









前言
索引是存储引擎用于快速找到记录的一种数据结构,索引对于良好的性能非常关键,特别是随着数据量的加大,索引对性能的影响越发重要,但是日常工作中索引经常被忽略,造成经常遇到糟糕索引导致的性能问题。索引优化是对查询性能优化最有效的手段,索引能够轻易将查询性能提高几个数量级,创建一个真正的最优索引,应该是研发追求的目标。
所谓索引其实就是我们日常经常使用目录,协助我们尽快找到需要的内容。索引有很多种类型,为不同的场景提供更好的性能。在MySQL中,索引是在存储引擎层实现,而不是在服务器层实现,所以并没有统一的索引标准。小编的日常工作中最常见的引擎是InnoDB,本文主要讲解InnoDB引擎支持的索引类型。底层存储引擎可能使用了不同的存储结构,索引是在存储引擎层实现的,所以本质上索引也是利用数据结构实现的。
B-Tree索引
数据结构就是B+Tree。
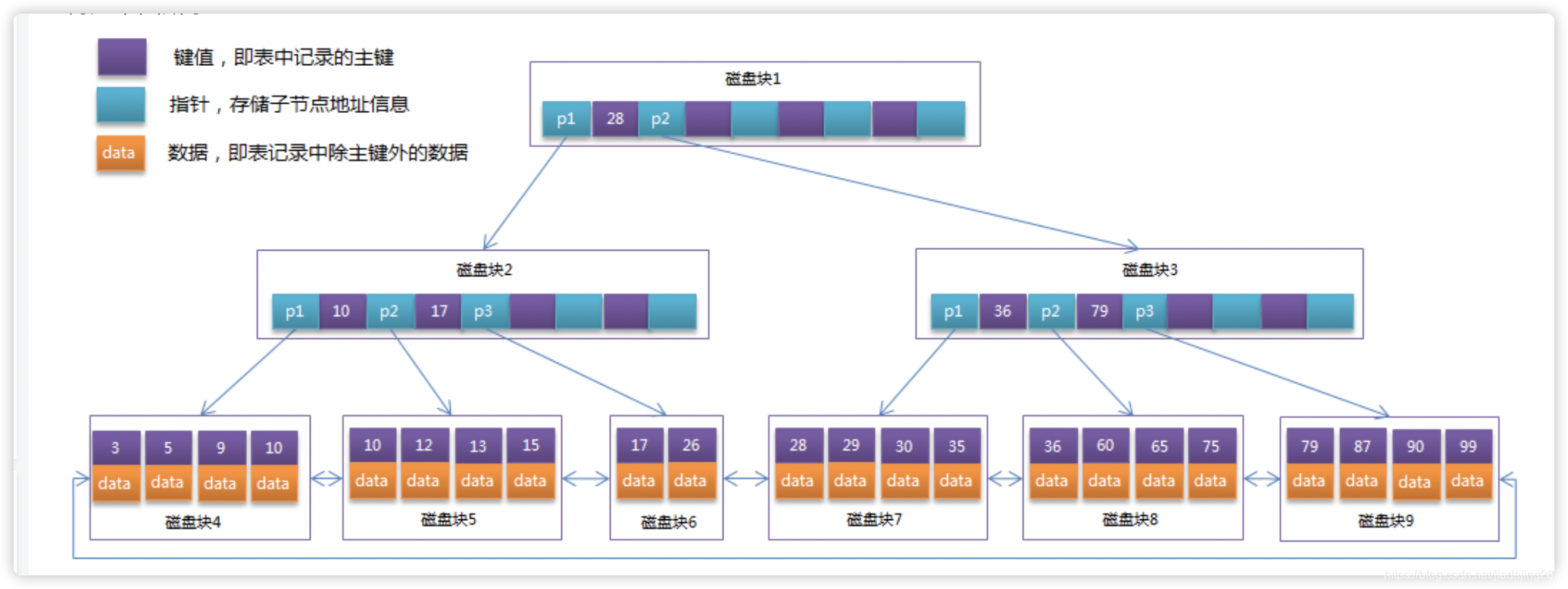
B-Tree索引意味着所有值都是按顺序存储,而且每个叶子页到根的距离是相等的。B-Tree索引能加快访问数据的速度,因为存储引擎不再需要全表扫描来获取需要数据,直接从索引的根节点检索,而且叶子节点指针指向是被索引的数据。
结合B+Tree的数据结构特性,可以看出B-Tree索引适用于全值匹配、键值范围、者键前缀(左前缀)、列前缀,精准匹配某一列并范围匹配另外一列、以及只访问索引(覆盖索引)的查询。
B-Tree索引的限制,与适用限制取反,非最左列开始查找,跳过索引中的列,适用范围查询的列,后面所有列均不无法适用索引优化
哈希索引
基于哈希表实现,只有精准匹配索引所有列的查询才有效果。在MySQL中只有Memory引擎显式支持。 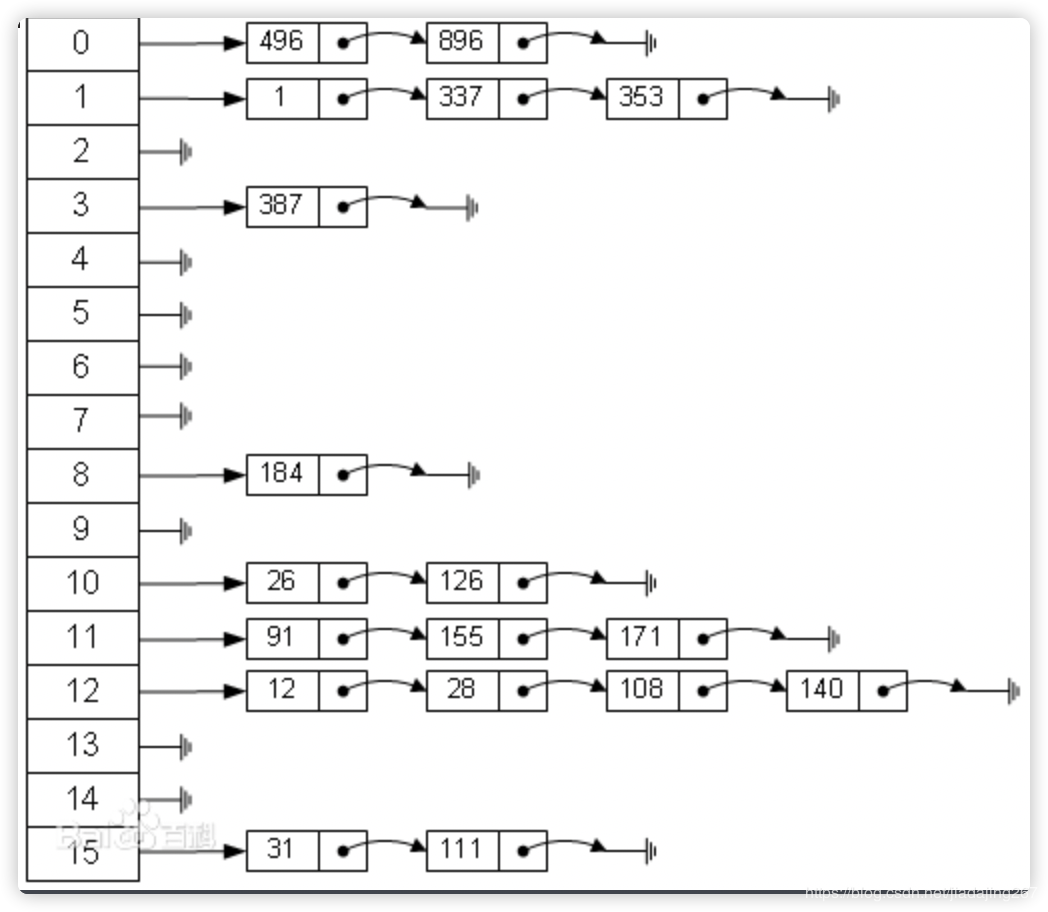 (图引自百度百科)
(图引自百度百科)
因为哈希索引只需要存储对应的哈希值,索引结构比较紧凑,哈希索引的查找速度比较快。但是哈希索引只包含哈希值和行指针,不存储字段值,不能避免使用索引中的值省去行读取;哈希索引数据不是按照索引值顺序存储,无法用于排序;同样也不支持部分索引列匹配查找;只支持等值比较;如果哈希冲突比较多,索引维护成本比较高。
InnoDB引擎有个特殊功能“自适应哈希索引”,当某些索引值被使用特别频繁的时候,会在内存中基于B-Tree索引上创建哈希索引,使得B-Tree索引具有哈希索引的有点,这是一个内部行为,用户不需要控制或者配置。
索引的优点
1、减少服务器需要扫描的数据量
2、帮助服务器避免排序和临时表
3、将随机I/O变成顺序I/O
评价索引好坏原则
1、索引将相关的记录放到一起则获得一星
2、索引中的数据顺序和查找中的排列顺序一致则获得二星
3、索引中的列包含了查询中需要的全部列则获得三星
高性能索引策略 1、独立列,索引列不能是表达式的一部分,也是函数的参数,因为MySQL无法自动解析方程式,造成索引失效,应该尽量简化where条件
2、前缀索引,当索引列过长,只选取先几个字符做限制,可以节约索引空间,提高索引效率。但是要选择足够长的前缀来保证较高的选择性,同时不能过长,使得前缀索引的选择性接近于索引整个列。一般前缀的选择性能够接近于0.031,基本上可用。
前缀索引不足之处:MySQL无法使用前缀索引做order by和group by以及覆盖扫描。
3、多列索引,避免为每个列创建独立的索引,每个表上索引最多五个,按照错误的顺序建立多例索引。
MySQL在5.0之后引入了一种“索引合并”,在Extra中看到Using union,则证明用到索引合并,一般这是优化的结果,同时也说了索引建的比较糟糕,通常意味着需要一个包含相关列的多列索引。
4、选择合适的索引列顺序 在多列B-Tree索引中,索引列顺序意味着按照最左列进行排序,其次第二列等等,索引顺序可以满足order by, group by, distinct等。选择索引列顺序的经验法则:将选择性最高的列放到索引最前列。
5、聚簇索引,并不是一种单独的索引类型,而是一种数据结构。在InnoDB的聚簇索引实际上在同一个结构上保持了B-Tree和数据行。表中有聚簇索引是,它的数据行实际上存放在索引的叶子页中。InnoDB中通过主键聚集数据,如果没有主键,则选择唯一的的非空索引代替,如果没有这样的索引,InnoDB会隐式定义一个主键作为聚簇索引。
只有主键列为聚集索引,其他均为辅助索引
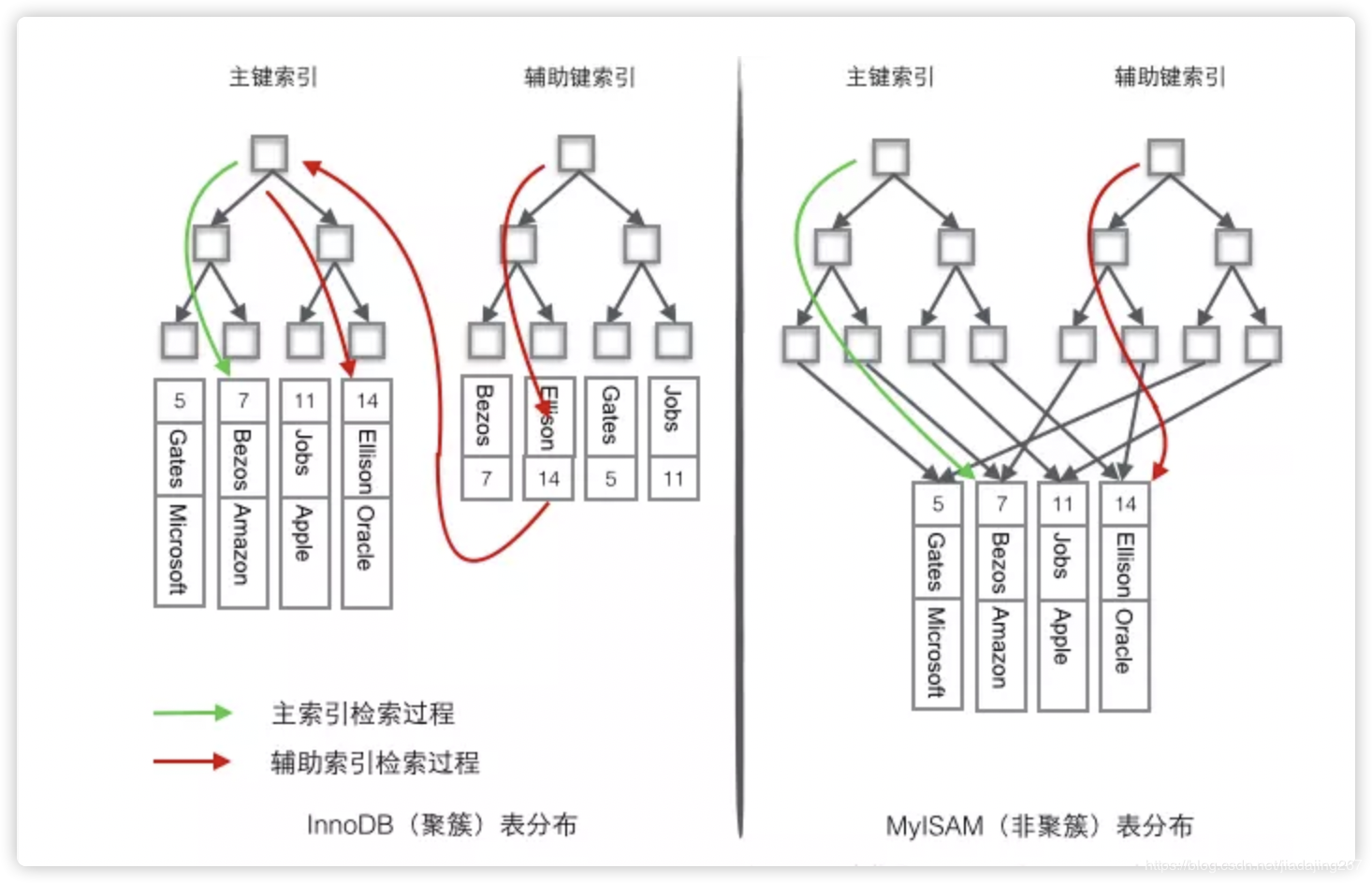
聚集的好处 1)、相关数据保存到一起,减少磁盘I/O操作
2)、数据访问更快,聚簇索引将索引和数据存在同一个B-Tree中,因此聚簇索引比非聚簇索引查找要快
3)、覆盖索引扫描查询可以直接使用页节点中的主键值
聚集的缺点 1)、最大限度提高I/O密集型应用性能,但是如果数据都在内存中,聚簇索引没有什么优势了。
2)、插入速度严重依赖于插入顺序。按照主键的顺序插入是加载数据到InnoDB表中速度最快的方式。
3)、更新聚簇索引列的成本很高,会强制InnoDB将每个被更新的行移动到新的位置。
4)、基于聚簇索引表插入新行,或者主键被更新,会造成页分裂
5)、聚簇索引可能导致全部扫描变慢,尤其是行稀疏,或者页分裂导致数据存储不连续的时候
6)、二级索引(非聚簇索引)可能比想象更大,因为二级索引的叶子节点包含了引用行的主键列覆盖索引
如果正在使用InnoDB表并且没有什么数据需要聚集,可以定义代理键作为主键,这种主键的数据和应用无关,最简单的方式是引用自增列,可以保证数据行是按顺序行写入,对于根据主键做关联操作的性能也会更好。避免随机的聚簇索引,尤其是I/O密集型的应用,从性能来说,UUID会造成聚簇索引插入完全随机。这是公司里主键不使用uuid,而是递增序列的原因。
6、覆盖索引,索引包含所需要查询的字段的值,即索引列即可满足查询内容,不需要再访问回表查询。Extra中有Using index则表示使用了覆盖索引。
1)、索引条目通常小于数据行大小,MySQL会极大地减少数据访问量。
2)、索引按照列顺序存储,简单的范围查询能使用完全顺序的索引访问
3)、InnoDB聚簇索引,二级索引中在叶子节点中保存了行主键值,如果二级主键能够覆盖查询,则可以避免对主键的二次查询
7、索引扫描排序 EXPlain中的Type列为index,则表示MySQL使用了索引扫描来做排序。MySQL中可以使用同一索引既满足排序又用于查找行。当索引顺序和order by子句顺序完全一致是,并且所有列的排序方向都一样时,才可以使用索引对结果进行排序。有一种特殊情况order by子句可以不满足左前缀要求,就是前导列为常量的时候。
8、重复索引,冗余索引 重复索引在相同的列上按照相同的顺序创建相同类型的索引,应该避免这样创建重复索引,发现后应该立即移除。
冗余索引通常发生在为表新增索引的时候,例如创建了索引(A,B),再创建索引(A)就是冗余索引。大部分情况下都不需要冗余索引,尽可能扩展已有索引,而不是创建新索引
9、索引和锁 索引可以让查询锁定更少的行,如果查询从不访问那些不需要的行,那么就会锁定更少的行。InnoDB只有在访问行的时候才会对其加锁,而索引可以减少InnoDB访问的行数,从而减少锁的数量。但这有当InnoDB在存储引擎层能过过滤掉所有不需要的行时才有效。如果索引无法过滤掉无效行,InnoDB检索到数据并返回服务器后,MySQL服务器才能应用where子句,此时已经无法避免行锁了。在MySQL5.1以及以后的版本中,InnoDB可以在服务端过滤掉行后就释放锁,在此之前的版本需要等事务提交后才能释放锁。
索引优化小技巧 1、在索引中加入更多列,做组合索引,并通过IN()的方式覆盖那些不在where子句中的列。但是不能乱用,因为每增加一个IN()条件,优化器需要做的组合都要以指数形式增加,会极大影响查询性能。 2、避免多个范围条件,可以使用In()来替代,用多个等值条件查询,避免使用范围索引后,后面的列无法使用其他索引 3、优化排序,当时排序涉及到大分页时,使用延迟关联,通过覆盖索引返回需要的主键,再根据主键关联原表获得需要的行 多列索引应用以及优化(in),拒绝多范围条件
最后
这篇文章内部不多,旨在让大家了解MySQL是什么,包括什么,如何引用,下一篇想要看什么知识点,欢迎评论区告诉我。
最后对于程序员来说,要学习的知识内容、技术有太多太多,要想不被环境淘汰就只有不断提升自己,从来都是我们去适应环境,而不是环境来适应我们!
刷题!刷题!刷起来!!
- Github标星35K+超火的阿里p7大佬整理的Java核心知识总结,附超全教程文档
- 硬核!啃完666页Java面试高频宝典,6月成功定级腾讯T3-2
- 阿里巴巴公司开源:2021年全网最详细的dubbo使用教程,15分钟快速从入门到实战
- 渣硕试水字节跳动,消息队列面试连环问,本以为简历都过不了,123+HR面直接拿到意向书满满干货指导!
学习技术是一条慢长而艰苦的道路,不能靠一时激情,也不是熬几天几夜就能学好的,必须养成平时努力学习的习惯。所以:贵在坚持!
最后如果你觉得文章对你有帮助,【记得一键三连哦!】你的支持是我创作更加优质文章的动力,不枉费我半夜起来加班!有任何建议或者意见评论区见!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









