







- 实验目的
1、编程实现PCA,对所提供数据(data.txt)进行主成分分析,低维空间维度d’=1
2、数据形式为[x1, x2],其中x1,x2为样本属性
- 实验内容:
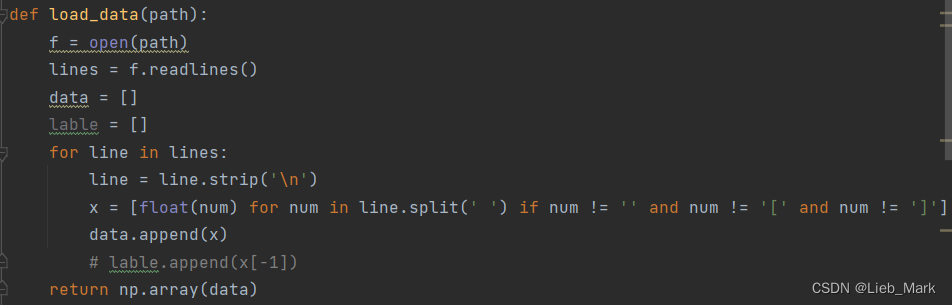
1、数据中含有“[”,“]”python读入时不能自己处理,所以使用f.readlines将内容读为字符串,遍历每一行,去除行末回车和左右中括号,数据转为float类型,数据放到data中并转array返回。
2、按照pca的步骤进行,首先对数据中心化,即减去平均值;然后使用np.cov求出样本的协方差;np.linalg.eig求出协方差矩阵的特征值和特征向量;对根据特征值的大小排序,因为这里要将成一维,所以找出特征值最大的特征向量作为投影矩阵,和原数据进行相乘得出降维后的值。
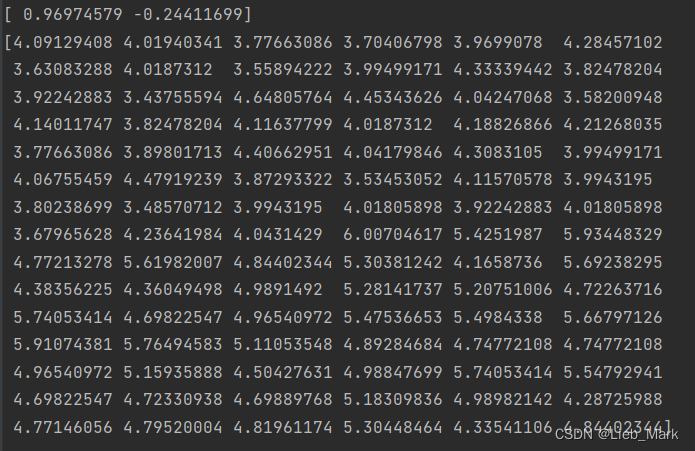
实验结果:
投影矩阵为:[ 0.96974579 -0.24411699]
- 实验原理:



- 心得体会:
实验的步骤比较简单,求特征值、特征矩阵、协方差矩阵等内容都可以使用numpy的内置函数解决。但是实验的原理理解起来花费了一些时间,通过在知乎上查找讲解,最后看明白了。在实验中进一步体会到了线性代数的精妙和重要性,以及对协方差矩阵、特征向量等的意义有了进一步的了解。
同时认识到了pca降维在机器学习中可以解决维度灾难,减小噪声等效果。巩固所学知识,为以后的学习打下坚实的基础。
import numpy as np
import matplotlib.pyplot as plt
def load_data(path):
f = open(path)
lines = f.readlines()
data = []
lable = []
for line in lines:
line = line.strip('\n')
x = [float(num) for num in line.split(' ') if num != '' and num != '[' and num != ']']
data.append(x)
# lable.append(x[-1])
return np.array(data)
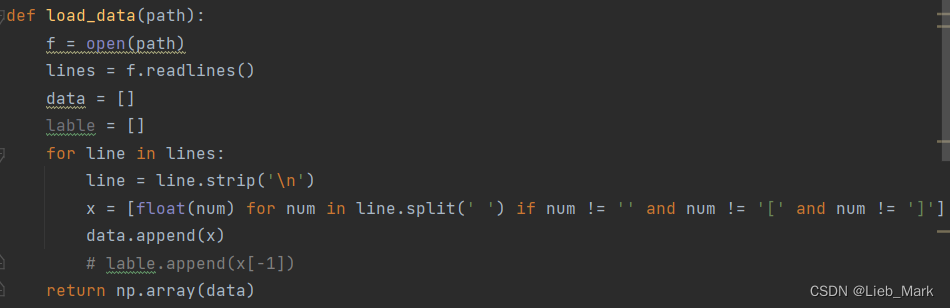
def pca(data, d):
mean = np.mean(data, axis=0)
source_data = data.copy()
data -= mean
cov = np.cov(data.T)
eigvals, eigvecs = np.linalg.eig(cov)
idx = np.argsort(eigvals)[::-1]
w = eigvecs[:, idx[0]]
return w, source_data.dot(w)
data = load_data(r'data.txt')
w, y = pca(data, 1)
print(w)
print(y)
















 2679
2679











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









