







机器学习实战1-基础运用
文章目录
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from scipy.stats import norm
from numpy.linalg import inv,eig
numpy的简单运用
生成矩阵和矩阵的简单操作
- 注意矩阵生成时
array()中填写的时一个二维列表,每个小列表代表矩阵的一行 - 注意
@表示矩阵乘法, 向量的点乘利用矩阵乘法实现,也可使用dot方法 np.linalg.inv()函数用于求逆,也可以在import时直接引入.T属性表示该矩阵的转置eig()函数用于求其特征值和特征向量,返回这两个值
a = np.array([[2,3],[1,2]]);print(f'a={a}')
b = np.array([[1],[2]]);print(f'b={b}')
c = a@b ;print(f'c={c}') #矩阵乘法
d = a*b ; print(f'd={d}') #各个元素分别相乘
print(f'a.T = {a.T}')
# a_1 = np.linalg.inv(a);
a_1 = inv(a) #上方直接从numpy中引入inv函数
print(f'inv(a) = {a_1}')
a_eigval,a_eigvector = eig(a)
print(f'a的特征值={a_eigval},a的特征向量={a_eigvector}')
a=[[2 3]
[1 2]]
b=[[1]
[2]]
c=[[8]
[5]]
d=[[2 3]
[2 4]]
a.T = [[2 1]
[3 2]]
inv(a) = [[ 2. -3.]
[-1. 2.]]
a的特征值=[3.73205081 0.26794919],a的特征向量=[[ 0.8660254 -0.8660254]
[ 0.5 0.5 ]]
用pandas库读取、保存csv数据文件
read_csv()函数及读入的数据处理
- 主要使用
read_csv()函数,常指定的参数有filepath_or_buffer路径、sep分隔符、header 导入为的列名称、names 没有赋值时指定第一列为列名,engine 解析引擎:有c(快)和python(全面);同时需要注意,读取后得到一个DataFrame格式的数据(类似字典,可以访问其键值数据)。常用属性和方法如下:- 可以使用键值下标直接访问数据的某一列,转置(访问其
.T属性)后同样使用键值下标访问某一行 - 使用
.shape属性查看大小 - 使用
.columns属性查看列名称 replace(a,b,inplace = True/False)将数据中的a全部使用b代替,同时,inplace参数决定是否在原数据上修改,如果是False,将会将修改后的数据返回isnull()得到一个逻辑下标的矩阵,True表示其为NaN,False表示其不为NaN,sum()方法可以对一列数据求和,求行和时可以先转置再求和dropna(axis = ,how = ,thresh=,inplace=)去除数据中nan的数据- 可选参数axis表示按行(0/‘index’)还是按列(1/‘columns’)
- 可选参数how表示筛选方式’any’表示只要有一个就删除该行/列,all表示只有整行/列是空值才删除
- 可选参数thresh 非空元素最低数量。int型,默认为None。如果该行/列中,非空元素数量小于这个值,就删除该行/列。
- 可选参数 inpalce,是否原地替换
.index可以输出一组数据的下标
- 可以使用键值下标直接访问数据的某一列,转置(访问其
path = ".\\adult.data"
Cnames = ['age', 'wc', 'fnlwgt', 'edu', 'edu_num',
'ms', 'occ', 'rs', 'race', 'sex',
'cap_g', 'cap_l', 'hpw', 'native', 'y'] #列名称的list
data = pd.read_csv(filepath_or_buffer = path, sep = ', ',
header=None,names= Cnames,engine='python')
print(type(data))
wc_data = data['wc'];print(wc_data) #访问某一列
print(data.shape) #查看大小
print(data.columns) #查看列名称
wc_data.replace('?',np.NaN,inplace=True) #将所有的缺失值以nan代替
wc_data_isnull = wc_data.isnull()
print(wc_data_isnull)
print(f'data_shape = {wc_data.shape}')
wc_data.dropna(axis=0,inplace= True) #按行删除
print(f'data_shape = {wc_data.shape}')
print(wc_data.index) #输出筛选后的下标
<class ‘pandas.core.frame.DataFrame’>
0 State-gov
1 Self-emp-not-inc
2 Private
3 Private
4 Private
…
32556 Private
32557 Private
32558 Private
32559 Private
32560 Self-emp-inc
Name: wc, Length: 32561, dtype: object
(32561, 15)
Index([‘age’, ‘wc’, ‘fnlwgt’, ‘edu’, ‘edu_num’, ‘ms’, ‘occ’, ‘rs’, ‘race’,
‘sex’, ‘cap_g’, ‘cap_l’, ‘hpw’, ‘native’, ‘y’],
dtype=‘object’)
0 False
1 False
2 False
3 False
4 False
…
32556 False
32557 False
32558 False
32559 False
32560 False
Name: wc, Length: 32561, dtype: bool
data_shape = (32561,)
data_shape = (30725,)
Int64Index([ 0, 1, 2, 3, 4, 5, 6, 7, 8,
9,
…
32551, 32552, 32553, 32554, 32555, 32556, 32557, 32558, 32559,
32560],
dtype=‘int64’, length=30725)
to_csv()保存数据
- 使用
to_csv()函数可以将数据保存为csv格式,常指定的参数有filepath_or_buffer路径、sep分隔符、header 是否保存列名,index是否保留索引等。
wc_data.to_csv(path_or_buf=".\\wc.data",sep=',',header=True,index=True)
matplotlib.pyplot库绘图的使用
条形图的绘制
使用plt.hist 函数,常用的可选参数有如下:
| 属性 | 说明 | 类型 |
|---|---|---|
| x | 数据 | 数值类型 |
| bins | 条形数 | int |
| color | 颜色 | “r”,“g”,“y”,“c” |
| density | 是否以密度的形式显示 | bool |
| range | x轴的范围 | 数值元组(起,终) |
| bottom | y轴的起始位置 | 数值类型 |
| histtype | 线条的类型 | “bar”:方形,“barstacked”:柱形,“step”:“未填充线条”;“stepfilled”:“填充线条” |
| align | 对齐方式 | “left”:左,“mid”:中间,“right”:右 |
注意:
- 其会将输入数据x的中数据值的个数作为纵坐标,数据值作为横坐标,即其表示的实际上是数据的频率直方图
- bins 表示条形的多少,即横坐标的"采样宽度",每个区间条的宽度
y = [1,1,2,2,5]
plt.hist(y,bins = 30,range=(0,15),histtype="barstacked",align="mid") #在0-15内采分30份间隔做数据的频率直方图
(array([0., 0., 2., 0., 2., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]),
array([ 0. , 0.5, 1. , 1.5, 2. , 2.5, 3. , 3.5, 4. , 4.5, 5. ,
5.5, 6. , 6.5, 7. , 7.5, 8. , 8.5, 9. , 9.5, 10. , 10.5,11. , 11.5, 12. , 12.5, 13. , 13.5, 14. , 14.5, 15. ]),
<BarContainer object of 30 artists>)
箱型图的绘制
分位数(Quantile)分位点/四分位数
- 分位数指的就是连续分布函数中的一个点,这个点对应概率。若概率,随机变量或它的概率分布的分位数,是指满足条件的实数。
- 四分位数即数据中位于全部数据25%,50%(中位数),75%的三个点的数据值
分位数与箱型图
- 箱<==>25%到75% ,其长度为IQR
- 上限值<==> 箱顶+1.5IQR
- 下限值<==> 箱底+1.5IQR
- 上相邻值<==> 与上限值最接近的数据值
- 下相邻值<==> 与下限值最接近的数据值
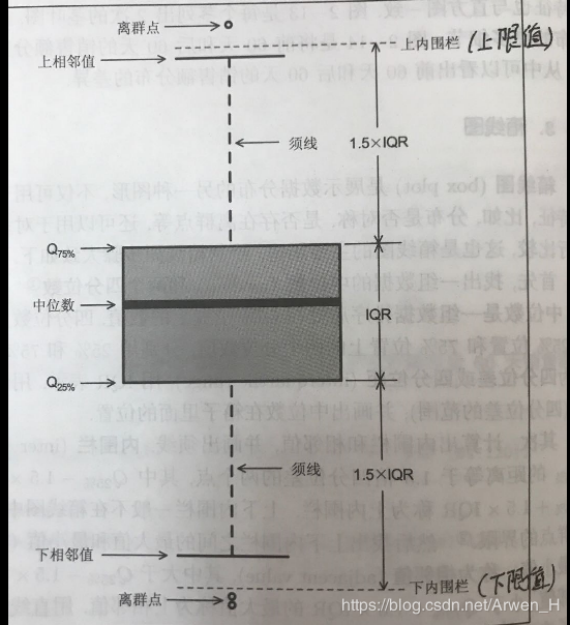
boxplot()函数
- 使用
boxplot()可绘制,输入的数据为列表,列表的一列为一条箱型图 - 可使用
xticks([1,2],[第一二列名字])
data1,data2 =[[0,1,2,4,5,9,9,11,2,24],[8,2,9,5,7,4,11,8,25,5]]
plt.boxplot([data1,data2])
plt.xticks([1,2],["data1","data2"])
# print(data1)
([<matplotlib.axis.XTick at 0x257122f1be0>,
<matplotlib.axis.XTick at 0x257122f1bb0>],
[Text(1, 0, ‘data1’), Text(2, 0, ‘data2’)])
绘制交叉报表
- 主要使用pandas中的
crosstab()函数,输入两组数据,绘制其交叉表 - 对于具有大量数据值的函数,可以使用
qcut(数据,[分位点列表]),可以按分位点列表划分成离散化数据,利于绘制交叉表 - 同时交叉表对象
- 可使用
.plot.bar()绘制竖直的条形图 - 可使用
.plot.barh()绘制水平的条形图
- 可使用
data_1q = pd.qcut(data1,[0,.25,.5,.75,1]) #四分类
data_2q = pd.qcut(data2,[0,.25,.5,.75,1]) #四分类
# print(data_1q,data_2q)
cross_tab = pd.crosstab(data_1q,data_2q)
print(cross_tab)
cross_tab.plot.bar()
col_0 (1.999, 5.0] (5.0, 7.5] (7.5, 8.75] (8.75, 25.0]
row_0
(-0.001, 2.0] 1 0 1 2
(2.0, 4.5] 1 0 0 0
(4.5, 9.0] 1 1 0 1
(9.0, 24.0] 1 0 1 0<AxesSubplot: xlabel=‘row_0’>
热力图
- 热力图常是用于展示数据间的相关关系
- 可使用
np.corrcoef(数据)函数生成数据之间的相关性 - 绘制热力图时需要使用
seaborn库, heatmap(corr_mat, cbar = 是否有颜色条, annot=是否显示相关数据在图像中, square = 是否方格, annot_kws = {'size': 20 数据字体大小}, yticklabels = 列标签, xticklabels = 行标签)
import seaborn as sns
cor = np.corrcoef([data1,data2]) #注意相关性是针对行的,所以仅对2行2列进行相关性分析
print(cor)
# sns.heatmap(cor,cbar=True,annot=True,square=True,annot_kws={'size':20},
# yticklabels=data1,xticklabels=data2)
sns.heatmap(cor,cbar=True,annot=True,square=True,annot_kws={'size':20})
[[ 1. -0.23026207]
[-0.23026207 1. ]]<AxesSubplot: >
plt绘图基础
- 使用
plot(x,y,color = "颜色",label = "标签")标签可用于legend显示 - 使用
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #中文标签可展示中文标签 - 使用
plt.legend()可显示标签 - 使用
plt.title("Q-Q图")可显示图像标题 - 使用
plt.xlabel("x轴说明");plt.ylabel("y轴说明")可显示坐标轴说明
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei'] #中文标签
x= np.arange(0,10,0.1)
plt.plot(x,np.sin(x),color = "red",label = "sin(x)")
plt.plot(x,np.sin(2*x),color = "blue",label = "sin(2x)")
plt.title("sin(x)和sin(2x)的图像")
plt.xlabel("x")
plt.ylabel("y")
plt.legend()
<matplotlib.legend.Legend at 0x257135ce400>
















 1333
1333

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









