







 超级会员免费看
超级会员免费看
模型选择
模型能力强的复杂度高,容易导致过拟合。
模型能力弱,又容易导致欠拟合。
1、引入验证集
将训练集分为两部分。训练集和验证集
但需遵循:
- 训练集中样本数量必须足够多,一般至少大于总样本数的一半
- 两组数据集必须从完整数据集中均匀取样,减少偏差。
验证集其实就是对模型的能力进行初步的评估。
交叉验证
如果我们数据本身就有限,将数据分为训练集和验证集导致数据稀疏问题。
为了解决这个问题,所以我们使用交叉验证方法。
交叉验证:
将训练集分为S组,每次取S-1组作为训练集,剩下的一组作为验证集。
取验证集中平均性能最好的一组模型。
2、模型选择准则
AIC(赤池信息准则)
公式:
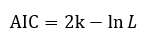
其中k为模型参数个数,n为样本数量,L为似然函数。训练模型时,增加参数数量,也就是增加模型复杂度,会增大似然函数,但是也会导致过拟合现象。kln(n)惩罚项在样本数量较多的情况下可有效防止模型精度过高造成模型复杂度过高的问

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 720
720











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











