





VisualBERT是一个简单而灵活的框架,用于对广泛的视觉和语言任务建模。VisualBERT由一堆Transformer层组成,这些层利用自注意力机制将输入文本元素和相应的输入图像区域隐式对齐。作者进一步提出了两个基于视觉的语言模型目标,用于在图像字幕数据上预训练VisualBERT。
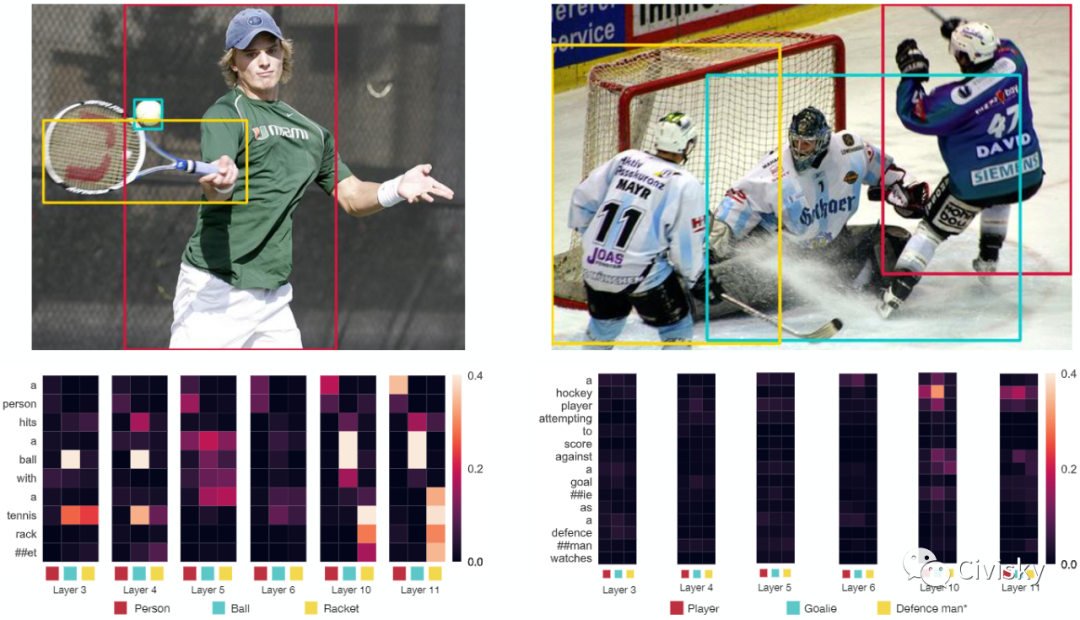
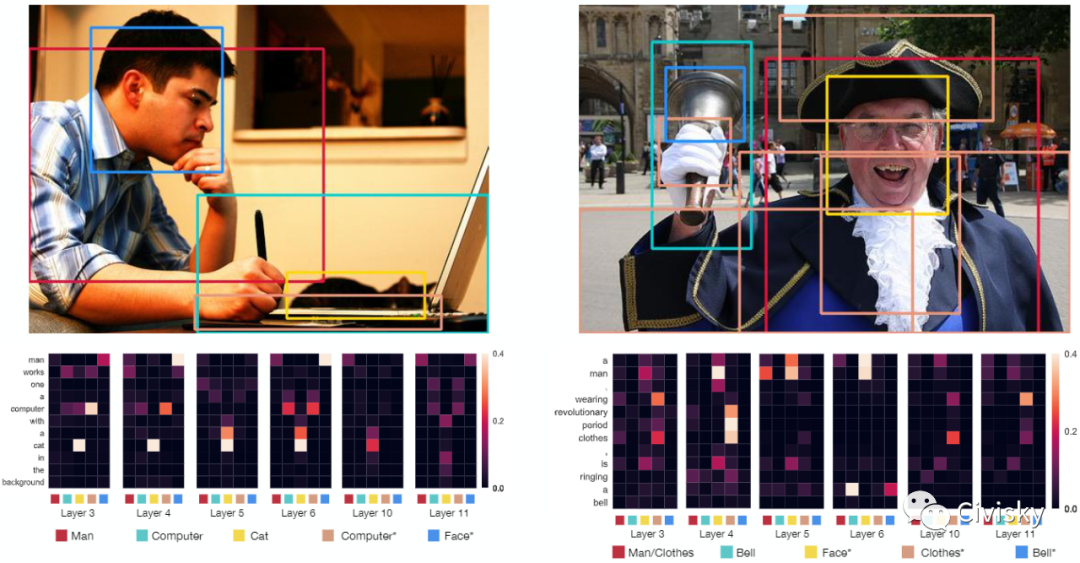
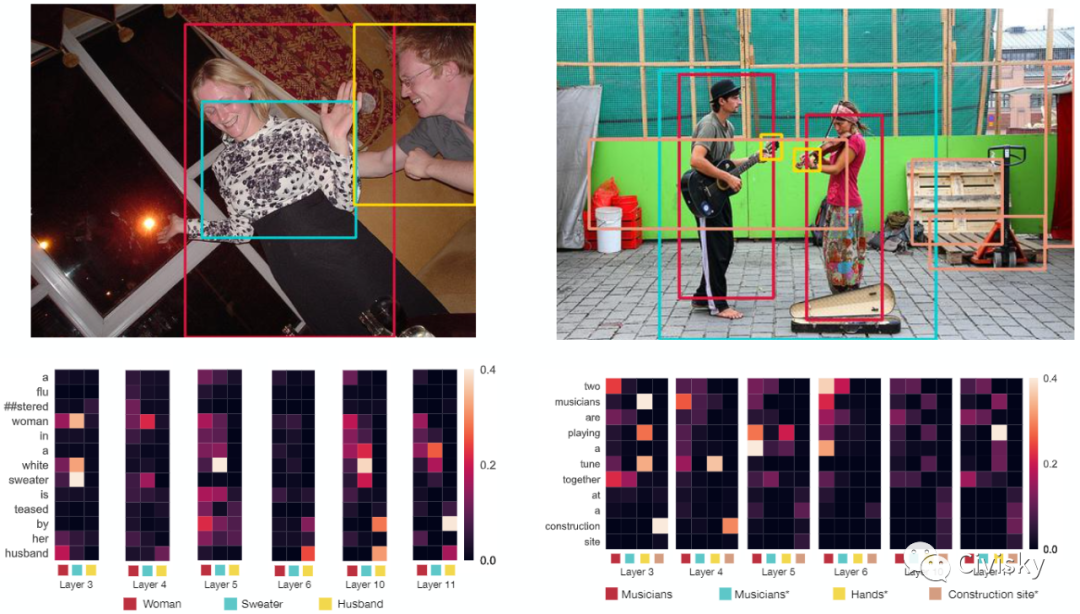
在VQA、VCR、NLVR和Flickr30K四种视觉-语言任务上的实验表明,VisualBERT在显著简化的同时,其性能优于或相当于最先进的模型。进一步的分析表明,VisualBERT可以在没有任何显式监督的情况下建立语言元素和图像区域之间的联系,甚至对句法关系和追踪有一定敏感性。















 1368
1368











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









