







一. 单选题
1.某苹果数据集如下所示, K近邻分类法(K取3)对(色度=8.8,高度=7.1,宽度=7.0)的苹果进行分类的结果为( )

A. 绿苹果;
B. 布瑞本;
C. 金冠苹果;
D. 绿苹果或布瑞本;
正确答案: B
2.下列是有关于是否投保的数据集,第二列至第四列为特征,表中最后一列类别代表是否投保,按照“年薪”进行划分的信息增益率为( )

A. 0.061;
B. 0.327;
C. 0.485;
D. 0;
正确答案: B
3.考虑下表中的数据集,使用贝叶斯分类预测记录X=(有房=否,婚姻状况=已婚,年收入=120k)的类标号( )
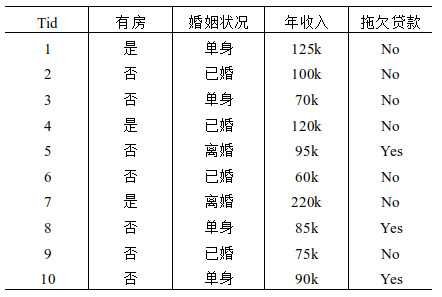
A. Yes;
B. No;
C. Yes or No;
D. 不确定;
正确答案: B
4.考虑下表中的一维数据集,根据 1-最近邻、3-最近邻、5-最近邻、9-最近邻,对数据点 x=5.0分类,使用多数表决( )

A. -、+、-、+;
B. +、+、-、-;
C. -、-、+、+;
D. +、-、+、-;
正确答案: D
5.下表给出了一个关于动物类别的训练数据。数据集包含5个属性:warm_blooded、feathers、fur、swims、lays_eggs。 若样本按warm_blooded划分,对应的熵为( )
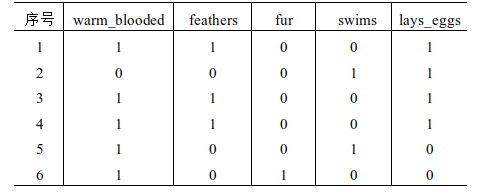
A. 0.809;
B. 0.819;
C. 0.609;
D. 0.619;
正确答案: A
6.下面的例子被分为3类:{Short,Tall,Medium},Height属性被划分为(0,1.6),(1.6,1.7),(1.7,1.8),(1.8,1.9),(1.9,2.0),(2.0,∞),根据下表,对于t=<Adam,M,1.95m>用贝叶斯分类方法进行分类,则最终结果为( )
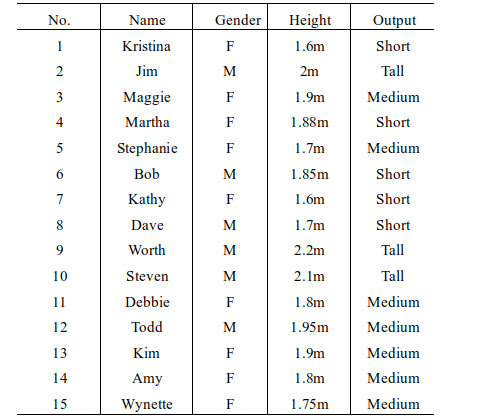
A. Short;
B. Tall;
C. Medium;
D. None;
正确答案: B
7.下列是有关于是否购买电脑的数据集,其中学历,是否结婚,收入为特征,表中最后一列类别代表是否购买电脑,则数据集的信息熵为( )
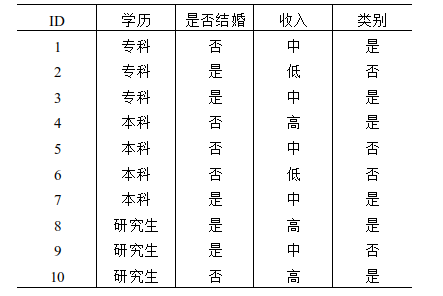
A. 0.254;
B. 0.376;
C. 0.971;
D. 0.865;
正确答案: C
8.下面的数据集包含两个属性X和Y,两个类标号"+“和”-“。每个属性取三个不同的值: 0, 1或2。”+"类的概念是Y=1, "-“类的概念是X=0或X=2。则由表构建的决策树的F1值(对”+"类定义)是( )。

A. 0.33;
B. 0.5;
C. 0.97;
D. 1;
正确答案: B
二. 多选题
1.决策树分类的主要包括( )
A. 对数据源进行OLAP, 得到训练集和测试集;
B. 对训练集进行训练;
C. 对初始决策树进行树剪枝;
D. 由所得到的决策树提取分类规则;
E. 使用测试数据集进行预测,评估决策树模型;
正确答案: ABCDE
2.下列哪些是分类与预测的不同之处( )
A. 分类的作用是构造一系列能描述和区分数据类型或概念的模型;
B. 分类被用作预测目标数据的类的标签;
C. 预测是建立一个模型去预测缺失的或无效的并且通常是数字的数据值;
D. 预测典型的应用是预测缺失的数字型数据的值;
正确答案: AC
3.下列哪些是朴素贝叶斯分类的优缺点( )
A. 朴素贝叶斯分类做了类条件独立假设,大幅降低了计算开销;
B. 需要大量训练数据以覆盖类条件概率空间,引入了很大开销;
C. 容易实现并在大多数情况下可以取得较好的结果;
D. 类条件独立在实际应用中缺乏准确性,因为变量之间经常存在依赖关系,这种依赖关系影响了朴素贝叶斯分类器的准确性;
正确答案: CD
4.支持向量机模型包括( )
A. 线性可分支持向量机;
B. 线性支持向量机;
C. 非线性可分支持向量机;
D. 非线性支持向量机;
正确答案: ABD
5.贝叶斯信念网络(BBN)有哪些特点( )
A. 构造网络费时费力;
B. 对模型的过分问题非常鲁棒;
C. 有效地避免过拟合;
D. 最小化计算开销;
正确答案: AB
三. 填空题
1.分类模型评价指标的计算
混淆矩阵如表所示,计算准确率、错误率、特效性等评价指标。
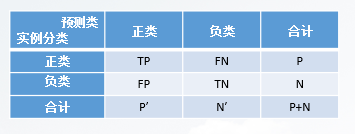
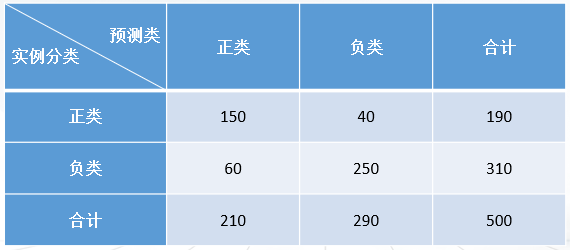
注意:以下括号中的计算结果用%表示,保留2位小数。
①准确率(accuracy)
又称为分类器的总体识别率,准确率表示分类器对各类元组的正确识别情况,它定义为被正确分类的元组数占预测总元组数的百分比,计算公式:
accuracy=(TP+TN)/(P+N) = ()
②错误率(error rate)
又称为误分辨率,错误率表示分类器对各类元组的错误识别情况,是1-accuracy ,具体计算公式:
“error rate”=(“F” P+“F” N)/(P+N) =()
③特效性(specificity)
又称为真负例识别率(True Negative Rate,TNR),特效性表示分类器对负元组的正确识别情况,它定义为正确识别的负元组数量占实际为负元组总数的百分比,计算公式:
“specificity”=TN/N = ()
④灵敏度(sensitivity)
灵敏度也被称为真正例识别率(True Positive Rate,TPR),即正确识别的正元组的百分比,衡量了分类器对正类的识别能力,具体计算公式:
sensitivity=TP/P = ()
⑤精度(precision)
精度可以看做精确性的度量,即正确识别的正元组数量占预测为正元组总数的百分比。具体计算公式:
precision=TP/(TP+FP)=TP/P′ =()
⑥召回率(recall)
召回率用来评价模型的灵敏度和识别率,是完全性的度量,即正元组被标记为正类的百分比,即为灵敏度(或真正例率),具体计算公式:
recall=TP/(TP+FN)=TP/P =()
⑦假负例识别率
假负例识别率(False Negative Rate,FNR),它定义为错误识别为负类的正元组数量占实际为正元组总数的百分比,具体计算公式:
FNR=FN/(TP+FN)=FN/P =()
⑧假正例识别率
假正例识别率(False Positive Rate,FPR),它定义为错误识别为正类的负元组数量占实际为负元组总数的百分比,具体计算公式:
FPR=FP/(FP+TN)=FP/N =()
正确答案:
(1) 80%;80.00%
(2) 20%;20.00%
(3) 80.65%;80.66%
(4) 78.94%;78.95%
(5) 71.42%;71.43%
(6) 78.94%;78.95%
(7) 21.05%;21.06%
(8) 19.35%;19.36%
四. 判断题
1.当一个数据对象同时属于多个类时,很难评估分类的准确率。通常在这种情况下,我们选择的分类器一般趋向于含有这样的特征:最小化计算开销,即使给予噪声数据或不完整数据也能准确预测,在大规模数据下仍然有效工作,提供简明易懂的结果。
正确答案: 对
2.KNN的主要思想是计算每个训练数据(每个训练数据都有一个唯一的类别标识)到待分类元祖的距离,取和待分类元祖距离最近的k个训练数据集,k个数据中哪个类别的训练数据占多数,则待分类元祖就属于那个类别。
正确答案: 对
3.将结点划分为更小的后续结点后,结点熵可能会增加。
正确答案: 错
4.朴素贝叶斯假设属性之间是相互独立的。
正确答案: 对
5.数据分类分为两步:第一步的基本任务是建立一个模型并描述预定的数据类集;第二步的基本任务是评估模型的预测准确率,用准确率可以接受的模型对类标号未知的数据进行分类。
正确答案: 对
6.分类规则的挖掘方法通常有:决策树法、贝叶斯法、人工神经网络法、粗糙集法和遗传算法。
正确答案: 错
7.下表为两周内天气与外出购物的数据集,利用朴素贝叶斯分类预测天气情况为(天气=晴,温度=冷,湿度=高,风力=强)时的结果为不会外出购物。
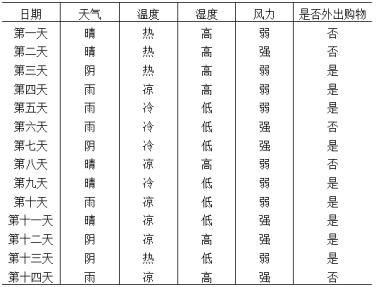
正确答案: 对














 142
142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









