






最近在克隆yolov5的时候,简单的做了一下数据集,在此总结一下自己的制作过程,还有一些小的技巧。
我用的是制作yolo标签常用的工具labelimg,labelimg具体怎么安装,在此省写,可以在csdn搜索相关的博客下载,本文是在大家已经具备labelimg下进行演示。
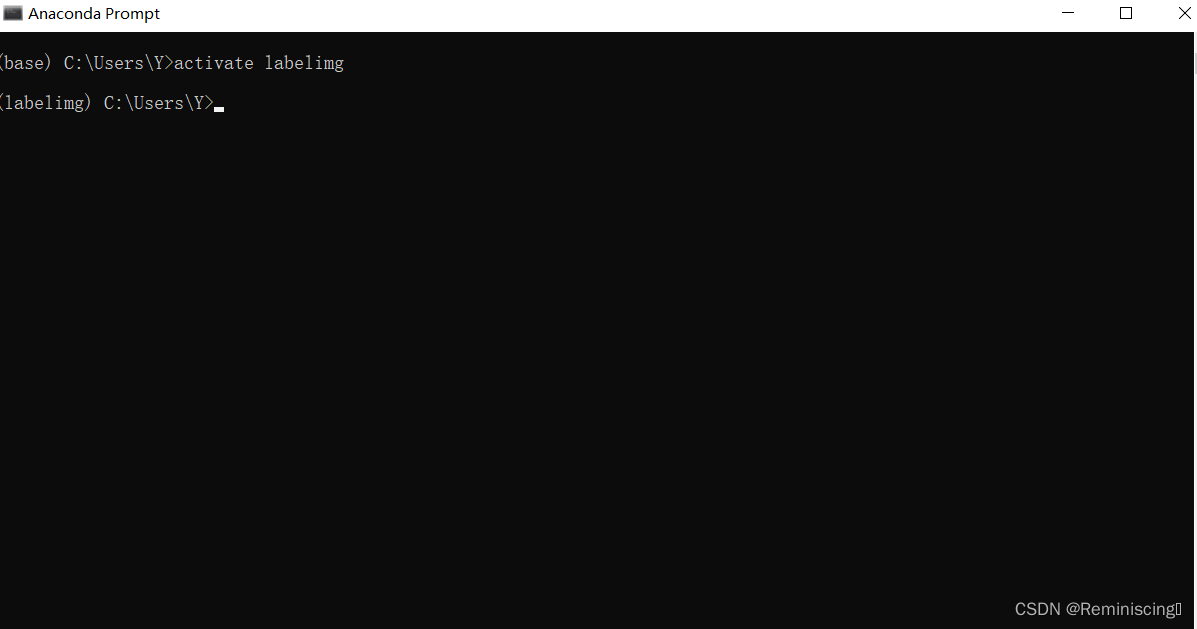
首先,大家可以打开anaconda prompt,输进去activate labelimg,接着输进去labelimg,打开labelimg,进行图像标注,下面图片展示。

然后建立一个文件夹mydatas,里面设置四个小的文件夹,如图所示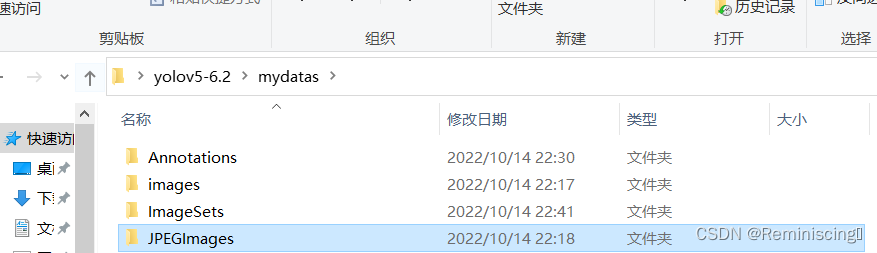
在images和JPEGImages中存放相同的照片,打开刚刚打开的labelimg软件,进行如下操作。 
ps:labelimg打标签的时候,要设置voc格式,还有一些小的快捷键,键盘的w是画框,a是上一张,d是下一张,工具栏中view中的第一个记得勾上,可以自动保存图,我给演示一个打标签的图片,如图所示,标签尽量用英文,我再看其他人的博客时候,用中文标注的时候,最后预测框,可能会出现乱码,还是最好用英文标注一下。
但是有的时候,可能觉得自己的图片有点少,我们可以继续图像增强操作,下面给大家附上一个百度网盘,是别人制作的,里面有说明,操作比较简单,不懂的可以来问我。http://链接:https://pan.baidu.com/s/1drtkGYXFDynL1-hQPz6Uhw 提取码:05za
还有一个小小的技巧就是,有的时候图片名字比较乱,我给大家推荐一个好压软件,可批量进行图片重新命名的操作,如图所示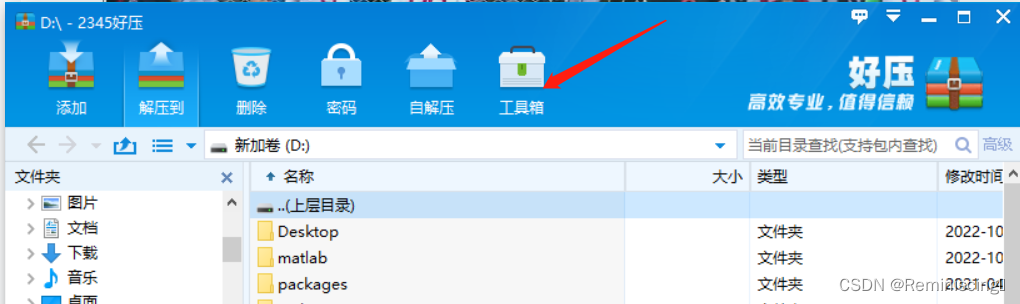
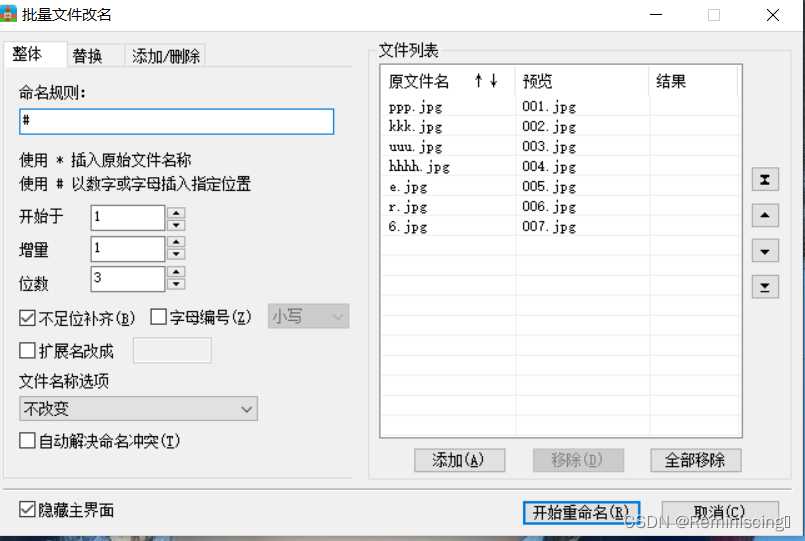
打标签做好之后,把创建的mydatas文件夹复制到yolov5的目录中去,我用的是pycharm打开的。

下面进行的是,划分训练集集,测试集,代码如下,这一部分基本不用修改,运行即可。
import os
import random
trainval_percent = 1
train_percent = 0.9
xmlfilepath = 'mydatas/Annotations'
txtsavepath = 'mydatas/ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv)
train = random.sample(trainval, tr)
ftrainval = open('mydatas/ImageSets/trainval.txt', 'w')
ftest = open('mydatas/ImageSets/test.txt', 'w')
ftrain = open('mydatas/ImageSets/train.txt', 'w')
fval = open('mydatas/ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftrain.write(name)
else:
fval.write(name)
else:
ftest.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()
在annotations下出现四个文本,
下一步,创建一个py,把标记的labels转换成txt文件,代码如下
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
sets = ['train', 'test', 'val']
classes = ['boltl', 'gear', 'nut', 'shaft']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('mydatas/Annotations/%s.xml' % (image_id),encoding='utf-8')
out_file = open('mydatas/labels/%s.txt' % (image_id), 'w',encoding='utf-8')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('mydatas/labels/'):
os.makedirs('mydatas/labels/')
image_ids = open('mydatas/ImageSets/%s.txt' % (image_set)).read().strip().split()
list_file = open('mydatas/%s.txt' % (image_set), 'w')
for image_id in image_ids:
list_file.write('mydatas/images/%s.jpg\n' % (image_id))
convert_annotation(image_id)
list_file.close()
值得要注意的是,这个代码中要修改几个地方,就是你自己打标签的名字,换成你自己的就可以了。
到此为止,数据集制作完成。
下面我给大家一个yaml文件,代码如下,
# YOLOv5 🚀 by Ultralytics, GPL-3.0 license
# COCO 2017 dataset http://cocodataset.org by Microsoft
# Example usage: python train.py --data coco.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco ← downloads here (20.1 GB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
#path: ../mydatas/ # dataset root dir
train: mydatas/train.txt # train images (relative to 'path') 118287 images
val: mydatas/val.txt # val images (relative to 'path') 5000 images
test: mydatas/test.txt # 20288 of 40670 images, submit to https://competitions.codalab.org/competitions/20794
# Classes
nc: 4 # number of classes
names: ['boltl', 'gear', 'nut', 'shaft'] # class names
# Download script/URL (optional)
download: |
from utils.general import download, Path
# Download labels
segments = False # segment or box labels
dir = Path(yaml['path']) # dataset root dir
url = 'https://github.com/ultralytics/yolov5/releases/download/v1.0/'
urls = [url + ('coco2017labels-segments.zip' if segments else 'coco2017labels.zip')] # labels
download(urls, dir=dir.parent)
# Download data
urls = ['http://images.cocodataset.org/zips/train2017.zip', # 19G, 118k images
'http://images.cocodataset.org/zips/val2017.zip', # 1G, 5k images
'http://images.cocodataset.org/zips/test2017.zip'] # 7G, 41k images (optional)
download(urls, dir=dir / 'images', threads=3)
需要修改以下几个部分,修改即可
然后打开train.py修改对应的参数就可以进行训练。














 985
985











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









