







 该博客对比了多种主流NLP框架在分词、命名实体识别、文本摘要、语义相似度和依存句法分析方面的性能。结果显示,foolnltk在命名实体识别中表现最佳,textRank和hanlp在抽取式文本摘要上占优,huggingface在语义相似度测试中领先,而spacy则在依存句法分析上表现出色。对于时间效率和精度的权衡,foolnltk适合高精度需求,jieba等框架则更适合时间敏感的应用。
该博客对比了多种主流NLP框架在分词、命名实体识别、文本摘要、语义相似度和依存句法分析方面的性能。结果显示,foolnltk在命名实体识别中表现最佳,textRank和hanlp在抽取式文本摘要上占优,huggingface在语义相似度测试中领先,而spacy则在依存句法分析上表现出色。对于时间效率和精度的权衡,foolnltk适合高精度需求,jieba等框架则更适合时间敏感的应用。
1. 实验目的
对比主流nlp框架的功能,并对其实际效果进行测评,以便后续使用。
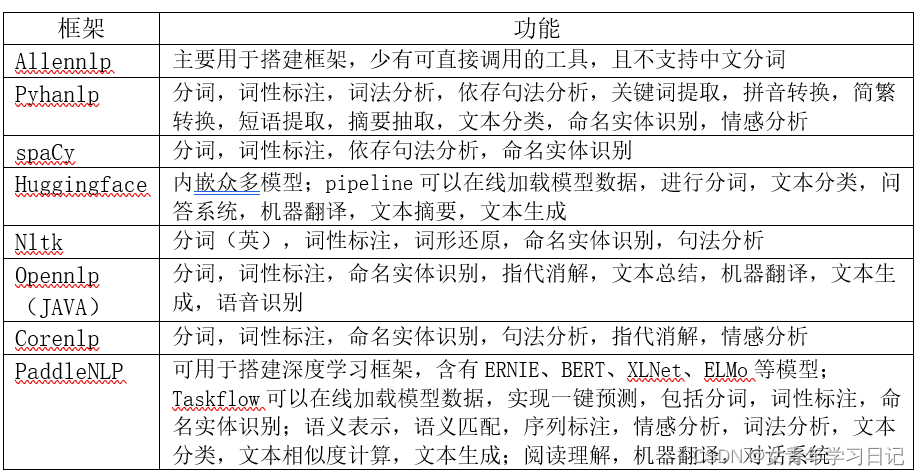
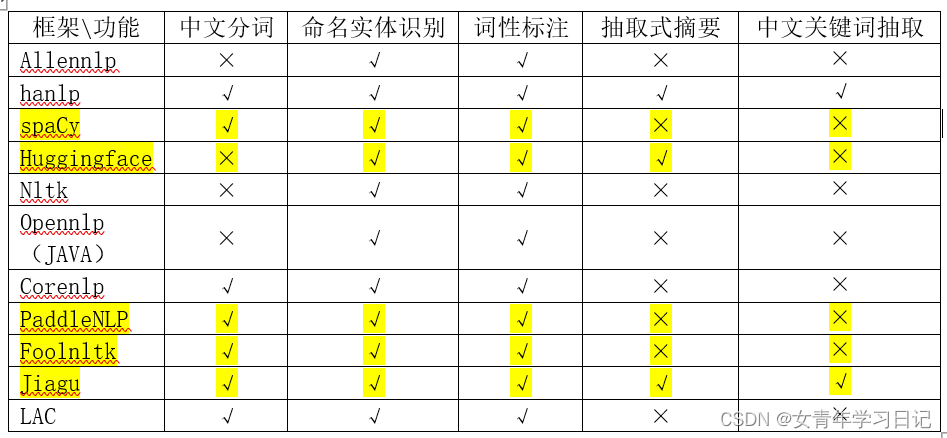
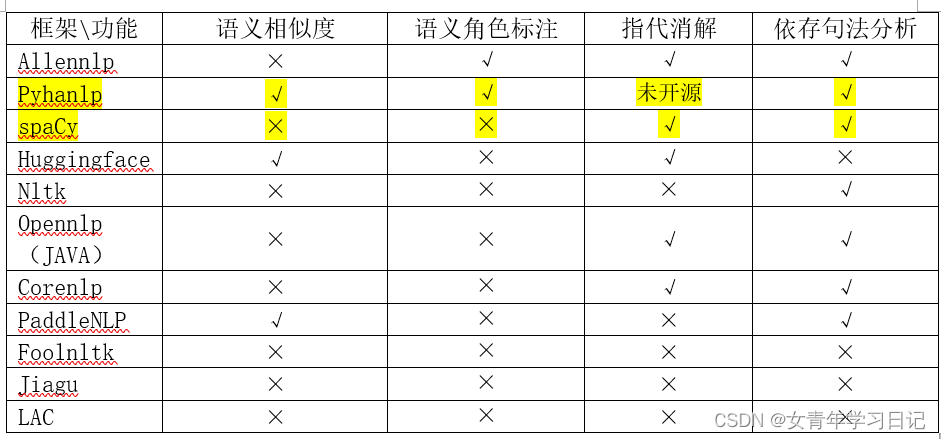
2. 功能矩阵对比
3. 性能测试
(1)分词
数据集选用sighan2005 PKU语料库测试集中的1930个样本。
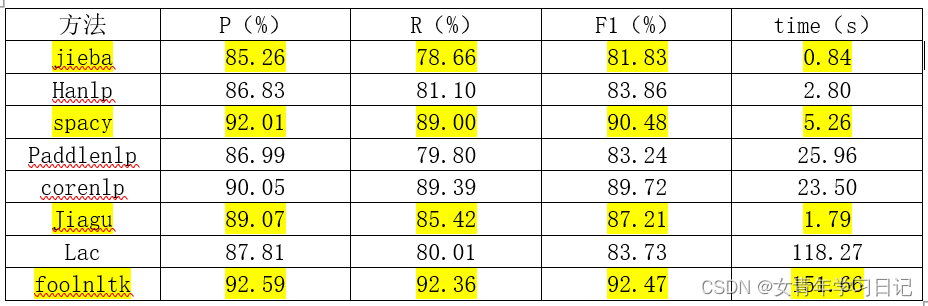
结论: 整体效果上看,若对精度要求高,对时间要求低,可以采用foolnltk;若对时间有一定的要求,则考虑jieba,jiagu和spacy。
(2)命名实体识别
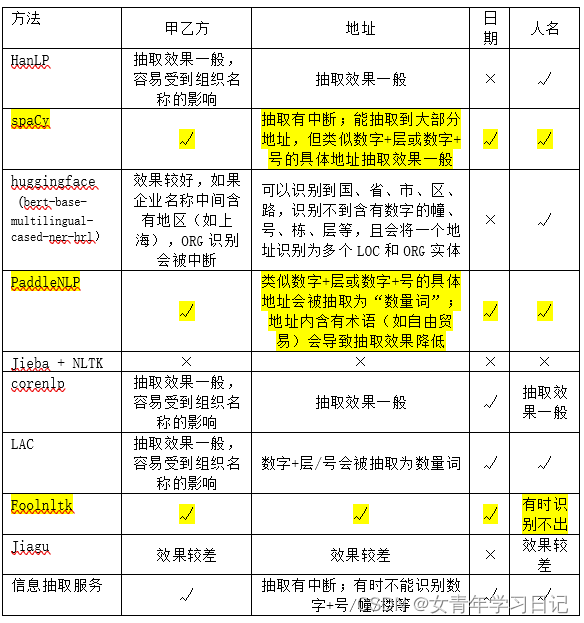
整体效果上,foolnltk > spacy > paddlenlp> huggingface > LAC > hanlp ≈ corenlp > jiagu > nltk
(3)抽取式文本摘要
数据集选用教育培训行业的中文语料,共192876条,随机选取1928条用于评测;评测标准选Rouge-1和Rouge-L。
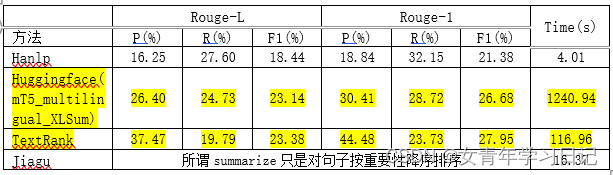
整体效果:textRank > huggingface & hanlp
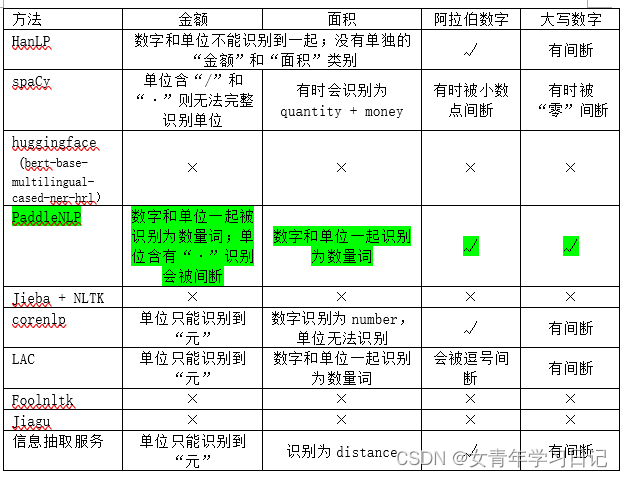
(4)语义相似度
数据集选用微众银行客户问句匹配数据的训练集,含有120000个句子对,取前1000个进行评测,选取阈值为0.5
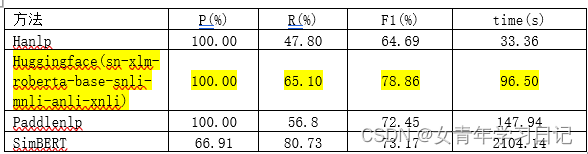
整体上看,huggingface效果最好。
(5)依存句法分析
数据集选用第二届自然语言处理与中文计算会议(NLP&CC 2013)中清华大学语义依存网络语料的验证集(已分词),共计2000个句子。

备注:
- Hanlp和spacy无法直接对分词后的文本进行依存分析,因此只评测分词结果和数据集相同的样本的准确率
- 注:nltk是调用的stanford corenlp的模型包
- Spacy标签的含义对应表:https://github.com/clir/clearnlp-guidelines/blob/master/md/specifications/dependency_labels.md
整体上看,spacy效果最好。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









