






神经网络(数学模型/计算机模型)
生物神经网络:

神经元并没有形成系统和网络. 可能只是一些分散的细胞而已, 一端连着嘴巴的味觉感受器, 一端连着手部的肌肉. 小时候, 世界上有一种神奇的东西叫做 – 糖果, 当我们第一次品尝它的时候, 美妙的感觉, 让我们发现活着是多么有意义的事情. 这时候神经元开始产生联结 , 记忆形成, 但是形成的新联结怎么样变成记忆, 仍然是科学界的一个迷. 不过现在, 我们的手和嘴产生了某种特定的搭配. 每次发现有糖果的时候, 某种生物信号就会从我们的嘴,通过之前形成的神经联结, 传递到手上, 让手的动作变得有意义。
人工神经网络
首先,替代掉生物神经网络的,就是已经成体系的人工神经网络,所有神经元之间的连接都是固定不可更换的,这也就是说,在人工神经网络里,没有凭空产生新连接这回事。人工神经网络典型的一种学习方式就是,我们已经知道吃到糖果后,手会如何的动,但是我想让神经网络学着帮我做这件动动手的事情,所以我预先准备好非常多吃糖的学习数据,然后将这些数据一次次放入这套人工神经网络系统中,糖的信号会通过这套系统传递到手。然后通过对比这次信号传递后,手的动作是不是讨糖动作,来修改人工神经网络当中的神经元强度,这种修改在专业术语中叫做“误差反向传递”,也可以看作是再一次将传过来的信号传回去,看看这个负责传递信号神经元对于讨糖的动作到底有么有贡献,让它好好反思与改正,争取下次做出更好的贡献。
**生物神经网络和人工神经网络的区别与联系 **:
人工神经网络靠的是正向和反向传播来更新神经元,从而形成一个好的神经系统,本质上,这是一个能让计算机处理和优化的数学模型,而生物神经网络是通过刺激,产生新的连接,让信号能够通过新的连接传递而形成反馈,虽然现在的计算机技术越来越高超,不过我们身体里的神经系统经过了数千万年的进化,还是独一无二的。
神经连接
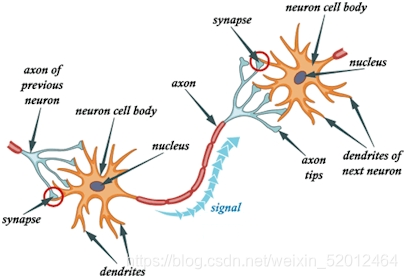
每个神经元(细胞)都向外伸出许多分支,其中用来接收输入的分支称作树突(dendrities),用来输出信号的分支称作轴突(axon),轴突连接到树突上形成一个突触(synapse)。每个神经元可以通过这种方式连接多个其他神经元,每个神经元也可以接受多个其他神经元的连接。很多连接起来的神经元形成了网状结构,海量具有传感和伸缩功能的体细胞通过神经纤维连接在这个网状结构的输入和输出端,中枢神经系统正是通过这种网状结构获得了“智能”。
网状结构的工作模式:
生物学家已经观察到的事实是,当有外界刺激时,网络上的某些神经元会被次第激活。神经元被激活的意思是这个神经元会向外传递信号或者对外传递的信号强度较大。
激活过程数学模型的建立:
(以一个突触为例)
用一个数值表示突触传递的信息,这寓示着将信息只归为一个类别,并用数值的大小表示其数量方面的属性。
多个突触:将一个轴突的输出表示成一个多维向量。可以引入多个虚拟突触来实现这个多维向量的各个维度的信息的传递。
神经元的激活:激活可以有两种模型结构——跳变式和连续式。
跳变式激活方式是:引入一个阈值,当输入信息经过某种处理后大于阈值即表示激活,小于阈值表示未激活。连续式激活方式表示神经元不是只有激活和未激活两种状态,而是有不同的激活水平,输入信息经过某种处理后直接输出激活水平。当突出同时传递多种信息时,引入虚拟神经元,让一个神经元只表示其中一个激活模型。让这个虚拟神经元接收所有树突上的输入信息,经过激活模型处理后生成一维的激活水平。当激活水平是多维时,再引入虚拟神经元,每个神经元只生成其中某一维的激活水平即可。
多维变一维,显然数学模型应该是加权和,给每一维找到一个权重相乘再加起来。
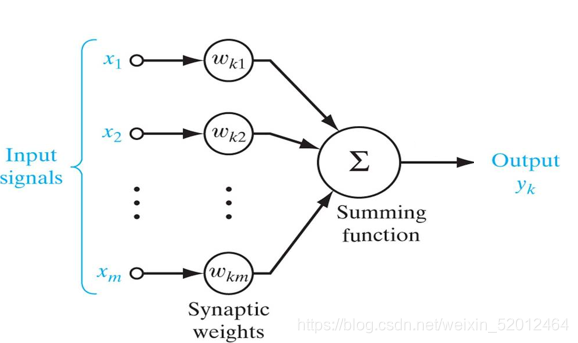
但是这个模型是线性的,所有输入和输出组成的点集落在一个超平面上。再引入一个非线性函数以这个加权和为输入,将其输出作为激活水平,这个非线性函数称作激活函数。
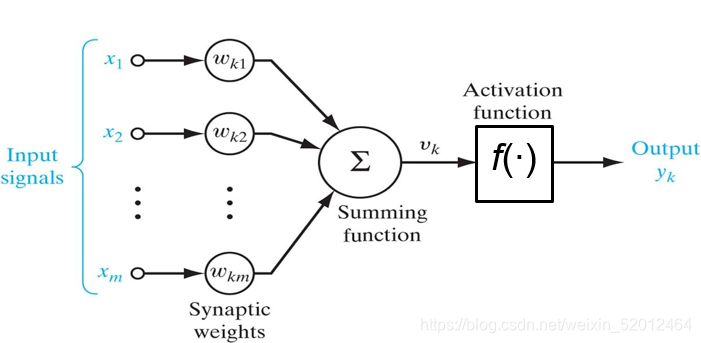
激活函数举例:
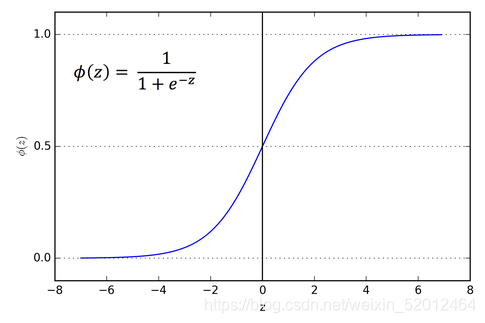
在激活函数自变量上增加一个偏移量,得到如下图:
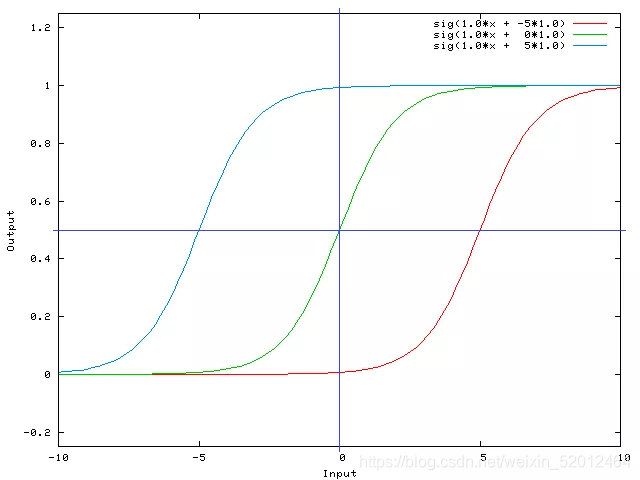
激活函数的偏移量使得超平面可以离开原点了,这仅仅是数学上的意义;其实它还完成了对跳变式激活方式的建模。参考上图,假设水平蓝线以上的数值才能表示激活,那么对于蓝色的图像来说处于持续激活状态,绿色的图片表示只要有输入就激活,而红色的部分则表示当输入数值超过5时才忽然进入激活状态,这就是跳变了。
神经网络由大量的、简单的处理单元(称为神经元)广泛地互相连接而形成的复杂网络系统,它反映了人脑功能的许多基本特征,是一个高度复杂的非线性动力学习系统。
神经元的功能:输入,输出,计算
拥有大量节点神经网络是一种运算模型,由大量的节点(或称“神经元”)和之间相互的联接构成。每个节点代表一种特定的输出函数,称为激励函数、激活函数(activation function)。
**阶层型结构:**通过输入层激活信号,再通过隐藏层提取特征,不同隐藏层神经单元对应不同输入层的神经单元权重(每两个节点间的联接都代表一个对于通过该连接信号的加权值,称之为权重)和自身偏置均可能不同,输入层兴奋传递到隐藏层兴奋,最后输出层根据不同的隐藏层权重和自身偏置输出结果。
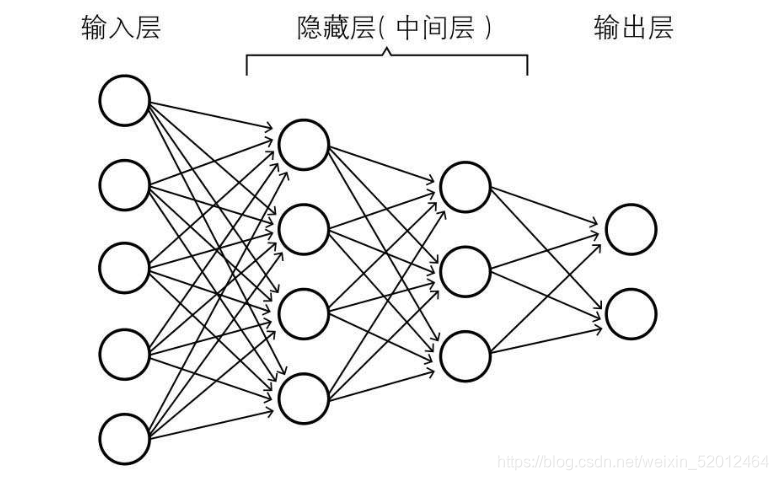
输入层 :主要用于获取输入的信息
隐藏层 :传输信息加工处理
输出层:传递输出信息
总体思路:输入 ——加工——输出
各个层如何向上传递信息
根据上边的介绍可知,输入层每个神经单元直接对应原始数据,然后向隐藏层提供信息,隐藏层每个神经单元对不同的输入层神经单元有不同的权重,从而偏向于对某种识别模式兴奋;多个隐藏层的神经单元兴奋后,输出层的神经单元根据不同隐藏层的兴奋加上权重后,给到不同的兴奋度,这个兴奋度就是模型最终识别的结果。
神经网络中权重和偏置的作用
根据上述信息可知,权重会影响神经单元对输入信息敏感程度,比如隐藏层的神经单元通过控制权重形成识别模式偏向,输出层的神经单元调整对隐藏层神经单元的权重,可以形成输出结果的偏向;
而偏置,可以理解为敏感度,如果没有设置合适的偏置,一些“噪音”就会影响模型识别的结果,或者一些本该被识别出来的场景,但是在传递过程中被屏蔽掉了。
有监督学习下,如何确认权重
在这里需要引入一个概念,『损失函数』又称为代价函数(cost function),计算方法为预测值与学习资料中偏差值之和(误差)的平方,有监督学习就是经过一些『学习资料』的训练,让模型预测的『误差』尽量的小。
注意:
1.设计一个神经网络时,输入层与输出层的节点数往往是固定的,中间层则可以自由设置。
在设计一个神经网络时,输入层的节点数需要与特征的维度匹配,输出层的节点数要与目标的维度匹配。而中间层的节点数,却是由设计者指定的。
2.神经网络结构图中的拓扑与箭头代表着预测过程时数据的流向,跟训练时的数据流有一定的区别。
3.结构图里的关键不是圆圈(代表“神经元”),而是连接线(代表“神经元”之间的连接)。每个连接线对应一个不同的权重(其值称为权值),这是需要训练得到的。
4.在其他绘图模型里,有向箭头可能表示的是值的不变传递。而在神经元模型里,每个有向箭头表示的是值的加权传递。
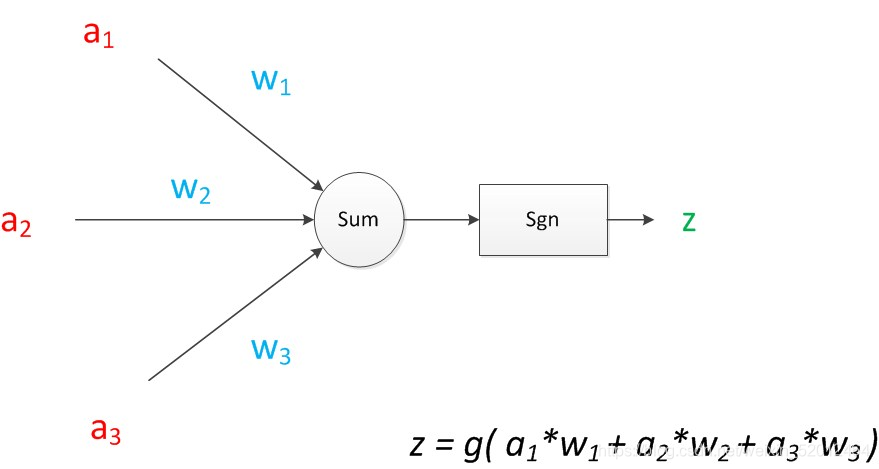
z是在输入和权值的线性加权和叠加了一个函数g的值。在MP模型里,函数g是sgn函数,也就是取符号函数。这个函数当输入大于0时,输出1,否则输出0。
神经元可以看作一个计算与存储单元。计算是神经元对其的输入进行计算功能。存储是神经元会暂存计算结果,并传递到下一层。
当我们用“神经元”组成网络以后,描述网络中的某个“神经元”时,我们更多地会用“单元”(unit)来指代。同时由于神经网络的表现形式是一个有向图,有时也会用“节点”(node)来表达同样的意思。
节点设计多少的方法:较好的方法就是预先设定几个可选值,通过切换这几个值来看整个模型的预测效果,选择效果最好的值作为最终选择。
Grid Search 网格搜索
训练:
不断训练,通过大量的数据测试,对比预测数据和真实数据的区别,反向传递修改,使真实模型更接近预测模型,建立数学模型进行判断运行。
加工是对数字的加工。
利用大量的数据对算法进行优化,使其得到的参数尽可能的接近预测模型,其差值称为损失。
首先给所有参数赋上随机值。使用这些随机生成的参数值,来预测训练数据中的样本。样本的预测目标为yp,真实目标为y。那么,定义一个值loss,计算公式如下。
loss = (yp - y)2(损失)
如果将先前的神经网络预测的矩阵公式带入到yp中(因为有z=yp),那么我们可以把损失写为关于参数(parameter)的函数,这个函数称之为损失函数(loss function)。
如何使损失函数的值最小?
优化模型:梯度下降 (联想高数:求导)
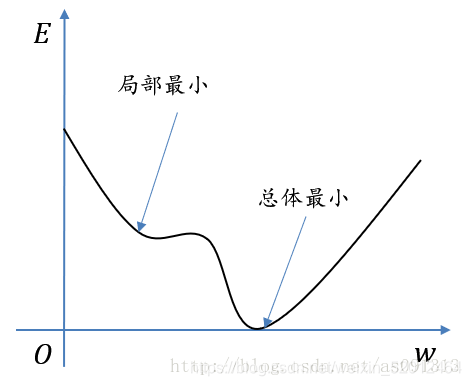
梯度:沿函数变化最快的方向的向量(函数最大偏导数方向)
全局最优解,局部最优解(求导得导数=0)
Θ 1=Θ 0+α▽J(Θ)→evaluated atΘ 0
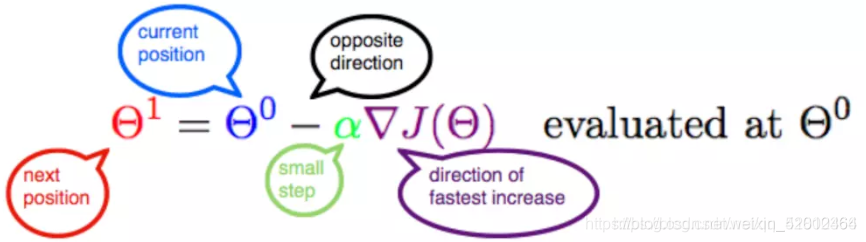
α在梯度下降算法中被称作为学习率或者步长。
单变量函数的梯度下降


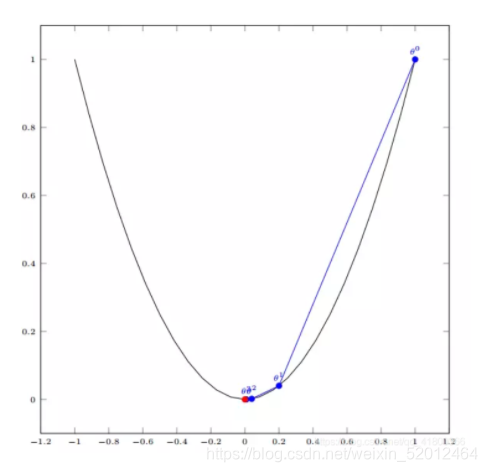
即到达函数最低点。
多变量的梯度下降:


实际案例
def f(x):
return 0.5 * (x - 0.25)**2
def df(x):
return x - 0.25 //求导
alpha = 0.1 //学习率
GD_X = [] //每次x更新后把值存在这个列表里面
GD_Y = [] //每次更新x后目标函数的值存在这个列表里面
x = 4 //随机初始化的x,其他的值也可以
f_current = f_change = f(x)
iter_num = 0
while iter_num <100 and f_change > 1e-10: //迭代次数小于100次或者函数变化小于1e-10次方时停止迭代
iter_num += 1
x = x - alpha * df(x)
tmp = f(x)
f_change = abs(f_current - tmp)
f_current = tmp
GD_X.append(x)
GD_Y.append(f_current)
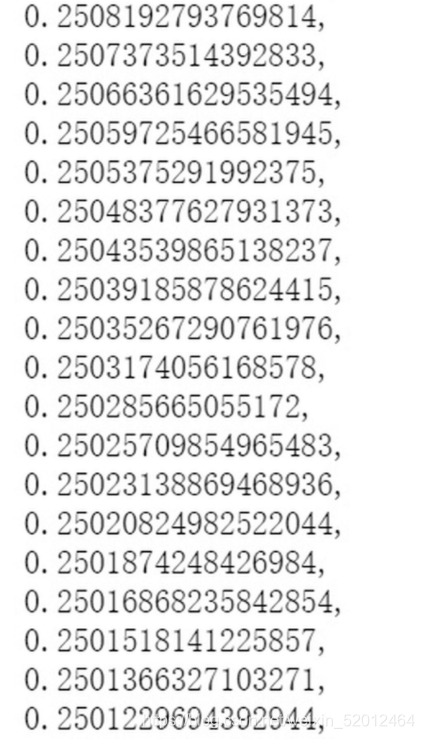
可以看出,x无限无限接近0.25
同时,可以打印出y的值
print("{:.10f}".format(GD_Y[-1])) #无限接近0
最终优化的参数 [公式] 并不是想象中的0.25,而是无限逼近0.25,这是梯度下降的缺点之一。
可视化学习过程:
import numpy as np
import matplotlib.pyplot as plt
X = np.arange(-4,4,0.05)
Y = f(X)
Y = np.array(Y)
plt.plot(X,Y)
plt.scatter(GD_X,GD_Y)
plt.title("$y = 0.5(x - 0.25)^2$")
plt.show()
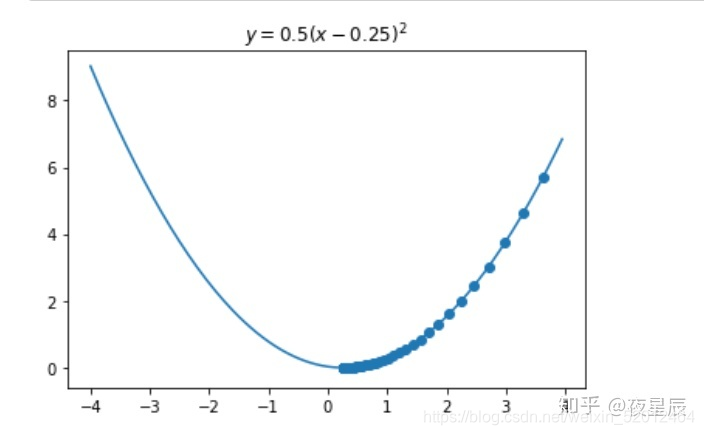
梯度下降算法的思路:梯度下降算法每次计算参数在当前的梯度,然后让参数向着梯度的反方向前进一段距离,不断重复,直到梯度接近零时截止。一般这个时候,所有的参数恰好达到使损失函数达到一个最低值的状态。
在神经网络模型中,由于结构复杂,每次计算梯度的代价很大。因此还需要使用反向传播算法。反向传播算法是利用了神经网络的结构进行的计算。不一次计算所有参数的梯度,而是从后往前。首先计算输出层的梯度,然后是第二个参数矩阵的梯度,接着是中间层的梯度,再然后是第一个参数矩阵的梯度,最后是输入层的梯度。计算结束以后,所要的两个参数矩阵的梯度就都有了。
单层神经网络
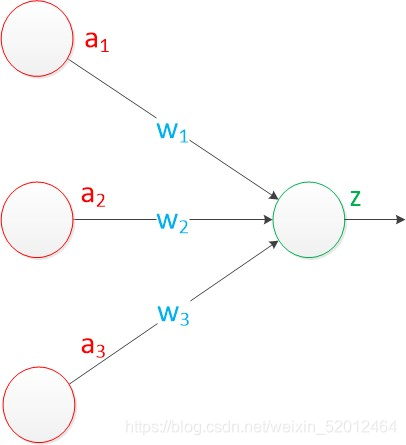
在原来MP模型的“输入”位置添加神经元节点,标志其为“输入单元”。其余不变,于是我们就有了下图:从本图开始,我们将权值w1, w2, w3写到“连接线”的中间。
在“感知器”中,有两个层次。分别是输入层和输出层。输入层里的“输入单元”只负责传输数据,不做计算。输出层里的“输出单元”则需要对前面一层的输入进行计算。我们把需要计算的层次称之为“计算层”,并把拥有一个计算层的网络称之为“单层神经网络”。
假如我们要预测的目标不再是一个值,而是一个向量,例如[2,3]。那么可以在输出层再增加一个“输出单元”。
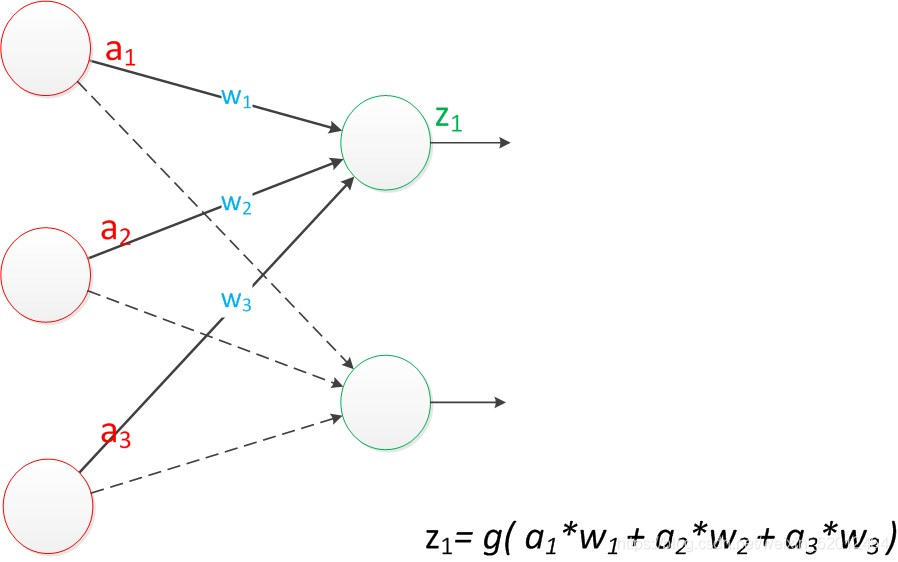
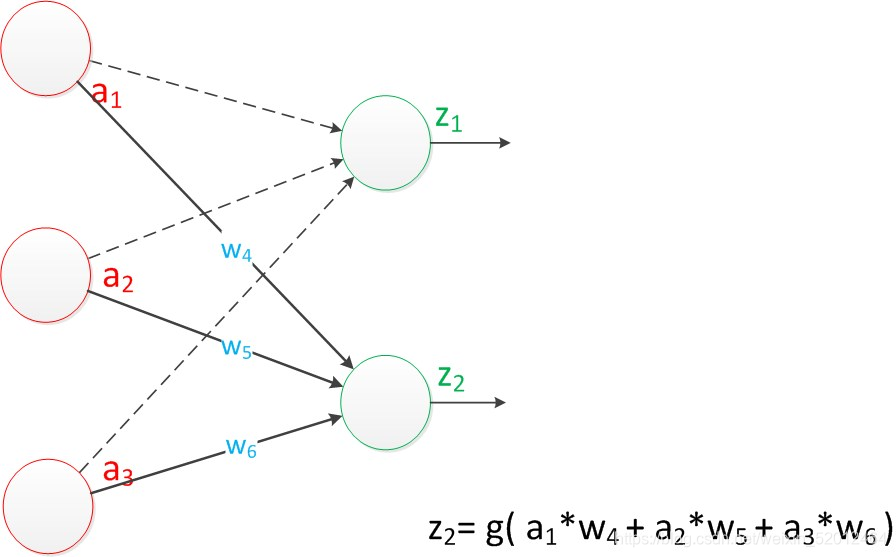
目前的表达公式有一点不让人满意的就是:w4,w5,w6是后来加的,很难表现出跟原先的w1,w2,w3的关系。
因此我们改用二维的下标,用wx,y来表达一个权值。下标中的x代表后一层神经元的序号,而y代表前一层神经元的序号(序号的顺序从上到下)。
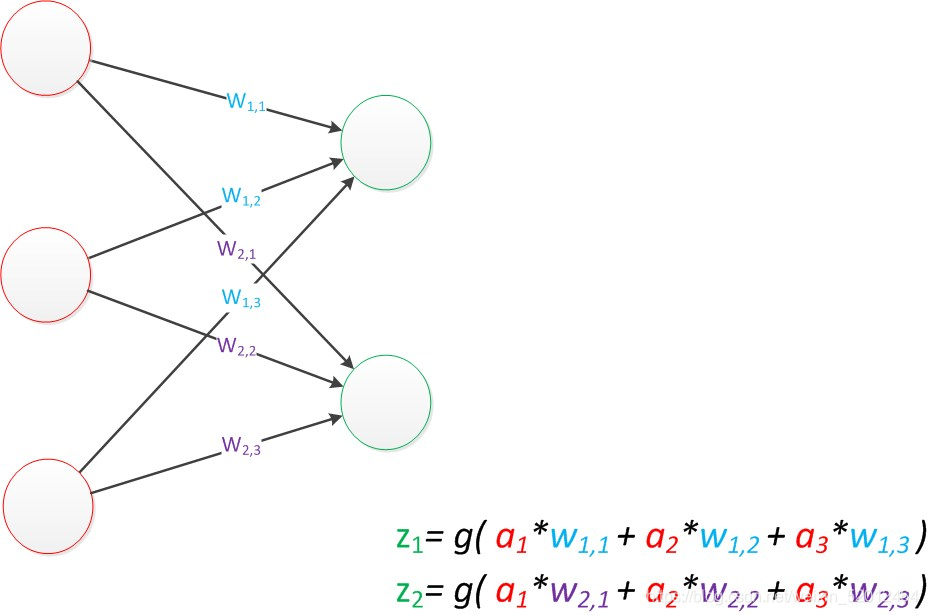
例如,输入的变量是[a1,a2,a3]T(代表由a1,a2,a3组成的列向量),用向量a来表示。方程的左边是[z1,z2]T,用向量z来表示。
系数则是矩阵W(2行3列的矩阵,排列形式与公式中的一样)。
于是,输出公式可以改写成:g(W * a) = z;(从前一层计算后一层的矩阵运算)
两层神经网络(多层感知器)
两层神经网络除了包含一个输入层,一个输出层以外,还增加了一个中间层。此时,中间层和输出层都是计算层。
ax(y)代表第y层的第x个节点。z1,z2变成了a1(2),a2(2)。下图给出了a1(2),a2(2)的计算公式。
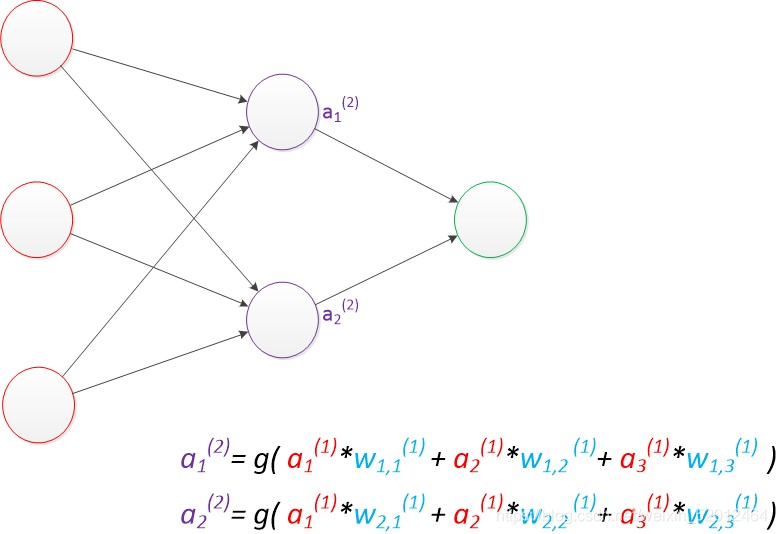
计算最终输出结果为:
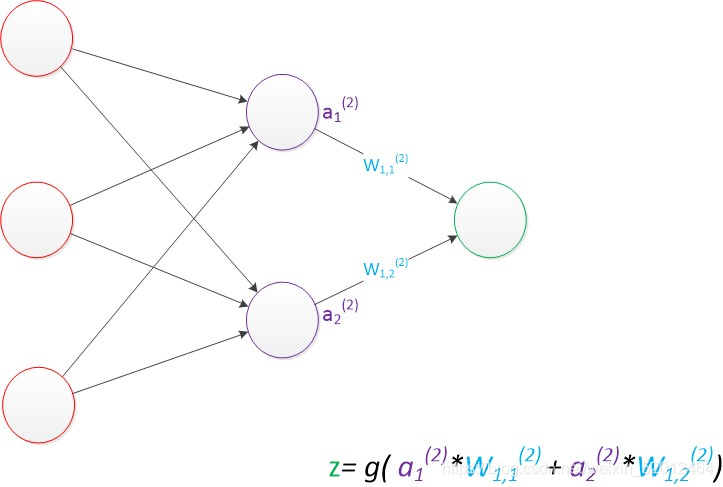
假设我们的预测目标是一个向量,那么与前面类似,只需要在“输出层”再增加节点即可。
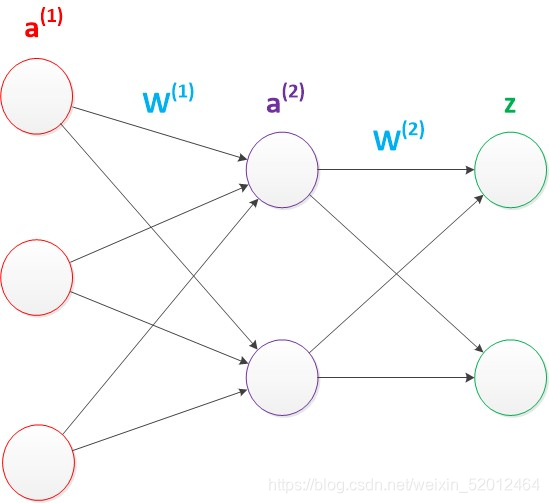
使用矩阵运算来表达整个计算公式的话如下:
g(W(1) * a(1)) = a(2);
g(W(2) * a(2)) = z;
偏置节点:
它本质上是一个只含有存储功能,且存储值永远为1的单元。在神经网络的每个层次中,除了输出层以外,都会含有这样一个偏置单元。
偏置单元与后一层的所有节点都有连接,我们设这些参数值为向量b,称之为偏置。
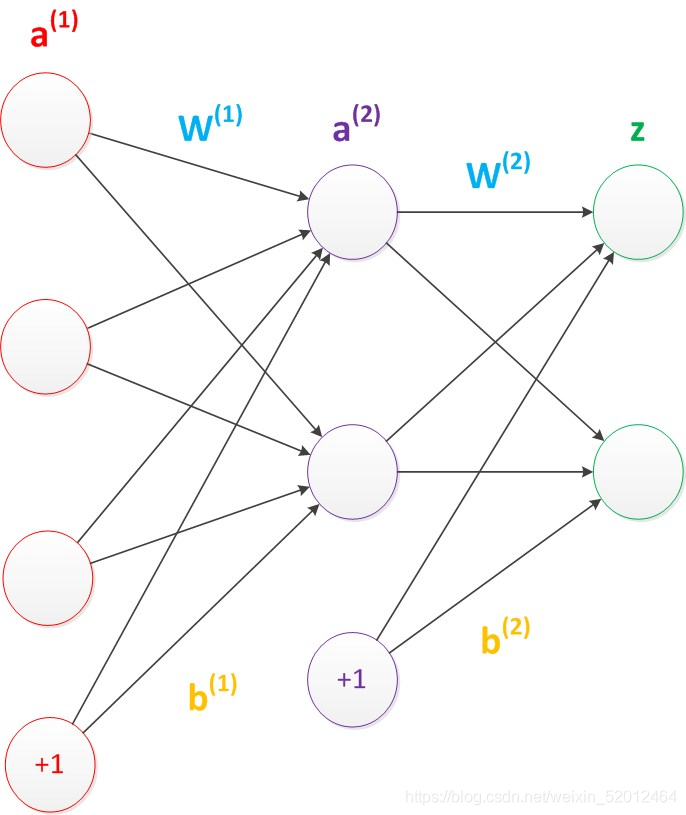
可以看出,偏置节点很好认,因为其没有输入(前一层中没有箭头指向它)。有些神经网络的结构图中会把偏置节点明显画出来,有些不会。一般情况下,我们都不会明确画出偏置节点。
在考虑了偏置以后的一个神经网络的矩阵运算如下:
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
在两层神经网络中,我们不再使用sgn函数作为函数g,而是使用平滑函数sigmoid作为函数g。我们把函数g也称作激活函数(active function)。
事实上,神经网络的本质就是通过参数与激活函数来拟合特征与目标之间的真实函数关系。
单层神经网路和两层神经网络的区别:
理论证明,两层神经网络可以无限逼近任意连续函数。
可以看到,输出层的决策分界仍然是直线。关键就是,从输入层到隐藏层时,数据发生了空间变换。也就是说,两层神经网络中,隐藏层对原始的数据进行了一个空间变换,使其可以被线性分类,然后输出层的决策分界划出了一个线性分类分界线,对其进行分类。
这样就导出了两层神经网络可以做非线性分类的关键–隐藏层。联想到我们一开始推导出的矩阵公式,我们知道,矩阵和向量相乘,本质上就是对向量的坐标空间进行一个变换。因此,隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分,转换成了线性可分。
两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数。因此,多层的神经网络的本质就是复杂函数拟合。
强化学习:
强化学习是一个通用的问题解决框架,其核心思想是 Trial & Error。
强化学习四元素
策略(Policy):环境的感知状态到行动的映射方式。
反馈(Reward):环境对智能体行动的反馈。
价值函数(Value Function):评估状态的价值函数,状态的价值即从当前状态开始,期望在未来获得的奖赏。
环境模型(Model):模拟环境的行为。
强化学习的目标就是获得最多的累计奖励。
举例:
小孩就是 agent,他试图通过采取行动(即行走)来操纵环境(行走的表面),并且从一个状态转变到另一个状态(即他走的每一步),当他完成任务的子任务(即走了几步)时,孩子得到奖励(给巧克力吃),并且当他不能走路时,就不会给巧克力。
强化学习会在没有任何标签的情况下,通过先尝试做出一些行为得到一个结果,通过这个结果是对还是错的反馈,调整之前的行为,就这样不断的调整,算法能够学习到在什么样的情况下选择什么样的行为可以得到最好的结果。
主要算法与分类:
从强化学习的几个元素的角度划分的话,方法主要有下面几类:
Policy based, 关注点是找到最优策略。
Value based, 关注点是找到最优奖励总和。
Action based, 关注点是每一步的最优行动。
我们可以用一个最熟知的旅行商例子来看,
我们要从 A 走到 F,每两点之间表示这条路的成本,我们要选择路径让成本越低越好:
那么几大元素分别是:
states ,就是节点 {A, B, C, D, E, F}
action ,就是从一点走到下一点 {A -> B, C -> D, etc}
reward function ,就是边上的 cost
policy,就是完成任务的整条路径 {A -> C -> F}
有一种走法是这样的,在 A 时,可以选的 (B, C, D, E),发现 D 最优,就走到 D,此时,可以选的 (B, C, F),发现 F 最优,就走到 F,此时完成任务。
这个算法就是强化学习的一种,叫做 epsilon greedy,是一种 Policy based 的方法,当然了这个路径并不是最优的走法。
此外还可以从不同角度使分类更细一些:
如下图所示的四种分类方式,分别对应着相应的主要算法:
Model-free:不尝试去理解环境, 环境给什么就是什么,一步一步等待真实世界的反馈, 再根据反馈采取下一步行动,常见的方法有policy optimization和Q-learning。
Model-based:先理解真实世界是怎样的, 并建立一个模型来模拟现实世界的反馈,通过想象来预判断接下来将要发生的所有情况,然后选择这些想象情况中最好的那种,并依据这种情况来采取下一步的策略。它比 Model-free 多出了一个虚拟环境,还有想象力。
Model-Based是去学习和理解环境,学会用一个模型来模拟环境,通过模拟的环境来得到反馈,Model-Based相当于比Model-Free多了模拟环境这个环节,通过模拟环境预判接下来会发生的所有情况,然后选择最佳的情况。
Policy-Based的方法直接输出下一步动作的概率,根据概率来选取动作。但不一定概率最高就会选择该动作,还是会从整体进行考虑。适用于非连续和连续的动作。常见的方法有policy gradients。
Value based:输出的是所有动作的价值, 根据最高价值来选动作,这类方法不能选取连续的动作。适用于非连续的动作。常见的方法有Q-learning和Sarsa。
回合更新的方法是指整个学习过程全部结束后再进行更新。Monte-carlo update:游戏开始后, 要等待游戏结束, 然后再总结这一回合中的所有转折点, 再更新行为准则,常见的方法有Monte-Carlo learning和基础版的policy gradients
单步更新的方法是指学习过程中的每一步都在更新,不用等到全部结束后在进行更新。常见的方法有Q-learning、Sarsa和升级版的policy gradients。
相比而言,单步更新的方法更有效率。
Temporal-difference update:在游戏进行中每一步都在更新, 不用等待游戏的结束, 这样就能边玩边学习了。
On-policy:在线学习(on-policy)指的是学习的过程agent必须参与其中,典型的算法为Sarsa。
离线学习(off-policy)指的是既可以自己参与其中,也可以根据他人学习过程进行学习。典型的方法是Q-learning,已经Deep-Q-Network。
根据回报函数(reward function)是否已知进行分类。强化学习为已知回报函数。但是当任务十分复杂时,回报函数往往很难确定。而逆强化学习则是用来解决这种问题,根据专家实例学习回报函数。
常见算法:
- 表格型方法:Sarsa和Q-Learning算法
QLearning是强化学习算法中value-based的算法,Q即为Q(s,a)就是在某一时刻的 s 状态下(s∈S),采取 动作a (a∈A)动作能够获得收益的期望,环境会根据agent的动作反馈相应的回报reward r,所以算法的主要思想就是将State与Action构建成一张Q-table来存储Q值,然后根据Q值来选取能够获得最大的收益的动作。
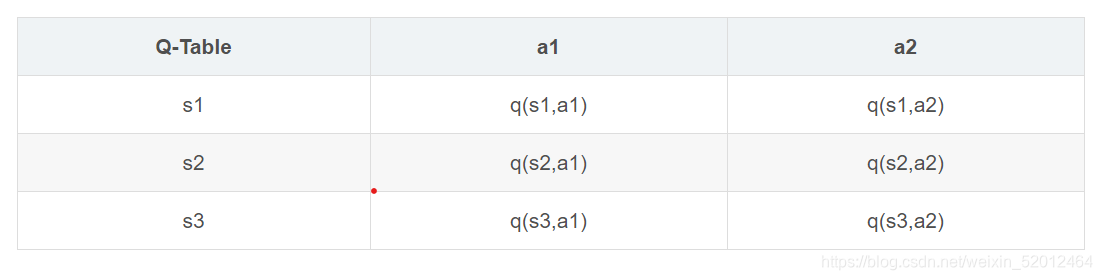
Sarsa,是为了建立和优化状态-动作(state-action)的价值Q表格所建立的方法。首先初始化Q表格,根据当前的状态和动作与环境进行交互后,得到奖励reward以及下一步的状态和动作后,对Q表格进行更新;并不断重复这个过程。
Q表格更新公式为:
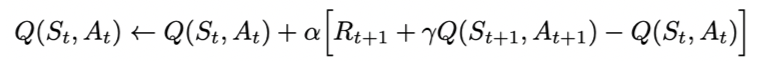
另外,为了保证每一步的探索性,Sarsa在执行下一步时采用e-greedy算法,即根据一定的概率估计来选择下一步的action。Sarsa的这种更新Q表格方式称为“on-policy”方式,即先做出下一步的动作再回头开更新Q值。
与之对应的是“off-policy”方式,即在更新Q表格时,无需知道下一步的动作,而是假设下一步的动作可以取到最大的Q值。基于这种“off-policy”的方法称为Q-Learning算法,其更新Q表格的数学表达式为:
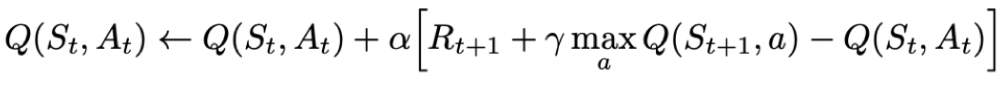
2. 基于神经网络方法:DQN算法
Deep Q-Learning,简称DQN算法是为了解决传统的
格型方法在大规模强化学习任务时遇到的执行效率低,存储量低等问题而提出的算法,它的基本思想是采用神经网络的方式来近似代替Q表格。DQN本质上还是Q-Learning算法,同样为了更好的与环境进行交互,采用e-greedy算法。
DQN的创新在于:
经验回放(experience replay):使用经验池存在多条s,a,r,s’信息,并随机选择一批数据作为输入到神经网络进行训练。经验回放保证了样本的关联性和利用效率问题,即对于某一条信息它有多次机会可以进入网络进行训练。
Q目标固定(fixed-Q-target):复制一个和原来一样的Q网络,用来训练目标Q。Q目标固定主要为了解决训练过程的稳定性问题。
3. 策略梯度方法:Policy-Gradient算法
策略梯度方法是指在优化神经网络的过程中,对于策略π(s,a)的期望回报,所有的轨迹获得的回报R与对应的轨迹发生概率p的加权和,当N足够大时,可通过采样N个Episode求平均的方式近似表达,即:
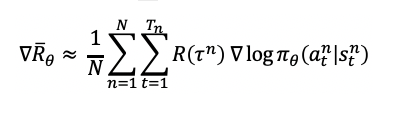














 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









