







文章目录
实验思维导图
1.决策树–ctree()–iris
1.1 数据
1.1.1 程序包加载
简洁安装程序包:将提供的程序包手动复制到R的镜像下的library下:
例如我的路径:D:\R-4.1.3\library,将重复的程序包替换即可。底部提供资料
library(ISLR)
library(TH.data)
library(MASS)
library(multcomp)
library(matrixStats)
library(libcoin)
library(survival)
library(coin)
library(zoo)
library(strucchange)
library(modeltools)
library(mvtnorm)
library(party)
library(grid)
#party包中的ctree():
#1.用于创建决策树
#2.提供用于控制决策树训练的几个参数,例如 midSplit、Min Busket、MaxSurrogate 和 MaxDepth
1.1.2 数据集探索
#查看iris数据集
str(iris)

数据集大小:150条数据、5个变量
在许多的科研著作中都在iris数据集上做分类操作。该数据集由3种不同类型的鸢尾花的50个样本数据构成。其中的一个种类与另外两个种类是线性可分离的,后两个种类是非线性可分离的。这个数据集包含了5个属性:
- Sepal.Length(花萼长度),单位是cm。
- Sepal.Width(花萼宽度),单位是cm。
- Petal.Length(花瓣长度),单位是cm。
- Petal.Width(花瓣宽度),单位是cm。
种类: - Iris Setosa(山鸢尾)
- Iris Versicolour(杂色鸢尾)
- Iris Virginica(维吉尼亚鸢尾)
1.1.3 数据集拆分
#拆分数据集
ind <- sample(2, nrow(iris), replace= TRUE, prob=c(0.7, 0.3))
#同ind <- sample(x = 2,size = nrow(iris),replace=TRUE,prob = c(0.7,0.3))
trainData <- iris[ind==1,]
testData <- iris[ind==2,]
#sample():
#x即拆分为两部分
#size即抽样大小
#replace = TRUE
#有放回抽样,“replace”就是重复的意思,即可以重复对元素进行抽样,也就是所谓的有放回抽样。
#prob即“probability”(概率)
#查看拆分后的数据
str(trainData)
str(testData)

1.2 训练
1.2.1 设置因变量、自变量
#myFormula指定了Species为目标变量,其余所有变量为自变量
myFormula <- Species ~ Sepal.Length + Sepal.Width + Petal.Length + Petal.Width
1.2.2 决策树建模
iris_ctree <- ctree(myFormula, data=trainData)
1.2.3 查看训练结果
#检查预测结果
table(predict(iris_ctree),trainData$Species)
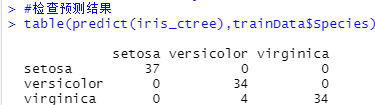
#Setosa鸢尾花:37条
#Versicolour鸢尾花:34条
#Virginica鸢尾花:34条
#既是Versicolour鸢尾花也是Virginica鸢尾花:4条
#共109条数据
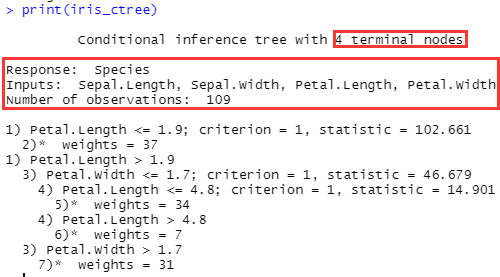
#查看已经训练过的决策树
print(iris_ctree)
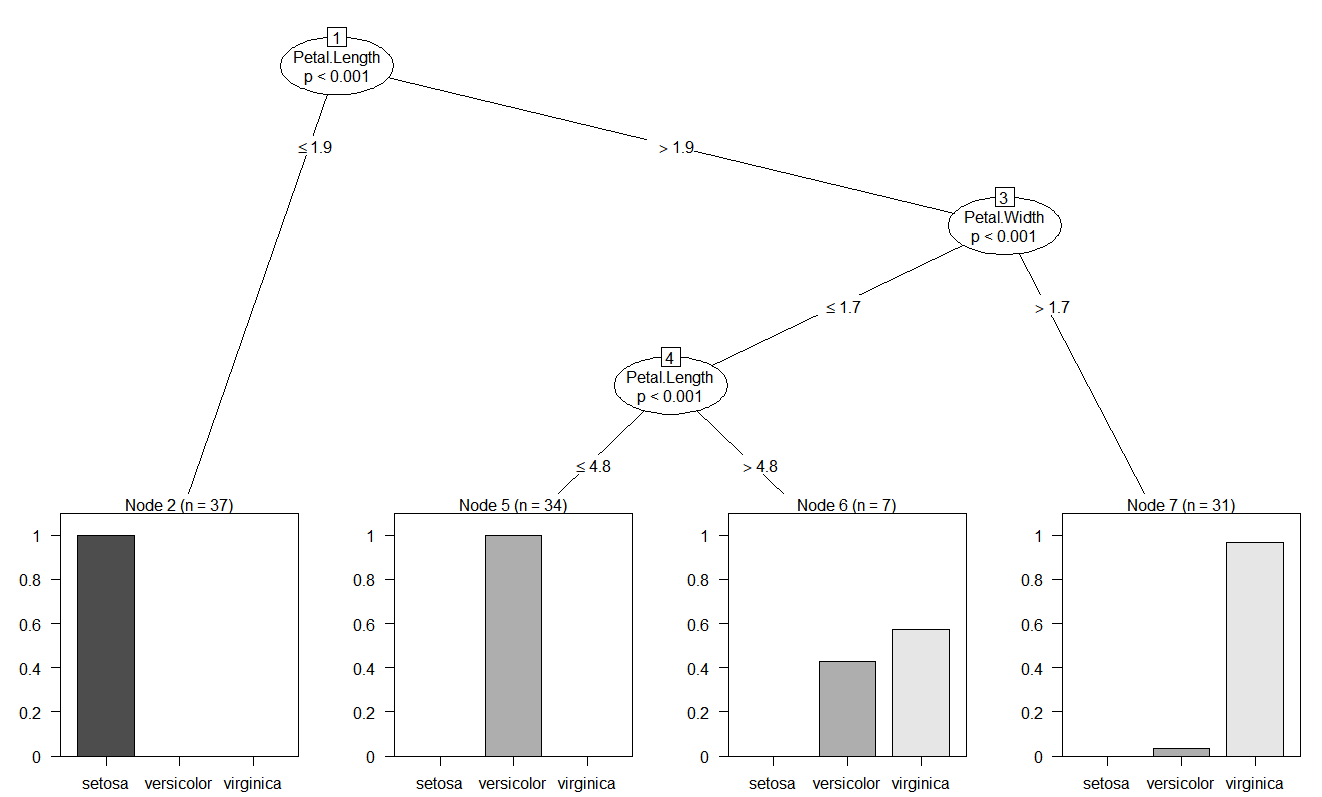
1.2.4 绘制决策树
#绘制决策树
plot(iris_ctree)
#决策树简化形式
plot(iris_ctree,type="simple")
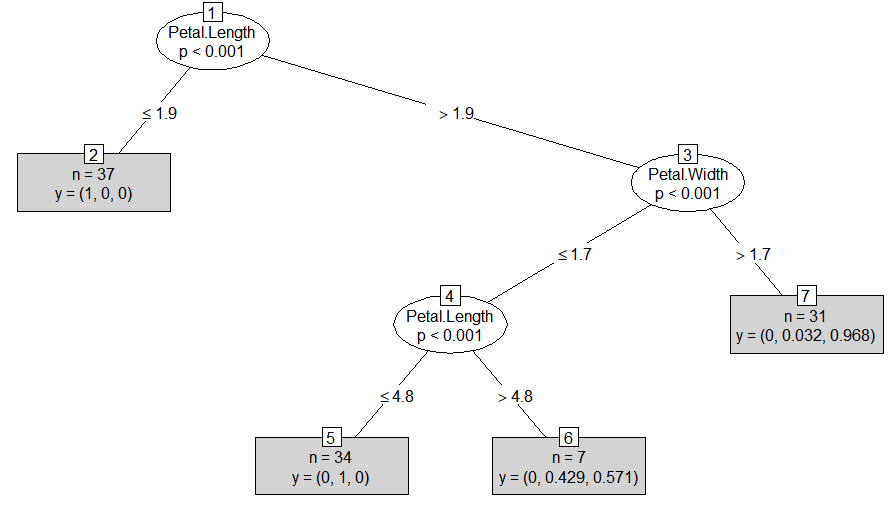
每个叶子节点的条形图显示一个实例被划分到某个种类到概率:
- 节点2“n=37,y=(1,0,0)”,表示该节点包含37个训练实例,并且所有实例都属于“setosa”
- 节点6“n=7,y=(0,0.429,0.571)”,表示该节点包含7个训练实例,42.9%的实例属于“Versicolour”,57.1%的实例属于“Virginica”,7×57.1%≈4,对应了4.1节的“既是Versicolour鸢尾花也是Virginica鸢尾花:4条”
1.3 预测
1.3.1 测试集预测
#predict()进行预测
testPred <- predict(iris_ctree,newdata = testData)
#查看预测结果
table(testPred,testData$Species)

1.3.2 预测结果分析
#Setosa鸢尾花:13条
#Versicolour鸢尾花:11条
#Virginica鸢尾花:15条
#既是Versicolour鸢尾花也是Virginica鸢尾花:1条
#既是Virginica鸢尾花也是Versicolour鸢尾花:1条
#共41条数据
2.决策树–rpart()–bodyfat
2.1 数据
2.1.1 程序包加载
install.package('rpart')
library(rpart)
#rpart这个包被用来在'bodyfat'这个数据集的基础上建立决策树。
#函数raprt()可以建立一个决策树,并且可以选择最小误差的预测。
2.1.2 数据集探索
data("bodyfat", package = "TH.data")
dim(bodyfat) #查看数据尺寸
attributes(bodyfat) #查看数据变量名、行名称、数据类型等
bodyfat[1:5,] #查看前五行数据
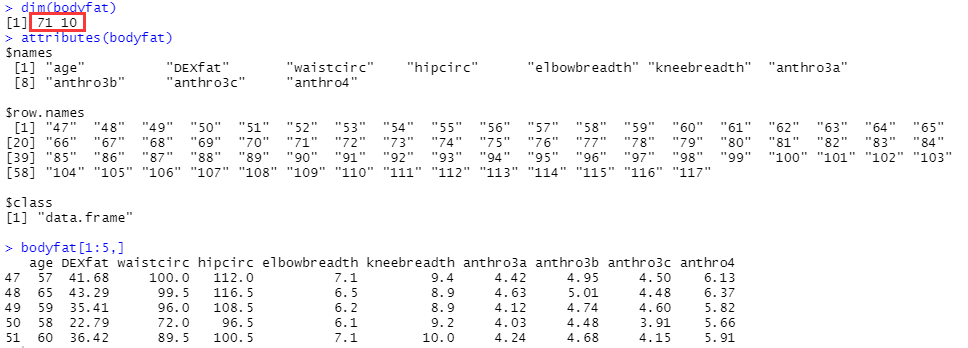 可以看到数据集有71条数据,包括10个变量:
可以看到数据集有71条数据,包括10个变量:
- age:年龄。
- DEXfat:以DXA计算的体脂重,响应变量。
- waistcirc:腰围。
- hipcirc:臀围。
- elbowbreadth:肘宽。
- kneebreadth:膝宽。
- anthro3a:三项人体测量的对数和。
- anthro3b:三项人体测量的对数和。
- anthro3c:三项人体测量的对数和。
- anthro4:三项人体测量的对数和。
2.1.3 数据集拆分
set.seed(1234) #设置随机种子
ind <- sample(2, nrow(bodyfat), replace=TRUE, prob=c(0.7, 0.3))
bodyfat.train <- bodyfat[ind==1,]
bodyfat.test <- bodyfat[ind==2,]
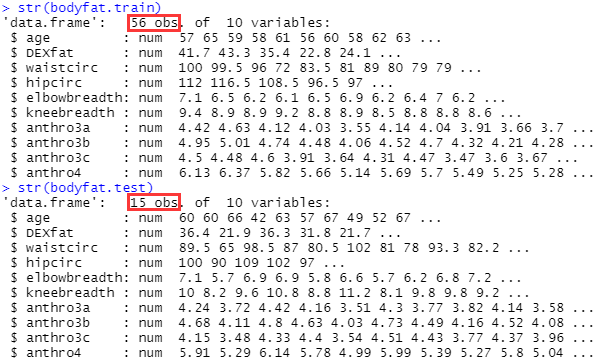
#查看拆分后的数据
str(bodyfat.train)
str(bodyfat.test)
2.2 训练
2.2.1 设置因变量、自变量
#将DEXfat设置为因变量,age、waistcirc、hipcirc、elbowbreadth、kneebreadth为自变量
myFormula <- DEXfat ~ age + waistcirc + hipcirc + elbowbreadth + kneebreadth
2.2.2 决策树建模
bodyfat_rpart <- rpart(myFormula, data = bodyfat.train,control = rpart.control(minsplit = 10))
#函数格式rpart(formula, data, weights, subset, na.action = na.rpart, method,
model = FALSE, x = FALSE, y = TRUE, parms, control, cost, ...)
#control设置决策树的参数
#minsplit用于指定节点的最小样本量,默认为20.当节点样本量小于指定值时将不再继续分组
2.2.3 查看训练结果
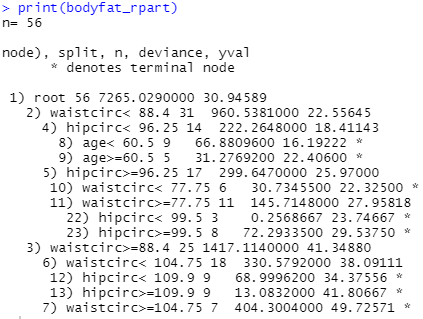
print(bodyfat_rpart)
2.2.4 绘制决策树
plot(bodyfat_rpart)
#为决策树添加文本标签
text(bodyfat_rpart, use.n=T)
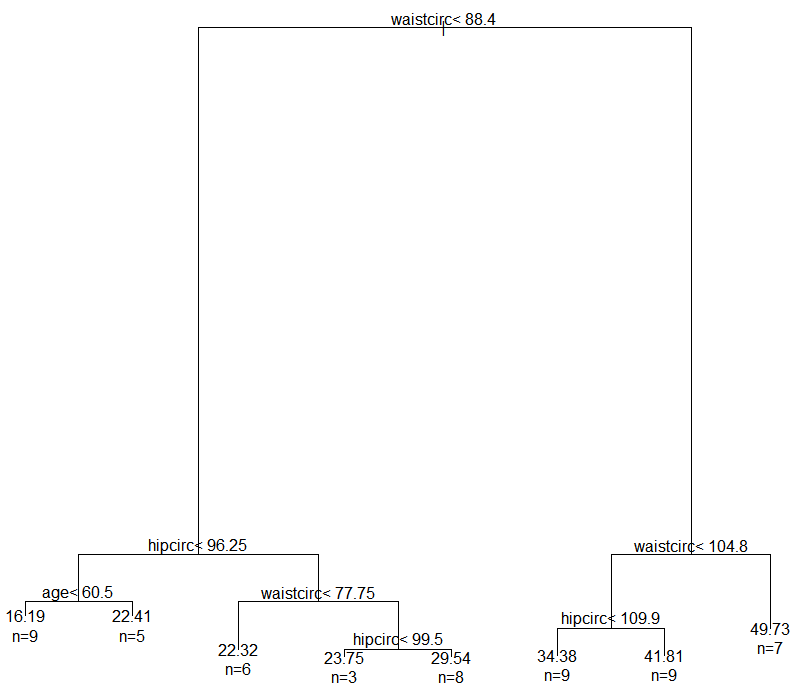
2.3 优化
2.3.1 优化模型(剪枝)
#选择预测误差最小值的预测树,从而优化模型
opt <- which.min(bodyfat_rpart$cptable[,"xerror"])
cp <- bodyfat_rpart$cptable[opt, "CP"]
#prune函数可以实现最小代价复杂度剪枝法
bodyfat_prune <- prune(bodyfat_rpart, cp = cp)
#cp为复杂度系数,上面的办法选择具有最小xerror的cp的办法
这里最开始不太明白“bodyfat_rpart$cptable”,简单查看一下:
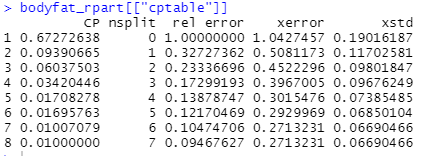
2.3.2 绘制决策树(剪枝后)
#绘制决策树
plot(bodyfat_prune)
#添加文本标签
text(bodyfat_prune, use.n=T)
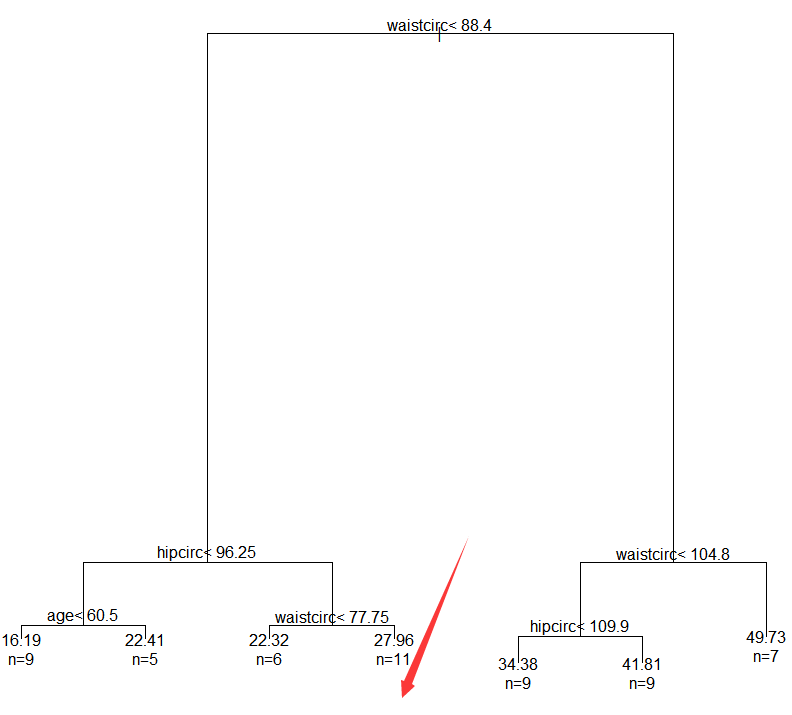
对比结果就会发现,优化模型后,就是将hipcirc<99.5这个分层给去掉了,也许是因为这个分层没有必要,可以思考一下为什么选择预测误差最小的结果的决策树的分层反而没有那么细。
2.4 预测
2.4.1 测试集预测
DEXfat_pred <- predict(bodyfat_prune, newdata=bodyfat.test)
2.4.2 预测值的极值
xlim <- range(bodyfat$DEXfat)
#绘制散点图
plot(DEXfat_pred ~ DEXfat,data=bodyfat.test,xlab="Observed",ylab="Predicted",ylim=xlim,xlim=xlim)
#此处plot(纵坐标数据~横坐标数据,数据,横坐标名称,纵坐标名称,纵坐标轴数值取bodyfat$DEXfat范围,横坐标轴数值取bodyfat$DEXfat范围)
#添加对角线
abline(a=0, b=1)
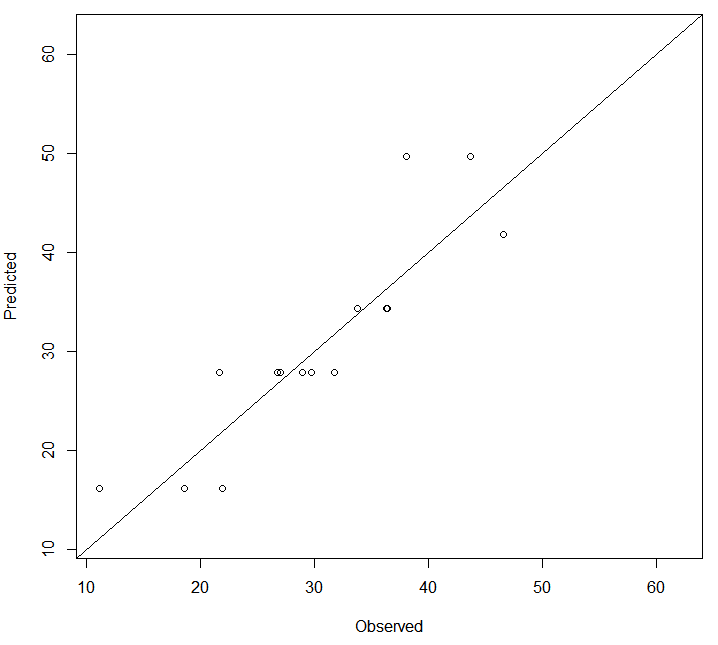
优化后的决策树将会用来预测,预测的结果会与实际的值进行对比。
上面的代码中,使用函数abline()绘制一条斜线。
一个好的模型的预测值应该是约接近真实值越好,也就是说大部分的点应该落在斜线上面或者在斜线附近。
3.随机森林–randomForest()–iris
3.1 程序包加载
install.packages('randomForest')
library(randomForest)
我们使用包randomForest并利用鸢尾花数据建立一个预测模型,包里面的randomForest()函数有两点不足:
- 第一,它不能处理缺失值,使得用户必须在使用该函数之前填补这些缺失值
- 第二,每个分类属性的最大数量不能超过32个,如果属性超过32个,那么在使用randomForest()之前那些属性必须被转化。也可以通过另外一个包’cforest’建立随机森林,并且这个包里面的函数并不受属性的最大数量约束,尽管如此,高维的分类属性会使得它在建立随机森林的时候消耗大量的内存和时间。
3.2 数据集拆分
ind <- sample(2, nrow(iris), replace=TRUE, prob=c(0.7, 0.3))
trainData <- iris[ind==1,]
testData <- iris[ind==2,]

3.3 随机森林建模
rf <- randomForest(Species ~ ., data=trainData, ntree=100, proximity=TRUE)
#Species ~ .指的是Species与其他所有属性之间的等式
# ntree:指定随机森林所包含的决策树数目,默认为500
# proximity:逻辑参数,是否计算模型的临近矩阵,主要结合MDSplot()函数使用
#查看预测结果
table(predict(rf), trainData$Species)
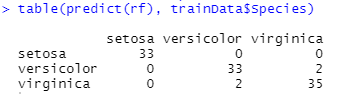
由上图的结果可知,即使在决策树中,仍然有误差,第二类和第三类话仍然会被误判
#查看模型
print(rf)
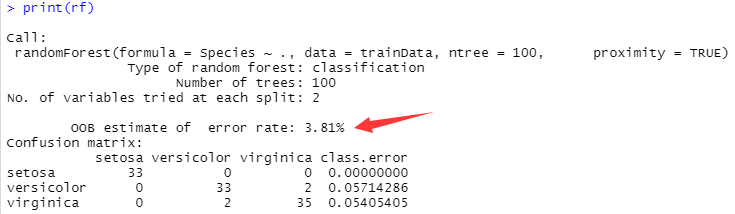
通过输入print(rf)知道误判率为3.81%
#绘制每一棵树的误判率的图
plot(rf)
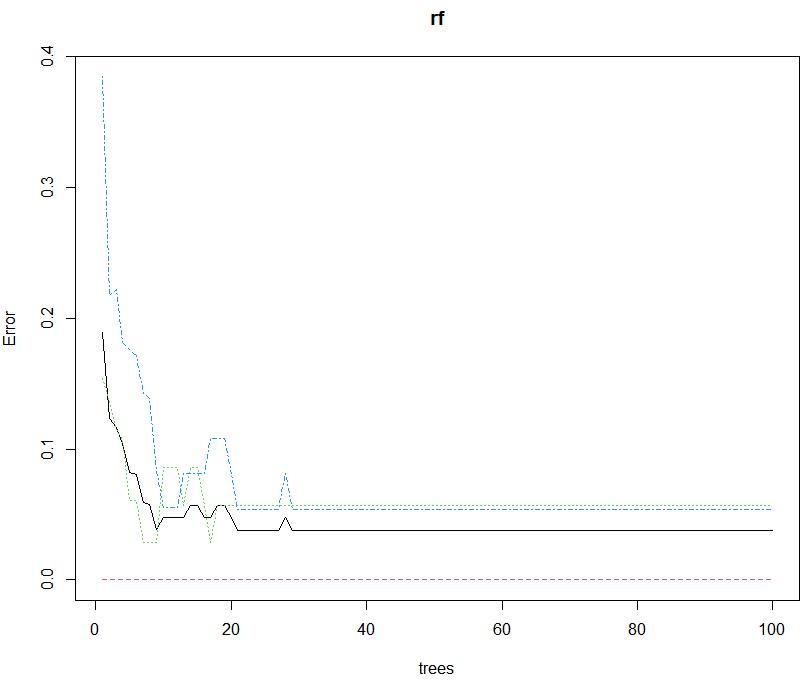
可以通过输入plot(rf)绘制每一棵树的误判率的图
3.4 测试集预测
最后,在测试集上测试训练集上建立的随机森林,并使用table()和margin()函数检测预测结果。
irisPred <- predict(rf, newdata=testData)
#查看测试集预测结果
table(irisPred, testData$Species)
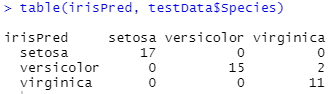
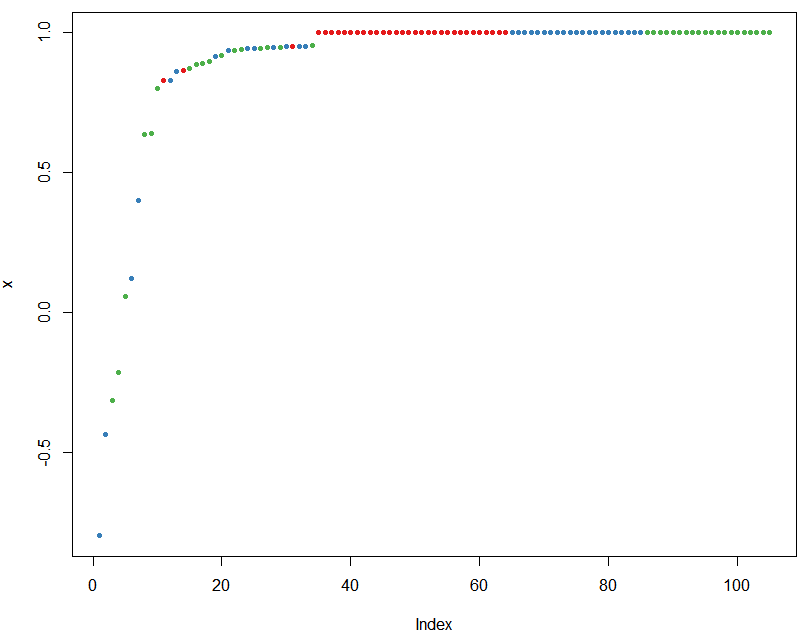
3.5 绘制概率图
#绘制每一个观测值被判断正确的概率图
plot(margin(rf, testData$Species))
实验分析
- 由测试集结果可知,ctree()的目前版本(0.9~9995)不能很好的处理缺失值,因此含有缺失值的实例有时会被划分到左子树中,有时会被划分到右子树中,这是由替代规则决定的。
- 如果训练集中的一个变量在使用函数 ctree()构建决策树后被剔除,那么在对测试集进行预测时也必须包含该变量,否则调用函数 predict()会失败。
- 如果测试集与实训集对分类变量水平值不同,对测试集对预测也会失败。解决此问题的另一个方法是,使用训练集构建一棵决策树后,再利用第一课决策树中包含的所有变量重新调用 ctree()建立一棵新的决策树,并根据测试集中分类变量的水平值显示的设置训练数据。
资料
提取码:h030(无需提取码,以防万一)
Reference
【R语言进行数据挖掘】决策树和随机森林/文博客园@tjxj666
R语言笔记:机器学习【决策树(Decision Tree】/文CSDN@LdyInG_
Learn R | Random Forest of Data Mining(下)/文知乎@Jason
《R语言与数据挖掘最佳实践和经典案例》—— 1.3 数据集/文阿里云开发者社区@华章出版社
分类-回归树模型(CART)在R语言中的实现/文CSDN@周小馬
分类-回归树模型(CART)在R语言中的实现/文博客园@刘小子
总结
- 个人感觉函数直接看官方文档效率会高一些,技术社区里常用的函数会有些人写一下注释,冷门函数看官方文档比较好
- 技术社区常用技术水文较多,一错全错















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









