







文章目录
- 一、概念
- 二、任务定义
- 三、任务分类
- 四、基于聚类的实体消歧方法
- 五、基于实体链接的实体消歧方法
- 六、各数据集上的SOTA模型
- 1. Raiman
- 2. Evaluating the Impact of Knowledge Graph Context on Entity Disambiguation Models
- 3. Global Entity Disambiguation with BERT
- 4. Neural Cross-Lingual Entity Linking
- 5. Deep Joint Entity Disambiguation with Local Neural Attention
- 6. Named Entity Recognition for Entity Linking: What Works and What’s Next
- 七、结果比较
一、概念
- 定义:同一个单词在不同上下文中表达的含义可能不同,需要消除歧义
- 举例:苹果可以指水果,也可以指苹果公司。
二、任务定义
实体消歧任务定义为六元组:

三、任务分类
- 按照目标实体列表是否给定
(1)未给定目标实体列表,则使用基于聚类的实体消歧系统。聚类的结果中每一个类别对应一个目标实体。
(2)已给定目标实体列表,则使用基于实体链接的实体消岐系统。聚类的结果中每一个类别对应一个目标实体。 - 按照数据类型
(1) 结构化文本实体消歧
通常存储于数据库,缺少上下文信息,主要依赖字面意思和实体关系信息进行消歧
(2) 非结构化文本实体消歧
含有大量上下文信息,主要利用指称项上下文进行消歧 - 按链接数据库类型
(1) 基于知识库的实体链接
在大型文本知识库中提取上下文特征和获取上下文信息
(2) 基于知识图谱的实体链接
利用知识图谱结构来表示实体之间的关系以及侯选实体的上下文特征
四、基于聚类的实体消歧方法
含义:未给定目标实体时,对待消歧的实体指称集合,以聚类方式实现消歧。
思想:同一指称项具有相似的上下文
核心:选取何种特征对于指称项进行表示
步骤:
• 对每一个实体指称项,抽取特征(上下文,实体,概念)表示为特征向量
• 计算实体指称项之间的相似度
• 用某种聚类算法对实体指称项聚类,使得聚类结果中每一个类别都对应于一个目标实体
- 基于词袋模型的聚类方法
将当前语料库中实体指称项周围的词组成特征向量,然后利用向量的相似度对指称项进行比较,并将指称项划分到最接近的实体引用项集合中 - 基于语义特征的聚类方法
不仅包括词袋向量,还包括语义特征,比如对文本进行SVD分解。 - 基于社会化网络的聚类方法
首先构造社会化网络,再利用网络中的社会关系计算实体指称项之间的相似度,比如通过包含身份证号、手机号的网络图消歧人名。这种方法注重实体间关系,忽略实体本身的特征以及实体的上下文特征,并且网络构造难度大,复杂度高。 - 基于百科知识的聚类方法
百科类网站通常会为每个实体分配一个单独页面,其中包括指向其他实体页面的超链接,这种链接关系反映条目之间的语义相关度。百科知识模型用实体上下文的百科条目对于实体进行向量表示,利用维基条目之间的相关度,来计算实体指称项之间的相似度。但是,百科知识覆盖性有限且实体种类较少,因此此类方法使用率较低。 - 基于多源异构语义知识融合的聚类方法
传统的聚类实体消歧方法所使用的目标知识库通常只有一种,覆盖度有限。采用多源异构知识可以克服这一缺点,挖掘和集成不同知识源中的结构化语义知识表示模型来统一表示这些语义知识可以提高实体消歧效率。该方法使用多个知识库(维基百科,wordnet,web网页库)进行聚类,多种数据源之间表达方式略有差异且组合难度大,从而导致实体聚类效果差。
五、基于实体链接的实体消歧方法
将一个命名实体的文本指称项链接到知识库中对应的实体(若不存在对应实体,则将实体指称项链接到空实体NIL)
• 候选实体生成:首先需要给定一个实体指称项,然后根据知识、规则等信息找到实体指称项所对应的候选实体列表。候选实体集合的质量取决于:(1)是否包含目标实体;(2)候选实体的数目
• 实体链接:给定指称项及其连接候选,确定该实体指称项最终指向的目标实体。
-
基于词袋模型计算相似度
将实体指称项上下文文本与候选实体上下文文本表示成词袋向量形式,通过计算向量间夹角确定指称项与候选实体相似度,选择相似度最大的候选实体进行链接 -
基于类别特征
加入指称项文本中的词与候选实体类别的共现特征 -
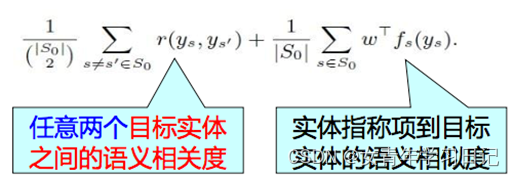
协同实体链接
不仅考虑实体指称项和目标实体的语义相似度,还考虑目标实体之间的语义相似度。
-
基于图的协同链接
上述Pairwise方法只考虑两两实体关系,结局不是全局最优的;采用图方法,全局考虑目标实体之间的语义关联 -
基于神经网络的实体消歧方法
自动联合学习实体和文档的表示,进而完成实体链接任务
六、各数据集上的SOTA模型
1. Raiman
(1)论文:
DeepType: Multilingual Entity Linking by Neural Type System Evolution
https://arxiv.org/pdf/1802.01021.pdf
https://github.com/openai/deeptype
(2)简介:
完全基于类型进行实体链接,构造一个包含很多细粒度类型的类型系统,预测entity mention的类型,基于预测的类型进行实体消歧。
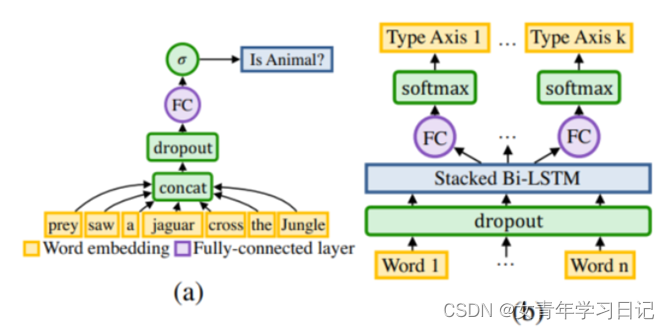
(3)环境需求:Mac OSX或Fedora 25
2. Evaluating the Impact of Knowledge Graph Context on Entity Disambiguation Models
(1)论文
https://arxiv.org/pdf/2008.05190.pdf
https://github.com/mulangonando/Impact-of-KG-Context-on-ED
(2)简介
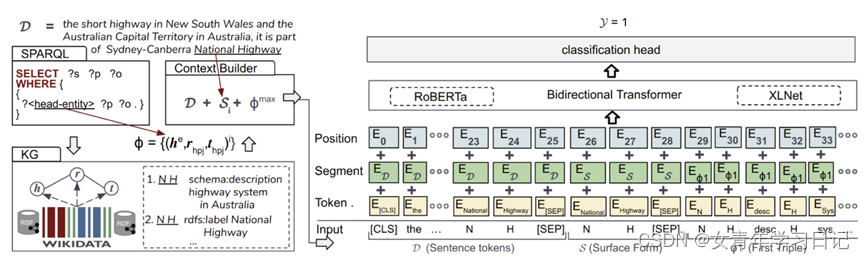
给定一个句子,一个已经识别出的实体描述,和一系列的候选实体,以及一个知识图谱,任务目标在于从KG中选择与文本中的描述相匹配的实体。作者视其为条件概率的分类问题,实际就是在RoBERTa或XLNet的基础上融入知识图谱的信息。
3. Global Entity Disambiguation with BERT
(1)论文
https://arxiv.org/pdf/1909.00426v5.pdf
https://github.com/studio-ousia/luke
(2)模型
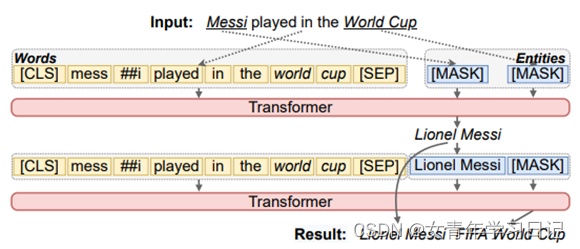
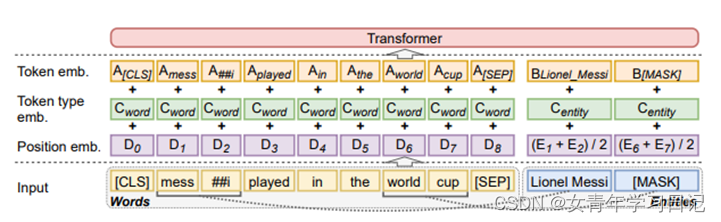
训练任务:预测随机masked掉的实体
Confidence-order:分N步预测,每步预测所有[MASK],按预测[MASK]为对应实体的分数高低,依次进行预测
Natural-order:按mention出现顺序预测
Local model:直接预测所有[MASK]
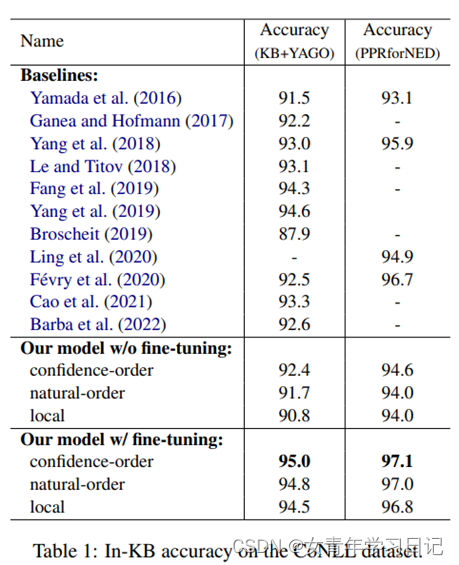
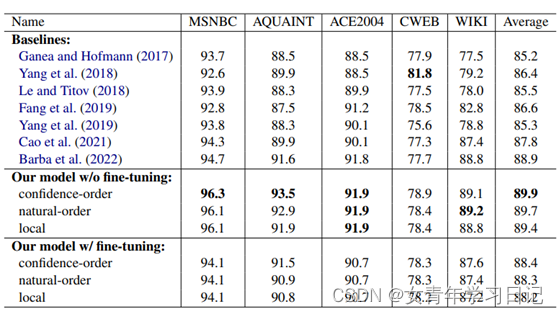
注:用luke-base进行预训练,服务器资源耗费极大。也可以在huggingface上下载模型参数。
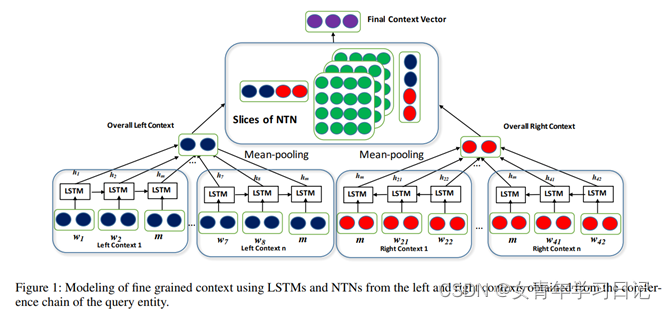
4. Neural Cross-Lingual Entity Linking
(1)论文
https://www.aaai.org/ocs/index.php/AAAI/AAAI18/paper/view/16501/16101
无开源代码
(2)简介
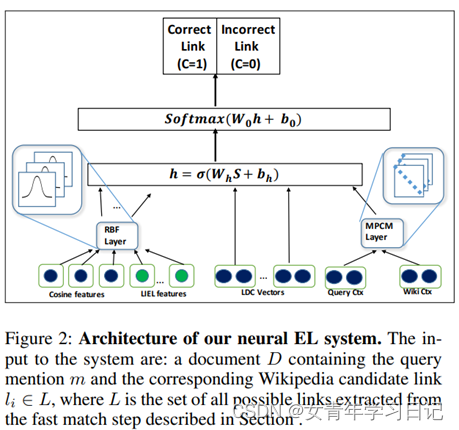
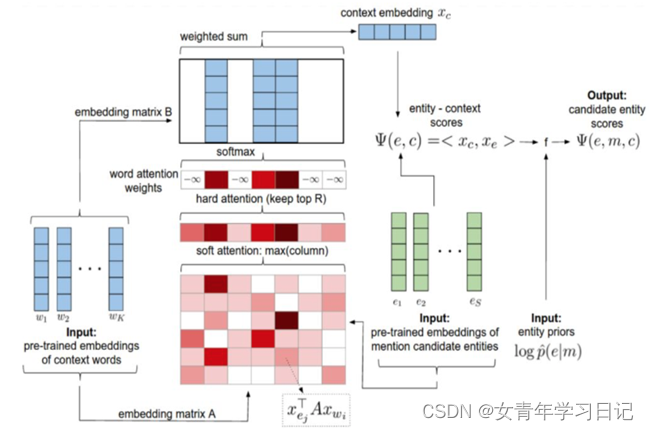
5. Deep Joint Entity Disambiguation with Local Neural Attention
(1)论文
https://aclanthology.org/D17-1277.pdf
https://github.com/dalab/deep-ed
(2)简介
将实体间关系也考虑进embedding中

6. Named Entity Recognition for Entity Linking: What Works and What’s Next
(1)论文
https://aclanthology.org/2021.findings-emnlp.220.pdf
https://github.com/babelscape/ner4el
(2)简介
尝试各种利用命名实体类别信息辅助实体链接的方法,发现NER能够很好的在少样本训练的情况下辅助实体链接模型,缩减采用大规模和有限规模数据训练出来的NL模型的表现差距。
(3)方法
引入了新的细粒度的NER分类,用他们来自动地给维基百科的每个实体进行标注。提出四种引入NER信息的方法:
a. NER-enriched entity representations
b. NER-enhanced candidate selection
c. NER-based negative sampling
d. NER-constrained decoding
Baseline:用两个transformer块,一个用来编码实体指称项(输入为token序列,指称项前后用[E]和[/E]标识,左右上下文最多包含64个token),一个用来编码目标实体(输入为对应维基百科文章的前128个tokrn),最大化余弦相似度:
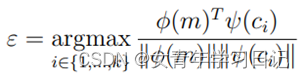
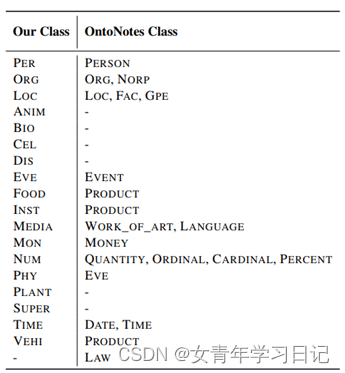
用于NER的细粒度类:
新设计NER类别,利用WordNet标注每个维基百科实体(先人工标200个最高级别的概念组成的种子集合,然后广度优先扩展),以及用BabelNet映射wordnet概念和维基网页。
NER增强的实体表示
通过在实体编码器中加入类别信息,丰富每个候选实体的嵌入。将(NER类别)+实体的文本描述作为增强字符串加入实体编码器。
NER增强的候选生成
训练+部署一个NER分类器(基于BERT)来预测一个mention的NER类别,丢弃掉所有不属于该类别的候选实体。
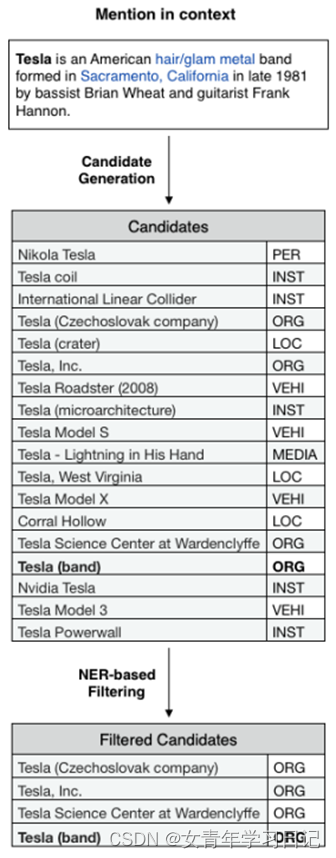
基于NER的负采样
模型通过比较正负样本和候选实体来学习嵌入,但有的实体指称项只有一个候选实体,导致学习不佳。因此考虑加入负样本。本文根据NER类别选择特定的负样本,加入和目标实体同类别的负样本,使得训练更有挑战性。
NER约束的解码器
在推断时,加入软约束或硬约束。直观上,对于非常有歧义的指称项,EL可能偏向频繁出现的实体,而不考虑背景。为此,本文约束EL系统,使其输出的实体的NER类别与同样输入的NER分类器的预测一致。硬约束:迫使EL系统的预测实体和NER分类器的预测完全一样;软约束:迫使预测实体属于NER分类器的top-k预测。
NER贡献的组合
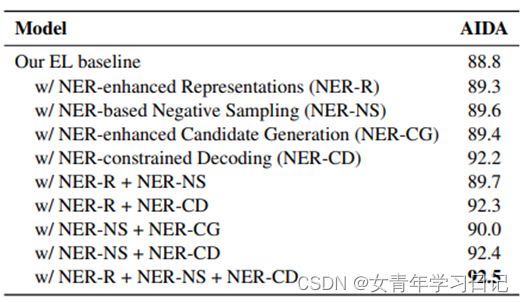
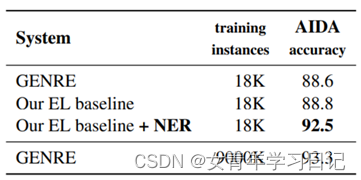
(4)实验demo
构建的NER_classifier未提供训练代码,但提供了保存好的模型,等于给Wikipedia的entity多加了个标签,无论是在编码、生成、判别阶段都可以用得上。
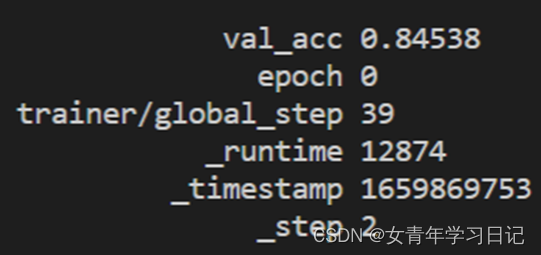
不加NER-Constrained Decoding (NER-CD)策略:共约5小时
七、结果比较
AIDA-CoNLL:
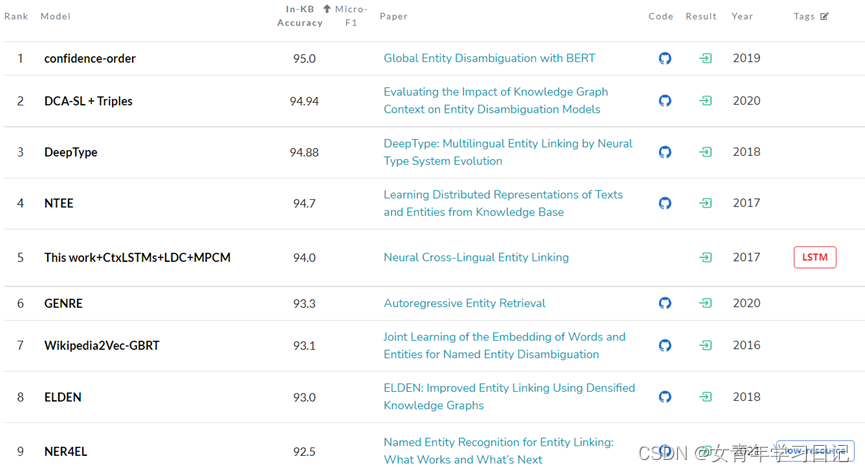
WNED-WIKI:

ACE2004:

AQUAINT:
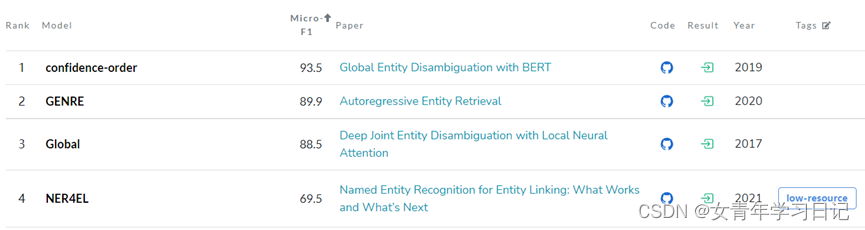
MSNBC:

WNED-CWEB:


















 1113
1113

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









