






文章有关信息如下:

最后用流域洪峰流量与72h洪量数据,得出相应高斯Copula、T-Copula、Frank-Copula等估计及其分布函数图与密度函数度,作为一个关于Copula的小例子。
研究背景
为了解释两个或多个水文气候变量(如温度和降水)的可变性及其相关性,越来越多的文献关注多元分析,其中基于Copula的概率分布的概念引起了人们的极大兴趣。copula是一种强大的工具,可以通过耦合边际分布并形成其联合累积分布来捕捉和建模变量之间的依赖结构。
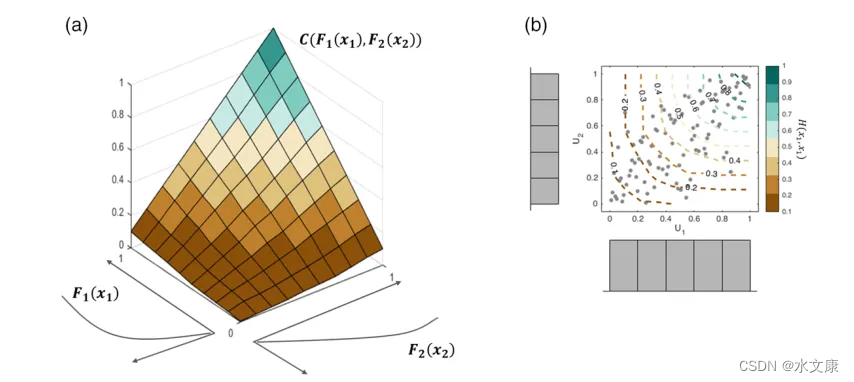
Copulas已被用于理论和应用水文气候分析。例如,理论研究采用Copula来更好地理解各种变量的相关性,如温度和降水量,或生成合成的水文气候数据。应用研究采用Copula来进行检测,例如,泥沙输移、热浪死亡率、干旱,河流洪水或沿海洪水、作物产量和地下水质量的可变性。此外,许多气候变化影响研究将Copula应用于气候模型的双向未来预测。
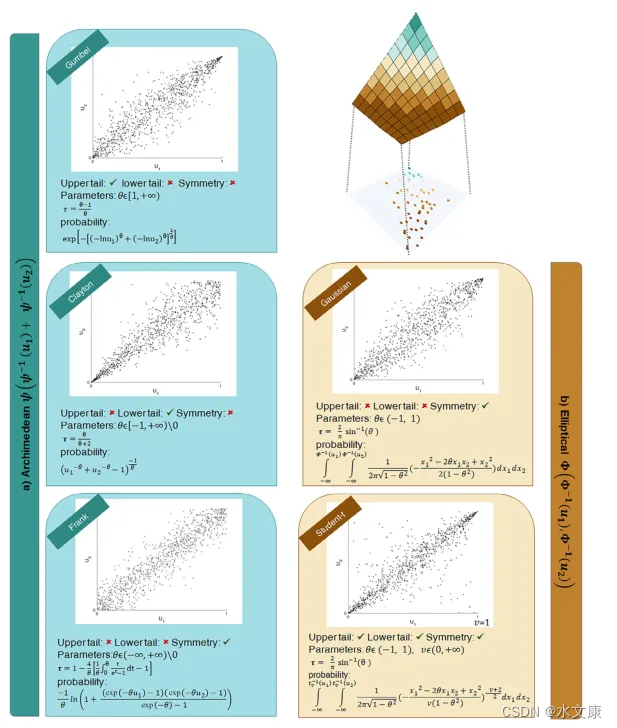
尽管对Copula在水文气象中的研究的数量越来越多,但大多依赖统计文献,这些文献往往侧重于理论基础,只有少数文章侧重于水文气候研究中遇到的实际挑战,例如,包括如何探索不同尺度下变量之间的相关性,如何预处理数据以实现特定的Copula假设以及如何稳健地选择Copula模型,或者如何验证Copula模型与数据的拟合。
文章要点
文章概述了Copula的最新技术,并强调了必要的要求、统计假设和局限性。基于系统的文献综述,文章发现出现了两个一般性问题:(1)推导Copula的重要步骤通常没有在文献中报告(再现性有限);(2)copula所需的关键统计假设通常没有经过测试(可信度有限)。因此,确定了以实践为导向的研究的常见步骤:1.依赖性时空控制的探索性分析;2.数据预处理;3.copula模型的选择和参数估计;4.拟合优度评估。
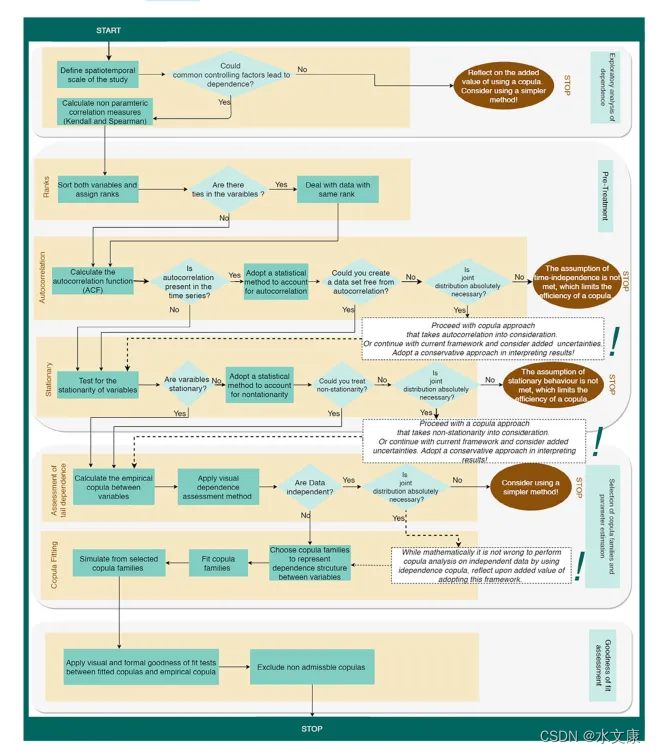
建模步骤
(1)变量依赖性的探索性分析
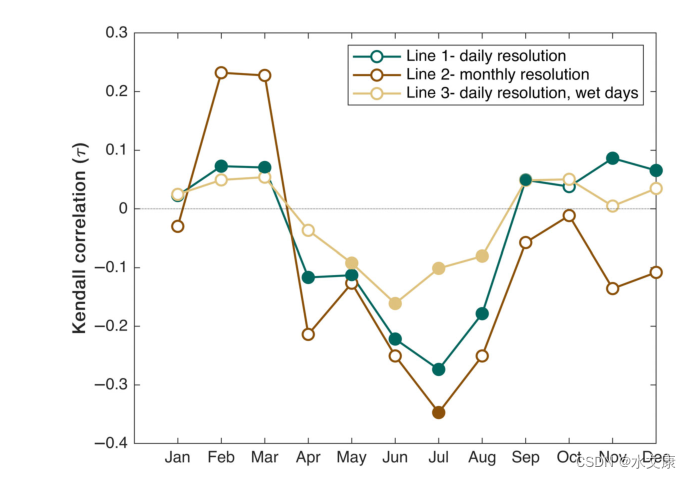
在Copula建模中用于评估依赖强度的最广泛使用的非参数度量是秩相关性,包括Kendall的τ和Spearman的ρ。它们都提供了随机变量之间关联强度的度量,通常被称为相关性。但是不能完全反映变量之间依赖结构的复杂性,不能揭示依赖结构。
(2)数据的预处理
Copula的应用要求水文气候变量是连续的且与时间无关的。因此,评估相关性(即具有相同秩的数据)或其他特征(如变量的自相关和平稳性)的存在是至关重要的。许多实际研究强调,秩标样本中的联系可能会导致Copula中的偏差,并随后影响所选copula模型的拟合优度检验。
(3)Copula选择和参数估计适当的拟合可以确保相关性结构和相关性强度都得到适当的表示。
依赖结构由所选择的copula族反映,而依赖强度由copula参数估计。一般情况下,Student-t、Gaussian和Frank Copulas被选为潜在的合适的Copula家族,因为它们都可以对负依赖性进行建模,并且能够对尾部的较低依赖性进行模型化。Copula参数估计过程需要
(1)边际分布的估计;
(2)通过参数和经验依赖性度量之间的理论关系,或通过最大化似然函数来绘制copula参数。最大似然(ML)和边际分布推理函数(IFM)是两种广泛使用的copula参数估计参数方法。
(4)拟合优度在估计copula参数后,必须使用性能度量来评估从不同copula家族获得的拟合优度,以消除不允许的copula。为此,一种方法是从具有在前一步中估计的特定copula参数的copula家族中抽取随机样本。然后,可以应用图形拟合优度测试来直观地评估拟合。另一种方法是直接将经验copula的K图与从理论copula中提取的样本的K图进行比较,或者分析分位数图或水平曲线或等值线等。
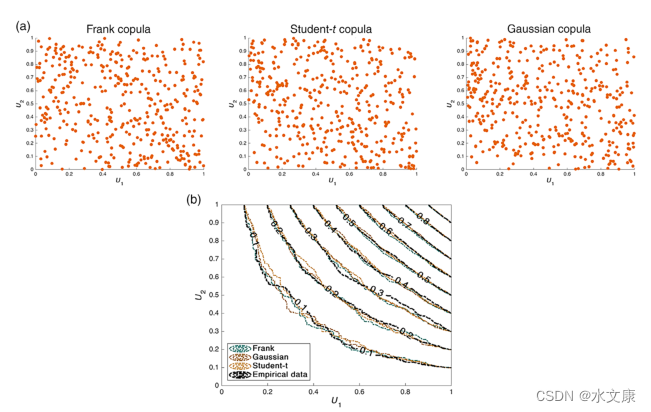
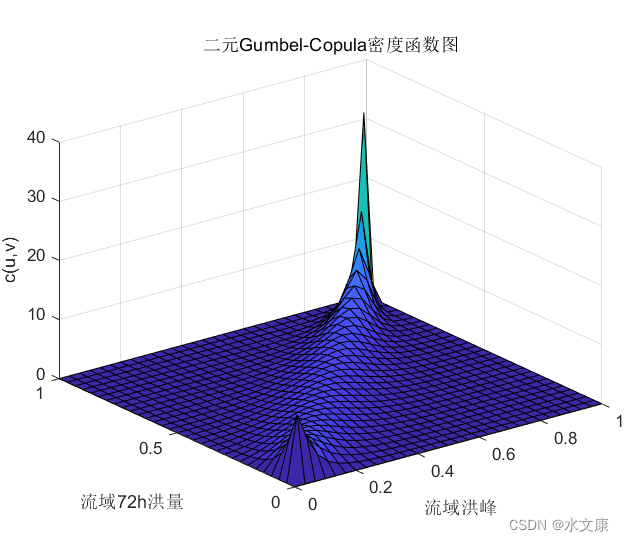
用如下流域洪峰流量与72h洪量数据,得出相应高斯Copula、T-Copula、Frank-Copula等估计及其分布函数图与密度函数度。
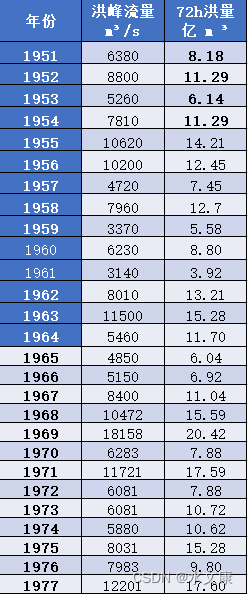
由matlab得出如下部分结果:
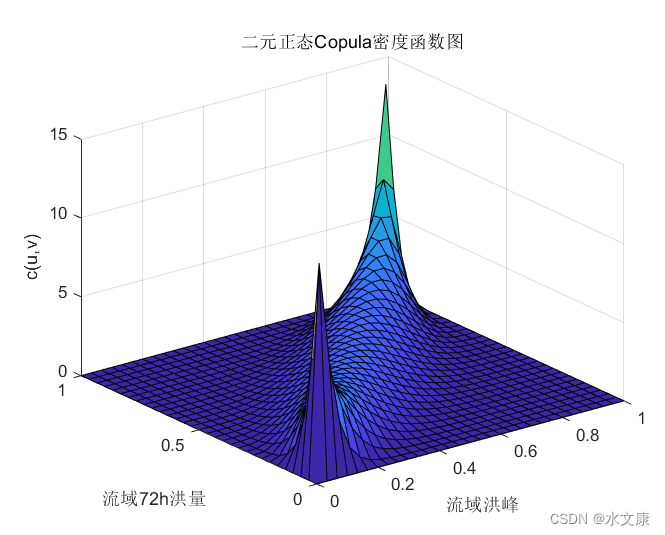
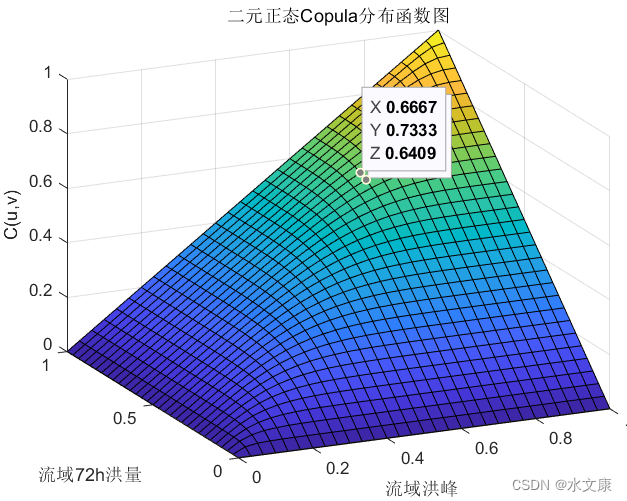
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









