(
p
i
0
+
p
i
1
+
p
i
2
.
.
.
+
p
i
α
1
)
(p_i^0+p_i^1+p_i^2...+p_i^{\alpha_1})
(pi0+pi1+pi2...+piα1)可以按照下面的方式进行推导:
t
0
=
1
t_0 = 1
t0=1
t
1
=
t
0
×
p
+
1
=
p
+
1
t_1 = t_0 \times p + 1 = p + 1
t1=t0×p+1=p+1
t
2
=
t
1
×
p
+
1
=
p
2
+
p
+
1
t_2 = t_1 \times p + 1 = p^2 + p + 1
t2=t1×p+1=p2+p+1
…
t
α
i
=
t
α
i
−
1
×
p
+
1
=
p
α
i
+
p
α
i
−
1
+
.
.
.
+
p
+
1
t_{\alpha_i }= t_{\alpha_i-1} \times p + 1 = p^{\alpha_i } + p^{\alpha_i-1} +... + p + 1
tαi=tαi−1×p+1=pαi+pαi−1+...+p+1,
最后计算
∏
i
=
1
n
t
α
i
\displaystyle\prod _{i=1}^n t_{\alpha_i}
i=1∏ntαi,即为约数之和。
代码:
#include<iostream>
#include<unordered_map>
using namespace std;
const int mod = 1e9 + 7;
int main()
{
int n;
cin >> n;
unordered_map<int, int> primes;
while (n--)
{
int x;
cin >> x;
for (int i = 2; i <= x / i; i++)
{
while (x % i == 0)
{
x /= i;
primes[i]++;
}
}
if (x > 1) primes[x]++;
}
long long res = 1;
for (auto prime : primes)
{
long long t = 1;
int p = prime.first, a = prime.second;
while (a--) t = (t * p + 1) % mod;
res = res * t % mod;
}
cout << res << endl;
return 0;
}
最大公因数

思路:
欧几里得算法,辗转相除法。
代码:
#include<iostream>
using namespace std;
int gcd(int m, int n)
{
return m % n == 0 ? n : gcd(n, m % n);
}
int main()
{
int n;
cin >> n;
while (n--)
{
int a, b;
cin >> a >> b;
cout << gcd(a, b) << endl;
}
return 0;
}
欧拉函数
欧拉函数
思路:
互质是公约数只有1的两个整数。在算数基本定理中,
N
=
p
1
α
1
×
p
2
α
2
×
p
3
α
3
×
.
.
.
×
p
m
α
m
N=p_{1}^{\alpha_1}\times p_{2}^{\alpha_2} \times p_{3}^{\alpha_3}\times... \times p_{m}^{\alpha_m}
N=p1α1×p2α2×p3α3×...×pmαm,根据欧拉函数的定义:
ϕ
(
N
)
=
N
×
p
1
−
1
p
1
×
p
2
−
1
p
2
×
.
.
.
×
p
m
−
1
p
m
\phi(N) = N \times \cfrac{p_1 - 1}{p_1} \times \cfrac{p_2 - 1}{p_2} \times ... \times \cfrac{p_m - 1}{p_m}
ϕ(N)=N×p1p1−1×p2p2−1×...×pmpm−1
只需求得
N
N
N的质因数
p
i
p_i
pi即可,可以用到分解质因数的方法。
代码:
#include<iostream>
using namespace std;
int main()
{
int n;
cin >> n;
while (n--)
{
int x;
cin >> x;
int res = x;
for (int i = 2; i <= x / i; i++)
{
// 分解质因数
if (x % i == 0)
{
res = res / i * (i - 1);
while (x % i == 0) x /= i;
}
}
// 最后的质因数
if (x > 1) res = res / x * (x - 1);
cout << res << endl;
}
return 0;
}
筛法求欧拉函数
思路:
在用线性筛法求质因数的过程中,可以同时求出很多东西,比如某个数的欧拉函数。
1
∼
N
1 \sim N
1∼N中与
N
N
N互质的数的个数即为
N
N
N的欧拉函数,记作
ϕ
(
N
)
\phi(N)
ϕ(N)。
- 若 N N N为质数,则 ϕ ( N ) = N − 1 \phi(N) = N-1 ϕ(N)=N−1
- 若
N
N
N不为质数,
N
N
N只会被最小的质因数给筛掉。
记 p j p_j pj为 N N N的质因子,枚举 2 ∼ N 2 \sim N 2∼N,记作 i i i。- 若
i
m
o
d
p
j
=
0
i \mod p_j = 0
imodpj=0,则
p
j
p_j
pj为
p
j
×
i
p_j \times i
pj×i的最小质因子,根据欧拉函数的计算公式:
ϕ
(
p
j
×
i
)
=
(
p
j
×
i
)
×
p
1
−
1
p
1
×
p
2
−
1
p
2
×
.
.
.
×
p
k
−
1
p
k
\phi(p_j \times i) = (p_j \times i) \times \cfrac{p_1 - 1}{p_1} \times \cfrac{p_2 - 1}{p_2} \times ... \times \cfrac{p_k - 1}{p_k}
ϕ(pj×i)=(pj×i)×p1p1−1×p2p2−1×...×pkpk−1
p
1
∼
p
k
p_1 \sim p_k
p1∼pk均为
i
i
i的质因子,
p
j
∈
{
p
1
,
.
.
.
,
p
k
}
p_j \in \{p_1,...,p_k\}
pj∈{p1,...,pk}。
观察 i × p 1 − 1 p 1 × p 2 − 1 p 2 × . . . × p k − 1 p k i \times\cfrac{p_1 - 1}{p_1} \times \cfrac{p_2 - 1}{p_2} \times ... \times \cfrac{p_k - 1}{p_k} i×p1p1−1×p2p2−1×...×pkpk−1,可以用 ϕ ( i ) \phi(i) ϕ(i)表示,则 ϕ ( p j × i ) = p j × ϕ ( i ) \phi(p_j \times i) = p_j \times \phi(i) ϕ(pj×i)=pj×ϕ(i) -
i
m
o
d
p
j
≠
0
i \mod p_j \ne 0
imodpj=0,
p
j
p_j
pj小于
i
i
i的最小质因子,则
p
j
p_j
pj是
p
j
×
i
p_j \times i
pj×i的最小质因子
ϕ ( p j × i ) = ( p j × i ) × p 1 − 1 p 1 × . . . × p j − 1 p j × . . . × p k − 1 p k = ( i × p 1 − 1 p 1 × p 2 − 1 p 2 × . . . × p k − 1 p k ) × ( p j × p j − 1 p j ) = ϕ ( i ) × ( p j − 1 ) \begin{aligned} \phi(p_j \times i) &= (p_j \times i) \times \cfrac{p_1 - 1}{p_1} \times ... \times \cfrac{p_j- 1}{p_j}\times ... \times\cfrac{p_k - 1}{p_k} \\ &= (i \times \cfrac{p_1 - 1}{p_1} \times \cfrac{p_2 - 1}{p_2} \times ... \times \cfrac{p_k - 1}{p_k}) \times (p_j \times \cfrac{p_j-1}{p_j}) \\ &= \phi(i) \times (p_j - 1) \end{aligned} ϕ(pj×i)=(pj×i)×p1p1−1×...×pjpj−1×...×pkpk−1=(i×p1p1−1×p2p2−1×...×pkpk−1)×(pj×pjpj−1)=ϕ(i)×(pj−1)
这样,便能遍历一次,求出 1 ∼ N 1 \sim N 1∼N内所有欧拉函数之和,这就是筛法求欧拉函数。
- 若
i
m
o
d
p
j
=
0
i \mod p_j = 0
imodpj=0,则
p
j
p_j
pj为
p
j
×
i
p_j \times i
pj×i的最小质因子,根据欧拉函数的计算公式:
ϕ
(
p
j
×
i
)
=
(
p
j
×
i
)
×
p
1
−
1
p
1
×
p
2
−
1
p
2
×
.
.
.
×
p
k
−
1
p
k
\phi(p_j \times i) = (p_j \times i) \times \cfrac{p_1 - 1}{p_1} \times \cfrac{p_2 - 1}{p_2} \times ... \times \cfrac{p_k - 1}{p_k}
ϕ(pj×i)=(pj×i)×p1p1−1×p2p2−1×...×pkpk−1
p
1
∼
p
k
p_1 \sim p_k
p1∼pk均为
i
i
i的质因子,
p
j
∈
{
p
1
,
.
.
.
,
p
k
}
p_j \in \{p_1,...,p_k\}
pj∈{p1,...,pk}。
欧拉定理,若
a
a
a与
n
n
n互质,则
a
ϕ
(
n
)
≡
1
(
m
o
d
n
)
a^{\phi(n)} \equiv 1\:\:(mod \:\:n)
aϕ(n)≡1(modn)
证明:
1
∼
n
1 \sim n
1∼n中与
n
n
n互质的数为
a
1
,
a
2
,
a
3
.
.
.
,
a
ϕ
(
n
)
a_1,a_2,a_3...,a_{\phi(n)}
a1,a2,a3...,aϕ(n)
每个数
×
a
\times a
×a,得
a
a
1
,
a
a
2
,
a
a
3
,
.
.
.
,
a
a
ϕ
(
n
)
aa_1,aa_2,aa_3,...,aa_{\phi(n)}
aa1,aa2,aa3,...,aaϕ(n)
每个数都与
n
n
n互质,在模
n
n
n的概念下,两组数可看作相同的,则有下式:
a
1
a
2
a
3
.
.
.
a
ϕ
(
n
)
≡
a
a
1
a
a
2
a
a
3
.
.
.
a
a
ϕ
(
n
)
(
m
o
d
n
)
a
ϕ
(
n
)
≡
1
(
m
o
d
n
)
\begin{aligned} a_1a_2a_3...a_{\phi(n)} &\equiv aa_1aa_2aa_3...aa_{\phi(n)} \:\:(mod \:\:n) \\ a^{\phi(n)} &\equiv 1 \:\:(mod \:\:n) \end{aligned}
a1a2a3...aϕ(n)aϕ(n)≡aa1aa2aa3...aaϕ(n)(modn)≡1(modn)
特例: 费马定理
若
p
p
p为质数,则
a
ϕ
(
p
)
≡
1
(
m
o
d
p
)
a^ {\phi(p)} \equiv 1 \:\:(mod \:\:p)
aϕ(p)≡1(modp),即
a
p
−
1
≡
1
(
m
o
d
p
)
a^ {p-1} \equiv 1 \:\:(mod \:\:p)
ap−1≡1(modp)
代码:
#include<iostream>
using namespace std;
typedef long long ll;
const int N = 1000010;
int primes[N], phi[N], cnt;
bool st[N];
ll get_eulers(int n)
{
ll res = 0;
phi[1] = 1;
for (int i = 2; i <= n; i++)
{
if (!st[i]) primes[cnt++] = i, phi[i] = i - 1;
for (int j = 0; primes[j] <= n / i; j++)
{
st[primes[j] * i] = true;
if (i % primes[j] == 0)
{
phi[primes[j] * i] = phi[i] * primes[j];
break;
}
phi[primes[j] * i] = phi[i] * (primes[j] - 1);
}
}
for (int i = 1; i <= n; i++) res += phi[i];
return res;
}
int main()
{
int n;
cin >> n;
cout << get_eulers(n) << endl;
return 0;
}
快速幂
快速幂
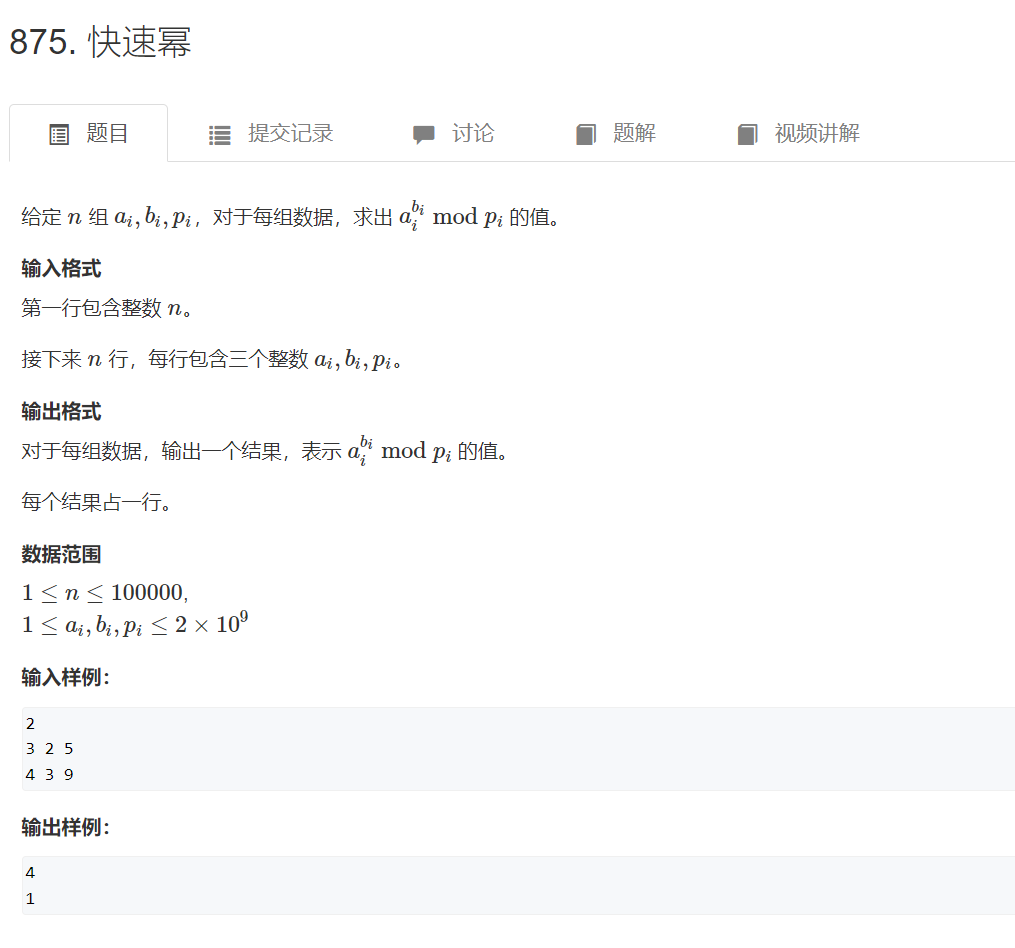
思路:
快速幂的思想是将指数
k
k
k看作二进制数之和这样便可以在
O
(
l
o
g
k
)
O(logk)
O(logk)的复杂度中求得结果。则推出下式
k
=
2
i
+
.
.
.
+
2
j
+
.
.
.
+
2
log
k
a
k
=
a
2
i
.
.
.
a
2
j
.
.
.
a
2
log
k
\begin{aligned} k &= 2^i+...+2^j+...+2^{\log k} \\ a^k &= a^{2^i}...a^{2^j}...a^{2^{\log k}} \end{aligned}
kak=2i+...+2j+...+2logk=a2i...a2j...a2logk
又知
a
2
0
=
a
a
2
1
=
a
2
0
×
2
=
(
a
2
0
)
2
.
.
.
a
2
log
k
=
a
2
(
log
k
)
−
1
×
2
=
(
a
2
(
log
k
)
−
1
)
2
\begin{aligned} a^{2^0} &= a \\ a^{2^1} &= a^{{2^0}\times 2} = (a^{2^0})^2 \\ ... \\ a^{2^{\log k}} &= a^{{2^{(\log k) - 1}}\times 2} = (a^{2^{(\log k) - 1}})^2 \\ \end{aligned}
a20a21...a2logk=a=a20×2=(a20)2=a2(logk)−1×2=(a2(logk)−1)2
若
k
k
k第
i
i
i位为
1
1
1,则结果
×
a
2
i
m
o
d
p
\times a^{2^i} \: mod \:p
×a2imodp,同时
k
k
k右移一位,底数平方得
a
2
i
+
1
a^{2^{i+1}}
a2i+1 ,
m
o
d
p
\: mod \:p
modp,继续计算下一位。
代码
#include<iostream>
using namespace std;
typedef long long ll;
int q_pow(int a, int b, int p)
{
int res = 1 % p;
while (b)
{
if (b & 1) res = (ll) res * a % p;
b >>= 1;
a = (ll) a * a % p;
}
return res;
}
int main()
{
int n;
scanf("%d", &n);
while (n--)
{
int a, b, p;
scanf("%d%d%d", &a, &b, &p);
printf("%d\n", q_pow(a, b, p));
}
return 0;
}
快速幂求逆元

思路:
若整数
b
b
b ,
m
m
m 互质,并且对于任意的整数
a
a
a,如果满足
b
∣
a
b|a
b∣a,则存在一个整数
x
x
x,使得
a
/
b
≡
a
×
x
(
m
o
d
m
)
a/b \equiv a×x(mod \:m)
a/b≡a×x(modm),则称
x
x
x 为
b
b
b 的模
m
m
m 乘法逆元,记为
b
−
1
(
m
o
d
m
)
b^{-1}(mod \:m)
b−1(modm)。
a
/
b
≡
a
×
x
(
m
o
d
m
)
a
/
b
×
b
≡
a
×
b
×
x
(
m
o
d
m
)
b
×
x
≡
1
(
m
o
d
m
)
\begin{aligned} a/b &\equiv a×x \:(mod \:m) \\ a/b \times b &\equiv a \times b \times x\:(mod \:m) \\ b \times x &\equiv1\:(mod \:m) \\ \end{aligned}
a/ba/b×bb×x≡a×x(modm)≡a×b×x(modm)≡1(modm)
又根据费马定理,
b
m
−
1
≡
1
(
m
o
d
m
)
b^ {m-1} \equiv 1 \:\:(mod \:\:m)
bm−1≡1(modm),则
b
×
x
=
b
m
−
1
b \times x = b^ {m-1}
b×x=bm−1,
x
=
b
m
−
2
x = b^ {m-2}
x=bm−2,若整数
b
b
b ,
m
m
m 互质,则存在
b
b
b的乘法逆元。
代码
#include <iostream>
#include <cstring>
#include <algorithm>
using namespace std;
typedef long long LL;
int n;
int qmi(int a, int b, int p)
{
int res = 1 % p;
while (b)
{
if (b & 1) res = (LL) res * a % p;
b >>= 1;
a = (LL) a * a % p;
}
return res;
}
int main()
{
scanf("%d", &n);
int a, p;
while (n -- )
{
scanf("%d%d", &a, &p);
// 如果a%p不等于0,若a<p,由p为质数,a,p互质。若a>p,p不等整除a,a,p互质
if (a % p) printf("%d\n", qmi(a, p - 2, p));
else puts("impossible");
}
return 0;
}
扩展欧几里得算法
扩展欧几里得算法
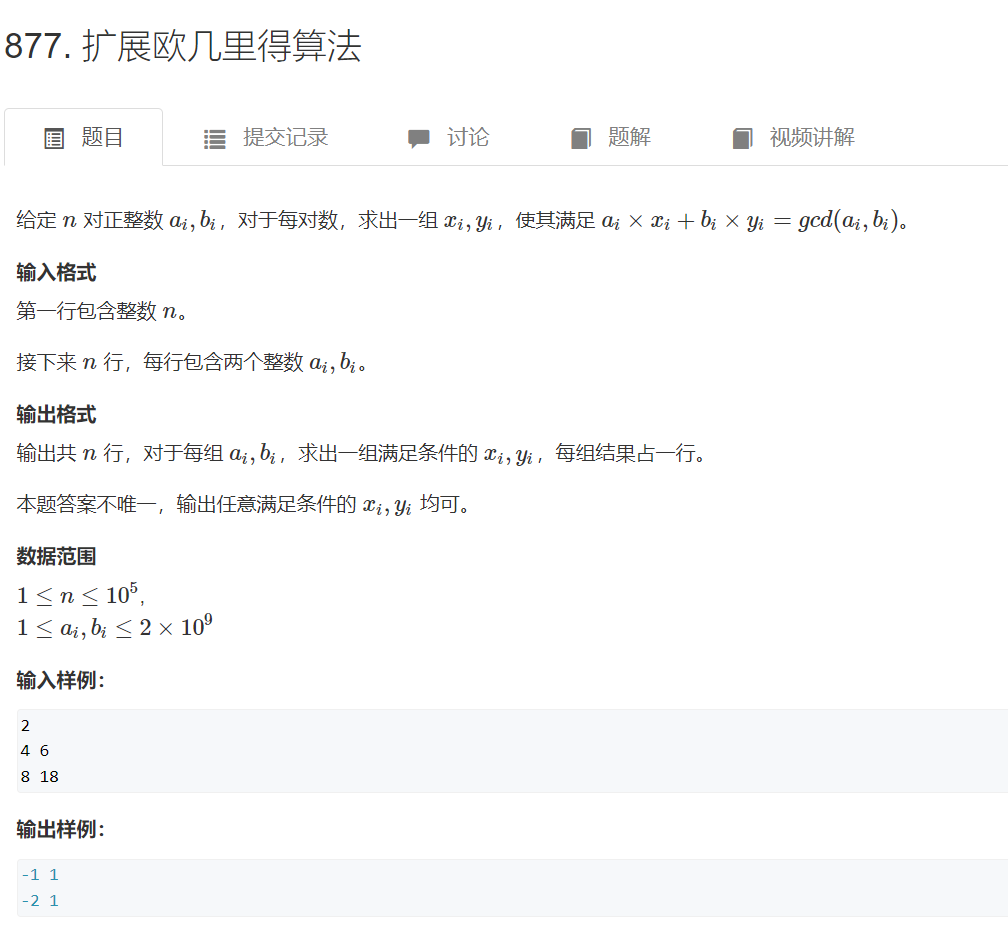
思路:
裴蜀定理: 对任何整数
a
a
a、
b
b
b,存在整数
x
x
x、
y
y
y,使得
a
x
+
b
y
=
(
a
,
b
)
ax + by = (a, b)
ax+by=(a,b),
(
a
,
b
)
(a, b)
(a,b)表示
a
a
a、
b
b
b的最大公因数,令
d
=
(
a
,
b
)
d=(a, b)
d=(a,b)。
若
b
=
0
b=0
b=0,则
d
=
a
d=a
d=a,
x
=
1
x=1
x=1,
y
=
0
y=0
y=0
由数学定理知,
(
a
,
b
)
=
(
b
,
a
m
o
d
b
)
(a, b) = (b, a \: mod \: b)
(a,b)=(b,amodb)。
a
a
a、
b
b
b交换顺序后,则有
(
a
m
o
d
b
)
x
+
b
y
=
d
(
a
m
o
d
b
)
=
a
−
⌊
a
b
⌋
b
(
a
−
⌊
a
b
⌋
b
)
x
+
b
y
=
d
a
x
+
(
y
−
⌊
a
b
⌋
x
)
b
=
d
(a \: mod \: b)x+by=d \\ (a \: mod \: b) = a - \lfloor \cfrac{a}{b} \rfloor b \\ (a - \lfloor \cfrac{a}{b} \rfloor b)x+by = d \\ ax + (y - \lfloor \cfrac{a}{b} \rfloor x)b = d
(amodb)x+by=d(amodb)=a−⌊ba⌋b(a−⌊ba⌋b)x+by=dax+(y−⌊ba⌋x)b=d
根据公式看到,与
b
b
b位置相同的参数的系数对应的为
y
y
y。
代码:
#include<iostream>
using namespace std;
/**
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
*/
int exgcd(int a, int b, int &x, int &y)
{
if (!b)
{
x = 1, y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= a / b * x;
return d;
}
int main()
{
int n;
scanf("%d", &n);
while (n--)
{
int a, b, x, y;
scanf("%d%d", &a, &b);
exgcd(a, b, x, y);
printf("%d %d\n", x, y);
}
return 0;
}
线性同余方程
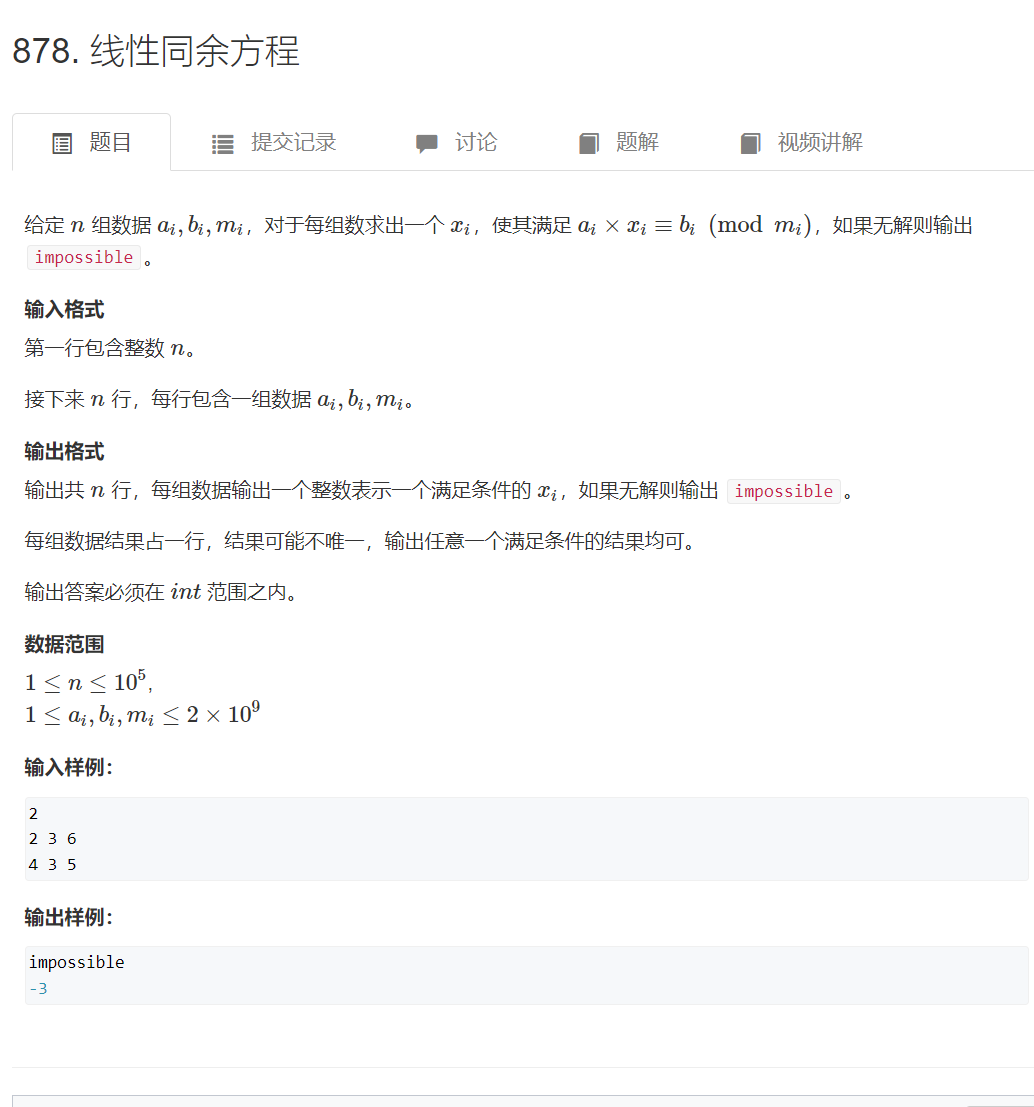
思路:
∵
a
x
≡
b
(
m
o
d
m
)
,
∃
y
∈
Z
\because a x \equiv b(\mod m),\exist y \in Z
∵ax≡b(modm),∃y∈Z,使得:
a
x
−
m
y
=
b
ax-my=b
ax−my=b。令
y
=
−
y
y=-y
y=−y,则
a
x
+
m
y
=
b
ax+my=b
ax+my=b,令
d
=
(
a
,
m
)
d=(a,m)
d=(a,m),并且
d
∣
b
d|b
d∣b。
用拓展欧几里得算法求解,
a
x
+
m
y
=
d
ax+my=d
ax+my=d,
x
x
x、
y
y
y扩大
b
d
\cfrac{b}{d}
db 倍,即可化为
a
x
+
m
y
=
b
ax+my=b
ax+my=b。
输出答案必须在
i
n
t
int
int 范围之内,计算出来的
x
x
x可能超过限制,又
a
x
m
o
d
m
=
(
a
∗
(
x
m
o
d
m
)
)
m
o
d
m
ax \mod m = (a * (x \mod m)) \mod m
axmodm=(a∗(xmodm))modm
保险起见,最后的
x
m
o
d
m
x \mod m
xmodm。
代码:
#include<iostream>
using namespace std;
/**
int gcd(int a, int b)
{
return b ? gcd(b, a % b) : a;
}
*/
int exgcd(int a, int b, int &x, int &y)
{
if (!b)
{
x = 1, y = 0;
return a;
}
int d = exgcd(b, a % b, y, x);
y -= a / b * x;
return d;
}
int main()
{
int n;
scanf("%d", &n);
while (n--)
{
int a, b, m, x, y;
scanf("%d%d%d", &a, &b, &m);
int d = exgcd(a, m, x, y);
if (b % d) puts("impossible");
else printf("%d\n", (long long)b / d * x % m);
}
return 0;
}
中国剩余定理
表达整数的奇怪方式
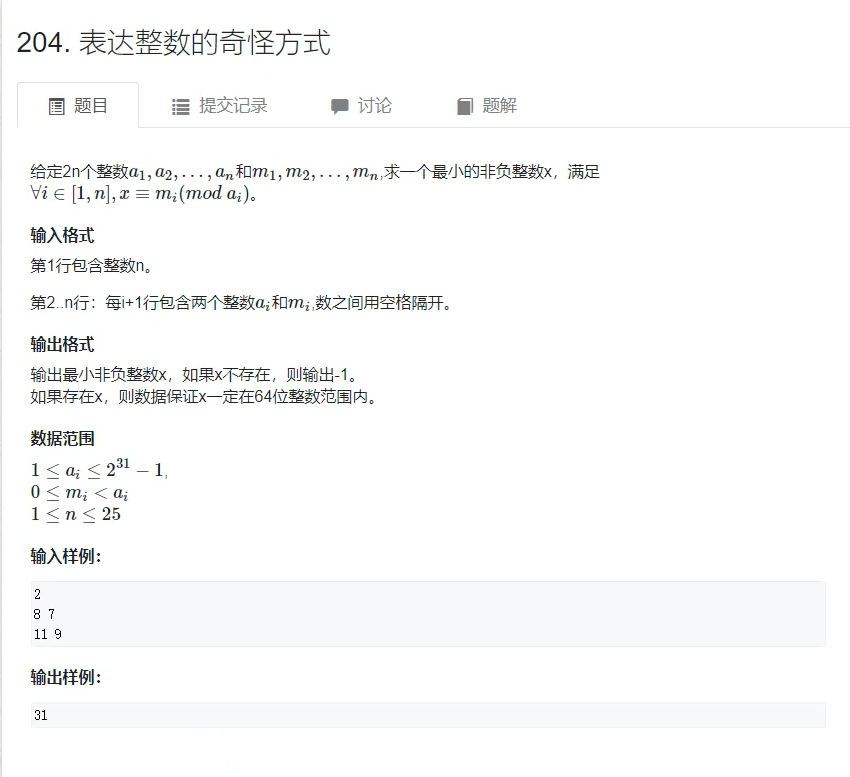
思路:
先引入中国剩余定理:
用现代数学的语言来说明的话,中国剩余定理给出了以下的一元线性同余方程组:
(
S
)
:
{
x
≡
a
1
(
m
o
d
m
1
)
x
≡
a
2
(
m
o
d
m
2
)
x
≡
a
3
(
m
o
d
m
3
)
.
.
.
x
≡
a
n
(
m
o
d
m
n
)
(S): \begin{cases} x \equiv a_1 \: (\mod m_1)\\ x \equiv a_2 \: (\mod m_2)\\ x \equiv a_3 \: (\mod m_3)\\ ...\\ x \equiv a_n \: (\mod m_n)\\ \end{cases}
(S):⎩
⎨
⎧x≡a1(modm1)x≡a2(modm2)x≡a3(modm3)...x≡an(modmn)
中国剩余定理说明:假设整数
m
1
,
m
2
,
.
.
.
,
m
n
m_1,m_2, ... ,m_n
m1,m2,...,mn两两互质,则对任意的整数:
a
1
,
a
2
,
.
.
.
,
a
n
a_1,a_2, ... ,a_n
a1,a2,...,an,方程组
(
S
)
(S)
(S)有解,并且通解可以用如下方式构造得到:
令 M = m 1 × m 2 × m 3 × . . . × m n = ∏ i = 1 n m i M=m_1\times m_2 \times m_3 \times ... \times m_n= \displaystyle\prod_{i = 1}^{n} m_i M=m1×m2×m3×...×mn=i=1∏nmi,令 M i = M m i , ∀ i ∈ { 1 , 2 , . . . , n } M_i= \cfrac {M}{m_i}, \forall i \in \{1,2,...,n\} Mi=miM,∀i∈{1,2,...,n},设 M i − 1 M_i^{-1} Mi−1为 M i M_i Mi模 m i m_i mi的逆元。
方程组
(
S
)
(S)
(S)的通解形式为:
x
=
a
1
M
1
−
1
M
1
+
a
2
M
2
−
1
M
2
+
.
.
.
+
a
n
M
n
−
1
M
n
+
k
M
=
k
M
+
∑
i
=
1
n
a
i
M
i
−
1
M
i
,
k
∈
Z
\begin{aligned} x&=a_1M_1^{-1}M_1+a_2M_2^{-1}M_2+...+a_nM_n^{-1}M_n+kM \\ &=kM+\displaystyle\sum_{i=1}^{n}a_iM_i^{-1}M_i \:,\:\: k\in \Z \end{aligned}
x=a1M1−1M1+a2M2−1M2+...+anMn−1Mn+kM=kM+i=1∑naiMi−1Mi,k∈Z
进行验证,等式右边对
m
i
m_i
mi 取模,除了
a
i
M
i
−
1
M
i
a_iM_i^{-1}M_i
aiMi−1Mi 之外的所有项都包含因数
m
i
m_i
mi,取模结果为0。根据逆元的定义
M
i
−
1
M
i
M_i^{-1}M_i
Mi−1Mi 对
m
i
m_i
mi 取模结果为1,则
a
i
M
i
−
1
M
i
a_iM_i^{-1}M_i
aiMi−1Mi对
m
i
m_i
mi取模结果为
a
i
a_i
ai ,证明
x
x
x 确实是 一元线性同余方程组的解。
但本题中给的条件并没有说明 m i m_i mi是互质的,因此不能用上述的方式求得通解。
换一种方式证明:
(
S
)
:
{
x
≡
a
1
(
m
o
d
m
1
)
x
≡
a
2
(
m
o
d
m
2
)
x
≡
a
3
(
m
o
d
m
3
)
.
.
.
x
≡
a
n
(
m
o
d
m
n
)
(S): \begin{cases} x \equiv a_1 \: (\mod m_1)\\ x \equiv a_2 \: (\mod m_2)\\ x \equiv a_3 \: (\mod m_3)\\ ...\\ x \equiv a_n \: (\mod m_n)\\ \end{cases}
(S):⎩
⎨
⎧x≡a1(modm1)x≡a2(modm2)x≡a3(modm3)...x≡an(modmn)
考虑前两个方程:
{
x
≡
a
1
(
m
o
d
m
1
)
x
≡
a
2
(
m
o
d
m
2
)
\begin{cases} x \equiv a_1 \: (\mod m_1)\\ x \equiv a_2 \: (\mod m_2)\\ \end{cases}
{x≡a1(modm1)x≡a2(modm2)
对方程组进行等价变形:
{
x
=
k
1
a
1
+
m
1
x
=
k
2
a
2
+
m
2
\begin{cases} x =k_1a_1+m_1\\ x =k_2a_2+m_2\\ \end{cases}
{x=k1a1+m1x=k2a2+m2
联立两个等式,消去
x
x
x,得:
k
1
a
1
+
m
1
=
k
2
a
2
+
m
2
k
1
a
1
−
k
2
a
2
=
m
2
−
m
1
\begin{aligned} k_1a_1+m_1&=k_2a_2+m_2\\ k_1a_1-k_2a_2&=m_2-m_1 \end{aligned}
k1a1+m1k1a1−k2a2=k2a2+m2=m2−m1
k 1 k_1 k1、 k 2 k_2 k2 有解等价于 ( a 1 , a 2 ) ∣ ( m 2 − m 1 ) (a1,a2) | (m_2-m_1) (a1,a2)∣(m2−m1),令 d = ( a 1 , a 2 ) d=(a1,a2) d=(a1,a2)
k 1 k_1 k1、 k 2 k_2 k2 通解为:
{
k
1
=
k
1
+
k
a
2
d
k
2
=
k
2
+
k
a
1
d
\begin{cases} k_1 =k_1+k \cfrac {a_2}{d}\\ k_2 =k_2+k \cfrac {a_1}{d}\\ \end{cases}
⎩
⎨
⎧k1=k1+kda2k2=k2+kda1
其中
k
∈
Z
k \in \Z
k∈Z,将
k
1
k_1
k1 待入
x
x
x中,得:
x
=
k
1
a
1
+
m
1
=
(
k
1
+
k
a
2
d
)
a
1
+
m
1
=
k
1
a
1
+
k
a
1
a
2
d
+
m
1
=
(
k
1
a
1
+
m
1
)
+
k
[
a
1
,
a
2
]
\begin{aligned} x &= k_1a_1+m_1\\ &= (k_1+k \cfrac {a_2}{d})a_1+m_1 \\ &= k_1a_1 + k\cfrac {a_1a_2}{d} + m_1 \\ &= (k_1a_1+m_1) + k[a_1,a_2] \end{aligned}
x=k1a1+m1=(k1+kda2)a1+m1=k1a1+kda1a2+m1=(k1a1+m1)+k[a1,a2]
把
[
a
1
,
a
2
]
[a1,a2]
[a1,a2] 看作
a
1
a_1
a1,
k
1
a
1
+
m
1
k_1a_1+m_1
k1a1+m1 看作
m
1
m_1
m1,得方程的一般形式为:
x
=
k
1
a
1
+
m
1
⏟
更新后的
m
1
+
k
[
a
1
,
a
2
]
⏟
更新后的
a
1
=
k
1
a
1
+
m
1
\begin{aligned} x &= \underbrace{k_1a_1+m_1}_{更新后的m_1} + k \underbrace{[a1,a2]}_{更新后的a_1} \\ &= k_1a_1+m_1 \end{aligned}
x=更新后的m1
k1a1+m1+k更新后的a1
[a1,a2]=k1a1+m1
则经过
n
−
1
n-1
n−1次迭代,可以将
n
n
n个方程合并为一个方程,
m
1
m_1
m1可以视作
x
1
x_1
x1,最后的
m
1
m_1
m1就是所求的解。
代码:
#include <iostream>
using namespace std;
typedef long long ll;
ll exgcd(ll a, ll b, ll &x, ll &y)
{
if (!b)
{
x = 1, y = 0;
return a;
}
ll d = exgcd(b, a % b, y, x);
y -= a / b * x;
return d;
}
int main()
{
int n;
cin >> n;
ll a1, m1;
cin >> a1 >> m1;
for (int i = 0; i < n - 1; i++)
{
ll a2, m2, k1, k2;
cin >> a2 >> m2;
ll d = exgcd(a1, a2, k1, k2);
// d | m2 - m1表示有解,否则输出 -1
if ((m2 - m1) % d)
{
puts("-1");
return 0;
}
// 此时k1是 k1 * a1 + k2 * a2 = d的解,所以要乘上(m2-m1) / d
k1 *= (m2 - m1) / d;
ll t = a2 / d;
// 模 t 是因为 k1 = k1 + kt, k1是不断迭代的结果,取模保证k1取比较小的值
k1 = (k1 % t + t) % t;
// 更新 m1, m1不断迭代,可以看作方程的解
m1 = a1 * k1 + m1;
// 更新a1,a1,a2,...,an的最小公倍数
a1 = a1 * a2 / d;
}
cout << (m1 % a1 + a1) % a1<< endl;
return 0;
}
高斯消元
高斯消元解线性方程组
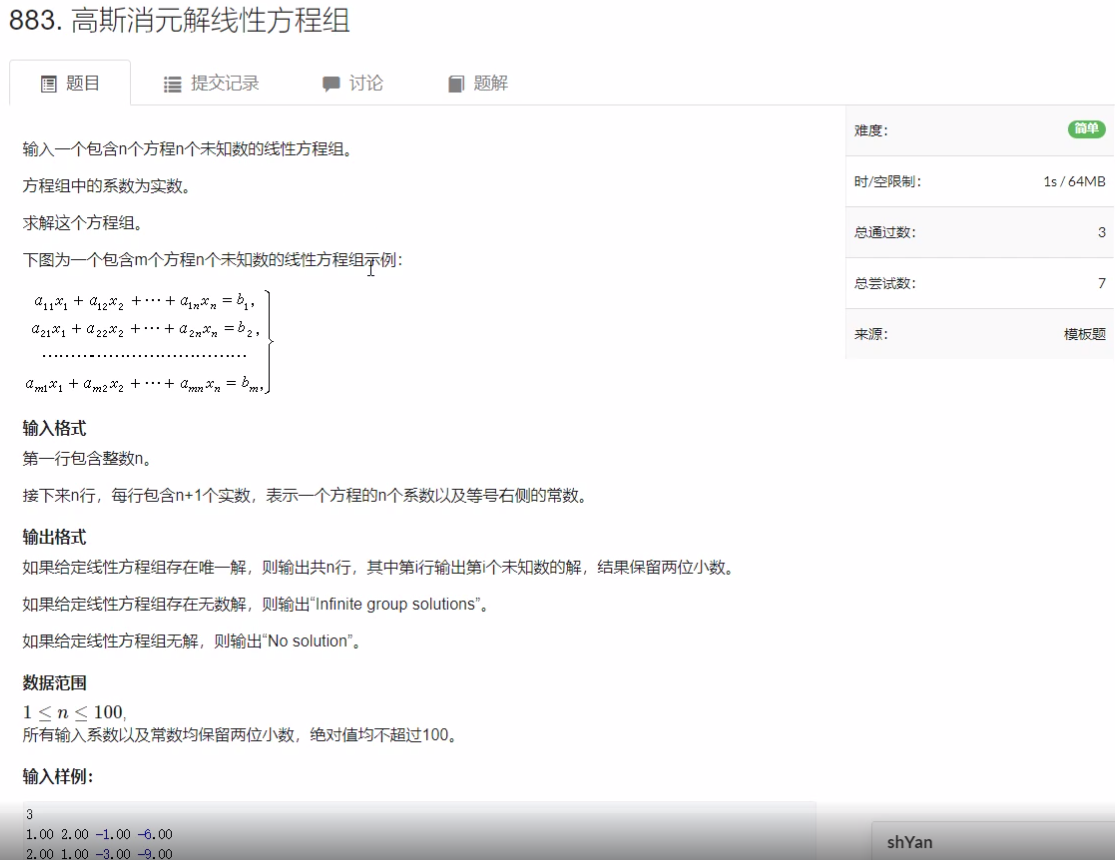
思路:
推导过程与线性代数求方程组的过程一样,主要就是通过初等行变换将增广矩阵变化为最简行阶梯型矩阵。比较系数矩阵与增广矩阵的秩,以及与未知数个数的关系,判断解的情况。在这里就不赘述了,代码中所需要注意的细节在注释里标注的很详细。

代码:
#include <iostream>
#include <algorithm>
#include <cmath>
using namespace std;
const int N = 110;
const double eps = 1e-6;
int n;
double a[N][N];
int gauss()
{
int c, r;
// 表示当前行, r表示当前列
for (c = 0, r = 0; c < n; c++)
{
int t = r;
// 找到每一行第一个非零元素绝对值最大的行
for (int i = r; i < n; i++)
if (fabs(a[i][c]) > fabs(a[t][c]))
t = i;
// 当前列第一个元素值为0 则跳至下一列
if (fabs(a[t][c]) < eps) continue;
// 将绝对值最大的行换到最顶端 最顶端即当前行r
for (int i = c; i <= n; i++) swap(a[t][i], a[r][i]);
// 将当前行的首位变成1 当前行的每一个数都除以首位的值
// 逆序保证每一项都除以首位的值,否则除首项外每一项都除以的是1
for (int i = n; i >= c; i--) a[r][i] /= a[r][c];
// 用当前行将下面所有的列首项消成0
for (int i = r + 1; i < n; i++)
{
if (fabs(a[i][c]) > eps)
{
// 逆序保证每一项都除以首位的值,否则初首项外都除以的是1
for (int j = n; j >= c; j--)
a[i][j] -= a[r][j] * a[i][c];
}
}
r++;
}
// 系数矩阵的秩小于未知数的个数n:
// 1. 系数矩阵的秩小于增广矩阵的秩,无解
// 2. 系数矩阵的秩等于增广矩阵的秩,无穷解
if (r < n)
{
// 系数矩阵的秩小于增广矩阵的秩,无解
for (int i = r; i < n; i++)
if (fabs(a[i][n]) > eps)
return 2;
// 系数矩阵的秩等于增广矩阵的秩,无穷解
return 1;
}
// 倒着把答案推出来
// 系数矩阵的秩等于未知数的个数n,唯一解
for (int i = n - 1; i >= 0; i -- )
for (int j = i + 1; j < n; j ++ )
a[i][n] -= a[i][j] * a[j][n];
return 0;
}
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n + 1; j++)
cin >> a[i][j];
int t = gauss();
if (t == 0)
{
for (int i = 0; i < n; i++)
// 防止出现 -0.00
printf("%.2lf\n", fabs(a[i][n]) < eps ? 0 : a[i][n]);
}
else if (t == 1) puts("Infinite group solutions");
else puts("No solution");
return 0;
}
高斯消元解异或线性方程组

思路:
高斯消元解异或方程组的方法如下:

代码:
#include <iostream>
using namespace std;
const int N = 110;
int a[N][N];
int n;
int gauss()
{
int r, c;
for (r = c = 0; c < n; c++)
{
// 找一个非0行
int t = r;
for (int i = r; i < n; i++)
if (a[i][c])
{
t = i;
break;
}
// 当前列找不到非0行,下一列
if (!a[t][c]) continue;
// 交换到最顶端
for (int i = c; i <= n; i++) swap(a[t][i], a[r][i]);
// 把下面行的清0
for (int i = r + 1; i < n; i++)
// 下面行首个元素为1,才能异或消掉
if (a[i][c])
for (int j = n; j >= c; j--)
a[i][j] ^= a[r][j];
r++;
}
if (r < n)
{
for (int i = r; i < n; i++)
if (a[i][n])
return 2;
return 1;
}
for (int i = n - 1; i >= 0; i--)
{
for (int j = i + 1; j < n; j++)
// x ^ a[i][j]a[j][n] = a[i][n]
// x ^ a[i][j]a[j][n] ^ a[i][j]a[j][n] = a[i][n] ^ a[i][j]a[j][n]
// x ^ (a[i][j]a[j][n] ^ a[i][j]a[j][n]) = a[i][n] ^ a[i][j]a[j][n]
// x ^ 0 = a[i][n] ^ a[i][j]a[j][n]
a[i][n] ^= a[i][j] & a[j][n];
}
return 0;
}
int main()
{
cin >> n;
for (int i = 0; i < n; i++)
for (int j = 0; j < n + 1; j++)
cin >> a[i][j];
int res = gauss();
if (res == 0)
{
for (int i = 0; i < n; i++) printf("%d\n", a[i][n]);
}
else if (res == 1) puts("Multiple sets of solutions");
else puts("No solution");
return 0;
}
求组合数

求组合数 I
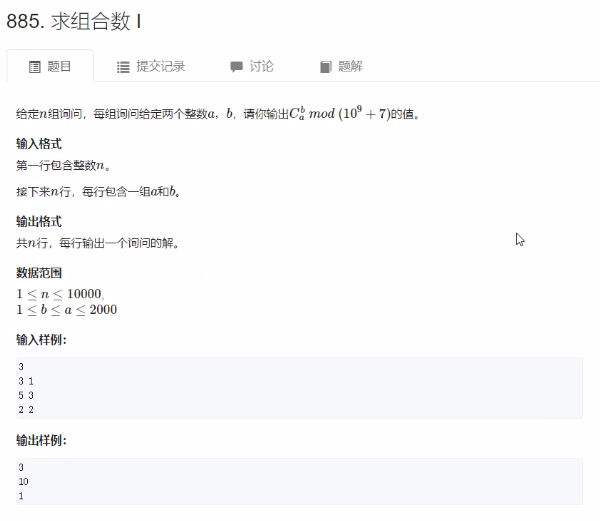
思路:
根据组合数的原理,
∁
m
n
=
∁
m
−
1
n
+
∁
m
−
1
n
−
1
\complement^n_m = \complement^{n}_{m-1}+\complement^{n-1}_{m-1}
∁mn=∁m−1n+∁m−1n−1,对于
a
、
b
∈
[
1
,
2000
]
a、b \in [1,2000]
a、b∈[1,2000],
b
≤
a
b \le a
b≤a,只需在
O
(
a
2
)
O(a^2)
O(a2)的时间复杂度内,就可以预处理出所有的组合数,再依次处理每一次的询问,也就是打表。
代码:
#include <iostream>
using namespace std;
const int N = 2010, mod = 1e9 + 7;
int c[N][N];
int main()
{
for (int i = 0; i < N; i++)
for (int j = 0; j <= i; j++)
{
if (!j) c[i][j] = 1;
else c[i][j] = (c[i - 1][j] + c[i - 1][j - 1]) % mod;
}
int n;
scanf("%d", &n);
while (n--)
{
int a, b;
scanf("%d%d", &a, &b);
printf("%d\n", c[a][b]);
}
return 0;
}
求组合数Ⅱ
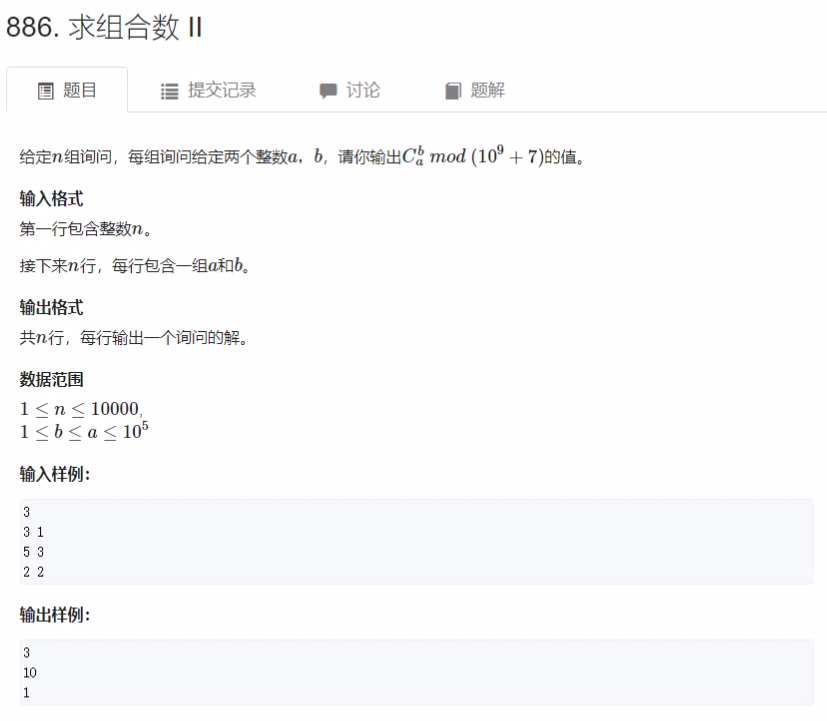
思路:
当 a 、 b a、b a、b范围特别大时,此时不适合用上面预处理出所有组合数的方式进行求解。根据组合数的公式 ∁ m n = m ! n ! ( m − n ) ! \complement^n_m = \cfrac{m!}{n!(m-n)!} ∁mn=n!(m−n)!m!,可以通过预处理 m ! m! m!、 n ! n! n!、 ( m − n ) ! (m-n)! (m−n)!,再根据求组合数的公式进行计算,时间复杂度为 O ( N log m o d ) O(N \log mod) O(Nlogmod) 。
值得注意的是,除以一个数并取模可以转化为乘该数的逆元,再预处理阶乘的同时,也计算阶乘的逆元。记
f
(
i
)
=
i
!
f(i) = i!
f(i)=i! ,
p
=
1000000007
p = 1000000007
p=1000000007,
p
p
p 为质数 ,
f
(
i
)
−
1
f(i)^{-1}
f(i)−1 为
f
(
i
)
f(i)
f(i) 模
p
p
p 的乘法逆元。
f
(
0
)
=
f
(
0
)
−
1
=
1
f(0) = f(0)^{-1} = 1
f(0)=f(0)−1=1 ,当
i
≥
1
i \ge 1
i≥1 时, 可得递推关系式为:
{
f
(
i
)
=
f
(
i
−
1
)
×
i
m
o
d
p
f
(
i
)
−
1
=
f
(
i
−
1
)
−
1
×
i
−
1
m
o
d
p
\begin{cases} f(i) = f(i-1) \times i \mod p \\ f(i)^{-1} = f(i - 1)^{-1} \times i^{-1} \mod p \end{cases}
{f(i)=f(i−1)×imodpf(i)−1=f(i−1)−1×i−1modp
接着依次处理每次询问即可。
代码:
#include <iostream>
using namespace std;
typedef long long ll;
const int N = 100010, mod = 1e9 + 7;
// 阶乘以及阶乘的逆元
int fac[N], infac[N];
int qmul(int a, int b, int p)
{
int res = 1;
while (b)
{
if (b & 1) res = (ll)res * a % p;
b >>= 1;
a = (ll)a * a % mod;
}
return res;
}
int main()
{
// 预处理0的阶乘,以及0的阶乘模 mod 的逆元
fac[0] = infac[0] = 1;
for (int i = 1; i < N; i++)
{
fac[i] = (ll)fac[i - 1] * i % mod;
infac[i] = (ll)infac[i - 1] * qmul(i, mod - 2, mod) % mod;
}
int n;
scanf("%d", &n);
while (n--)
{
int a, b;
scanf("%d%d", &a, &b);
// 两个相乘之后就开始取模,防止超过范围
printf("%d\n", (ll)fac[a] * infac[b] % mod * infac[a - b] % mod);
}
return 0;
}
求组合数Ⅲ
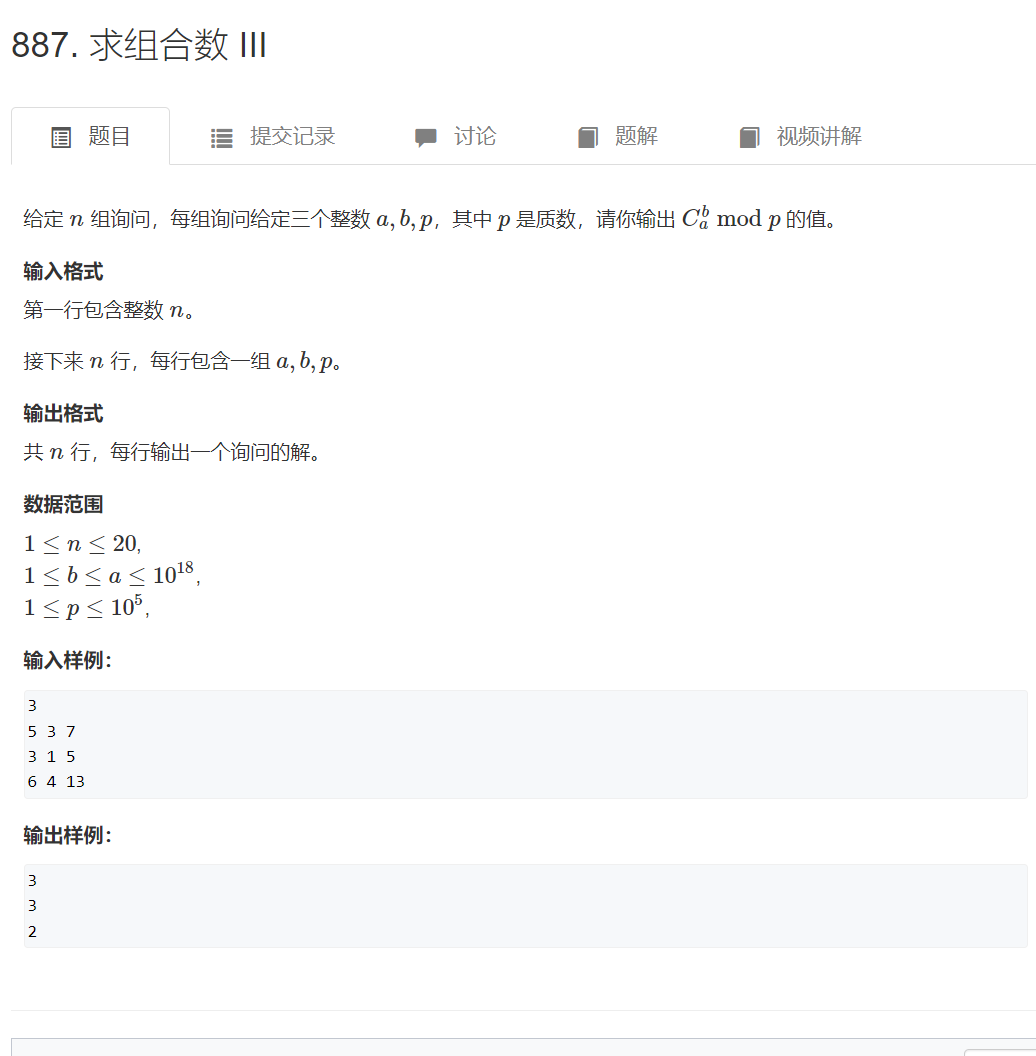
思路:
对于非负整数
a
a
a、
b
b
b,质数
p
p
p ,可以用
L
u
c
a
s
Lucas
Lucas 定理来求组合数。
L
u
c
a
s
Lucas
Lucas 定理求组合数的公式为:
∁
a
b
=
∁
(
a
m
o
d
p
)
(
b
m
o
d
p
)
∗
∁
⌊
a
/
p
⌋
⌊
b
/
p
⌋
\complement^b_a = \complement^{(b \mod p)}_{(a \mod p)} * \complement^{ \lfloor b/p \rfloor}_{\lfloor a/p \rfloor}
∁ab=∁(amodp)(bmodp)∗∁⌊a/p⌋⌊b/p⌋
代码:
#include <iostream>
using namespace std;
typedef long long ll;
int p;
int qmul(int a, int b)
{
int res = 1;
while (b)
{
if (b & 1) res = (ll) res * a % p;
a = (ll) a * a % p;
b >>= 1;
}
return res;
}
// 朴素法求组合数
int c(int a, int b)
{
int res = 1;
for (int i = 1, j = a; i <= b; i++, j--)
{
res = (ll) res * j % p;
res = (ll) res * qmul(i, p - 2) % p;
}
return res;
}
int lucas(ll a, ll b)
{
if (a < p && b < p) return c(a, b);
return (ll) lucas(a % p, b % p) * lucas(a / p, b / p) % p;
}
int main()
{
int n;
cin >> n;
while (n--)
{
ll a, b;
cin >> a >> b >> p;
cout << lucas(a, b) << endl;
}
return 0;
}
求组合数Ⅳ
思路:
本题要求输出组合数的真实结果,朴素方法来求组合数的公式为:
∁ m n = m ! n ! ( m − n ) ! \complement^n_m = \cfrac{m!}{n!(m-n)!} ∁mn=n!(m−n)!m!
要用到乘法和除法,下面给出一种优化方式,可以仅用乘法求得组合数。
对于非负整数 a a a、 b b b, p i p_i pi为 a a a的质因数,则有:
a ! = p 1 α 1 p 2 α 2 p 3 α 3 . . . p k α k a! = p_1^{\alpha_1} p_2^{\alpha_2} p_3^{\alpha_3} ...p_k^{\alpha_k} a!=p1α1p2α2p3α3...pkαk
接下来求 p i p_i pi 的个数,设 f ( a , p ) f(a, p) f(a,p) 为 a ! a! a! 中质因子 p p p 的个数 ,则有下面的结论:
f ( a , p ) = ⌊ a p ⌋ + ⌊ a p 2 ⌋ + ⌊ a p 3 ⌋ + . . . = p 的倍数 + p 2 的倍数 + p 3 的倍数 + . . . \begin{aligned} f(a, p) &= \lfloor \cfrac{a}{p} \rfloor + \lfloor \cfrac{a}{p^2} \rfloor + \lfloor \cfrac{a}{p^3} \rfloor + ... \\ &= p的倍数+p^2的倍数+p^3的倍数+... \end{aligned} f(a,p)=⌊pa⌋+⌊p2a⌋+⌊p3a⌋+...=p的倍数+p2的倍数+p3的倍数+...
举例验证: 8 ! = 1 × 2 × 3 × 4 × 5 × 6 × 7 × 8 8!=1\times 2 \times 3 \times 4 \times 5 \times 6 \times 7 \times 8 8!=1×2×3×4×5×6×7×8 ,求其中 2 2 2 的个数。
- 含 2 2 2 的一次方的有 2 、 4 、 6 、 8 2、4、6、8 2、4、6、8 四个 2 2 2 。
- 含 2 2 2 二次方有 4 、 8 4、8 4、8 ,但 4 、 8 4、8 4、8 中 2 2 2 的一次方已经记过一次了,所以只加二次方中的两个 2 2 2 。
- 含 2 2 2 三次方有 8 8 8 ,但 8 8 8 中 2 2 2 的一次方已经记过一次了,所以只加三次方中的一个 2 2 2 。
同理可类推到 p k p^k pk 它的幂次中的前 k − 1 k−1 k−1 个 p p p,在计算 p 1 ∼ p k − 1 p^1∼p^{k−1} p1∼pk−1 次数中都已经算过一次。
α i \alpha_i αi 为 分子 a ! a! a! 中 质因数 p i p_i pi 的个数,减去 分母中 b ! ( a − b ) ! b!(a-b)! b!(a−b)! 中 质因数 p i p_i pi 的个数,得 α i ′ \alpha_i' αi′ 再把所有的质因数相乘,得到的结果就是组合数:
∁ a b = ∏ i = 1 k p i α i ′ \complement^b_a = \displaystyle\prod_{i=1}^{k}p_i^{\alpha_i'} ∁ab=i=1∏kpiαi′
代码:
#include <iostream>
#include <vector>
using namespace std;
const int N = 5010;
int primes[N], cnt, sum[N];
bool st[N];
void get_primes(int n)
{
for (int i = 2; i <= n; i++)
{
if (!st[i]) primes[cnt++] = i;
for (int j = 0; primes[j] <= n / i; j++)
{
st[primes[j] * i] = true;
if (i % primes[j] == 0) break;
}
}
}
// 获取n!中p质因子的个数
int get(int n, int p)
{
int res = 0;
while (n)
{
res += n / p;
n /= p;
}
return res;
}
// 高精度乘法
vector<int> mul(vector<int> &a, int b)
{
vector<int> res;
int t = 0;
for (int i = 0; i < a.size() || t; i++)
{
if (i < a.size()) t += a[i] * b;
res.push_back(t % 10);
t /= 10;
}
// 去掉前导0
while (res.size() > 1 && res.back() == 0) res.pop_back();
return res;
}
int main()
{
int a, b;
cin >> a >> b;
get_primes(a);
for (int i = 0; i < cnt; i++)
{
int p = primes[i];
sum[i] = get(a, p) - get(b, p) - get(a - b, p);
}
vector<int> res;
res.push_back(1);
for (int i = 0; i < cnt; i++)
for (int j = 0; j < sum[i]; j++)
res = mul(res, primes[i]);
for (int i = res.size() - 1; i >= 0; i--) printf("%d", res[i]);
return 0;
}
满足条件的01序列
思路:
将寻找满足条件的长度为 2 n 2n 2n 的序列的问题,转化为在直角坐标系中,从原点 ( 0 , 0 ) (0,0) (0,0) 出发到 ( n , n ) (n, n) (n,n) 的路径,一个路径对应一个 01 01 01 序列。假设向右走记为 0 0 0 ,向上走记为 1 1 1 。满足条件的序列要求前缀中 0 0 0 的个数不少于 1 1 1 的个数,即任意时刻向右走的步数大于向上走的步数, 路径经过的任意一点的坐标 ( x , y ) (x, y) (x,y) 满足 x ≥ y x \ge y x≥y ,所以路径都在直线 y = x y = x y=x 上及以下, 不满足条件的路径都会穿过直线 y = x + 1 y = x + 1 y=x+1 ,分析见如下示例:
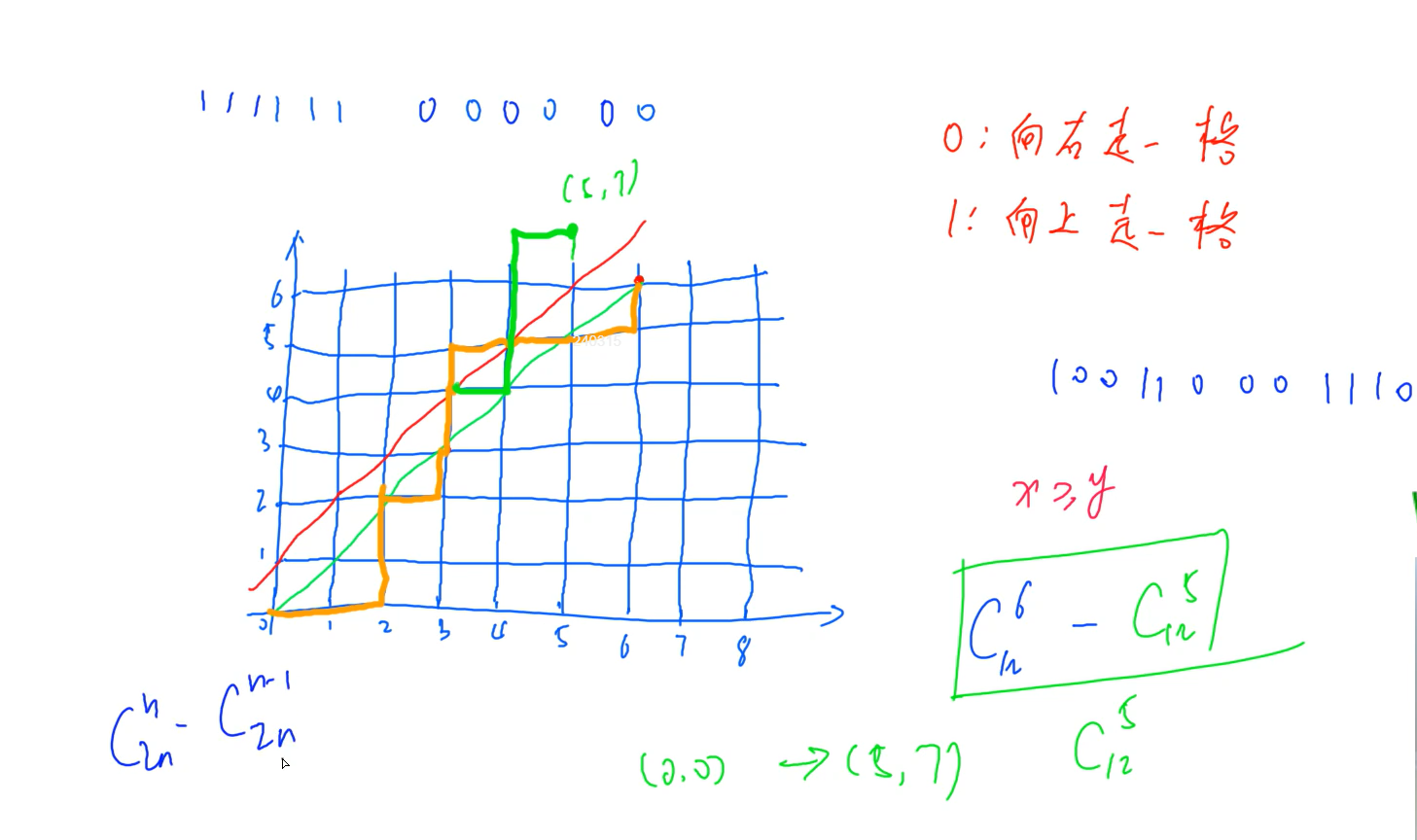
以 n = 6 n = 6 n=6 的情况进行分析,将不符合条件的路径在直线 y = x + 1 y = x + 1 y=x+1 上方的部分以直线 y = x + 1 y = x + 1 y=x+1 为对称轴做轴对称图形,由几何关系知,终点一定会到达 ( 5 , 7 ) (5,7) (5,7) 。到达 ( 6 , 6 ) (6, 6) (6,6) 的路径总数为 ∁ 12 6 \complement^6_{12} ∁126,不符合条件的路径总数等于 到达 ( 5 , 7 ) (5,7) (5,7) 的路径总数,值为 ∁ 12 5 \complement^5_{12} ∁125 ,所以符合条件的路径总数为 ∁ 12 6 − ∁ 12 5 \complement^6_{12} - \complement^5_{12} ∁126−∁125 ,将这一结论推广,得满足条件的长度为 2 n 2n 2n 的序列的总数为:
∁ 2 n n − ∁ 2 n n − 1 = ( 2 n ) ! n ! n ! − ( 2 n ) ! ( n − 1 ) ! ( n + 1 ) ! = ( 2 n ) ! ( n + 1 ) ( n + 1 ) ! n ! − ( 2 n ) ! n ( n + 1 ) ! n ! = ( 2 n ) ! ( n + 1 ) ! n ! = 1 n + 1 ( 2 n ) ! n ! n ! = 1 n + 1 ∁ 2 n n \begin{aligned} \complement^n_{2n} - \complement^{n-1}_{2n} &= \cfrac {(2n)!}{n!n!} - \cfrac {(2n)!}{(n-1)!(n+1)!} \\ &= \cfrac {(2n)!(n+1)}{(n+1)!n!} - \cfrac {(2n)!n}{(n+1)!n!}\\ &= \cfrac {(2n)!}{(n+1)!n!} \\ &= \cfrac 1 {n+1} \: \cfrac {(2n)!}{n!n!} \\ &= \cfrac 1 {n+1} \:\complement^n_{2n} \end{aligned} ∁2nn−∁2nn−1=n!n!(2n)!−(n−1)!(n+1)!(2n)!=(n+1)!n!(2n)!(n+1)−(n+1)!n!(2n)!n=(n+1)!n!(2n)!=n+11n!n!(2n)!=n+11∁2nn
1 n + 1 ∁ 2 n n \cfrac 1 {n+1} \:\complement^n_{2n} n+11∁2nn 也就是卡塔兰数 ( C a t a l a n n u m b e r ) (Catalan \: number) (Catalannumber) 。
代码:
#include <iostream>
using namespace std;
typedef long long ll;
const int mod = 1e9 + 7;
int qmul(int a, int k)
{
int res = 1;
while (k)
{
if (k & 1) res = (ll) res * a % mod;
k >>= 1;
a = (ll) a * a % mod;
}
return res;
}
int main()
{
int n;
cin >> n;
int a = 2 * n, b = n;
int ans = 1;
for (int i = 1, j = a; i <= b; i++, j--)
{
ans = (ll) ans * j % mod;
ans = (ll) ans * qmul(i, mod - 2) % mod;
}
ans = (ll)ans * qmul(n + 1, mod - 2) % mod;
cout << ans << endl;
return 0;
}
容斥原理
能被整除的数
思路:
首先,从一个例子引入容斥原理:
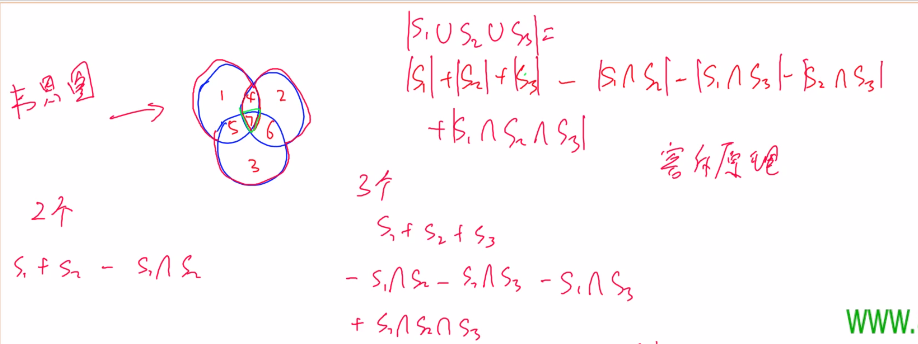
本题求解的思路与上一个例子中求解面积的思路类似,假设 S i S_i Si 为 1 ∼ n 1 \sim n 1∼n 中能被 p i p_i pi 整除的数的集合,则 ∣ S i ∣ \vert S_i \vert ∣Si∣ 表示集合 S i S_i Si 的元素个数,且 ∣ S i ∣ = ⌊ n p ⌋ \vert S_i \vert= \lfloor \cfrac n p \rfloor ∣Si∣=⌊pn⌋ , 1 ∼ n 1 \sim n 1∼n 中能被 p i p_i pi 、 p j p_j pj整除的数的集合表示为 S i ∩ S j S_i \cap S_j Si∩Sj , ∣ S i ∩ S j ∣ = ⌊ n p i p j ⌋ \vert S_i \cap S_j \vert= \lfloor \cfrac n {p_ip_j} \rfloor ∣Si∩Sj∣=⌊pipjn⌋ ,推广得:
1 ∼ n 1 \sim n 1∼n 中能被 p i p_i pi 、 p j p_j pj 、 p k p_k pk … 整除的数的集合表示为 S i ∩ S j ∩ S k . . . S_i \cap S_j \cap S_k... Si∩Sj∩Sk... , ∣ S i ∩ S j ∩ S k . . . ∣ = ⌊ n p i p j p j . . . ⌋ \vert S_i \cap S_j \cap S_k...\vert= \lfloor \cfrac n {p_ip_jp_j...} \rfloor ∣Si∩Sj∩Sk...∣=⌊pipjpj...n⌋ 。 ∣ S i ∪ S j . . . ∪ S n ∣ \vert S_i \cup S_j ...\cup S_n \vert ∣Si∪Sj...∪Sn∣ 表示 1 ∼ n 1 \sim n 1∼n 中能被 p i p_i pi 、 p j p_j pj 、 p k p_k pk … 中至少一个数整除的数的个数,最终的结果为:
∣ S i ∪ S j . . . ∪ S n ∣ = ∑ i ∣ S i ∣ − ∑ i , j ∣ S i ∩ S j ∣ + ∑ i , j , k ∣ S i ∩ S j ∩ S k ∣ + . . . + ( − 1 ) n − 1 ∑ i , j , k . . . n ∣ S i ∩ S j ∩ S k . . . ∩ S n ∣ \vert S_i \cup S_j ...\cup S_n \vert = \displaystyle\sum_{i} \vert S_i \vert-\displaystyle\sum_{i,j} \vert S_i \cap S_j\vert + \displaystyle\sum_{i,j,k} \vert S_i \cap S_j \cap S_k\vert +...+(-1)^{n-1}\displaystyle\sum_{i,j,k...n} \vert S_i \cap S_j \cap S_k...\cap S_n \vert ∣Si∪Sj...∪Sn∣=i∑∣Si∣−i,j∑∣Si∩Sj∣+i,j,k∑∣Si∩Sj∩Sk∣+...+(−1)n−1i,j,k...n∑∣Si∩Sj∩Sk...∩Sn∣
由组合计数的原理知,一共有 2 n − 1 2^n - 1 2n−1 个集合,时间复杂度为 O ( 2 n ) O(2^n) O(2n) ,可以枚举一个 n n n 位的二进制数,第 m m m 位为 1 1 1 表示包括这个集合,二进制数中 1 1 1 的个数为奇数时,系数为 1 1 1 ,否则为 − 1 -1 −1 。
代码:
#include <iostream>
using namespace std;
typedef long long ll;
const int N = 20;
int p[N];
int main()
{
int n, m;
cin >> n >> m;
int ans = 0;
for (int i = 0; i < m; i++) cin >> p[i];
for (int i = 1; i < 1 << m; i++)
{
// t为质因数的乘积, cnt为i中1的个数。
int t = 1, cnt = 0;
for (int j = 0; j < m; j++)
{
if (i >> j & 1)
{
cnt++;
// 质数乘积大于n, 就不用再考虑了
if ((ll)t * p[j] > n)
{
t = -1;
break;
}
t *= p[j];
}
}
if (t != -1)
{
if (cnt % 2) ans += n / t;
else ans -= n / t;
}
}
cout << ans << endl;
return 0;
}
博弈论
Nim游戏
思路:
给定 N N N 堆物品,第i堆物品有 A i A_i Ai 个。两名玩家轮流行动,每次可以任选一堆,取走任意多个物品,可把一堆取光,但不能不取。取走最后一件物品者获胜。两人都采取最优策略,问先手是否必胜。
我们把这种游戏称为 NIM 博弈。把游戏过程中面临的状态称为局面。整局游戏第一个行动的称为先手,第二个行动的称为后手。若在某一局面下无论采取何种行动,都会输掉游戏,则称该局面必败。
所谓采取最优策略是指,若在某一局面下存在某种行动,使得行动后对面面临必败局面,则优先采取该行动。同时,这样的局面被称为必胜。我们讨论的博弈问题一般都只考虑理想情况,即两人均无失误,都采取最优策略行动时游戏的结果。
NIM博弈不存在平局,只有先手必胜和先手必败两种情况。
定理: NIM博弈先手必胜,当且仅当 A 1 ⊕ A 2 ⊕ … ⊕ A n ≠ 0 A_1 \oplus A_2 \oplus … \oplus A_n \ne 0 A1⊕A2⊕…⊕An=0
为方便证明,引入两种状态:
- 先手必胜状态:通过变换可以变为必败状态的状态, A 1 ⊕ A 2 ⊕ … ⊕ A n ≠ 0. A_1 \oplus A_2 \oplus … \oplus A_n \ne 0. A1⊕A2⊕…⊕An=0.
- 先手必败状态:通过变换不可以变为必败状态的状态, A 1 ⊕ A 2 ⊕ … ⊕ A n = 0. A_1 \oplus A_2 \oplus … \oplus A_n = 0. A1⊕A2⊕…⊕An=0.
先手必胜状态:
假设
A
1
⊕
A
2
⊕
…
⊕
A
n
=
x
≠
0
A_1 \oplus A_2 \oplus … \oplus A_n = x \ne 0
A1⊕A2⊕…⊕An=x=0,
x
x
x 的二进制表示中最高位
1
1
1 在第
k
k
k 位,
A
1
,
A
2
.
.
.
A
n
A_1,A_2...A_n
A1,A2...An 中 必然有一个数
A
i
A_i
Ai 的第
k
k
k 位为
1
1
1 ,则有
A
i
⊕
x
<
A
i
A_i \oplus x \lt A_i
Ai⊕x<Ai,从第
i
i
i 堆中拿走
A
i
−
(
A
i
⊕
x
)
A_i - (A_i \oplus x)
Ai−(Ai⊕x)个,得第
i
i
i 堆中剩余个数:
A
i
′
=
A
i
−
(
A
i
−
(
A
i
⊕
x
)
)
=
A
i
⊕
x
A_i'=A_i - (A_i - (A_i \oplus x)) = A_i \oplus x
Ai′=Ai−(Ai−(Ai⊕x))=Ai⊕x
接下来的状态:
A 1 ⊕ A 2 ⊕ . . . ⊕ A i ′ . . . ⊕ A n = A 1 ⊕ A 2 ⊕ . . . ⊕ A i ⊕ x . . . ⊕ A n = A 1 ⊕ A 2 ⊕ … ⊕ A n ⊕ x = x ⊕ x = 0 \begin{aligned} A_1 \oplus A_2 \oplus ...\oplus A_i'...\oplus A_n&=A_1 \oplus A_2 \oplus ...\oplus A_i\oplus x...\oplus A_n \\ &=A_1 \oplus A_2 \oplus … \oplus A_n\oplus x \\ &= x \oplus x \\ &= 0 \end{aligned} A1⊕A2⊕...⊕Ai′...⊕An=A1⊕A2⊕...⊕Ai⊕x...⊕An=A1⊕A2⊕…⊕An⊕x=x⊕x=0
可以变为必败状态,因此处于先手必胜状态的先手在理想状态下必胜。
先手必败状态:
假设 A 1 ⊕ A 2 ⊕ … ⊕ A n = x = 0 A_1 \oplus A_2 \oplus … \oplus A_n = x = 0 A1⊕A2⊕…⊕An=x=0,经过理想变换得第 i i i 堆中剩余个数 A i ′ A_i' Ai′ 。
接下来的状态:
A 1 ⊕ A 2 ⊕ . . . ⊕ A i ′ . . . ⊕ A n = 0 = A 1 ⊕ A 2 ⊕ . . . ⊕ A i . . . ⊕ A n \begin{aligned} A_1 \oplus A_2 \oplus ...\oplus A_i'...\oplus A_n&=0 \\ &=A_1 \oplus A_2 \oplus ...\oplus A_i...\oplus A_n \\ \end{aligned} A1⊕A2⊕...⊕Ai′...⊕An=0=A1⊕A2⊕...⊕Ai...⊕An
得 A i ′ = A i A_i' = A_i Ai′=Ai ,又 A i ′ ≠ A i A_i' \ne A_i Ai′=Ai ,矛盾,因此先手必败状态无法通过变换变为必败状态,因此处于先手必败状态的先手在理想状态下必败。
代码
#include <iostream>
uisng namespace std;
int main()
{
int n, res = 0;
scanf("%d", &n);
while (n--)
{
int x;
scanf("%d", &x);
res ^= x;
}
puts(res ? "Yes" : "No");
return 0;
}
台阶-Nim游戏
思路:
台阶 Nim 游戏一种可行的解法是判断奇数台阶石子数异或值不等于0,则先手必胜。在此状态下,先手总有办法通过变换使奇数台阶石子数异或值等于0,此时,如果后手拿了奇数台阶的石子,先手可以通过移动其他奇数台阶的石子使奇数台阶石子数异或值等于0,如果后手拿了偶数台阶的石子,先手可以通过移动相同数量的石子使奇数台阶石子数异或值等于0,因此先手必胜。
对样例进行验证:
第一步先手可将3号台阶的1个石子移动到2号台阶,此时奇数台阶石子数异或值等于0,后手接下来有三种走法:
- 拿2号台阶的石子放到1号台阶,先手下一步可以将相同数量的石子放到地面,奇数台阶石子数异或值等于0
- 拿1号台阶的石子放到地面,先手可将相同数量的石子从3号台阶放到2号台阶,奇数台阶石子数异或值等于0
- 拿3号台阶的石子放到2号台阶,先手可将相同数量的石子从1号台阶放到地面,奇数台阶石子数异或值等于0
因此,只要一开始奇数台阶石子数异或和不等于0,先手总能通过移动石子使奇数台阶石子数异或和等于0,因此先手必胜。
代码:
#include <iostream>
using namespace std;
int main()
{
int n, res = 0;
scanf("%d", &n);
for (int i = 1; i <= n; i++)
{
int x;
scanf("%d", &x);
if (i % 2) res ^= x;
}
puts(res ? "Yes" : "No");
return 0;
}
集合-Nim游戏

思路:
与上题不同的是,每次拿取的石子数量是有限制的,包含于集合 S S S 中。从当前状态拿取不同的石子接下来的状态是可以追溯可以枚举的,可以看作从当前状态可以用箭头指向多个状态,类似于有向图,因此本题也是一个有向图游戏问题。
有向图游戏:
给定一个有向无环图,图中有一个唯一的起点,在起点上放有一枚棋子。两名玩家交替地把这枚棋子沿有向边进行移动,每次可以移动一步,无法移动者判负。该游戏被称为有向图游戏。
任何一个公平组合游戏都可以转化为有向图游戏。具体方法是,把每个局面看成图中的一个节点,并且从每个局面向沿着合法行动能够到达的下一个局面连有向边。
为了便于分析有向图游戏问题,引入两个概念:
- M e x Mex Mex 运算
- S G SG SG 函数
M e x Mex Mex 运算:
设 S S S 表示一个非负整数集合。定义 m e x ( S ) mex(S) mex(S) 为求出不属于集合 S S S 的最小非负整数的运算,即:
m e x ( S ) = m i n { x } mex(S) = min\{x\} mex(S)=min{x}, x x x 属于自然数,且 x x x 不属于 S S S。
S G SG SG函数:
在有向图游戏中,对于每个节点 x x x ,设从 x x x 出发共有 k k k 条有向边,分别到达节点 y 1 , y 2 , … , y k y1, y2, …, yk y1,y2,…,yk ,定义 S G ( x ) SG(x) SG(x) 为 x x x 的后继节点 y 1 , y 2 , … , y k y1, y2, …, yk y1,y2,…,yk 的 S G SG SG 函数值构成的集合再执行 m e x ( S ) mex(S) mex(S) 运算的结果,即:
S G ( x ) = m e x ( { S G ( y 1 ) , S G ( y 2 ) , … , S G ( y k ) } ) SG(x) = mex(\{SG(y1), SG(y2), …, SG(yk)\}) SG(x)=mex({SG(y1),SG(y2),…,SG(yk)})
特别地,整个有向图游戏 G G G 的 S G SG SG 函数值被定义为有向图游戏起点 s s s 的 S G SG SG 函数值,即 S G ( G ) = S G ( s ) SG(G) = SG(s) SG(G)=SG(s) 。
定理:
有向图游戏的某个局面必胜,当且仅当该局面对应节点的
S
G
SG
SG 函数值大于0。
有向图游戏的某个局面必败,当且仅当该局面对应节点的
S
G
SG
SG 函数值等于0。
下面举个例子更好理解:
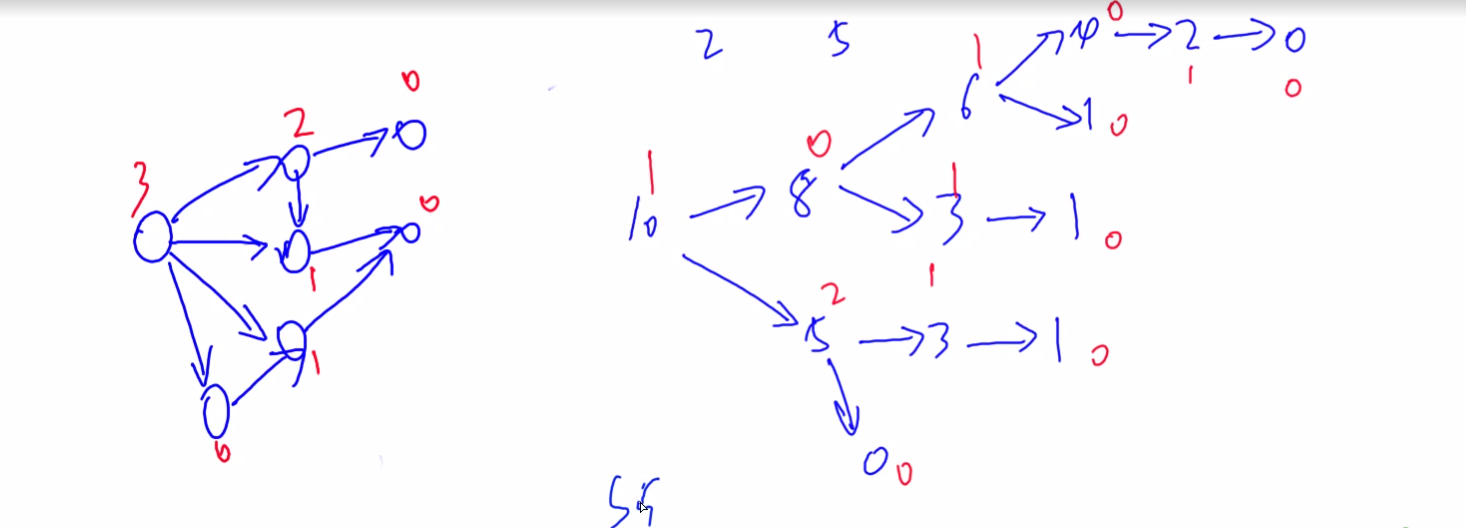
有向图游戏的和的
S
G
SG
SG 函数值等于它包含的各个子游戏
S
G
SG
SG 函数值的异或和,即:
S
G
(
G
)
=
S
G
(
G
1
)
⊕
S
G
(
G
2
)
⊕
…
⊕
S
G
(
G
m
)
SG(G) = SG(G_1) \oplus SG(G_2) \oplus … \oplus SG(G_m)
SG(G)=SG(G1)⊕SG(G2)⊕…⊕SG(Gm)
证明过程与上题类似。
对于有向图问题计算 S G SG SG 值问题可以用到记忆化搜索,保证每个节点最多只遍历一次,时间复杂度为 O ( n k ) O(nk) O(nk) 。
代码:
#include <iostream>
#include <cstring>
#include <set>
using namespace std;
const int N = 110, M = 10010;
// s表示数字集 f[i]表示数量为i的石子的sg值
int s[N], f[M];
int n, k;
int sg(int x)
{
if (f[x] != -1) return f[x];
set<int> S;
for (int i = 0; i < k; i++)
if (x >= s[i]) S.insert(sg(x - s[i]));
for (int i = 0; ; i++)
if (!S.count(i))
return f[x] = i;
}
int main()
{
cin >> k;
for (int i = 0; i < k; i++) cin >> s[i];
memset(f, -1, sizeof f);
int res = 0;
cin >> n;
for (int i = 0; i < n; i++)
{
int x;
cin >> x;
res ^= sg(x);
}
puts(res ? "Yes" : "No");
return 0;
}
拆分-Nim游戏
思路:
假设一个局面为 a i a_i ai ,根据题意可以拆分为两个局面,设为 ( b i , b j ) . . . (b_i,b_j)... (bi,bj)...,且 ∣ a i ∣ > ∣ b i ∣ ≥ ∣ b j ∣ \vert a_i \vert > |b_i| \ge|b_j| ∣ai∣>∣bi∣≥∣bj∣,根据有向图游戏的性质, s g ( a i ) = s g ( b i ) ⊕ s g ( b j ) sg(a_i) =sg(b_i) \oplus sg(b_j) sg(ai)=sg(bi)⊕sg(bj),局面 a i a_i ai 可以分为 ∣ a i ∣ 2 |a_i|^2 ∣ai∣2 种不同的局面,局面 a i a_i ai 划分的所有局面的 s g sg sg 值异或起来的值就是 s g ( a i ) sg(a_i) sg(ai),最后的结果为:
s g ( a ) = s g ( a 1 ) ⊕ s g ( a 2 ) ⊕ s g ( a 2 ) ⊕ . . . ⊕ s g ( a n ) sg(a) = sg(a_1) \oplus sg(a_2) \oplus sg(a_2) \oplus ... \oplus sg(a_n) sg(a)=sg(a1)⊕sg(a2)⊕sg(a2)⊕...⊕sg(an)
若 s g ( a ) ≠ 0 sg(a) \ne 0 sg(a)=0 ,先手必胜,否则必败。
代码:
#include <iostream>
#include <cstring>
#include <set>
using namespace std;
const int N = 110;
int f[N];
int sg(int x)
{
if (f[x] != -1) return f[x];
set<int> s;
for (int i = 0; i < x; i++)
for (int j = 0; j <= i; j++)
s.insert(sg(i) ^ sg(j));
for (int i = 0; ; i++)
{
if (!s.count(i))
return f[x] = i;
}
}
int main()
{
int n, res = 0;
cin >> n;
memset(f, -1, sizeof f);
for (int i = 0; i < n; i++)
{
int x;
cin >> x;
res ^= sg(x);
}
puts(res ? "Yes" : "No");
return 0;
}














 8651
8651











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









