







机器学习:决策树进阶
文章目录
在 ID3算法中,我们实现了基于离散属性的决策树构造。C4.5决策树在划分属性选择、连续值、缺失值、剪枝等几方面做了改进。
下文的决策树算法进阶以C4.5展开
1.连续值处理
1.方法概述:
C4.5算法中策略是采用二分法将连续属性离散化处理:假定样本集D的连续属性有n个不同的取值,对这些值从小到大排序,得到属性值的集合 。把区间
。把区间 的中位点
的中位点 作为候选划分点,于是得到包含n-1个元素的划分点集合
作为候选划分点,于是得到包含n-1个元素的划分点集合
基于每个划分点t,可将样本集D分为子集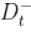 和
和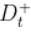 ,其中
,其中 中包含属性上不大于t的样本,
中包含属性上不大于t的样本, 包含属性a上大于t的样本。
包含属性a上大于t的样本。
对于每个划分点t,按如下公式计算其信息增益值,然后选择使信息增益值最大的划分点进行样本集合 的划分。
的划分。
2.数据示例
在原西瓜数据集中增加两个连续属性“密度”和“含糖率”,下面我们计算属性“密度”的信息增益。

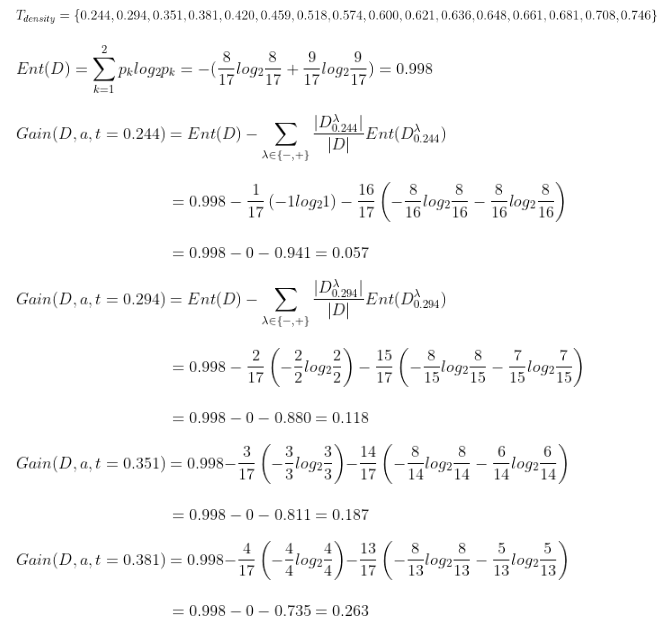
所有划分点的信息增益均可按上述方法计算得出,最优划分点为0.381,对应的信息增益为0.263。我们分别按照离散值和连续值的信息增益计算方法,计算出每个属性的信息增益,从而选择最优划分属性,构造决策树。
3.python实现
1.创建watermelondata2.txt存储数据

2.读取数据集
fr = open(r'F:\work\机器学习\code\watermelondata2 .txt',encoding='utf-8')
listWm = [inst.strip().split('\t') for inst in fr.readlines()]
labels = ['色泽', '根蒂', '敲声', '纹理', '脐部', '触感', '密度', '含糖率']
labelProperties = [0, 0, 0, 0, 0, 0, 1, 1] # 属性的类型,0表示离散,1表示连续
3.划分数据集
# 划分数据集, axis:按第几个特征划分, value:划分特征的值, LorR: value值左侧(小于)或右侧(大于)的数据集
def splitDataSet_c(dataSet, axis, value, LorR='L'):
retDataSet = []
featVec = []
if LorR == 'L':
for featVec in dataSet:
if float(featVec[axis]) < value:
retDataSet.append(featVec)
else:
for featVec in dataSet:
if float(featVec[axis]) > value:
retDataSet.append(featVec)
return retDataSet
4.选择最优属性,增加连续属性分支
# 选择最好的数据集划分方式
def chooseBestFeatureToSplit_c(dataSet, labelProperty):
numFeatures = len(labelProperty) # 特征数
baseEntropy = calcShannonEnt(dataSet) # 计算根节点的信息熵
bestInfoGain = 0.0
bestFeature = -1
bestPartValue = None # 连续的特征值,最佳划分值
for i in range(numFeatures): # 对每个特征循环
featList = [example[i] for example in dataSet]
uniqueVals = set(featList) # 该特征包含的所有值
newEntropy = 0.0
bestPartValuei = None
if labelProperty[i] == 0: # 对离散的特征
for value in uniqueVals: # 对每个特征值,划分数据集, 计算各子集的信息熵
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet) / float(len(dataSet))
newEntropy += prob * calcShannonEnt(subDataSet)
else: # 对连续的特征
sortedUniqueVals = list(uniqueVals) # 对特征值排序
sortedUniqueVals.sort()
listPartition = []
minEntropy = inf
for j in range(len(sortedUniqueVals) - 1): # 计算划分点
partValue = (float(sortedUniqueVals[j]) + float(
sortedUniqueVals[j + 1])) / 2
# 对每个划分点,计算信息熵
dataSetLeft = splitDataSet_c(dataSet, i, partValue, 'L')
dataSetRight = splitDataSet_c(dataSet, i, partValue, 'R')
probLeft = len(dataSetLeft) / float(len(dataSet))
probRight = len(dataSetRight) / float(len(dataSet))
Entropy = probLeft * calcShannonEnt(
dataSetLeft) + probRight * calcShannonEnt(dataSetRight)
if Entropy < minEntropy: # 取最小的信息熵
minEntropy = Entropy
bestPartValuei = partValue
newEntropy = minEntropy
infoGain = baseEntropy - newEntropy # 计算信息增益
if infoGain > bestInfoGain: # 取最大的信息增益对应的特征
bestInfoGain = infoGain
bestFeature = i
bestPartValue = bestPartValuei
return bestFeature, bestPartValue
5.构建决策树方法
# 创建树, 样本集 特征 特征属性(0 离散, 1 连续)
def createTree_c(dataSet, labels, labelProperty):
# print dataSet, labels, labelProperty
classList = [example[-1] for example in dataSet] # 类别向量
if classList.count(classList[0]) == len(classList): # 如果只有一个类别,返回
return classList[0]
if len(dataSet[0]) == 1: # 如果所有特征都被遍历完了,返回出现次数最多的类别
return majorityCnt(classList)
bestFeat, bestPartValue = chooseBestFeatureToSplit_c(dataSet,
labelProperty) # 最优分类特征的索引
if bestFeat == -1: # 如果无法选出最优分类特征,返回出现次数最多的类别
return majorityCnt(classList)
if labelProperty[bestFeat] == 0: # 对离散的特征
bestFeatLabel = labels[bestFeat]
myTree = {bestFeatLabel: {}}
labelsNew = copy.copy(labels)
labelPropertyNew = copy.copy(labelProperty)
del (labelsNew[bestFeat]) # 已经选择的特征不再参与分类
del (labelPropertyNew[bestFeat])
featValues = [example[bestFeat] for example in dataSet]
uniqueValue = set(featValues) # 该特征包含的所有值
for value in uniqueValue: # 对每个特征值,递归构建树
subLabels = labelsNew[:]
subLabelProperty = labelPropertyNew[:]
myTree[bestFeatLabel][value] = createTree_c(
splitDataSet(dataSet, bestFeat, value), subLabels,
subLabelProperty)
else: # 对连续的特征,不删除该特征,分别构建左子树和右子树
bestFeatLabel = labels[bestFeat] + '<' + str(bestPartValue)
myTree = {bestFeatLabel: {}}
subLabels = labels[:]
subLabelProperty = labelProperty[:]
# 构建左子树
valueLeft = '是'
myTree[bestFeatLabel][valueLeft] = createTree_c(
splitDataSet_c(dataSet, bestFeat, bestPartValue, 'L'), subLabels,
subLabelProperty)
# 构建右子树
valueRight = '否'
myTree[bestFeatLabel][valueRight] = createTree_c(
splitDataSet_c(dataSet, bestFeat, bestPartValue, 'R'), subLabels,
subLabelProperty)
return myTree
6.绘制决策树
Trees = trees.createTree_c(listWm, labels, labelProperties)
print(json.dumps(Trees, encoding="utf-8", ensure_ascii=False))
treePlotter.createPlot(Trees)
7.决策树的结构
字典:

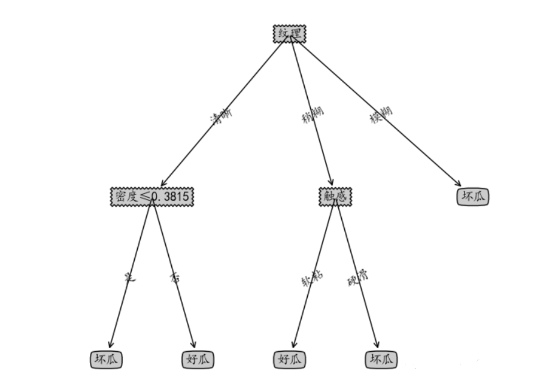
2.剪枝处理
1.概述
剪枝(pruning)是决策树学习算法对付“过拟合”的主要手段。在决策树学习过程中,为了尽可能正确分类训练样本,节点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因训练样本学的“太好”了,以致于把训练集自身的一些特点当做所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合风险。
决策树剪枝的基本策略有“预剪枝”和“后剪枝”。
预剪枝:
预剪枝是指在决策树生成过程中,对每个结点在划分前先进行估计,若当前节点的划分不能带来决策树泛化性能的提升,则停止划分当前节点并将当前节点标记为叶节点。
现在问题来了?如何判断决策树泛化性能是否提升了呢?
答案在验证集中进行测试。学过机器学习的同学都知道,数据集可分为训练集和测试集。我们在训练集中可预留出一部分数据作为验证集。通过使用决策树对验证集进行分类,若验证集分类准确率上升,我们则可认为决策树泛化性能提升了。
后剪枝:
后剪枝则是先从训练集生成一颗完整的决策树,然后自底向上地对非叶节点进行考察。若将该节点对应的子树替换为叶节点能带来决策树泛化性能提升,则将该子树替换为叶结点。
一般情形下,后剪枝决策树的欠拟合风险很小,泛化性能往往优于预剪枝决策树。但是后剪枝过程是在生成决策树之后进行的,并且要自底向上地对树中所有非叶节点进行逐一考察,因此其训练时间开销比未剪枝决策树和预剪枝决策树都要大很多。若不考虑计算开销影响,一般往往选择后剪枝方式进行处理。
2.后剪枝的python实现:
1.数据集:基于离散的西瓜数据集
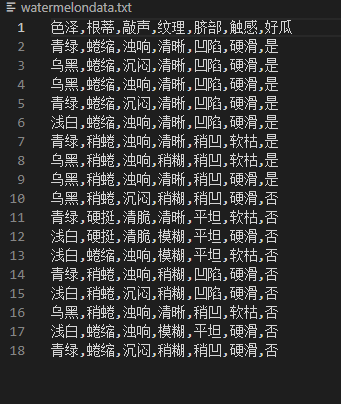
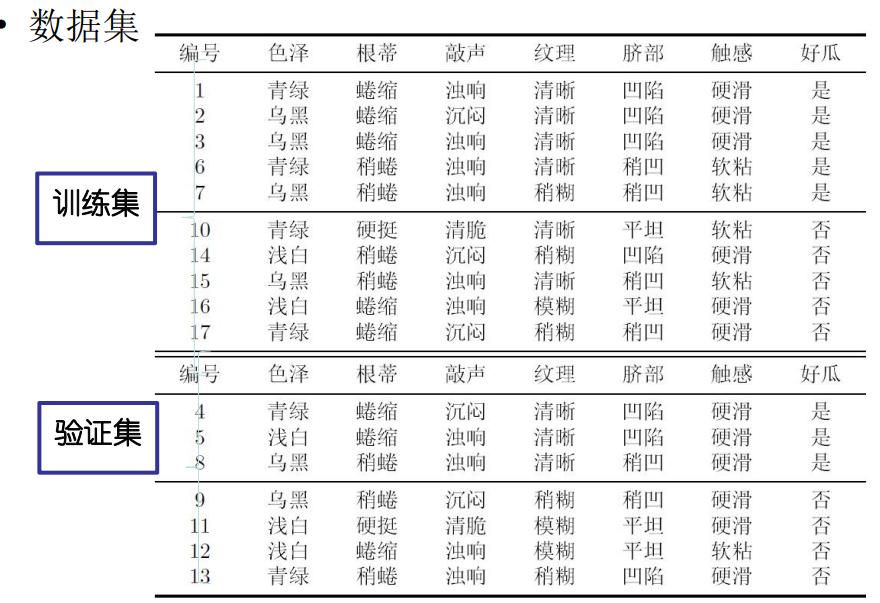
2.划分数据集:将其按西瓜书中所给分为训练集与测试集,以csv格式存储

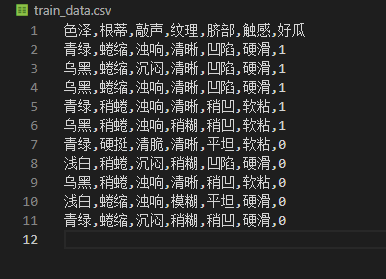
3.剪枝方法函数:
# 后剪枝
def post_prunning(tree , test_data , test_label , names):
newTree = tree.copy() #copy是浅拷贝
names = np.asarray(names)
# 取决策节点的名称 即特征的名称
featName = list(tree.keys())[0]
# 取特征的列
featCol = np.argwhere(names == featName)[0][0]
names = np.delete(names, [featCol]) #删掉使用过的特征
newTree[featName] = tree[featName].copy() #取值
featValueDict = newTree[featName] #当前特征下面的取值情况
featPreLabel = featValueDict.pop("prun_label") #如果当前节点剪枝的话是什么标签,并删除_vpdl
# 分割测试数据 如果有数据 则进行测试或递归调用:
split_data = drop_exist_feature(test_data,featName) #删除该特征,按照该特征的取值重新划分数据
split_data = dict(split_data)
for featValue in featValueDict.keys(): #每个特征的值
if type(featValueDict[featValue]) == dict: #如果下一层还是字典,说明还是子树
split_data_feature = split_data[featValue] #特征某个取值的数据,如“脐部”特征值为“凹陷”的数据
split_data_lable = split_data[featValue].iloc[:, -1].values
# 递归到下一个节点
newTree[featName][featValue] = post_prunning(featValueDict[featValue],split_data_feature,split_data_lable,split_data_feature.columns)
# 根据准确率判断是否剪枝,注意这里的准确率是到达该节点数据预测正确的准确率,而不是整体数据集的准确率
# 因为在修改当前节点时,走到其他节点的数据的预测结果是不变的,所以只需要计算走到当前节点的数据预测对了没有即可
ratioPreDivision = equalNums(test_label, featPreLabel) / test_label.size #判断测试集的数据如果剪枝的准确率
#计算如果该节点不剪枝的准确率
ratioAfterDivision = predict_more(newTree, test_data, test_label)
if ratioAfterDivision < ratioPreDivision:
newTree = featPreLabel # 返回剪枝结果,其实也就是走到当前节点的数据最多的那一类
return newTree
4.后剪枝处理结果

可见剪枝后决策树不仅更加轻量,而且对于测试集的预测准确率从0.428提升到了0.714















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









