







一、非高可用集群带来的问题
1、单点故障
a. 每个群集同一时刻只能有一个活跃的NameNodeNameNode存在单点故障(SPOF)
b. 如果该计算机或进程不可用,则整个群集在整个NameNode重新启动或在另一台计算机上启动之前将不可用
c. 如果发生意外事件(例如机器崩溃),则在操作员重新启动NameNode之前,群集将不可 用。
d. 计划内的维护事件,例如NameNode计算机上的软件或硬件升级,将导致群集停机时间的延长
2、水平扩展 将来服务器启动的时候,启动速度慢
3、namenode随着业务的增多,内存占用也会越来越多,如果namenode内存占满,将无法继续提供服务
4、日志丢失问题
二、高可用架构流程图
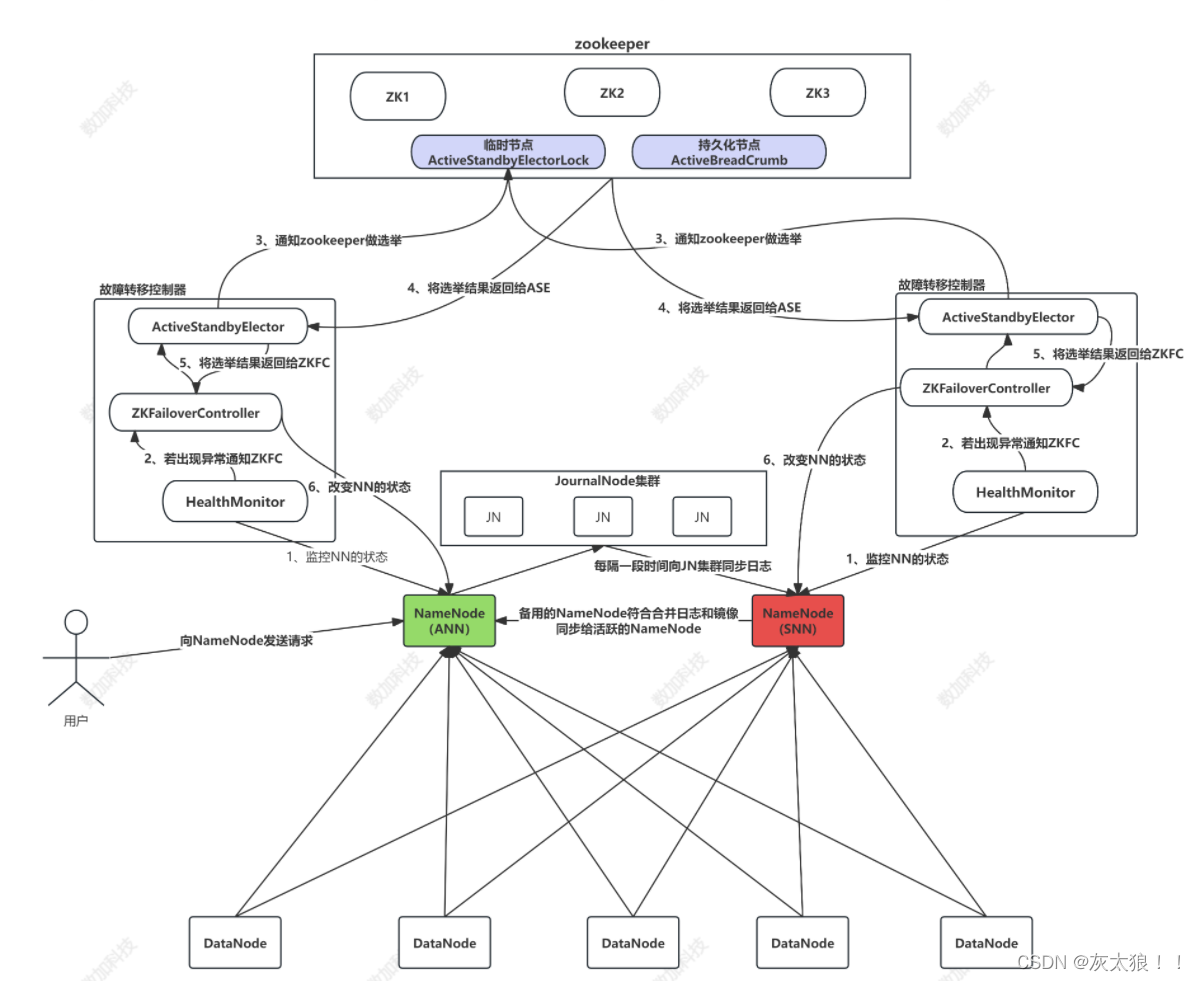
1.流程思路:
1.1、hadoop2.x启用了主备节点切换的模式(1主1备)
1.2 、当主节点出现异常的时候,集群直接将备用节点切换成主节点,而且要满足:(1)要求备用节点马上就要工作(2)主备节点内存几乎同步相同1.3 、独立的线程对主备节点进行监控健康状态1. 4 、需要有一定的选举机制,帮助我们确定主从关系1.5 、我们需要实时存储日志的中间件
2.节点作用:
2.1ActiveNameNode(ANN)
a. 它的功能和原理的 NN 的功能是一样的b. 接受客户端请求,查询数据块 DN 信息c. 存储数据的元数据信息数据文件: Block : DN 的映射关系d. 工作:启动时:接受DN 的 block 汇报 运行时:和 DN 保持心跳 (3s,10m)e. 存储介质完全基于内存优点:数据处理效率高缺点:数据的持久化 ( 日志 edits+ 快照 fsimage)
2.2StandbyNameNode(SNN)
a. Standby NameNode : NN 的备用节点b. 他和主节点做同样的工作,但是它不会发出任何指令 ( 同一 时刻,集群只能有一个活跃的节点)c. 存储:数据的元数据信息数据文件: Block : DN 的映射关系它的内存数据和主节点内存数据几乎是一致的d. 工作:启动时: 接受DN 的 block 汇报运行时: 和 DN 保持心跳 (3s,10m )e. 存储介质:完全基于内存优点:数据处理效率高缺点:数据的持久化
2.3DataNode(DN)
a. 存储文件的 Block 数据b. 介质:硬盘c. 启动时:同时向两个 NN 汇报 Block 信息d. 运行中:同时和两个主节点保持心跳机制
三、高可用集群的搭建
前提:高可用集群需要zookeeper的选举结果来支持(在hadoop专栏中有zookeeper的搭建过程)
1.vim core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cluster</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/soft/hadoop-3.1.1/tmp</value>
</property>
<property>
<name>fs.trash.interval</name>
<value>1440</value>
</property>
<property>
<name>ha.zookeeper.quorum</name>
<value>master:2181,node1:2181,node2:2181</value>
</property>
</configuration>
2.vim hdfs-site.xml
<configuration>
<!-- 指定hdfs元数据存储的路径 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>/usr/local/soft/hadoop-3.1.1/data/namenode</value>
</property><!-- 指定hdfs数据存储的路径 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>/usr/local/soft/hadoop-3.1.1/data/datanode</value>
</property><!-- 数据备份的个数 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property><!-- 关闭权限验证 -->
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property><!-- 开启WebHDFS功能(基于REST的接口服务) -->
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property><!-- //以下为HDFS HA的配置// -->
<!-- 指定hdfs的nameservices名称为mycluster -->
<property>
<name>dfs.nameservices</name>
<value>cluster</value>
</property><!-- 指定cluster的两个namenode的名称分别为nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.cluster</name>
<value>nn1,nn2</value>
</property><!-- 配置nn1,nn2的rpc通信端口 -->
<property>
<name>dfs.namenode.rpc-address.cluster.nn1</name>
<value>master:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.cluster.nn2</name>
<value>node1:8020</value>
</property><!-- 配置nn1,nn2的http通信端口 -->
<property>
<name>dfs.namenode.http-address.cluster.nn1</name>
<value>master:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.cluster.nn2</name>
<value>node1:9870</value>
</property><!-- 指定namenode元数据存储在journalnode中的路径 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://master:8485;node1:8485;node2:8485/cluster</value>
</property><!-- 指定journalnode日志文件存储的路径 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/usr/local/soft/hadoop-3.1.1/data/journal</value>
</property><!-- 指定HDFS客户端连接active namenode的java类 -->
<property>
<name>dfs.client.failover.proxy.provider.cluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property><!-- 配置隔离机制为ssh -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property><!-- 指定秘钥的位置 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property><!-- 开启自动故障转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property></configuration>
3.将配置好的高可用集群同步到node1和node2
scp -r hadoop-3.1.1 node1:`pwd`
scp -r hadoop-3.1.1 node2:`pwd`
4.格式化与启动
(1)格式化集群
hdfs namenode -format
(2)启动节点
hadoop-daemon.sh start namenode
(3)执行同步 没有格式化的NN上执行 在另外一个namenode上面执行 这里选择node1
hdfs namenode -bootstrapStandby
(4)格式化ZK 在master上面执行
要先 把zk集群正常 启动起来
hdfs zkfc -formatZK
(5)启动hdfs集群,在master上执行
start-dfs.sh














 991
991











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









