







 文章介绍了鸢尾花数据集,并通过Python的sklearn库展示了如何使用批量、小批量和随机梯度下降方法实现一元线性回归,比较了不同优化算法在花瓣长度与花瓣宽度上的效果,讨论了各种梯度下降法的优缺点以及它们在模型训练过程中的表现。
文章介绍了鸢尾花数据集,并通过Python的sklearn库展示了如何使用批量、小批量和随机梯度下降方法实现一元线性回归,比较了不同优化算法在花瓣长度与花瓣宽度上的效果,讨论了各种梯度下降法的优缺点以及它们在模型训练过程中的表现。
一、鸢尾花数据集
Iris 鸢尾花数据集内包含 3 类分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica),共 150 条记录,每类各 50 个数据,每条记录都有 4 项特征:花萼长度、花萼宽度、花瓣长度、花瓣宽度。

使用时可通过外部数据文件导入,也可通过 sklean.datasets库导入实现。
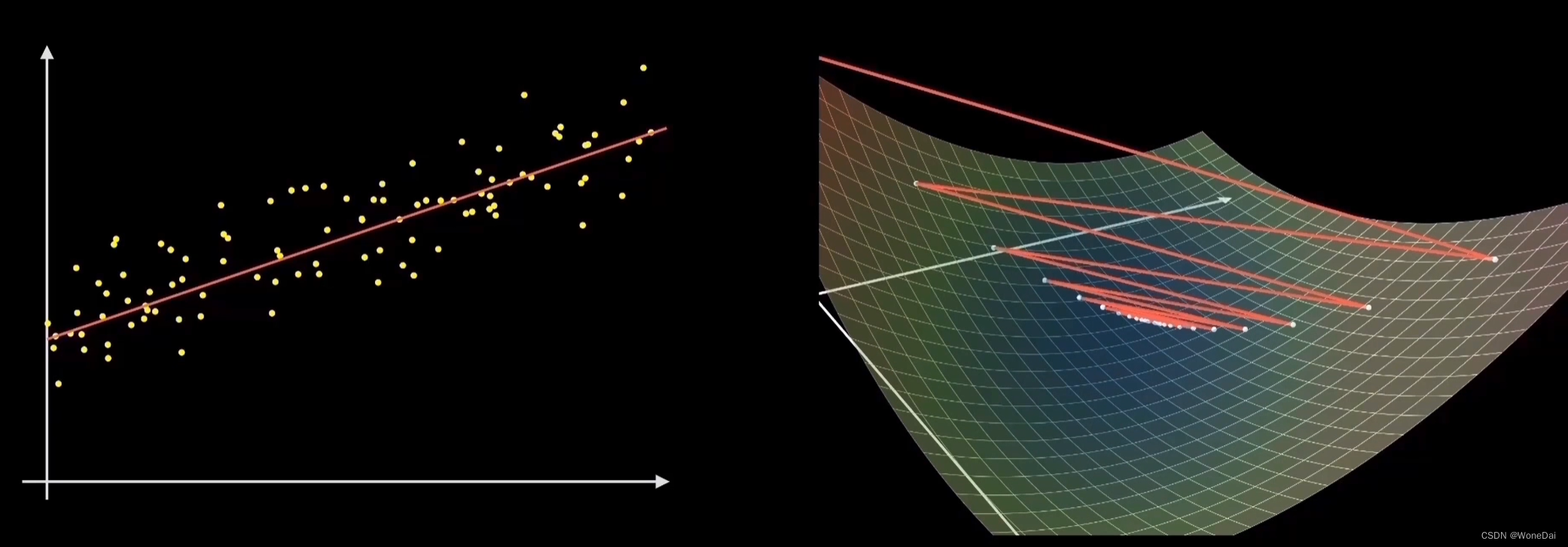
二、三种梯度下降实现一元线性回归----花瓣长度和花瓣宽度
1、批量梯度下降
批量梯度下降法是最原始的形式,它是指在每一次迭代时使用所有样本来进行梯度的更新。
优点:
(1)一次迭代是对所有样本进行计算,此时利用矩阵进行操作,实现了并行。
(2)由全数据集确定的方向能够更好地代表样本总体,从而更准确地朝向极值所在的方向。当目标函数为凸函数时,BGD一定能够得到全局最优。
缺点:
(1)当样本数目 m 很大时,每迭代一步都需要对所有样本计算,训练过程会很慢。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
# 加载数据集
iris = load_iris()
X = iris.data[:, 2] # 取花瓣长度特征
y = iris.data[:, 3]
# 数据标准化
'''
即将数据集中每个特征的值都减去该特征的均值,然后再除以该特征的标准差,使得每个特征的值都在均值为0,方差为1的范围内。
这种数据处理方式能够加速训练过程并提高模型的准确性,
因为在使用梯度下降等优化算法时,数据集中不同特征的值范围过大会导致梯度下降过程中每个特征的权重更新速度不同,
从而导致优化效果较差。标准化处理能够将不同特征的值范围缩小到相近的范围,避免这个问题。
'''
X = (X - np.mean(X)) / np.std(X)
# 构建模型
theta = np.zeros(2) # 参数初始化
alpha = 0.01 # 学习率
iters = 1000 # 迭代次数
m = len(X) # 样本数量
# 批量梯度下降算法
def bgd(X, y, theta, alpha, iters):
J_history = [] # 记录代价函数的值
for i in range(iters):
h = np.dot(X, theta) # 预测值
error = h - y # 误差
cost = 1 / (2 * m) * np.dot(error.T, error) # 计算代价函数
J_history.append(cost)
theta = theta - (alpha / m) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









